week 2——Linear Regression
Posted ^_^|
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了week 2——Linear Regression相关的知识,希望对你有一定的参考价值。
对数据表示做一些规定
x j ( i ) = v a l u e o f f e a t u r e j i n t h e i t h t r a i n i n g e x a m p l e x i = t h e i n p u t ( f e a t u r e ) o f t h e i t h t r a i n i n g e x a m p l e m = t h e n u m b e r o f t r a i n i n g e x a m p l e s n = t h e n u m b e r o f f e a t u r e s x_j^{(i)} = value\\ of\\ feature\\ j\\ in\\ the\\ i^{th}\\ training\\ example \\\\ x^{i} = the\\ input\\ (feature)\\ of\\ the\\ i^{th}\\ training\\ example \\\\ m = the\\ number\\ of\\ training\\ examples \\\\ n = the\\ number\\ of\\ features \\\\ xj(i)=value of feature j in the ith training examplexi=the input (feature) of the ith training examplem=the number of training examplesn=the number of features
预测函数,损失函数表示
h
y
p
o
t
h
e
s
i
s
f
u
n
c
t
i
o
n
:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
hypothesis \\ function:\\ h_{\\theta}(x) = \\theta_0+ \\theta_1x_1+ \\theta_2x_2+\\cdots+ \\theta_nx_n
hypothesis function: hθ(x)=θ0+θ1x1+θ2x2+⋯+θnxn
c
o
s
t
f
u
n
c
t
i
o
n
:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
cost \\ function: \\ J(\\theta) = \\frac{1}{2m}\\sum\\limits_{i=1}^{m}(h_\\theta(x_i)-y_i)^2
cost function: J(θ)=2m1i=1∑m(hθ(xi)−yi)2
梯度下降法
repeat until convergence:{
θ
j
=
θ
j
−
α
∂
J
(
θ
)
∂
θ
j
=
θ
j
−
α
1
m
∑
i
=
1
m
(
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
)
\\\\ \\theta_j = \\theta_j - \\alpha\\frac{\\partial J(\\theta)}{\\partial\\theta_j} = \\theta_j - \\alpha\\frac{1}{m}\\sum\\limits_{i=1}^{m}((h_\\theta(x^{(i)}) - y^{(i)})x_j^{(i)})
θj=θj−α∂θj∂J(θ)=θj−αm1i=1∑m((hθ(x(i))−y(i))xj(i))
}
数据归一化
x − μ σ \\frac{x-\\mu}{\\sigma} σx−μ
正规方程法
θ = ( X T X ) − 1 X T y \\theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy
梯度下降法和正规方程法对比

matlab下演练
假设有数据特征矩阵X为47 × \\times × 2表示47个样本,2个特征。同时y表示结果矩阵,大小为为47 × \\times × 1。 θ \\theta θ 初始化为47 × \\times × 1的全零向量。
- 首先,一般会为其增加全1列(即
h
(
θ
)
=
w
0
+
x
1
w
1
+
x
2
w
2
h(\\theta) = w_0+x_1w_1+x_2w_2
h(θ)=w0+x1w1+x2w2 一般为
w
0
w_0
w0 补充
x
0
x_0
x0 为1)
X = [ones(m, 1) X]; - 归一化
mu = mean(X);
sigma = std(X);
X_norm = (X - mu)./sigma; - 计算损失函数
J = sum((X* theta - y).^2)/(2*m); - 梯度下降
for iter = 1:num_iters:
theta = theta - alpha * (X’((Xtheta) - y)) / m;
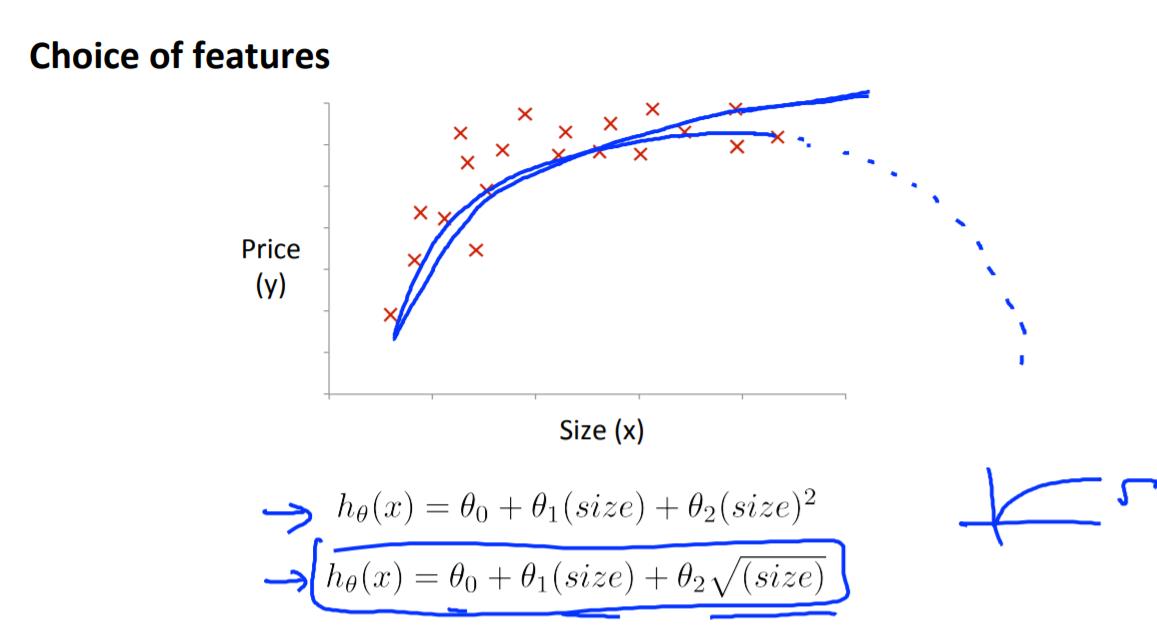
非线性化
以上是关于week 2——Linear Regression的主要内容,如果未能解决你的问题,请参考以下文章