论文泛读 Deep Learning 论文合集
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读 Deep Learning 论文合集相关的知识,希望对你有一定的参考价值。
【论文泛读】 Deep Learning 论文合集
文章目录
- 【论文泛读】 Deep Learning 论文合集
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- ImageNet Classification with Deep Convolutional Neural Networks
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- Going deeper with convolutions
- Deep Residual Learning for Image Recognition
- Densely Connected Convolutional Networks
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- You Only Look Once: Unified, Real-Time Object Detection
- YOLO9000: Better, Faster, Stronge
- YOLOv3: An Incremental Improvement
这个是一个汇总篇,记录了我已读论文的一些笔记,详细还得看论文和里面的笔记。
一些计算机视觉的顶会:
- IEEE Conference on Computer Vision and Pattern Recognition(CVPR):IEEE国际计算机视觉与模式识别会议
- Conference and Workshop on Neural Information Processing Systems(NIPS):神经信息处理系统大会
- IEEE International Conference on Computer Vision(ICCV):国际计算机视觉大会
- European Conference on Computer Vision(ECCV):欧洲计算机视觉国际会议
计算机视觉三大会议分别是CVPR,ICCV和ECCV
(空的有些还在整理中)
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
CVPR’15
问题
- 训练深度神经网络的复杂性在于,每层输入的分布在训练过程中会发生变化,因为前面的层的参数会发生变化。通过要求较低的学习率和仔细的参数初始化减慢了训练,并且使具有饱和非线性的模型训练起来非常困难,这种现象称为 Internal Covariate Shift
方法
- 基于 Internal Covariate Shift ,提出了一个新的机制,大大加快了深度网络的训练,通过加BN层,对输出进行Batch Normalization。BN每个激活只增加了两个额外的参数,这样做可以保持网络的表示能力。

结论
- 不仅仅提高了训练的速度,同时也使得收敛速度大大加快。
- 使得调参变得更简单了,比如说可以使用更高的学习率,更简单的初始化
- 提高了模型的泛化能力,类似与Dropout的效果,可以防止过拟合。
在使用BN的时候,也需要注意几个点
-
batch size尽可能设置大点,设置小后表现可能没那么好,设置的越大求的均值和方差越接近整个训练集的均值和方差。这个我觉得可以利用大数定律来进行一个证明。
-
我们的BN层可以放在卷积层(Conv)和激活层(如ReLU)之间,并且我们的卷积层可以去掉bias,因为是没有用的,在前面也已经推导过的。
