用 Python 帮财务小妹解决 PDF 拆分,小妹说太棒了。。。
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Python 帮财务小妹解决 PDF 拆分,小妹说太棒了。。。相关的知识,希望对你有一定的参考价值。
财务小妹的需求
需要从 PDF 中取出几页并将其保存为新的 PDF,当然又由于小妹是个编程小白,这个工具需要做成傻瓜式的带有GUI页面的形式
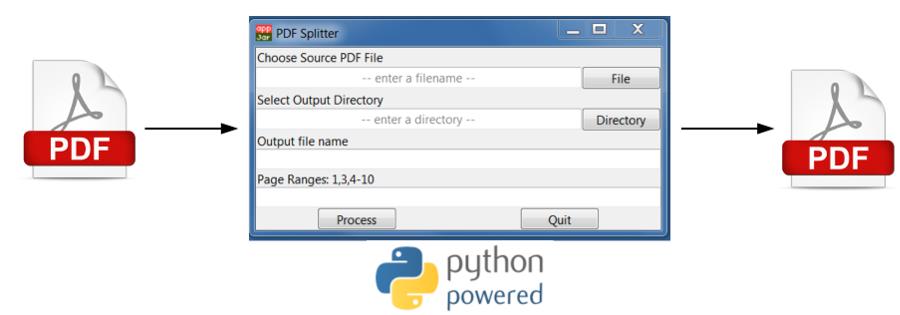
选择源pdf文件,再指定下生成的新的pdf文件名称及保存位置,和需要拆分的page信息,就可以得到新的pdf文件了
技术选型
对于 Python GUI,我们有太多种选择了,下面我们先来横向的简单对比下
从高层次上看,大的GUI工具有:
-
Qt
-
WxWindows
-
Tkinter
-
Customer libraries(Kivy,Toga等)
-
Web相关(html,Flask等)
不过今天,我选择的工具是 appJar,这是一个由一位从事教育工作的大神发明的,所以它可以提供一个更加简单的GUI创建过程,而且是完全基于 Tkinter 的,Python 默认支持
开整!
首先为了实现 PDF 操作,我这里选择了 pypdf2 库
我们先硬编码一个输入输出的示例
from PyPDF2 import PdfFileWriter, PdfFileReader
infile = "Input.pdf"
outfile = "Output.pdf"
page_range = "1-2,6"
接下来我们实例化 PdfFileWriter 和 PdfFIleReader 对象,并创建实际的 Output.pdf 文件
output = PdfFileWriter()
input_pdf = PdfFileReader(open(infile, "rb"))
output_file = open(outfile, "wb")
下面一个比较复杂的点就是需要拆分 pdf,提取页面并保存在列表中
page_ranges = (x.split("-") for x in page_range.split(","))
range_list = [i for r in page_ranges for i in range(int(r[0]), int(r[-1]) + 1)]
最后就是从原始文件中拷贝内容到新的文件
for p in range_list:
output.addPage(input_pdf.getPage(p - 1))
output.write(output_file)
下面来构建 GUI 界面
对于这个拆分 PDF 的小工具,需要具有如下功能:
-
可以通过标准文件浏览器选择 pdf 文件
-
可以选择输出文件的位置及文件名称
-
可以自定义提取哪些页面
-
有一些错误检查
通过 PIP 安装好 appJar 后,我们就可以编码了
from appJar import gui
from PyPDF2 import PdfFileWriter, PdfFileReader
from pathlib import Path
创建 GUI 窗口
app = gui("PDF Splitter", useTtk=True)
app.setTtkTheme("default")
app.setSize(500, 200)
这里我使用了默认主题,当然也可以切换各种各样的主题模式
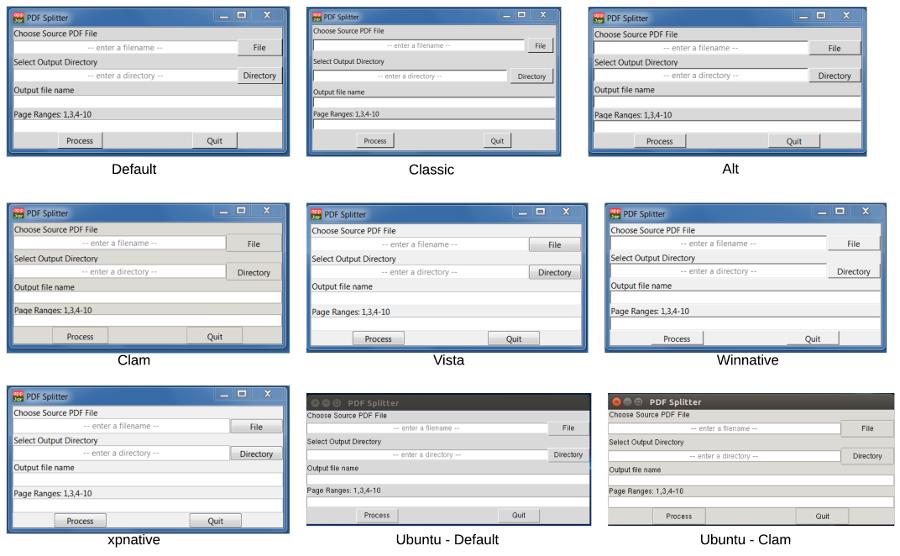
下面是添加标签和数据输入组件
app.addLabel("Choose Source PDF File")
app.addFileEntry("Input_File")
app.addLabel("Select Output Directory")
app.addDirectoryEntry("Output_Directory")
app.addLabel("Output file name")
app.addEntry("Output_name")
app.addLabel("Page Ranges: 1,3,4-10")
app.addEntry("Page_Ranges")
接下来添加按钮,“处理”和“退出”,按下按钮,调用如下函数
app.addButtons(["Process", "Quit"], press)
最后就是运行这个 app 啦
# start the GUI
app.go()
这要我们就完成了 GUI 的搭建,下面编写内部处理逻辑。程序读取任何输入,判断是否为 PDF,并拆分
def press(button):
if button == "Process":
