Python从入门到精通五万六千字对Python基础知识做一个了结吧!(二十八)值得收藏
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python从入门到精通五万六千字对Python基础知识做一个了结吧!(二十八)值得收藏相关的知识,希望对你有一定的参考价值。
为什么写这篇文章
我从2021年6月13号写下第一篇Python的系列专栏算起,陆续更新了二十七篇Python系列文章。在此感谢读者朋友们的支持和阅读,特别感谢一键三连的小伙伴。
本专栏起名【Python从入门到精通】,主要分为基础知识和项目实战两个部分,目前基础知识部分已经完全介绍完毕。下一阶段就是写Python项目实战以及爬虫相关的知识点。
为了对前期学习的Python基础知识做一个总结归纳,以帮助读者朋友们更好的学习下一部分的实战知识点,故在此我写下此文,共勉,同进。
同时为了方便大家交流学习,我这边还建立了一个Python的学习群。群里都是一群热爱学习的小伙伴,不乏一些牛逼的大佬。大佬带飞,我相信进入群里的小伙伴一定会走的更快,飞的更高。 欢迎扫码进群。

本专栏写了什么
下面就通过一个思维导图,展示本专栏Python基础知识部分的总览图。

本专栏从零基础出发,从环境的搭建到高级知识点的学习,一步步走来,相信各位读者朋友们早已掌握相关的知识点。接下来就做一个详细的回顾。
0.何为Python
Python是一门开源免费的,通用型的脚本编程语言。它需要在运行时将代码一行行解析成CPU能识别的机器码。它是一门解析型的语言,何为解析型语言呢?就是在运行时通过解析器将源代码一行行解析成机器码。而像C语言,C++等则是编译型的语言,即通过编译器将所有的源代码一次性编译成二进制指令,生成一个可执行的程序。解析型语言相对于编译型语言的好处就是天然具有跨平台的特点,一次编码,到处运行。
1. 开发环境配置
- 下载Python解释器
如同Java需要安装JDK 编译器一样,Python也需要安装解释器来运行Python程序。
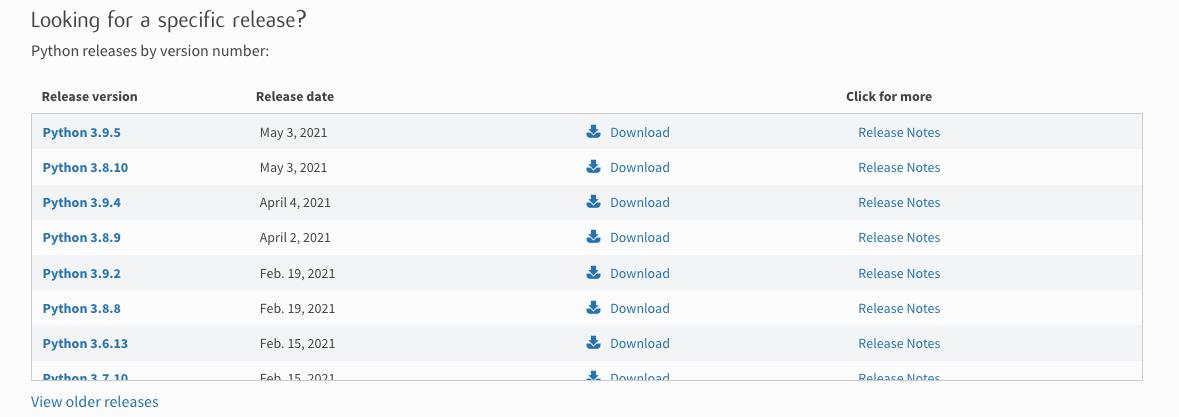
官方的下载网址是: https://www.python.org/downloads/,映入眼帘的是最新的发布版本,如果想下载其他版本的话,可以下来找到如下图所示的信息,当前的最新版本是 python 3.9.5 版本。根据你开发电脑的系统选择不同系统的安装包。

安装包下载之后双击运行进行安装。需要注意的是在Window下安装需要勾选 Add Python 3.8 to PATH,如下图1.2所示

安装完成之后在命令行中输入python3验证安装的结果,如果出现如下结果就表明安装Python编译器安装成功了。

详细内容可以查看【Python从入门到精通】(一)就简单看看Python吧
2. 工具安装
2.1. 安装PyCharm开发工具
