Redis,性能加速的催化剂
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis,性能加速的催化剂相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
二、Redis加快速度的六个设计
我们用mysql跟Redis对比,如下图:
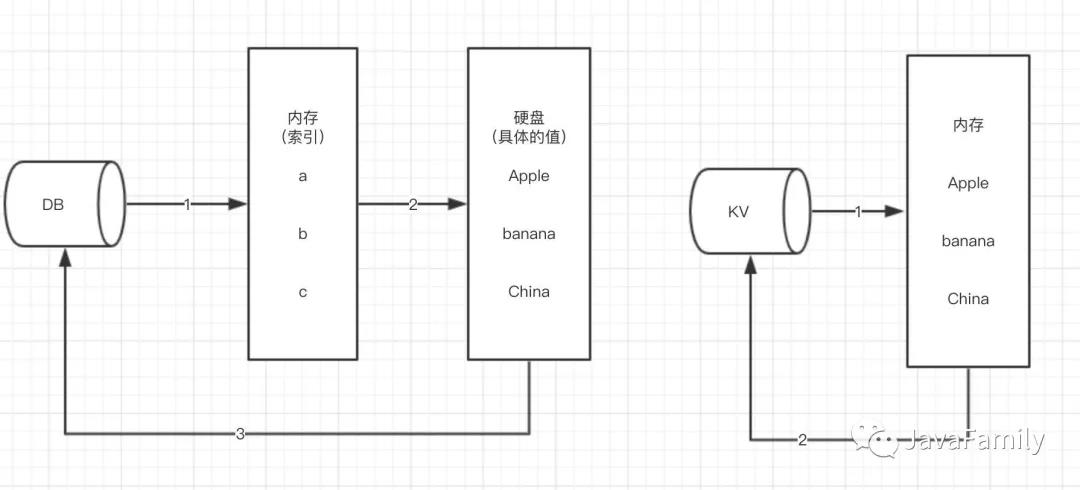
解释上图:左边为mysql的介绍,mysql中的innodb存储引擎,分为内存部分和硬盘部分两层结构:内存部分存放索引,如a b c,磁盘部分中存放具体的值Apple banana China;
右边为redis的介绍,redis只有内存一层结构:为什么没有磁盘?因为Redis是纯粹在内存里的,不涉及磁盘,除非RDB持久化和AOF持久化。所以,从这个图上上面,我们可以知道redis为什么比mysql快的第一个理由,因为redis是完全基于内存的。
金手指:Redis加快速度的六个设计
1、Redis由C语言编写,采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。
2、丰富的数据结构,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。它的,数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
4、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
5、多路I/O复用模型,非阻塞IO:使用多路I/O复用模型,非阻塞IO;
6、Redis自己构建了 VM 机制代替系统调用系统函数:使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制代替系统调用系统函数,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
三、Memcache(简称MC)和Redis
| Memcache | redis | |
|---|---|---|
| 数据类型(Redis速度快的第二个原因) | 数据结构:只支持 K-V 结构,不提供持久化和主从同步功能。且在k-v结构:key 不能超过 250 个字节;value 不能超过 1M 字节;key 的最大失效时间是 30 天(数据类型是Memcache的最大劣势,是大家选择Redis、MongoDB的重要原因) | 数据类型:相比 MC,Redis 还有一个非常大的优势,就是除了 K-V 之外,还支持多种数据格式,例如 list、set、sorted set、hash 等。 |
| 基于内存(Redis速度快的第三个原因) | 基于内存:MC 功能简单,基于内存存储数据,注意MC的内存结构以及钙化问题; | 基于内存:Redis 支持持久化,所以 Redis 不仅仅可以用作缓存,也可以用作 NoSQL 数据库(解释:redis基于内存可以作为缓存,但是持久化到磁盘就可以成为NoSQL数据库了,然后,RDB作为全量复制的冷备份,slave第一次接入集群的时候master发送,AOF作为热备份,slave每次接收master的同步)。 |
| 多线程or单线程(Redis速度快的第四个原因) | 多线程:MC 处理请求时使用多线程异步 IO 的方式,可以合理利用 CPU 多核的优势,性能非常优秀; | 单线程:Redis 采用单线程模式处理请求。 |