-
BN和dropout不要同时用,BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
参考
原论文地址:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
我的笔记地址:【论文泛读】 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ImageNet Classification with Deep Convolutional Neural Networks
NIPS’12
问题
方法
结论
参考
原论文地址:ImageNet Classification with Deep Convolutional Neural Networks
我的笔记地址:更新中
Very Deep Convolutional Networks for Large-Scale Image Recognition
CVPR’15
问题
方法
结论
参考
原论文地址:Very Deep Convolutional Networks for Large-Scale Image Recognition
我的笔记地址:更新中
Going deeper with convolutions
CVPR’14
问题
-
深度学习以及神经网络快速发展,人们不再只关注更给力的硬件、更大的数据集、更大的模型,而是更在意新的idea、新的算法以及模型的改进。
-
如果想要提高神经网络的性能,最直接的想法就是加深神经网络的深度和宽度,增加它的层数,提高每一层的神经元的个数
但是这种做法有两个缺陷
- 更大的尺寸意味着更大的参数,这样会使增大的网络更容易过拟合,特别是训练集的样本比较少的时候。
- 更大的网络尺寸会增大计算量,耗费大量的计算资源
方法
-
在ImageNet大规模视觉识别挑战赛2014(ILSVRC14)上提出了一种代号为Inception的深度卷积神经网络结构,并在分类和检测上取得了新的最好结果。
-
提出了Inception模型,在模型中,用了1x1,3x3,5x5的卷积层,这是为了方便,而不是必要的,因为用这样的模型,我们在块填充padding的时候会比较方便而不需要考虑太多的操作。
-
并且对于Inception来说,它与VGG的不同在于,VGG是串行的网络层,Inception是并行的网络层,用不同尺寸的卷积层可以用来提取不同尺度特征

结论
- GoogLeNet是2014 ILSVRC 比赛的冠军,并且提高了网络内部计算资源的利用率,比AlexNet的参数少了12倍
参考
原论文地址:Going deeper with convolutions
我的笔记地址:【论文泛读】 GooLeNet:更深的卷积网络
Deep Residual Learning for Image Recognition
CVPR‘16 2016年的Best Paper
问题
- 好的网络不是靠堆叠更多的层就可以实现的
堆叠网络的缺点:
-
网络难以收敛,梯度消失/爆炸在一开始就阻碍网络的收敛。
传统解决办法:
通过适当权重初始化+Batch Normalization 就可以很大程度上解决,这使得数十层的网络能通过具有反向传播的随机梯度下降(SGD)开始收敛。 -
出现退化问题(degradation problem):随着网络深度的增加,准确率达到饱和(这可能并不奇怪)然后迅速下降。意外的是,这种下降不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差
方法
-
