玩日志的你不了解 Filebeat ,就像搞结拜不认识关二爷!深度解析 Filebeat 工作原理,轻松玩转大数据!
Posted 魏小言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩日志的你不了解 Filebeat ,就像搞结拜不认识关二爷!深度解析 Filebeat 工作原理,轻松玩转大数据!相关的知识,希望对你有一定的参考价值。
文章目录

深度解析 Filebeat 工作原理,轻松玩转大数据!
什么是 Filebeat
玩日志的同学可能比较了解 Filebeat。Filebeat 是一个轻量级的日志收集模块。由 Goland 实现,用于转发和汇总日志与文件。它是 ES [elastic] 旗下 beats 项目其中的一员,通常与 ELK 配套使用,编排在 Logstash 之前。
这里放上 Filebeat 的官方介绍:https://www.elastic.co/cn/beats/filebeat
Filebeat 工作原理
官网中有 Filebeat 的文档,是英文版,这里附上译文:
Filebeat 的工作原理
在本主题中,您将了解 Filebeat 的关键构建块以及它们如何协同工作。了解这些概念将帮助您就为特定用例配置 Filebeat 做出明智的决定。
Filebeat 由两个主要组件组成:Input和Harvester。这些组件协同工作以拖尾文件并将事件数据发送到您指定的输出。
什么是Harvester?
Harvester负责读取单个文件的内容。Harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个Harvester。Harvester负责打开和关闭文件,这意味着Harvester运行时文件描述符保持打开状态。如果文件在收集过程中被删除或重命名,Filebeat 会继续读取该文件。这会产生副作用,即磁盘上的空间会被保留,直到Harvester关闭。默认情况下,Filebeat 保持文件打开直到 close_inactive 达到。
关闭Harvester会产生以下后果:
- 如果在Harvester仍在读取文件时删除了文件,则文件处理程序将关闭,从而释放底层资源。
- 只有在 scan_frequency 结束后才会重新开始收集文件。
- 如果在Harvester关闭时移动或移除文件,则不会继续收割文件。
- 要控制Harvester何时关闭,请使用 close_* 配置选项。
什么是Input?
Input负责管理Harvester并找到所有要读取的源。
如果Input类型是日志,则Input会查找驱动器上与定义的 glob 路径匹配的所有文件,并为每个文件启动Harvester。每个Input都在自己的 Go 例程中运行。
以下示例将 Filebeat 配置为从与指定的 glob 模式匹配的所有日志文件中收集行:
filebeat.inputs:
- 类型:日志
路径:
- /var/log/.log
- /var/path2/.log
Filebeat 目前支持多种Input类型。每个Input类型可以定义多次。日志Input检查每个文件以查看是否需要启动Harvester,是否已经在运行,或者是否可以忽略该文件(请参阅 ignore_older)。仅当Harvester关闭后文件的大小发生变化时才会拾取新行。
Filebeat 如何保持文件的状态?
Filebeat 保持每个文件的状态,并经常将状态刷新到注册表文件中的磁盘。该状态用于记住Harvester读取的最后一个偏移量,并确保发送所有日志行。如果无法访问输出(例如 Elasticsearch 或 Logstash),Filebeat 会跟踪发送的最后一行,并在输出再次可用时继续读取文件。当 Filebeat 运行时,每个Input的状态信息也保存在内存中。当 Filebeat 重新启动时,来自注册表文件的数据用于重建状态,Filebeat 在最后一个已知位置继续每个Harvester。
对于每个Input,Filebeat 会保留它找到的每个文件的状态。由于文件可以重命名或移动,文件名和路径不足以识别文件。对于每个文件,Filebeat 存储唯一标识符以检测之前是否收集了文件。
如果您的用例涉及每天创建大量新文件,您可能会发现注册表文件变得太大。有关可以设置以解决此问题的配置选项的详细信息,请参阅注册表文件太大。
Filebeat 如何确保至少一次交付?
Filebeat 保证事件将至少传送到配置的输出一次并且不会丢失数据。 Filebeat 能够实现这种行为,因为它将每个事件的传递状态存储在注册表文件中。
在定义的输出被阻塞并且没有确认所有事件的情况下,Filebeat 将继续尝试发送事件,直到输出确认它已收到事件。
如果 Filebeat 在发送事件的过程中关闭,它不会在关闭之前等待输出确认所有事件。任何发送到输出但在 Filebeat 关闭之前未确认的事件,将在 Filebeat 重新启动时再次发送。这可确保每个事件至少发送一次,但最终可能会将重复的事件发送到输出。您可以通过设置 shutdown_timeout 选项将 Filebeat 配置为在关闭之前等待特定时间。
Filebeat 的至少一次交付保证存在限制,涉及日志轮换和删除旧文件。如果将日志文件写入磁盘并以比 Filebeat 处理它们的速度更快的速度旋转,或者如果在输出不可用时删除文件,则数据可能会丢失。在 Linux 上,由于 inode 重用,Filebeat 也有可能跳过行。
Filebeat 工作流图
相信大家看了文档之后,可以了解到 Filebeat 的基本组件及相关的功能实现。
这里通过一流程图形式化的方式进一步介绍 Filebeat 是如何工作的!