| 缓存失效 | 缓存失效时间:MC 对缓存的数据可以设置失效期,过期后的数据会被清除;失效的策略采用延迟失效,即当再次使用数据时检查是否失效;当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。 | key 失效机制:Redis 的 key 可以设置过期时间,过期后 Redis 采用主动和被动结合的失效机制,一个是和 MC 一样在访问时触发被动删除,另一种是定期的主动删除。 |
| 集群(Redsi集群优势) | 无 | 集群:Redis 提供主从同步机制,以及 Cluster 集群部署能力,能够提供高可用服务。 |
Redis相对于Mencached的优点(数据结构优势+集群优势)
第一,数据结构,Redis 支持复杂的数据结构
解释:Redis 相比 Memcached 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, Redis 会是不错的选择。
第二,集群,Redis 原生支持集群模式
解释:在 redis3.x 版本中,便能支持 Cluster 模式,而 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
第三,性能对比:redis单核100k以下数据好,Memcached 多核100k以上数据好
解释:由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Remcached,还是稍有逊色。
四、Redis六种淘汰策略
问题1:为什么Redis需要淘汰策略,而不是扫描全部设置了过期时间的key呢?
回答1:因为Redis里面所有的key都有过期时间,如果全部扫描压力太大,全扫描跟你去查数据库不带where条件不走索引全表扫描一样,不显示。
问题2:如果一直没随机到很多key,里面不就存在大量的无效key了,如何处理?
回答2:定时删除+惰性删除
定时删除:每隔一段实践删除一些,对CPU不友好,对内存友好;
惰性删除:不主动删,我等你来查询了我看看你过期没,过期就删去redis中这个key,没过期就取出,对CPU友好,对内存不友好。
问题3:如果某些key,定时删除没删,我也没查询(则惰性删除也没有删除),如何?
内存淘汰机制!官网上给到的内存淘汰机制是六个:
(1) noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
(2) allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
(3) volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
(4) allkeys-random: 回收随机的键使得新添加的数据有空间存放。
(5) volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
(6) volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
小结:如果没有键满足回收的前提条件的话,策略volatile-lru, volatile-random以及volatile-ttl就和noeviction 差不多了。
五、Redis线程模型与事件
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件(文件事件+时间事件):
文件事件 (file event):Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