由于这个退化问题,作者就进行了一个思考:假设我们训练了一个浅层网络,那么在其后面直接添加多层恒等映射层(本身)而构成的一个深层网络,那这个深层网络最起码也不能比浅层网络差。我们这样做了以后,起码我们加深模型至少不会使得模型变得更差,这样我们就可以加深我们的深度。
-
为了解决我们的退化问题,我们提出了一个残差结构
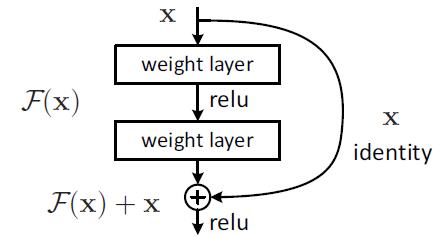
-
在过去的网络结构中,我们会去拟合我们的期望的底层映射 H ( x ) H(x) H(x),但是对于我们的是拟合我们的残差 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x
-
这样我们最后得到的映射是 F ( x ) + x F(x)+x F(x)+x,我们假设残差的映射比原来的更容易优化。在极端情况下,如果一个恒等映射是最优的,那么将残差置为零比通过一堆非线性层来拟合恒等映射更容易。 并且对于我们来说,我们多加一个捷径连接(shortcut connections),在下面这种情况下,我们是用恒等映射就是自己本身,这样既不增加额外的参数也不增加计算复杂度。(默认加法不会影响太大的复杂度)这样我们的网络还是可以用带有反向传播的SGD进行我们的训练
结论
- 在ResNet网络中有如下几个亮点:
(1)提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
(2)使用Batch Normalization加速训练(丢弃dropout)
- 在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
(1)梯度消失或梯度爆炸。
(2)退化问题(degradation problem)。
在ResNet论文中说通过数据的预处理以及在网络中使用BN(Batch Normalization)层能够解决梯度消失或者梯度爆炸问题,residual结构(残差结构)来减轻退化问题。此时拟合目标就变为F(x),F(x)就是残差。
参考
原论文地址:Deep Residual Learning for Image Recognition (arxiv.org)
我的笔记地址:【论文泛读】 ResNet:深度残差网络
Densely Connected Convolutional Networks
CVPR‘17 2017年的Best Paper
问题
- 研究表明,如果在靠近输入层与输出层之间的地方使用短连接(shorter connections),就可以训练更深、更准确、更有效的卷积网络。
方法
-
在这篇论文中,作者提出了一个结构:为了保证最大信息流在层与层之间的传递,将所有层(使用合适的特征图尺寸)都进行互相连接。为了能够保证前馈的特性,每一层将之前所有层的输入进行拼接,之后将输出的特征图传递给之后的所有层。
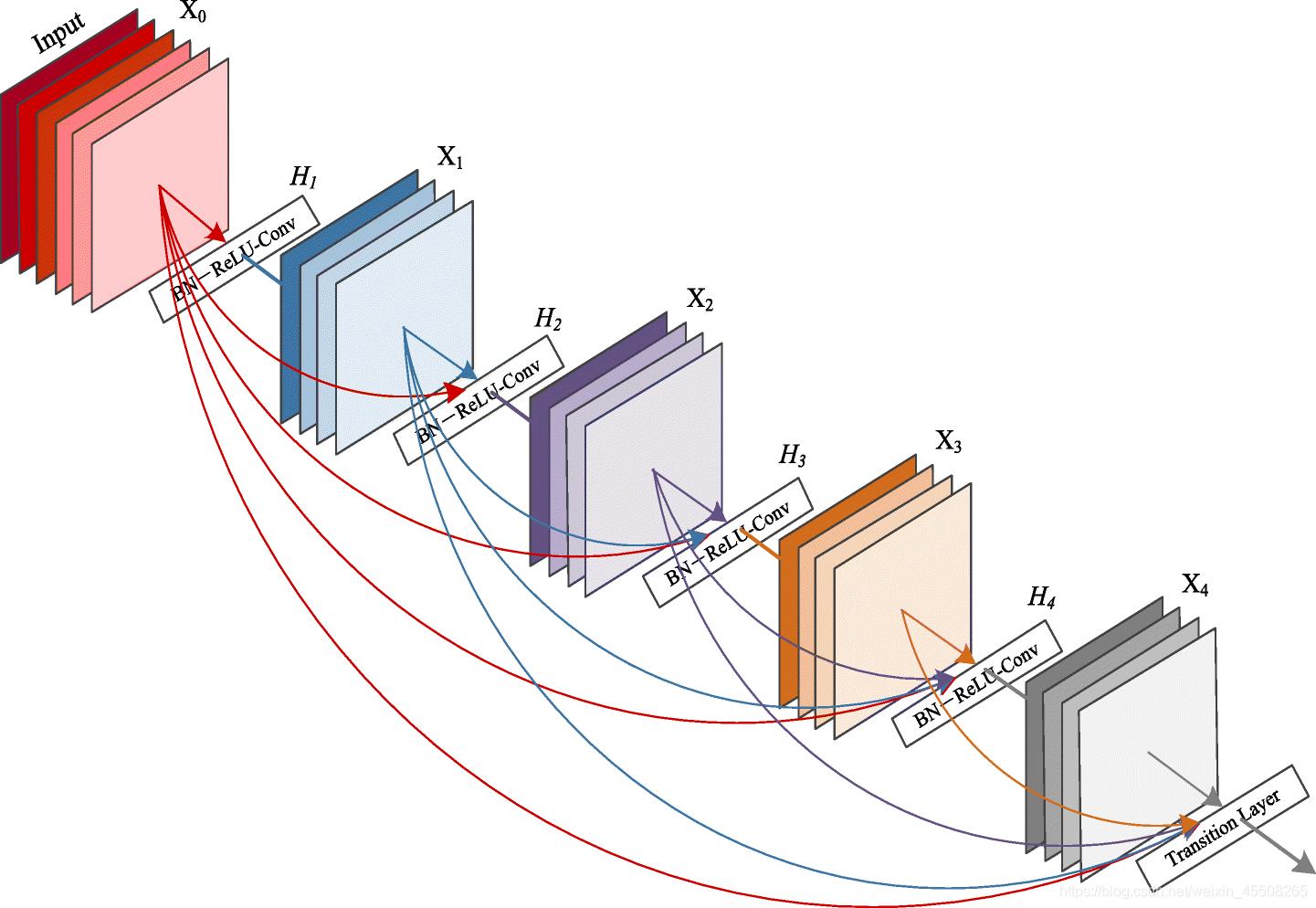
-
与ResNet相反的是,作者并没有将特征传递给某一层之前将其进行相加(combine),而是将其进行拼接(concatenate)。因此,第 l l l 层有 l l l 个输出,这些输出是该层之前所有的卷积块(block)的特征图,而它自己的特征图则传递给之后的所有 而它自己的特征图则传递给之后的所有 L − 1 L-1 L−1 层,所以一个 L L L 层的网络就有 L ( L + 1 ) 2 \\frac{L(L+1)}{2} 2L(L+1) (其实就是 C n + 1 2 C_{n+1}^{2} Cn+12)个连接,而不是像传统的结构仅仅有 L L L 个连接。由于它的稠密连接模块,所以我们更喜欢把这个方法称为稠密卷积网络(DenseNets)。
结论
-
DenseNet作为另一种拥有较深层数的卷积神经网络,具有如下优点:
(1) 相比ResNet拥有更少的参数数量.