工欲善其事必先利其器,在实际开发中我们都是通过IDE(集成开发环境)来进行编码,为啥要使用IDE呢?这是因为IDE集成了语言编辑器,自动建立工具,除错器等等工具可以极大方便我们快速的进行开发。打个比方 我们可以将集成开发环境想象成一个台式机。虽然只需要主机就能运行起来,但是,还是需要显示器,键盘等才能用的爽。
PyCharm就是这样一款让人用的很爽的IDE开发工具。下面就简单介绍一下它的安装过程
下载安装包
点击链接 https://www.jetbrains.com/pycharm/download/
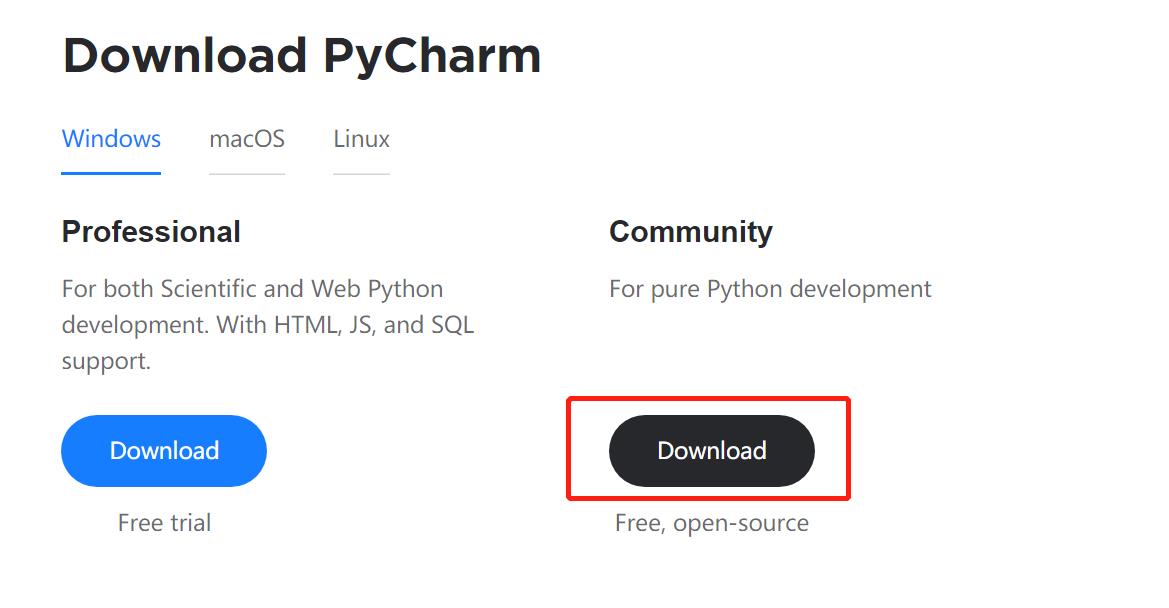
进入下来页面,PyCharm 有专业版和社区版。其中,专业版需要购买才能使用,而社区版是免费的。社区版对于日常的Python开发完全够用了。所以我们选择PyCharm的社区版进行下载安装。点击如下图所示的按钮进行安装包的下载。
安装
安装包下载好之后,我们双击安装包即可进行安装,安装过程比较简单,基本只需要安装默认的设置每一步点击Next按钮即可,不过当出现下图的窗口时需要设置一下。
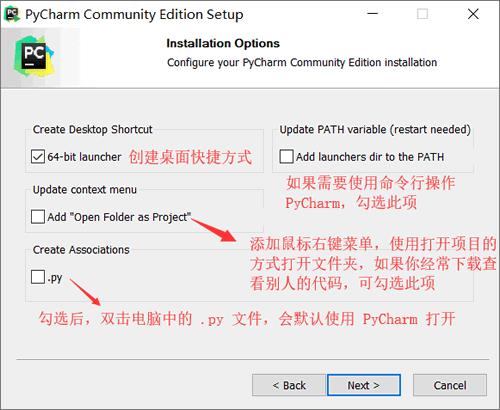
设置好之后点击 Next 进入下一步的安装,知道所有的安装都完成。
使用
这里使用只需要注意一点,就是设置解释器,默认的话在Project Interpreter的选择框中是提示的是 No interpreter,即没有选中解释器,所以,我们需要手动添加。
所以需要点击设置按钮设置解释器,这里选择 Add Local 设置本地的解释器。

打开解释器的设置页面之后,默认选中的是Virtualenv Environment 这个tab页,
这里Location是用来设置项目的虚拟环境,具体可以参考pycharm的使用小结,设置虚拟环境,更换镜像源
Base interpreter 用来设置解释器的路径。

至此,开发Python的脚手架已经弄好,接下来就是编码了。
如下创建了一个名为demo_1.py的文件,然后在文件中写入了如下几行代码
print("你好,世界")
a = 120
b = 230
print(a + b)
运行这些代码只需要简单的右键选中 Run ‘demo_1’ 或者 Debug ‘demo_1’ ,这两者的区别是Run demo_1是以普通模式运行代码,而 Debug ‘demo_1’ 是以调试模式运行代码。

运行结果就是:

详细内容可以查看【Python从入门到精通】(二)怎么运行Python呢?有哪些好的开发工具
3. 编码规范&注释
3.1.注释
首先介绍的是Python的注释,Python的注释分为两种:单行注释和多行注释。
- 单行注释
Python使用 # 号作为单行注释的符号,其语法格式为:#注释内容从#号开始直到这行结束为止的所有内容都是注释。例如:
# 这是单行注释
- 多行注释
多行注释指一次注释程序中多行的内容(包含一行) ,Python使用三个连续的 单引号’’’ 或者三个连续的双引号""" 注释多行内容。其语法格式是如下:
'''