时间事件( time event):Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
5.1 文件事件
Redis基于Reactor模式开发了自己的网络事件处理器,这个处理器被称为文件事件处理器:
1)文件事件处理器使用I/O多路复用( multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器;
2)当被监听的套接字准备好执行连接应答(accept)、读取(read)写人(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
注意:虽然文件事件处理器以单线程方式进行,但是通过使用I/O多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis服务器中其他同样以单线程方式运行的模块进行对接,这保持了Redis内部单线程设计的简单性。
Redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。文件事件处理器 file event handler ,采用 IO 多路复用机制同时监听多个 Socket,根据 Socket 上的事件来选择对应的事件处理器进行处理。文件事件处理器的结构包含 4 个部分:
多个 Socket
IO 多路复用程序
文件事件分派器
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 Socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 Socket,会将 Socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。如下图:
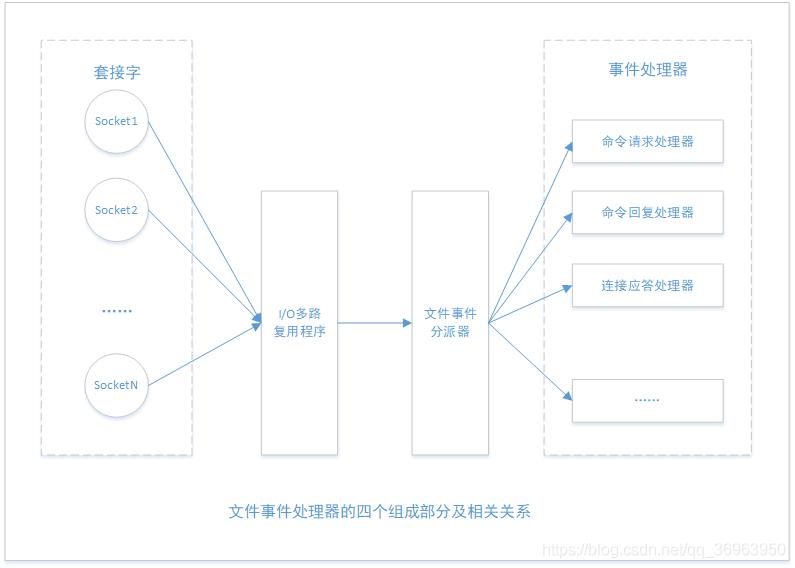
对于上图的解释:
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
1)关于I/O多路复用程序:I/O多路复用程序负责监听多个套接字,并向文件事件分派器传送那些产生了事件的套接字。
2)关于套接字队列:尽管多个文件事件可能会并发地出现,但I/O多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序(sequentially),同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕),I/O多路复用程序才会继续向文件事件分派器传送下一个套接字。

3)关于文件事件分派器:文件事件分派器接收I/O多路复用程序传来的套接字,并根据套接字产生的事件的类型,调用相应的事件处理器。
4)关于事件处理器:服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个函数,它们定义了某个事件发生时,服务器应该执行的动作。
问题1:为什么redis是单线程的?
回答1:
底层原因:Redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。
业务原因一:redis采用了非阻塞的异步事件处理机制,没有必要用多线程
业务原因二:一般缓存数据都是内存操作 IO 时间不会太长,单线程可以避免线程上下文切换产生的代价。
业务原因三:redis确实是单线程,但是可以搭建多个redis实例构成redis集群。
问题2:Redis使用单线程,我们现在服务器都是多核的,那不是很浪费?