(2) 旁路加强了特征的重用.
(3) 网络更易于训练,并具有一定的正则效果.
(4) 缓解了gradient vanishing和model degradation的问题.
参考
原论文地址: Densely Connected Convolutional Networks (arxiv.org)
我的笔记地址:【论文泛读】 DenseNet:稠密连接的卷积网络
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
NIPS’15/CVPR’16
问题
- 当时最新的检测网络都依赖区域推荐算法来推测物体位置。像SPPnet和Fast R-CNN已经大幅削减了检测网络的时间开销,但区域推荐的计算却变成了瓶颈。
方法
-
本论文将引入一个区域推荐网络(RPN)和检测网络共享全图像卷积特征,使得区域推荐的开销几近为0。一个RPN是一个全卷积网络技能预测物体的边框,同时也能对该位置进行物体打分。RPN通过端到端的训练可以产生高质量的推荐区域,然后再用Fast R-CNN进行检测。通过共享卷积特征,我们进一步整合RPN和Fast R-CNN到一个网络,用近期流行的“术语”说,就是一种“注意力”机制。RPN组件会告诉整合网络去看哪个部分。
-
Faster R-CNN有两个模块组成,整个网络是一个单一、通以的目标检测网络。
- 第一个模块是深度卷积网络用于生成推荐区域
- 第二个模块是Fast R-CNN用来推荐的区域的检测器
其实又可以细分为四个部分,Conv Layer,Region Proposal Network(RPN),RoI Pooling,Classification and Regression,就如下面论文中的图一样
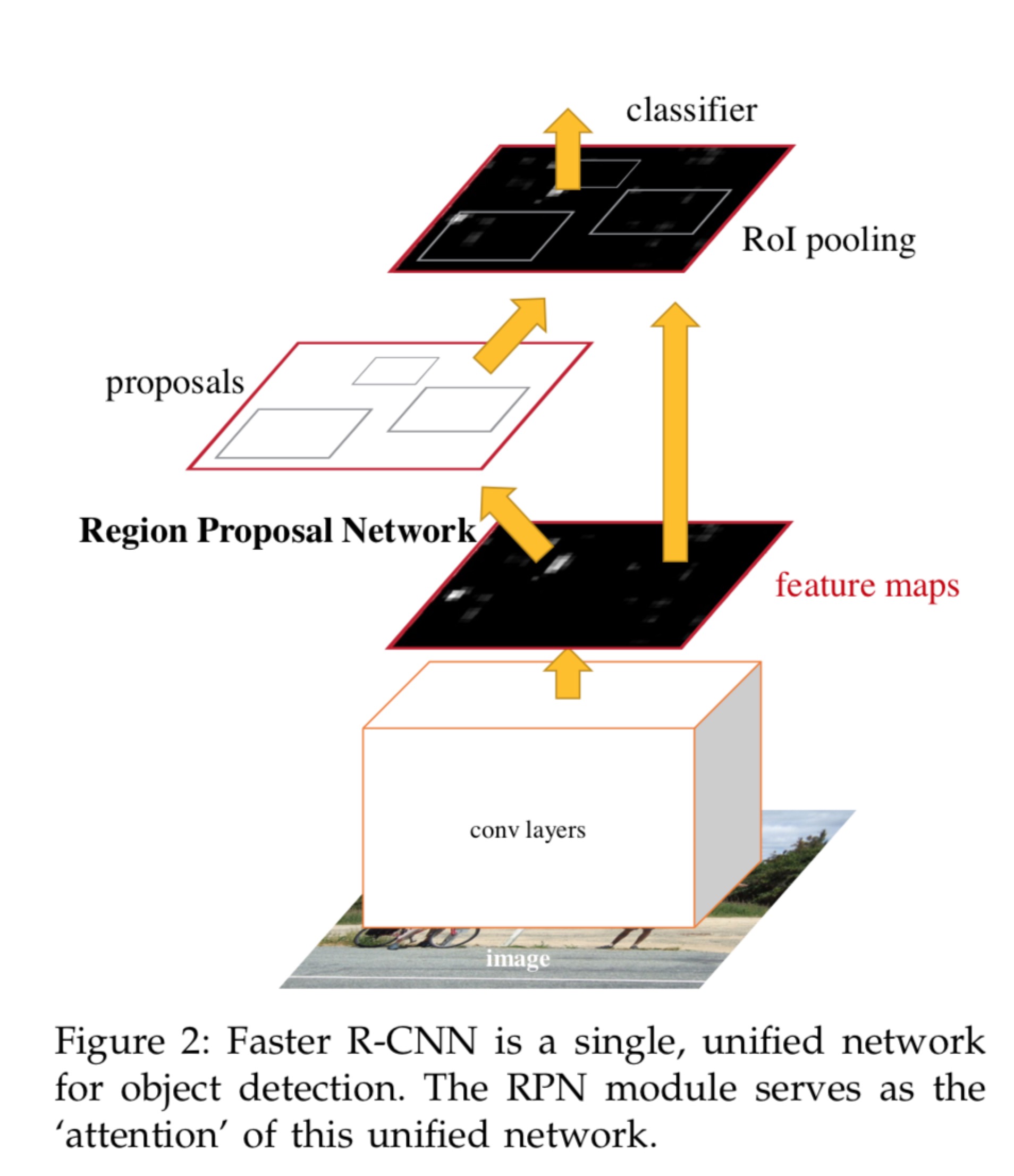
-
Conv layers:卷积层包括一系列卷积(Conv + Relu)和池化(Pooling)操作,用于提取图像的特征(feature maps),一般直接使用现有的经典网络模型ZF或者VGG16,而且卷积层的权值参数为RPN和Fast RCNN所共享,这也是能够加快训练过程、提升模型实时性的关键所在。