三个连续的单引号的多行注释
注释多行内容
'''
或者
"""
三个连续的双引号的多行注释
注释多行内容
"""
多行注释通常用来为Python文件、模块、类或者函数等添加版权或者功能描述信息(即文档注释)
3.2.缩进规则
不同于其他编程语言(如Java,或者C)采用大括号{}分割代码块,Python采用代码缩进和冒号 : 来区分代码块之间的层次。如下面的代码所示:
a = -100
if a >= 0:
print("输出正数" + str(a))
print('测试')
else:
print("输出负数" + str(a))
其中第一行代码a = -100和第二行代码if a >= 0:是在同一作用域(也就是作用范围相同),所以这两行代码并排。而第三行代码print("输出正数" + str(a)) 的作用范围是在第二行代码里面,所以需要缩进。第五行代码也是同理。第二行代码通过冒号和第三行代码的缩进来区分这两个代码块。
Python的缩进量可以使用空格或者Tab键来实现缩进,通常情况下都是采用4个空格长度作为一个缩进量的。
这里需要注意的是同一个作用域的代码的缩进量要相同,不然会导致IndentationError异常错误,提示缩进量不对,如下面代码所示:第二行代码print("输出正数" + str(a)) 缩进了4个空格,而第三行代码print('测试')只缩进了2个空格。
if a >= 0:
print("输出正数" + str(a))
print('测试')
在Python中,对于类定义,函数定义,流程控制语句就像前面的if a>=0:,异常处理语句等,行尾的冒号和下一行缩进,表示下一个代码块的开始,而缩进的结束则表示此代码的结束。
详细内容可以查看【Python从入门到精通】(三)Python的编码规范,标识符知多少?
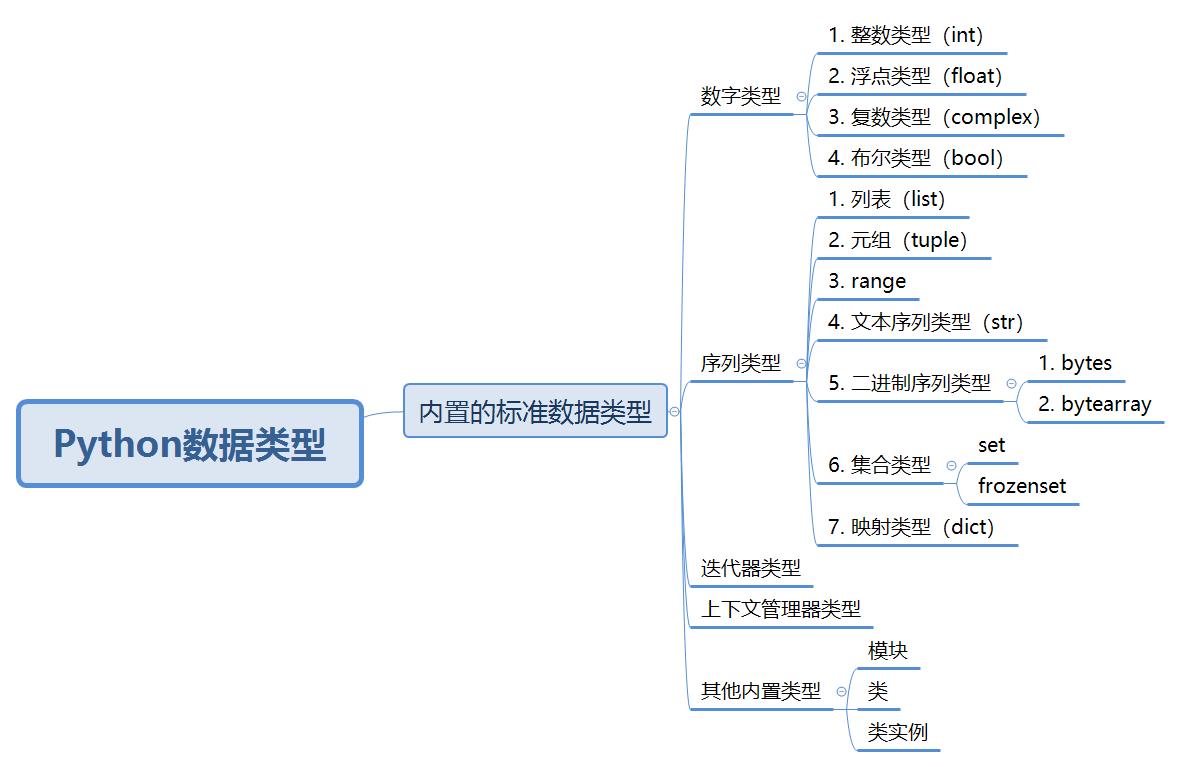
4. 数据类型
4.1.各种数据类型总览
4.2.整数(int)
Python3中的整数是不分类型,也就是说没有长整数类型(Long)或者短整数类型(short)之分,它的取值范围是是无限的,即不管多大或者多小的数字,Python都能轻松的应对。如下就是两个极大或者极小的整数。
>>> 100000-0000000000000000000000000000000000000000
1000000000000000000000000000000000000000000000
>>> print(-1000000000000000000000000000000000000000000000)
-1000000000000000000000000000000000000000000000
可以看出再大或者再小的数字都不会出现溢出的情况,这说明了Python对整数的处理能力非常强。
整数的不同进制
Python中可以用多种进制的来表示整数。
- 十进制形式
我们平时常见的整数就是十进制形式,它由 0~9 共十个数字排列组合而成。