回答2:是的他是单线程的,但是,我们可以通过在单机开多个Redis实例。
问题3:redis单线程如何处理多个事件?
回答3:
第一,redis单线程,但是可以部署多个redis实例,实现redis集群。
第二,对于单个redis,它采用 IO 多路复用机制同时监听多个 Socket,根据 Socket 上的事件来选择对应的事件处理器进行处理。
问题4:Redis使用单线程避免了上下文切换,什么是上下文切换?为什么上下文切换不安全?
回答4:好比你看一本英文书,你看到第十页发现有个单词不会读,你加了个书签,然后去查字典,过了一会你又回来继续从书签那里读,ok到目前为止没啥问题。如果是你一个人读肯定没啥问题,但是你去查的时候,别的小伙伴好奇你在看啥他就翻了一下你的书,然后溜了,哦豁,你再看的时候就发现书不是你看的那一页了。为啥会线程不安全,就是因为你一个人怎么看都没事,但是人多了换来换去的操作一本书数据就乱了。
5.2 时间事件
Redis的时间事件分为以下两类:
1)定时事件 :让一段程序在指定的时间之后执行一次。比如说,让程序X在当前时间的30毫秒之后执行一次。
2)周期性事件 :让一段程序每隔指定时间就执行一次。比如说,让程序Y每隔30毫秒就执行一次。
一个时间事件主要由以下三个属性组成:
1)id:服务器为时间事件创建的全局唯一ID(标识号),ID号按从小到大的顺序递增,新事件的ID号比旧事件的ID号要大。
2)when:毫秒精度的UNX时间戳,记录了时间事件的到达( arrive)时间。
3)timeProc:时问事件处理器,一个函数,当时间事件到达时,服务器就会调用相应的处理器来处理事件。
目前版本的 Redis只使用周期性事件 ,而没有使用定时事件
时间事件的底层实现:
服务器将所有时间事件都放在一个无序链表中,每当时间事件执行器运行时,它就遍历整个链表,查找所有已到达的时间事件 ,并调用相应的事件处理器。
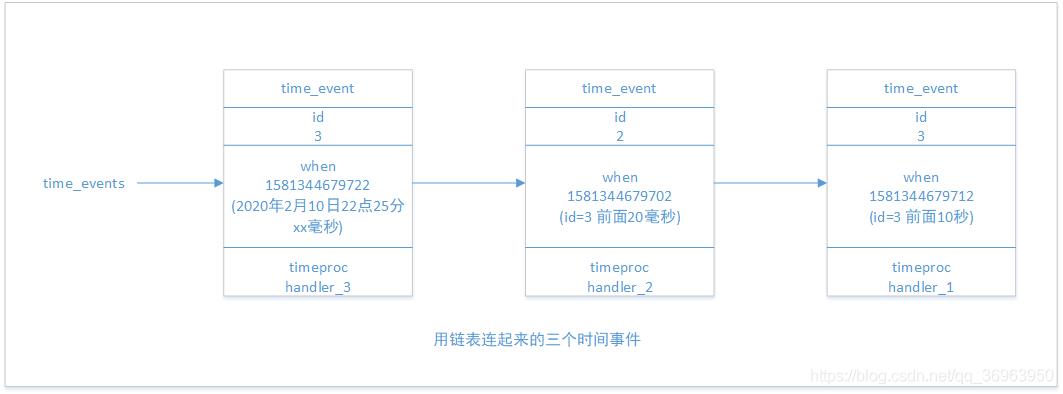
上图展示了一个保存时间事件的链表的例子,链表中包含了三个不同的时间事件因为新的时间事件总是插入到链表的表头,所以三个时间事件分别按ID逆序排序,表头事件的ID为3.中间事件的ID为2,表尾事件的ID为1。
注意,我们说保存时间事件的链表为无序链表,指的不是链表不按ID排序,而是说该链表不按when属性的大小排序。正因为链表没有按when属性进行排序,所以当时间事件执行器运行的时候,它必须遍历链表中的所有时间事件 ,这样才能确保服务器中所有已到达的时间事件都会被处理。
5.3 事件的调度与执行(文件事件+时间事件)
因为服务器中同时存在文件事件和时间事件两种事件类型,所以服务器必须对两种事件进行调度,决定何时应该处理文件事件 ,何时又应该处理时间事件,以及花多少时间来理它们等等。给出伪代码(要和下面的图及其解释对应着看):
def aeProcessEvents():
# 获取到达时间离当前时间最接近的时间事件
time_event = aeSearchNearestTimer()
# 计算最接近的时间事件距离到达还有多少毫秒
remaind_ms = time_event.when - unix_ts_now()
# 如果事件已到达,那么remaind_ms的值可能是负数,将其设置为0
if remaind_ms < 0
remaind_ms = 0
# 根据remaind_ms的值,创建timeval结构
timeval = create_timeval_with_ms(remaind_ms)
