实验进行时
Posted Coding With you.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验进行时相关的知识,希望对你有一定的参考价值。
torch与cuda版本配对:Previous PyTorch Versions | PyTorch
删除虚拟环境:conda remove -n mygcn --all
时序KG
删掉1.7.1torch装1.8.0,解决报错RuntimeError: CUDA error: no kernel image is available for execution on the
已经成功运行,问题是没有看懂代码,baseline怎么运行
gcn:
报错:Script file 'D:\\anaconda3\\Scripts\\pip-script.py' is not present.
解决:输入easy_install -i https://mirrors.aliyun.com/pypi/simple pip,之后再安装
少样本进行gragh2text任务:
1.报错:
RuntimeError: CUDA out of memory. Tried to allocate 432.00 MiB (GPU 0; 23.70 GiB total capacity; 8.70 GiB already allocated; 73.69 MiB free; 9.24 GiB reserved in total by PyTorch)
可以在报错的地方加上:
4.关键字生成——向量-文本
就是将向量的表示通过全连接层投影到更大的向量logits中,然后通过softmax层将logits对应的分数转化为概率,得到每一个唯一单词的得分
eg:词汇表包含100个词,要生成8个单词,那么logits维度为:8*100*嵌入维度;softmax为8*100可以得到每一个单词对应于词汇表中单词的概率,选择概率最大的对应的词作为得到的单词
with torch.no_grad():
或者将训练集数据、batchsize进行调小
2.学习率
原始的学习率太小了,所以训练的超级慢
科普:学习率 (learning rate),作为监督学习以及深度学习中重要的超参,它控制网络模型的学习进度,决定这网络能否成功或者需要多久成功找到全局最小值,从而得到全局最优解,也就是最优参数。
学习率过大会忽略某些阶段直接学习到下一个阶段,造成学习不全面;还有就是会造成网络不收敛,在最优值上下徘徊,忽略了最优值的位置
学习率过小会使得学习的速度特别慢,甚至在局部极值那里就开始收敛(因为在那块一直跨不过去局部极值这个坑,使得极值在这里便收敛了)
学习率设置:一般是通过学习轮数的改变动态学习学习率的刚开始训练时:学习率以 0.01 ~ 0.001 为宜。
一定轮数过后:逐渐减缓。
接近训练结束:学习速率的衰减应该在100倍以上。
如果是 迁移学习 ,由于模型已在原始数据上收敛,此时应设置较小学习率 (≤0.0001) 在新数据上进行微调
学习率衰减机制:
每n轮学习率减半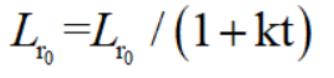
训练过程中的之输衰减:decay_steps
使用批归一化:一般是在网络每一层输入的时候插入一个BN层(归一化为均值为0,方差为1),然后在进入下一层。有了它现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为BN算法收敛很快。
实验
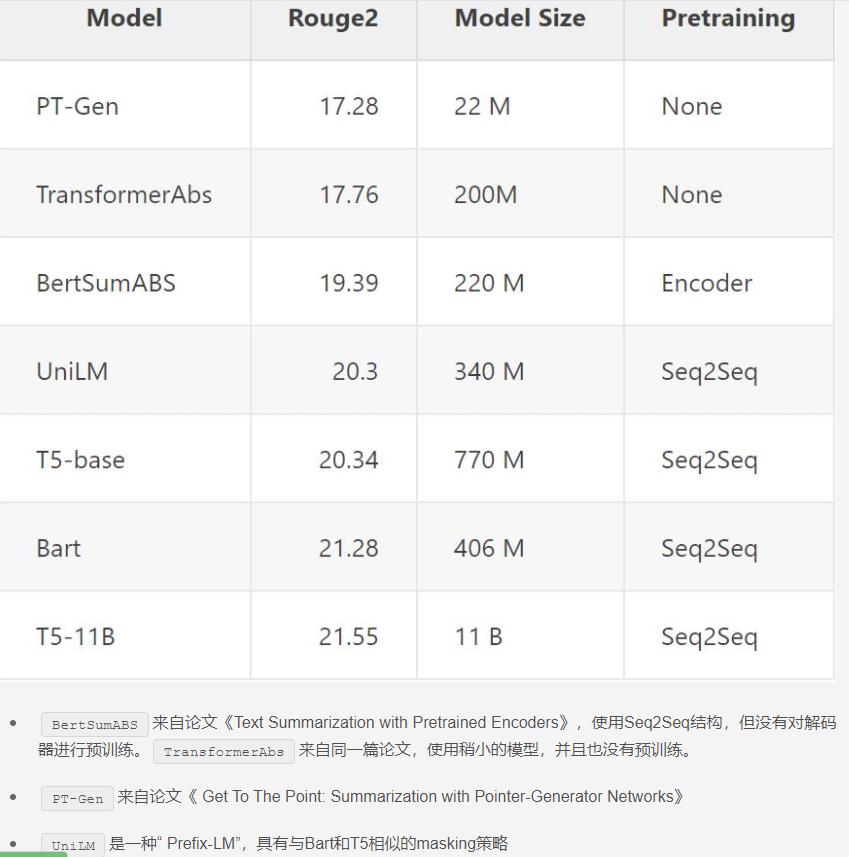
1.BART是生成式预训练模型,可以看作是Bert和gpt的结合体。
在2019年提出,是一个预训练模型。《BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension》
比bert的参数要多一些,在Discriminative Tasks上,达到了RoBERTa类似的表现;在text generation tasks.取得了new state-of-the-art结果。
Transformmer复现
PyTorch教程与源码讲解20——Transformer模型六大细节难点的逐行实现(二)_哔哩哔哩_bilibili
PyTorch教程与源码讲解21——Transformer模型总结及其loss代码实现_哔哩哔哩_bilibili
PyTorch教程与源码讲解21——Transformer模型总结及其loss代码实现_哔哩哔哩_bilibili
以上是关于实验进行时的主要内容,如果未能解决你的问题,请参考以下文章