注意,使用十进制形式的整数不能以 0 作为开头,除非这个数值本身就是 0。 - 二进制形式
由 0 和 1 两个数字组成,书写时以0b或0B开头。例如,1001对应十进制数是 9。 - 八进制形式
八进制整数由 0~7 共八个数字组成,以0o或0O开头。注意,第一个符号是数字 0,第二个符号是大写或小写的字母 O。 - 十六进制形式
由 0~9 十个数字以及 A~F(或 a~f)六个字母组成,书写时以0x或0X开头。
# 二进制
a=0b1001
print('a=',a)
# 八进制
b=0o207
print('b=',b)
# 十六进制
c=0x45
print('c=',c)
运行结果是:
a= 9
b= 135
c= 69
Python 3.x允许使用下划线_作为数字(包括整数和小数)的分隔符,通常每隔三个数字添加一个下划线,比如:click = 1_301_547
4.3. 浮点数/小数(float)
在编程语言中,小数通常以浮点数的形式存储,浮点数和定点数是相对的;小数在存储过程中如果小数点发生移动,就称为浮点数;如果小数点不动,就称为定点数。
小数的书写形式
Python中的小数有两种书写形式:
- 十进制形式
这就是我们经常看到的小数形式,比如101.1;234.5;0.23 - 指数形式
Python小数点指数形式的写法为:aEn或aen
a为尾数部分,是一个十进制,n为指数部分,是一个十进制,E或者e是固定的字符,用于分割尾数部分和指数部分,真的表达式是 a×10n。
举个栗子:
2.3E5=2.3x10的5次方
依然还举个栗子:
x=10.01
print('x=',x)
y=-0.031
print('y=',y)
z=2.3E10
print('z=',z)
w=-0.00000001
print('w=',w)
运行结果是:
x= 10.01
y= -0.031
z= 23000000000.0
w= -1e-08
4.4.布尔类型(bool)
布尔类型用来表示真(对)或假(错),比如常见的3>2 比较算式,这个是正确的,Python中使用True来代表;再比如2>3 比较算式,这个是错误的,用False来代表。
print(3>2)
print(2>3)
print('True==1的结果是:',True==1)
print('False==0的结果是:',False==0)
运行结果是:
True
False
True==1的结果是: True
False==0的结果是: True
详细内容可以查看【Python从入门到精通】(四)Python的内置数据类型有哪些呢?数字了解一下
5. 序列
序列(sequence)指的是一块可存放多个元素的内存空间,这些元素按照一定的顺序排列。每个元素都有自己的位置(索引),可以通过这些位置(索引)来找到指定的元素。如果将序列想象成一个酒店,那么酒店里的每个房间就相当于序列中的每个元素,房间的编号就相当于元素的索引,可以通过编号(索引)找到指定的房间(元素)。
5.1.有哪些序列类型呢?