# 阻塞并等待文件事件产生,最大阻塞时间由传入的timeval结构决定
# 如果remaind_ms的值为0,那么asApiPoll调用之后马上返回,不阻塞
setApiPoll(timeval)
# 处理所有已产生的文件事件
processFileEvents()
# 处理所有已产生的时间事件
processTimeEvents()
从事件处理的角度来看,Redis服务器的运行流程如下:
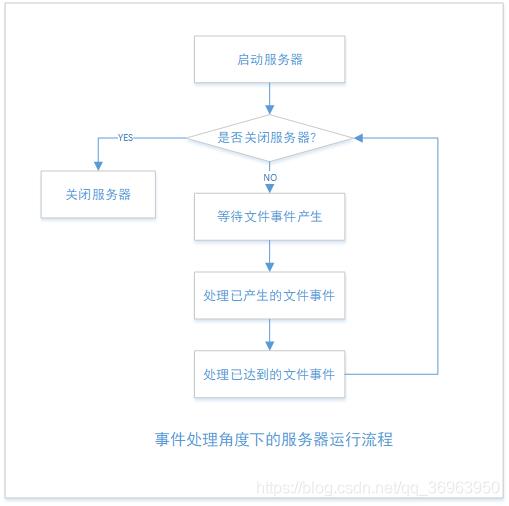
对于上图解释:
1)aeApipo11函数的最大阻塞时间由到达时间最接近当前时间的时间事件决定,这个方法既可以避免服务器对时间事件进行频繁的轮询(忙等待),也可以确保 aeApiPo 函数不会阻寒过长时间。
2)因为文件事件是随机出现的,如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将再次等待并处理文件事件。随着文件事件的不断执行,时间会逐渐向时间事件所设置时间逼近,并最终来到到达时间,这时服务器就可以开始处理到达的时间事件了。
3)对文件事件和时间事件的处理都是同步、有序、原子地执行的,服务器不会中途中断事件处理,也不会对事件进行抢占,因此,不管是文件事件的处理器,还是时间事件的处理器,它们都会尽可地减少程序的阻塞时间,并在有需要时主动让出执行权,从面降低造成事件饥饿的可能性。比如说,在命令回复处理器将一个命令回复写入到客户端套接字时,如果写入字节数超过了一个预设常量的话,命令回复处理器就会主动用 break跳出写入循环,将余下的数据留到下次再写;另外,时间事件也会将非常耗时的持久化操作放到子线程或者子进程执行。
4)因为时间事件在文件事件之后执行,并且事件之间不会出现抢占,所以时间事件的实际处理时间,通常会比时间事件设定的到达时间稍晚一些。
举例:一次完整的事件调度和执行过程
| 开始时间 | 结束时间 | 动作 |
|---|---|---|
| 0 | 10 | 创建一个在100毫秒到达的时间事件 |
| 11 | 30 | 等待文件事件 |
| 31 | 50 | 处理文件事件 |
| 51 | 85 | 等待文件事件 |
| 85 | 130 | 处理文件事件 |
| 131 | 150 | 执行时间事件 |
该表中记录的事件执行流程凸显了上面的时间调度规则2、3、4.
因为时间事件尚未到达,所以在处理时间事件之前,服务器已经等待并处理了两次文件事件。
因为处理事件的过程不会出现抢占,所以实际处理时间事件的时间比预定的100毫秒慢了30毫秒。
六、Redis集群
6.1 Redis集群与主从复制
问题1:单机Redis会有瓶颈,那你们是怎么解决这个瓶颈的?
回答1:集群(永远的永远,处理单机的性能瓶颈就是分布式集群架构,Redis也是这样)
解释:在Redis中,使用的集群的部署方式也就是Redis cluster,并且是主从同步读写分离,类似Mysql 的主从同步,Redis cluster 支撑 N 个 Redis master node,每个master node都可以挂载多个 slave node。这样整个 Redis 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master 节点就能存放更多的数据了。
问题2:为什么需要Redis集群主从架构、读写分离?
回答2:因为单机QPS是有上限的,而且Redis的特性就是必须支撑读高并发的,那你一台机器又读又写,无法承受住,但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。
问题3:集群的高可用怎么保证,集群的高并发如何保证?