-
Region Proposal Networks:RPN层是faster-rcnn最大的亮点,RPN网络用于生成region proposcals.基于网络模型引入的多尺度Anchor,通过Softmax对anchors属于目标(foreground)还是背景(background)进行分类判决,并使用Bounding Box Regression对anchors进行回归预测,获取Proposal的精确位置,并用于后续的目标识别与检测。
-
Roi Pooling:综合卷积层特征feature maps和候选框proposal的信息,将propopal在输入图像中的坐标映射到最后一层feature map(conv5-3)中,对feature map中的对应区域进行池化操作,得到固定大小(7×77×7)输出的池化结果,并与后面的全连接层相连。
-
Classification and Regression: 全连接层后接两个子连接层——分类层(cls)和回归层(reg),分类层用于判断Proposal的类别,回归层则通过bounding box regression预测Proposal的准确位置。
结论
- 该论文提出了RPN来生成高效,准确的区域推荐。通过与下游检测网络共享卷积特征,区域推荐步骤几乎是零成本的。我们的方法使统一的,基于深度学习的目标检测系统能够以接近实时的帧率运行。学习到的RPN也提高了区域提议的质量,从而提高了整体的目标检测精度。
参考
原论文地址:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)
我的笔记地址:【论文泛读】 Faster R-CNN:利用RPN实现实时目标检测
You Only Look Once: Unified, Real-Time Object Detection
CVPR‘16
问题
- YOLO是目前比较流行的object detection算法,速度快且结构简单,其他的object detection算法如faster RCNN(之前已经解读了一下)。YOLO模型指标准化、实时的目标检测。有了YOLO,不需要一张图像看一千次,来产生检测结果,你只需要看一次,这就是我们为什么把它叫"YOLO"物体探测方法(You only look once)。