src_file = app.getEntry("Input_File")
dest_dir = app.getEntry("Output_Directory")
page_range = app.getEntry("Page_Ranges")
out_file = app.getEntry("Output_name")
errors, error_msg = validate_inputs(src_file, dest_dir, page_range, out_file)
if errors:
app.errorBox("Error", "\\n".join(error_msg), parent=None)
else:
split_pages(src_file, page_range, Path(dest_dir, out_file))
else:
app.stop()
如果单击 “处理(Process)”按钮,则调用 app.getEntry() 检索输入值,每个值都会被存储,然后通过调用 validate_inputs() 进行验证
来看看 validate_inputs 函数
def validate_inputs(input_file, output_dir, range, file_name):
errors = False
error_msgs = []
# Make sure a PDF is selected
if Path(input_file).suffix.upper() != ".PDF":
errors = True
error_msgs.append("Please select a PDF input file")
# Make sure a range is selected
if len(range) < 1:
errors = True
error_msgs.append("Please enter a valid page range")
# Check for a valid directory
if not(Path(output_dir)).exists():
errors = True
error_msgs.append("Please Select a valid output directory")
# Check for a file name
if len(file_name) < 1:
errors = True
error_msgs.append("Please enter a file name")
return(errors, error_msgs)
这个函数就是执行一些检查来确保输入有数据并且有效
在收集验证了所以数据后,就可以调用 split 函数来处理文件了
def split_pages(input_file, page_range, out_file):
output = PdfFileWriter()
input_pdf = PdfFileReader(open(input_file, "rb"))
output_file = open(out_file, "wb")
page_ranges = (x.split("-") for x in page_range.split(","))
range_list = [i for r in page_ranges for i in range(int(r[0]), int(r[-1]) + 1)]
for p in range_list:
# Need to subtract 1 because pages are 0 indexed
try:
output.addPage(input_pdf.getPage(p - 1))
except IndexError:
# Alert the user and stop adding pages
app.infoBox("Info", "Range exceeded number of pages in input.\\nFile will still be saved.")
break
output.write(output_file)
if(app.questionBox("File Save", "Output PDF saved. Do you want to quit?")):
app.stop()
好了,这要我们就完成了一个简易的 GUI 拆分 PDF 文件的工具喽.
参考链接:https://mp.weixin.qq.com/s/_dQrXzn9cOUoA6jojt0h-w
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于用 Python 帮财务小妹解决 PDF 拆分,小妹说太棒了。。。的主要内容,如果未能解决你的问题,请参考以下文章