回答3:
第一,Redis Sentinal 着眼于高可用:
支持主从同步,通过 Sentinal 哨兵来监控 Redis 主服务器的状态,在master宕机时会自动将slave提升为master,继续提供服务。在 Redis 集群中,sentinel 也会进行多个redis实例部署,sentinel 之间通过 Raft 协议来保证自身的高可用。
第二,Redis Cluster 着眼于扩展性:
在单个redis内存不足时,使用Cluster进行分片存储。Redis Cluster 的分片机制,在内部分为 16384 个 slot 插槽,这 16384 个slot 插槽,分布在所有 master 节点上,每个 master 节点负责一部分 slot。数据读写的时候,按 key 做 CRC16 来计算在哪个 slot,由哪个 master 进行处理。数据的冗余是通过 slave 节点来保障。
注意:分布式集群是解决高并发的手段,这是一条通用准则,后端微服务架构、redis集群、mysql集群都是这样.
问题4:主从复制怎样进行?
回答4:先全量再增量
(1) 新的slaver进来的时候用RDB冷备份做全量复制
你启动一台 slave 的时候,他会发送一个psync命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成RDB快照,还会把新的写请求都缓存在内存中,RDB文件生成后,master会将这个RDB发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
(2) 新数据使用AOF做增量复制
之后,一旦有新的数据进入,master就会同步到slaver,使用AOF热备份做增量复制,这个AOF持久化增量复制就像MySQL的Binlog一样,把日志增量同步给从服务就好了。
问题5:数据传输的时候断网了或者服务器挂了怎么办啊?
回答5:传输过程中有什么网络问题啥的,会自动重连的,并且连接之后会把缺少的数据补上的。
6.2 Redis集群选主
问题1:什么情况下要选主?
回答1:当主节点挂掉之后要选主。当主挂掉时,在从节点中根据一定策略选出新主,并调整其他从 slaveof 到新主。
问题2:如何选主,到底选哪个slave从节点作为master主节点?
回答2:Redis选主的策略简单来说有三个:
(1)相同条件下,slave 的 priority 设置的越小,优先级越高;
(2)相同条件下,slave 复制的数据越多,优先级越高;
(3)相同条件下,slave 的 runid 越小,优先级越高;
6.3 哨兵集群Sentinel
6.3.1 哨兵组件的四个功能
“哨兵集群Sentinel”:哨兵是一个一个的,通过哨兵来完成四个功能:集群监控(master宕机了就要选主)、消息通知、故障转移、配置中心,囊括所有哨兵的集群就是Sentinel。
哨兵组件的四个功能:
集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
消息通知:如果某个 Redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
6.3.2 哨兵必须用三个实例去保证自己的健壮性的
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并不能保证数据不丢失,但是可以保证集群的高可用。为什么必须要三个实例呢?我们先看看两个哨兵会咋样。
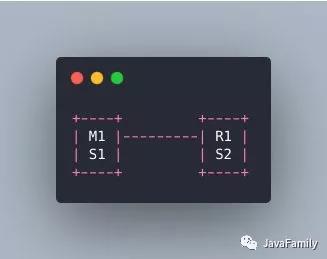
master宕机了 s1和s2两个哨兵只要有一个认为你宕机了就切换了,并且会选举出一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。那这样有啥问题呢?M1宕机了,S1没挂那其实是OK的,但是整个机器都挂了呢?哨兵就只剩下S2个裸屌了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。经典的哨兵集群是这样的:
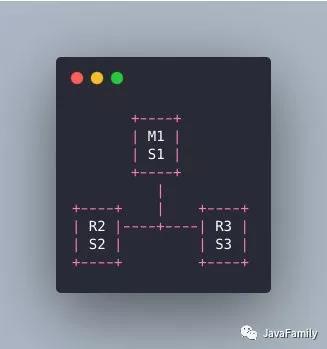
M1所在的机器挂了,哨兵还有两个,两个人一看他不是挂了嘛,那我们就选举一个出来执行故障转移不就好了。
七、尾声
Redis,性能加速的催化剂(三),完成了。
天天打码,天天进步!
以上是关于Redis,性能加速的催化剂的主要内容,如果未能解决你的问题,请参考以下文章