方法
-
提出了YOLO,一种新的目标检测方法。以前的目标检测工作重新利用分类器来执行检测。相反,我们将目标检测框架看作回归问题从空间上分割边界框和相关的类别概率。单个神经网络在一次评估中直接从完整图像上预测边界框和类别概率。由于整个检测流水线是单一网络,因此可以直接对检测性能进行end-to-end(端到端)的优化。
-
YOLO1的网络架构受到GoogLeNet图像分类模型的启发。我们的网络有24个卷积层,后面是2个全连接层。我们只使用 1 × 1 1 \\times 1 1×1降维层,后面是 3 × 3 3 \\times 3 3×3卷积层,而不是GoogLeNet使用的Inception模块,具体如下图所示

我们网络的最终输出是 7 × 7 × 30 7 \\times 7 \\times 30 7×7×30的预测张量。
结论
-
YOLO算法有较为明显的优点:
1、YOLO的速度非常快。在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是150fps。
2、YOLO是基于图像的全局信息进行预测的。这一点和基于sliding window以及region proposal等检测算法不一样。与Fast R-CNN相比,YOLO在误检测(将背景检测为物体)方面的错误率能降低一半多。
3、YOLO可以学到物体的generalizable representations。可以理解为泛化能力强。
4、准确率高,有实验证明。
参考
原论文地址:You Only Look Once: Unified, Real-Time Object Detection
我的笔记地址:【论文泛读】 YOLO v1:统一、实时的目标检测框架
YOLO9000: Better, Faster, Stronge
CVPR‘17 CVPR 2017 Best Paper Honorable Mention
前言