了解完了序列的基本概念,那么在Python中一共有哪些序列类型呢?如下图所示:

从图中可以看出在Python中共有7种序列类型,分别是文本序列类型(str);二进制序列类型 bytes和bytearray;列表(list);元组(tuple);集合类型(set和frozenset);范围类型(range)以及字典类型(dict)。
5.2. 按照能存储的元素划分
按照能存储的元素可以将序列类型划分为两大类:分别是:容器序列和扁平序列
容器序列:即可容纳不同数据类型的元素的序列;有 list;tuple;set;dict
举个栗子:
list=['runoob',786,2.23,'john',70.2]
这里的list保存的元素有多种数据类型,既有字符串,也有小数和整数。
扁平序列:即只能容纳相同数据类型的元素的序列;有bytes;str;bytearray,以str为例,同一个str只能都存储字符。
5.2. 按照是否可变划分
按照序列是否可变,又可分为可变序列和不可变序列。
这里的可变的意思是:序列创建成功之后,还能不能进行修改操作,比如插入,修改等等,如果可以的话则是可变的序列,如果不可以的话则是不可变序列。
可变序列有列表( list);字典(dict)等,
不可变的序列有元祖(tuple),后面的文章会详细的对这些数据类型做详细介绍。
5.3. 序列的索引
在介绍序列概念的时候,说到了序列中元素的索引,那么什么是序列的索引呢?其实就是位置的下标。 如果对C语言中的数组有所了解的话,我们知道数组的索引下标都是从0开始依次递增的正数,即第一个元素的索引下标是0,第n个元素的索引下标是n-1。序列的索引也是同理,默认情况下都是从左向右记录索引,索引值从0开始递增,即第一个元素的元素的索引值是0,第n个元素的索引值是n-1。如下图所示:

当然与C语言中数组不同的是,Python还支持索引值是负数,该类的索引是从右向左计数。换句话说,就是从最后一个元素开始计数,从索引值-1开始递减,即第n个元素的索引值是-1,第1个元素的索引值是-n,如下图所示:

5.4.序列切片
切片操作是访问序列元素的另一种方式,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的序列。切片操作的语法格式是:
sname[start : end : step]
各个参数的含义分别是:
- sname: 表示序列的名称
- start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,不指定的情况下会默认为0,也就是从序列的开头开始切片。
- end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度。
- step: 表示步长,即在切片过程中,隔几个存储位置(包括当前位置)取一次元素,也就是说,如果step的值大于1,比如step为3时,则在切片取元素时,会隔2个位置去取下一个元素。
还是举个栗子说明下吧:
str1='好好学习,天天向上'
# 取出索引下标为7的值
print(str1[7])
# 从下标0开始取值,一直取到下标为7(不包括)的索引值
print(str1[0:7])
# 从下标1开始取值,一直取到下标为4(不包括)的索引值,因为step等于2,所以会隔1个元素取值
print(str1[1:4:2])
# 取出最后一个元素
print(str1[-1])
# 从下标-9开始取值,一直取到下标为-2(不包括)的索引值
print(str1[-9:-2])
运行的结果是:
向
好好学习,天天
好习
上
好好学习,天天
5.5.序列相加
Python支持类型相同的两个序列使用"+"运算符做想加操作,它会将两个序列进行连接,但是不会去除重复的元素,即只做一个简单的拼接。
str='他叫小明'
str1='他很聪明'
print(str+str1)
运行结果是:他叫小明他很聪明
5.6.序列相乘
Python支持使用数字n乘以一个序列,其会生成一个新的序列,新序列的内容是原序列被重复了n次的结果。
