什么都不会,如何完成毕设?在线课程评论情感分析-本科毕设实战案例
Posted K同学啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么都不会,如何完成毕设?在线课程评论情感分析-本科毕设实战案例相关的知识,希望对你有一定的参考价值。
大家好,我是K同学啊~
春去秋来,时间就这样嘀嗒嘀嗒的过去,不知道大家的毕设做得怎么样了呢
K同学就今天和大家分享一篇关于在线课程评论情感分析的实战案例,帮助大家找找灵感。
数据用的是一份公开的在线课程评论数据,我的环境如下
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- gensim版本号:4.0.1
你可以使用下面的语句配置好 gensim
pip install gensim==4.0.1 -i https://pypi.mirrors.ustc.edu.cn/simple/
如果你对自然语言处理方面的文章有兴趣的话,或许📚《自然语言处理NLP-实例教程》有你想要的
如果你想找一些毕设相关的实战案例做参考,你可以在📚《深度学习100例》找到带源码和数据的实战案例,深度学习小白建议先从📚《小白入门深度学习》这个专栏学起哦!
这些还不能满足你,可以加我微信(mtyjkh_)为你提供一些力所能及的帮助。
🎯 代码+数据 见文末,进入正题
一、导入数据
# 加载语料库文件,并导入数据
neg = pd.read_excel('data/neg.xls', header=None)#, index=None
pos = pd.read_excel('data/pos.xls', header=None)#
pos.head()
| 0 | |
|---|---|
| 0 | 做父母一定要有刘墉这样的心态,不断地学习,不断地进步,不断地给自己补充新鲜血液,让自己保持一... |
| 1 | 作者真有英国人严谨的风格,提出观点、进行论述论证,尽管本人对物理学了解不深,但是仍然能感受到... |
| 2 | 作者长篇大论借用详细报告数据处理工作和计算结果支持其新观点。为什么荷兰曾经县有欧洲最高的生产... |
| 3 | 作者在战几时之前用了"拥抱"令人叫绝.日本如果没有战败,就有会有美军的占领,没胡官僚主义的延... |
| 4 | 作者在少年时即喜阅读,能看出他精读了无数经典,因而他有一个庞大的内心世界。他的作品最难能可贵... |
分词处理
# jieba 分词
word_cut = lambda x: jieba.lcut(x)
pos['words'] = pos[0].apply(word_cut)
neg['words'] = neg[0].apply(word_cut)
pos.head()
Building prefix dict from the default dictionary ...
Loading model from cache C:\\Users\\ADMINI~1\\AppData\\Local\\Temp\\jieba.cache
Loading model cost 0.502 seconds.
Prefix dict has been built successfully.
| 0 | words | |
|---|---|---|
| 0 | 做父母一定要有刘墉这样的心态,不断地学习,不断地进步,不断地给自己补充新鲜血液,让自己保持一... | [做, 父母, 一定, 要, 有, 刘墉, 这样, 的, 心态, ,, 不断, 地, 学习,... |
| 1 | 作者真有英国人严谨的风格,提出观点、进行论述论证,尽管本人对物理学了解不深,但是仍然能感受到... | [作者, 真有, 英国人, 严谨, 的, 风格, ,, 提出, 观点, 、, 进行, 论述,... |
| 2 | 作者长篇大论借用详细报告数据处理工作和计算结果支持其新观点。为什么荷兰曾经县有欧洲最高的生产... | [作者, 长篇大论, 借用, 详细, 报告, 数据处理, 工作, 和, 计算结果, 支持, ... |
| 3 | 作者在战几时之前用了"拥抱"令人叫绝.日本如果没有战败,就有会有美军的占领,没胡官僚主义的延... | [作者, 在, 战, 几时, 之前, 用, 了, ", 拥抱, ", 令人, 叫绝, ., ... |
| 4 | 作者在少年时即喜阅读,能看出他精读了无数经典,因而他有一个庞大的内心世界。他的作品最难能可贵... | [作者, 在, 少年, 时即, 喜, 阅读, ,, 能, 看出, 他, 精读, 了, 无数,... |
# 使用 1 表示积极情绪,0 表示消极情绪,并完成数组拼接
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)), np.zeros(len(neg))))
二、Word2vec处理
# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(vector_size=300, #是指特征向量的维度,默认为100。