- YOLOv1的改进,基于前者上的改进,使得Better, Faster, Stronge,YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势
方法
-
预测更准确(Better)
虽然YOLOv1检测速度很快,但是在精度上却不R-CNN系列的检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进方法如下图所示,可以看到,大部分的改进策略都可以比较显著的提高模型的mAP。
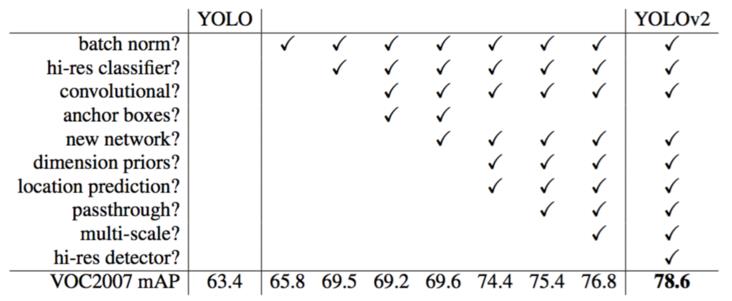
-
速度更快(Faster)
为了进一步提升速度,YOLO2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。
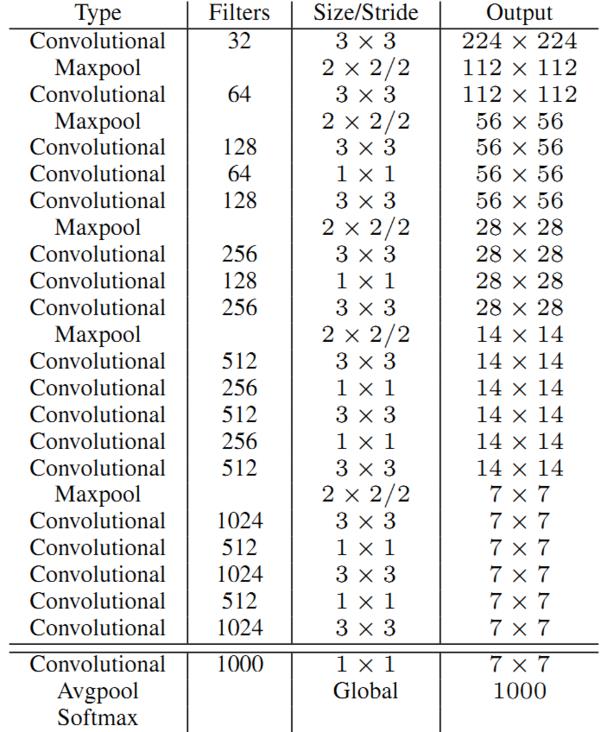
-
识别对象更多(Stronger)/ YOLO9000
基本的思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。
YOLO9000是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
结论
- 总的来说,YOLO2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势。YOLO9000则开创性的提出联合使用分类样本和检测样本的训练方法,使对象检测能够扩展到缺乏检测样本的对象。
参考
原论文地址:[YOLO9000: Better, Faster, Stronger](https://arxiv.org/abs/1804.02767)
我的笔记地址:【论文泛读】 YOLO v2:Better,Faster,Stronger
YOLOv3: An Incremental Improvement
CVPR‘18
前言
- YOLOv3是YOLO (You Only Look Once)系列目标检测算法中的第三版,相比之前的算法,尤其是针对小目标,精度有显著提升。
方法
-
作者对YOLOv3进行了一些更新改进 The Deal
-