str2='你好呀'
print(str2*3)
运行结果是:你好呀你好呀你好呀 ,原序列的内容重复了3次。
5.7.检查元素是否包含在序列中
Python中可以使用in关键字检查某个元素是否为序列中的成员,其语法格式为:
value in sequence
其中,value表示要检查的元素,sequence表示指定的序列。
举个栗子:查找天字是否在字符串str1中。
str1='好好学习,天天向上'
print('天' in str1)
运行结果是:True
6. 字符串
*由若干个字符组成的集合就是一个字符串(str)**,Python中的字符串必须由双引号""或者单引号’'包围。其语法格式是:
"字符串内容"
'字符串内容'
如果字符串中包含了单引号需要做特殊处理。比如现在有这样一个字符串
str4='I'm a greate coder' 直接这样写有问题的。
处理的方式有两种:
- 对引号进行转义,通过转义符号
\\进行转义即可:
str4='I\\'m a greate coder'
- 使用不同的引号包围字符串
str4="I'm a greate coder"
这里外层用双引号,包裹字符串里的单引号。
6.1.字符串拼接
通过+运算符
现有字符串码农飞哥好,,要求将字符串码农飞哥牛逼拼接到其后面,生成新的字符串码农飞哥好,码农飞哥牛逼
举个例子:
str6 = '码农飞哥好,'
# 使用+ 运算符号
print('+运算符拼接的结果=',(str6 + '码农飞哥牛逼'))
运行结果是:
+运算符拼接的结果= 码农飞哥好,码农飞哥牛逼
6.2.字符串截取(字符串切片)
切片操作是访问字符串的另一种方式,它可以访问一定范围内的元素,通过切片操作,可以生成一个新的字符串。切片操作的语法格式是:
sname[start : end : step]
各个参数的含义分别是:
- sname: 表示字符串的名称
- start:表示切片的开始索引位置(包括该位置),此参数也可以不指定,不指定的情况下会默认为0,也就是从序列的开头开始切片。
- end:表示切片的结束索引位置(不包括该位置),如果不指定,则默认为序列的长度。
- step: 表示步长,即在切片过程中,隔几个存储位置(包括当前位置)取一次元素,也就是说,如果step的值大于1,比如step为3时,则在切片取元素时,会隔2个位置去取下一个元素。
还是举个栗子说明下吧:
str1='好好学习,天天向上'
# 取出索引下标为7的值
print(str1[7])
# 从下标0开始取值,一直取到下标为7(不包括)的索引值
print(str1[0:7])
# 从下标1开始取值,一直取到下标为4(不包括)的索引值,因为step等于2,所以会隔1个元素取值
print(str1[1:4:2])
# 取出最后一个元素
print(str1[-1])
# 从下标-9开始取值,一直取到下标为-2(不包括)的索引值
print(str1[-9:-2])
运行的结果是:
向
好好学习,天天
好习
上
好好学习,天天
6.3.分割字符串
Python提供了split()方法用于分割字符串,split() 方法可以实现将一个字符串按照指定的分隔符切分成多个子串,这些子串会被保存到列表中(不包含分隔符),作为方法的返回值反馈回来。该方法的基本语法格式如下:
str.split(sep,maxsplit)
此方法中各部分参数的含义分别是:
- str: 表示要进行分割的字符串
- sep: 用于指定分隔符,可以包含多个字符,此参数默认为None,表示所有空字符,包括空格,换行符"\\n"、制表符"\\t"等
- maxsplit: 可选参数,用于指定分割的次数,最后列表中子串的个数最多为maxsplit+1,如果不指定或者指定为-1,则表示分割次数没有限制。
在 split 方法中,如果不指定 sep 参数,那么也不能指定 maxsplit 参数。
举例说明下:
str = 'https://feige.blog.csdn.net/'
print('不指定分割次数', str.split('.'))
