pandas使用cut函数基于分位数进行连续值分箱(手动计算分位数)处理后出现NaN值原因及解决
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas使用cut函数基于分位数进行连续值分箱(手动计算分位数)处理后出现NaN值原因及解决相关的知识,希望对你有一定的参考价值。
pandas使用cut函数基于分位数进行连续值分箱(手动计算分位数)处理后出现NaN值原因及解决
目录
pandas使用cut函数基于分位数进行连续值分箱(手动计算分位数)处理后出现NaN值原因及解决
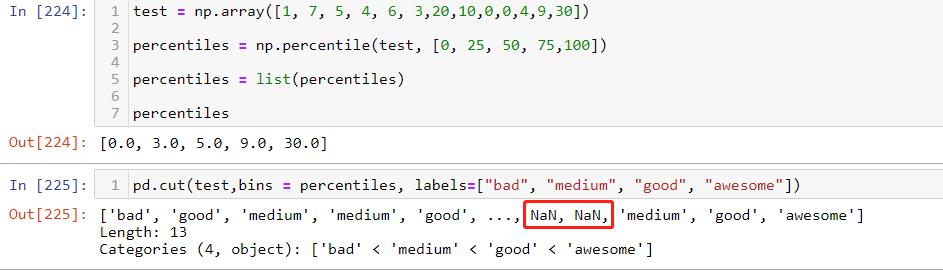
['bad', 'good', 'medium', 'medium', 'good', ..., NaN, NaN, 'medium', 'good', 'awesome'] Length: 13 Categories (4, object): ['bad' < 'medium' < 'good' < 'awesome']
问题:
test = np.array([1, 7, 5, 4, 6, 3,20,10,0,0,4,9,30])
percentiles = np.percentile(test, [0, 25, 50, 75,100])
percentiles = list(percentiles)
percentiles
pd.cut(test,bins = percentiles, labels=["bad", "medium", "good", "awesome"])[0.0, 3.0, 5.0, 9.0, 30.0]
['bad', 'good', 'medium', 'medium', 'good', ..., NaN, NaN, 'medium', 'good', 'awesome']
Length: 13
Categories (4, object): ['bad' < 'medium' < 'good' < 'awesome']
解决:
#include_lowest = True
#include_lowest = True
test = np.array([1, 7, 5, 4, 6, 3,20,10,0,0,4,9,30])
percentiles = np.percentile(test, [0, 25, 50, 75,100])
percentiles = list(percentiles)
percentiles
pd.cut(test,bins = percentiles, labels=["bad", "medium", "good", "awesome"],include_lowest = True)[0.0, 3.0, 5.0, 9.0, 30.0]
['bad', 'good', 'medium', 'medium', 'good', ..., 'bad', 'bad', 'medium', 'good', 'awesome']
Length: 13
Categories (4, object): ['bad' < 'medium' < 'good' < 'awesome']
参考:python
参考:pandas
以上是关于pandas使用cut函数基于分位数进行连续值分箱(手动计算分位数)处理后出现NaN值原因及解决的主要内容,如果未能解决你的问题,请参考以下文章