Bounding Box Prediction:在 YOLO9000 之后,我们的系统使用维度聚类(dimension cluster)固定 anchor boxes 来选定边界框。
-
Class Prediction:这里对我们多分类进行了改进,之前的时候,我们都是用softmax,但是YOLOv3用独立的逻辑回归来分类。并且在训练过程,二分类交叉熵损失函数。这样可以每个预测框的每个类别逐一用逻辑回归输出概率,结果可以有多个类别输出高概率。
-
Predictions Across Scales:这里就到YOLOv3一个特别好的创新点,YOLOv3使用多尺度的目标检测。这个想法借鉴了FPN(feature pyramid networks),采用多尺度来对不同size的目标进行检测,越精细的grid cell就可以检测出越精细的物体。
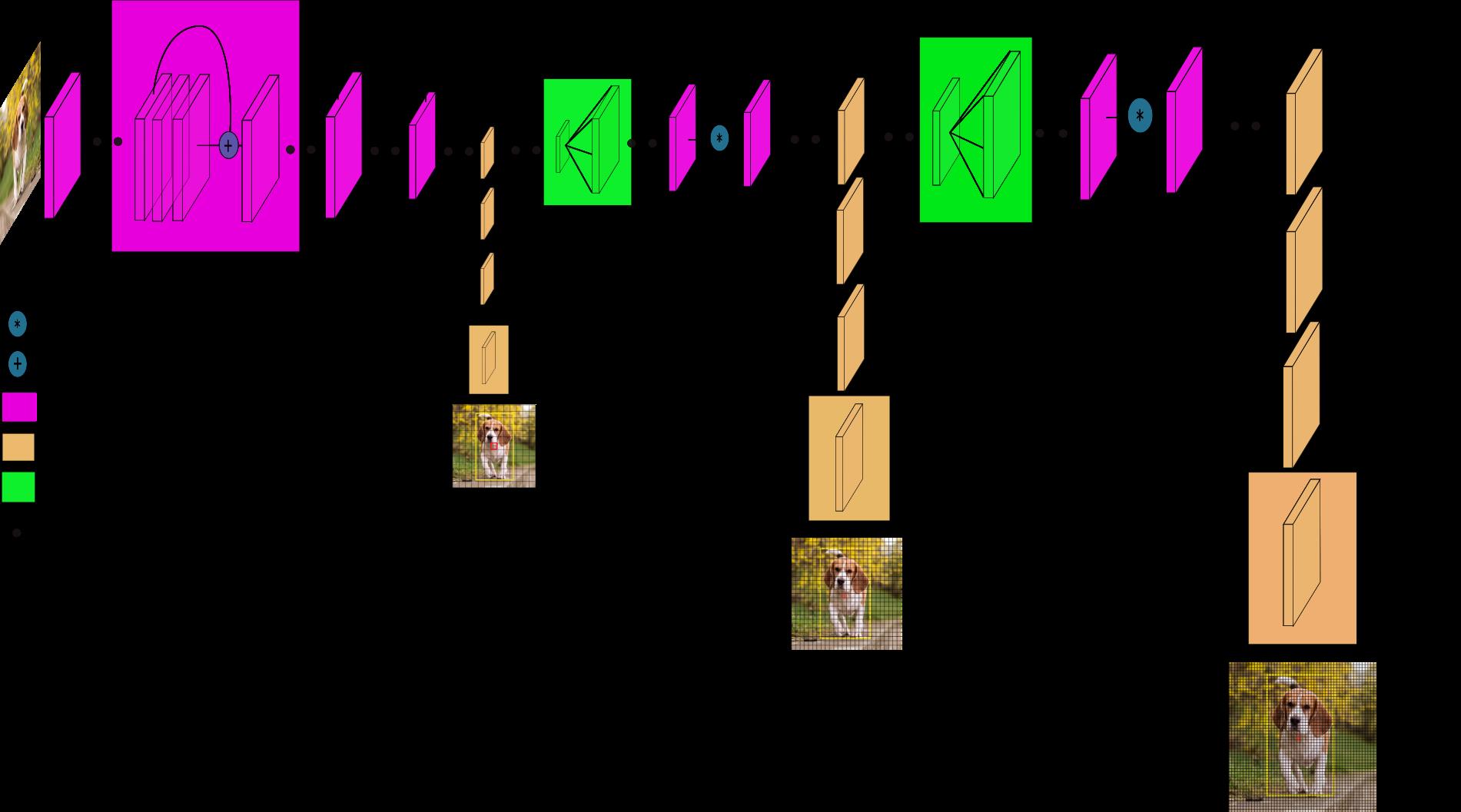
-
Feature Extractor:在YOLOv3中,作者用了一个新模型,结合了YOLOv2的Darknet-19和当时比较新奇时髦的残差网络。并且多用了连续的3x3和1x1的卷积,所以这个模型也比较大,它有53层卷积,所以被称为Darknet-53。还有一个比较好的点是,论文的模型中,最后一层用了全局平均池化,所以能够更好的对我们的目标检测进行预测。
结论
-
YOLOv3表现出了不错的性能,我们可以从下面的表可以看的出来,对于 COCOs 数据集那些奇怪的 mAP 评价指标,它的表现与与 SSD 平分秋色,但速度提高了 3 倍。尽管如此,它仍然比像 RetinaNet 这样的模型要差不少。
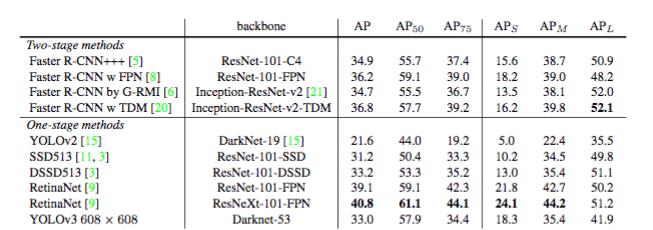
-
在过去,YOLO 一直被用于小型对象检测。但现在我们可以看到其中的演变趋势,随着多尺寸预测功能的上线,YOLOv3 将具备更高 APS 性能。但它目前在中等尺寸或大尺寸物体上的检测表现还相对较差,仍需进一步的完善。
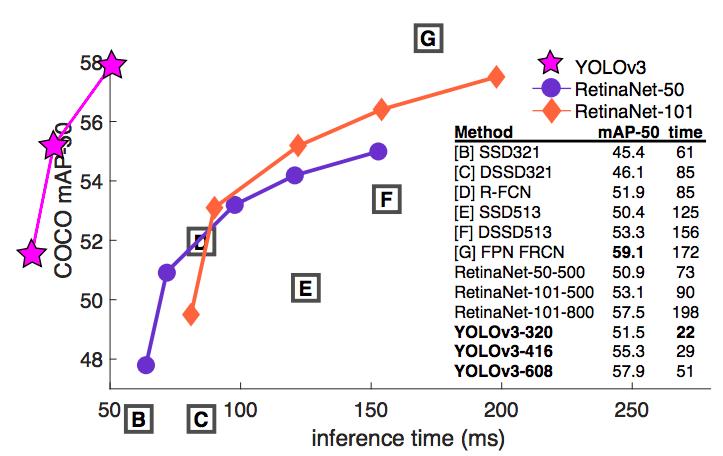
参考
以上是关于论文泛读 Deep Learning 论文合集的主要内容,如果未能解决你的问题,请参考以下文章