print('指定分割次数为2次',str.split('.',2))
运行结果是:
不指定分割次数 ['https://feige', 'blog', 'csdn', 'net/']
指定分割次数为2次 ['https://feige', 'blog', 'csdn.net/']
6.4.合并字符串
合并字符串与split的作用刚刚相反,Python提供了join() 方法来将列表(或元组)中包含的多个字符串连接成一个字符串。其语法结构是:
newstr = str.join(iterable)
此方法各部分的参数含义是:
- newstr: 表示合并后生成的新字符串
- str: 用于指定合并时的分隔符
- iterable: 做合并操作的源字符串数据,允许以列表、元组等形式提供。
依然是举例说明:
list = ['码农飞哥', '好好学习', '非常棒']
print('通过.来拼接', '.'.join(list))
print('通过-来拼接', '-'.join(list))
运行结果是:
通过.来拼接 码农飞哥.好好学习.非常棒
通过-来拼接 码农飞哥-好好学习-非常棒
6.5.检索字符串是否以指定字符串开头(startswith())
startswith()方法用于检索字符串是否以指定字符串开头,如果是返回True;反之返回False。其语法结构是:
str.startswith(sub[,start[,end]])
此方法各个参数的含义是:
- str: 表示原字符串
- sub: 要检索的子串‘
- start: 指定检索开始的起始位置索引,如果不指定,则默认从头开始检索
- end: 指定检索的结束位置索引,如果不指定,则默认一直检索到结束。
举个栗子说明下:
str1 = 'https://feige.blog.csdn.net/'
print('是否是以https开头', str1.startswith('https'))
print('是否是以feige开头', str1.startswith('feige', 0, 20))
运行结果是:
是否是以https开头 True
是否是以feige开头 False
6.6.检索字符串是否以指定字符串结尾(endswith())
endswith()方法用于检索字符串是否以指定字符串结尾,如果是则返回True,反之则返回False。其语法结构是:
str.endswith(sub[,start[,end]])
此方法各个参数的含义与startswith方法相同,再此就不在赘述了。
6.7.字符串大小写转换(3种)函数及用法
Python中提供了3种方法用于字符串大小写转换
- title()方法用于将字符串中每个单词的首字母转成大写,其他字母全部转为小写。转换完成后,此方法会返回转换得到的字符串。如果字符串中没有需要被转换的字符,此方法会将字符串原封不动地返回。其语法结构是
str.title() - lower()用于将字符串中的所有大写字母转换成小写字母,转换完成后,该方法会返回新得到的子串。如果字符串中原本就都是小写字母,则该方法会返回原字符串。 其语法结构是
str.lower() - upper()用于将字符串中的所有小写字母转换成大写字母,如果转换成功,则返回新字符串;反之,则返回原字符串。其语法结构是:
str.upper()。
举例说明下吧:
str = 'feiGe勇敢飞'
print('首字母大写', str.title())
print('全部小写', str.lower())
print('全部大写', str.upper())
运行结果是:
首字母大写 Feige勇敢飞
全部小写 feige勇敢飞
全部大写 FEIGE勇敢飞
6.8.去除字符串中空格(删除特殊字符)的3种方法
Python中提供了三种方法去除字符串中空格(删除特殊字符)的3种方法,这里的特殊字符,指的是指表符(\\t)、回车符(\\r),换行符(\\n)等。
- strip(): 删除字符串前后(左右两侧)的空格或特殊字符
- lstrip():删除字符串前面(左边)的空格或特殊字符
- rstrip():删除字符串后面(右边)的空格或特殊字符
Python的str是不可变的,因此这三个方法只是返回字符串前面或者后面空白被删除之后的副本,并不会改变字符串本身
举个例子说明下:
str = '\\n码农飞哥勇敢飞 '
print('去除前后空格(特殊字符串)', str.strip())
print('去除左边空格(特殊字符串)', str.lstrip())
print('去除右边空格(特殊字符串)', str.rstrip())
运行结果是:
去除前后空格(特殊字符串) 码农飞哥勇敢飞
去除左边空格(特殊字符串) 码农飞哥勇敢飞
去除右边空格(特殊字符串)
码农飞哥勇敢飞
6.9.encode()和decode()方法:字符串编码转换
最早的字符串编码是ASCll编码,它仅仅对10个数字,26个大小写英文字母以及一些特殊字符进行了编码,ASCII码最多只能表示256个字符,每个字符只需要占用1个字节。为了兼容各国的文字,相继出现了GBK,GB2312,UTF-8编码等,UTF-8是国际通用的编码格式,它包含了全世界所有国家需要用到的字符,其规定英文字符占用1个字节,中文字符占用3个字节。
- encode() 方法为字符串类型(str)提供的方法,用于将 str 类型转换成 bytes 类型,这个过程也称为“编码”。其语法结构是:
str.encode([encoding="utf-8"][,errors="strict"]) - 将bytes类型的二进制数据转换成str类型。这个过程也称为"解码",其语法结构是:
bytes.decode([encoding="utf-8"][,errors="strict"])
举个例子说明下:
str = '码农飞哥加油'
bytes = str.encode()
print('编码', bytes)
print('解码', bytes.decode())
运行结果是:
编码 b'\\xe7\\xa0\\x81\\xe5\\x86\\x9c\\xe9\\xa3\\x9e\\xe5\\x93\\xa5\\xe5\\x8a\\xa0\\xe6\\xb2\\xb9'
解码 码农飞哥加油
默认的编码格式是UTF-8,编码和解码的格式要相同,不然会解码失败。
6.9.序列化和反序列化
在实际工作中我们经常要将一个数据对象序列化成字符串,也会将一个字符串反序列化成一个数据对象。Python自带的序列化模块是json模块。
- json.dumps() 方法是将Python对象转成字符串
- json.loads()方法是将已编码的 JSON 字符串解码为 Python 对象
举个例子说明下:
import json
dict = {'学号': 1001, 'name': "张三", 'score': [{'语文': 90, '数学': 100}]}
str = json.dumps(dict,ensure_ascii=False)
print('序列化成字符串', str, type(str))
dict2 = json.loads(str)
print('反序列化成对象', dict2, type(dict2))
运行结果是:
序列化成字符串 {"name": "张三", "score": [{"数学": 100, "语文": 90}], "学号": 1001} <class 'str'>
反序列化成对象 {'name': '张三', 'score': [{'数学': 100, '语文': 90}], '学号': 1001} <class 'dict'>
详细内容可以查看
【Python从入门到精通】(五)Python内置的数据类型-序列和字符串,没有女友,不是保姆,只有拿来就能用的干货
【Python从入门到精通】(九)Python中字符串的各种骚操作你已经烂熟于心了么?【收藏下来就挺好的】
7. 列表&元组
7.1.列表(list)的介绍
列表作为Python序列类型中的一种,其也是用于存储多个元素的一块内存空间,这些元素按照一定的顺序排列。其数据结构是:
[element1, element2, element3, ..., elementn]
element1~elementn表示列表中的元素,元素的数据格式没有限制,只要是Python支持的数据格式都可以往里面方。同时因为列表支持自动扩容,所以它可变序列,即可以动态的修改列表,即可以修改,新增,删除列表元素。看个爽图吧!
7.2.列表的操作
首先介绍的是对列表的操作:包括列表的创建,列表的删除等!其中创建一个列表的方式有两种:
第一种方式:
通过[]包裹列表中的元素,每个元素之间通过逗号,分割。元素类型不限并且同一列表中的每个元素的类型可以不相同,但是不建议这样做,因为如果每个元素的数据类型都不同的话则非常不方便对列表进行遍历解析。所以建议一个列表只存同一种类型的元素。
list=[element1, element2, element3, ..., elementn]
例如:test_list = ['测试', 2, ['码农飞哥', '小伟'], (12, 23)]
PS: 空列表的定义是list=[]
第二种方式:
通过list(iterable)函数来创建列表,list函数是Python内置的函数。该函数传入的参数必须是可迭代的序列,比如字符串,列表,元组等等,如果iterable传入为空,则会创建一个空的列表。iterable不能只传一个数字。
classmates1 = list('码农飞哥')
print(classmates1)
生成的列表是:['码', '农', '飞', '哥']
7.3. 向列表中新增元素
向列表中新增元素的方法有四种,分别是:
第一种: 使用**+运算符将多个列表**连接起来。相当于在第一个列表的末尾添加上另一个列表。其语法格式是listname1+listname2
name_list = ['码农飞哥', '小伟', '小小伟']
name_list2 = ['python', 'java']
print(name_list + name_list2)
输出结果是:['码农飞哥', '小伟', '小小伟', 'python', 'java'],可以看出将name_list2中的每个元素都添加到了name_list的末尾。
第二种:使用append()方法添加元素
append()方法用于向列表末尾添加元素,其语法格式是:listname.append(p_object)其中listname表示要添加元素的列表,p_object表示要添加到列表末尾的元素,可以是字符串,数字,也可以是一个序列。举个栗子:
name_list.append('Adam')
print(name_list)
name_list.append(['test', 'test1'])
print(name_list)
运行结果是:
['码农飞哥', '小伟', '小小伟', 'Adam']
['码农飞哥', '小伟', '小小伟', 'Adam', ['test', 'test1']]
可以看出待添加的元素都成功的添加到了原列表的末尾处。并且当添加的元素是一个序列时,则会将该序列当成一个整体。 以上是关于Python从入门到精通五万六千字对Python基础知识做一个了结吧!(二十八)值得收藏的主要内容,如果未能解决你的问题,请参考以下文章
第三种:使用extend()方法
extend()方法跟append()方法的用法相同,同样是向列表末尾添加元素。元素的类型只需要Python支持的数据类型即可。不过与append()方法不同的是,当添加的元素是序列时