min_count=10) #可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5。
w2v.build_vocab(x)
w2v.train(x,
total_examples=w2v.corpus_count,
epochs=20)
# 对每个句子的词向量进行均值计算
def average_vec(text):
vec = np.zeros(300).reshape((1, 300))
for word in text:
try:
vec += w2v.wv[word].reshape((1, 300))
except KeyError:
continue
return vec
# 将词向量保存为 Ndarray
x_vec = np.concatenate([average_vec(z) for z in x])
# 保存 Word2Vec 模型及词向量
w2v.save('data/w2v_model.pkl')
三、训练支持向量机情绪分类模型
model = SVC(kernel='rbf', verbose=True) # 构建支持向量机分类模型
model.fit(x_vec, y) # 训练模型
# 保存训练好的模型
joblib.dump(model, 'data/svm_model.pkl')
[LibSVM]
['data/svm_model.pkl']
# 输出模型交叉验证准确率
print(cross_val_score(model, x_vec, y))
[LibSVM][LibSVM][LibSVM][LibSVM][LibSVM][0.9156598 0.89623312 0.8047856 0.83961147 0.79436153]
四、情感预测
# 读取 Word2Vec 并对新输入进行词向量计算
def average_vec(words):
# 读取 Word2Vec 模型
w2v = Word2Vec.load('data/w2v_model.pkl')
vec = np.zeros(300).reshape((1, 300))
for word in words:
try:
vec += w2v.wv[word].reshape((1, 300))
except KeyError:
continue
return vec
# 对电影评论进行情感判断
def svm_predict(string):
# 对评论分词
words = jieba.lcut(str(string))
words_vec = average_vec(words)
# 读取支持向量机模型
model = joblib.load('data/svm_model.pkl')
result = model.predict(words_vec)
# 实时返回积极或消极结果
if int(result[0]) == 1:
print(string, '[积极]')
return result[0]
else:
print(string, '[消极]')
return result[0]
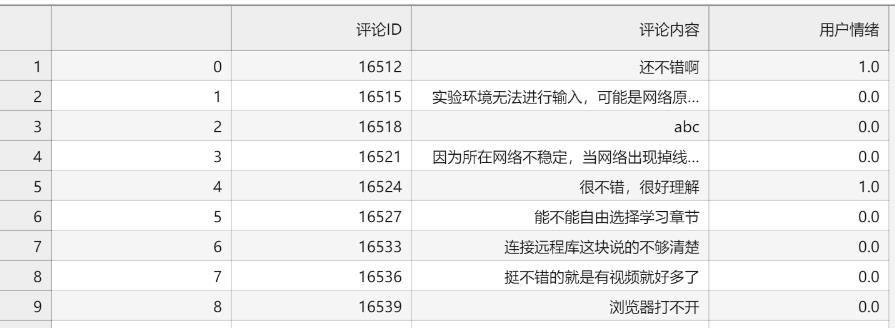
# 读取课程评论数据
df = pd.read_csv("comments.csv", header=0)
comment_sentiment = []
# 用10条数据做测试
for string in df['评论内容'][:10]:
result = svm_predict(string)
comment_sentiment.append(result)
#将情绪结果与原数据合并为新数据
merged = pd.concat([df, pd.Series(comment_sentiment, name='用户情绪')], axis=1)
# 储存文件
pd.DataFrame.to_csv(merged,'comment_sentiment.csv',encoding="utf-8-sig")
print('done.')
还不错啊 [积极]
实验环境无法进行输入,可能是网络原因吧,或者其他问题 [消极]
abc [消极]
因为所在网络不稳定,当网络出现掉线后,实验楼界面就无法点击和输入了 [消极]
很不错,很好理解 [积极]
能不能自由选择学习章节 [消极]
连接远程库这块说的不够清楚 [消极]
挺不错的就是有视频就好多了 [消极]
浏览器打不开 [消极]
重启下 [消极]
done.
我们最后的预测结果如下:
最后再送大家一本,帮助大家拿到 BAT 等一线大厂 offer 的数据结构刷题笔记,是谷歌和阿里的大佬写的,对于算法薄弱或者需要提高的同学都十分受用(提取码:9go2 ):
以及我整理的7K+本开源电子书,总有一本可以帮到你 💖(提取码:4eg0)
以上是关于什么都不会,如何完成毕设?在线课程评论情感分析-本科毕设实战案例的主要内容,如果未能解决你的问题,请参考以下文章