Filebeat 组件图
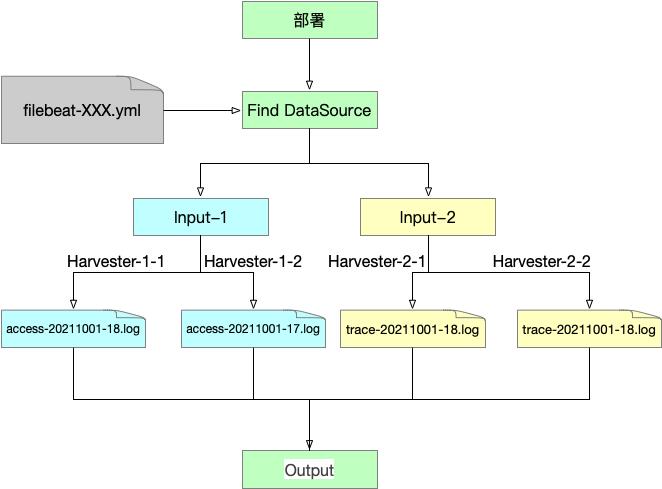
如图所示,Filebeat 有两个主要组件,分别为 Input 、 Harvester。
- Input 主要负责依据配置信息发现数据源,并管理正则命中的 Harvester。
- Harvester 主要负责日志文件的行数据收集,针对每个日志会构建独立的 Harvester。
Filebeat 部署之后,将由 Input 发现数据源,为每个文件构建 Harvester 实例;通过 Harvester 实例频次收集日志数据,并实时推送给目标输出。
Filebeat Harvester 流程图
看了组件图,还是不够细致,无法看到 Harvester 日志具体的收集策略!
下面是 Harvester 的主要流程图:
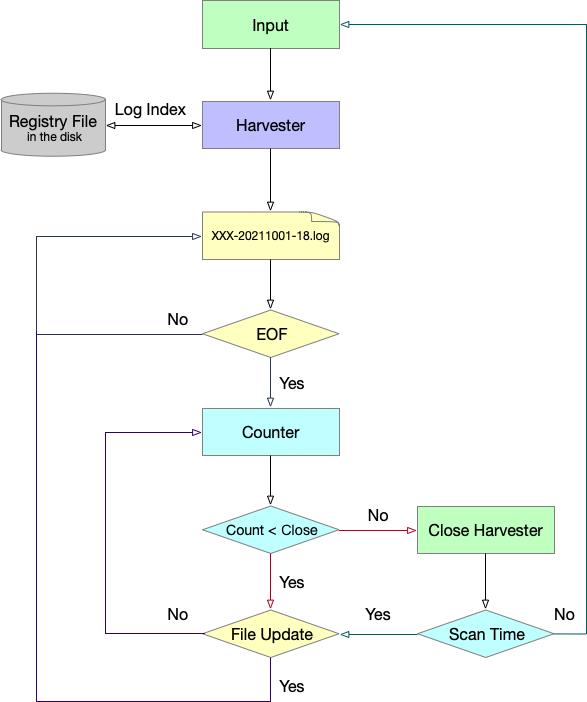
如图所示,Harvester 先会读取上次文件位置的偏移量,顺序读文件更新行直至读到最后一行 EOF;此时 Harvester 会进行 Counter 的初始化,以 配置参数 backoff 为基准,执行退避策略,监测文件是否更新。
- backoff 时间间隔默认 1 — 10s,默认系数为 2;
- backoff:1
- max_backoff:10
- backoff_factor:2
- 其监测时间间隔会逐步增大,backoff = backoff * backoff_factor 为间隔频次,且不会超过 max_backoff 。当间隔周期结束或文件存在更新,backoff 会自动回退至 1s 。
在监测过程中,Harvester 受 close_inactive 参数影响。当 Counter 监测时间到达 close_inactive 时间,则此 Harvester 会自动关闭。由 Input 继续按 scan_frequency 频次寻找数据源并构建新的 Harvester …
Filebeat 配置参数
上面流图中介绍了主要阶段,Harvester 还与很多参数紧密相关,下面列部分参数含义供大家参考。
paths:指定要监控的日志。
encoding:指定被监控的文件的编码类型,使用 plain 和 utf-8 都是可以处理中文日志的。
input_type:指定文件的输入类型 log (默认)或者 stdin 。
exclude_lines:在输入中排除符合正则表达式列表的那些行。
include_lines:包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines 执行完毕之后会执行 exclude_lines。
exclude_files:忽略掉符合正则表达式列表的文件(默认为每一个符合 paths 定义的文件都创建一个harvester)。
fields:向输出的每一条日志添加额外的信息,比如 “level:debug”,方便后续对日志进行分组统计。默认情况下,会在输出信息的 fields 子目录下以指定的新增 fields 建立子目录,例如 fields.level。
scan_frequency:Filebeat 以多快的频率去 input 指定的目录下面检测文件更新(比如是否有新增文件)。
harvester_buffer_size:每个 harvester 监控文件时,使用的 buffer 的大小,默认是 16384 。
max_bytes:日志文件中增加一行算一个日志事件,max_bytes 限制在一次日志事件中最多上传的字节数,多出的字节会被丢弃,默认是10M。
Backoff:Filebea t检测到某个文件到了 EOF 之后,每次等待多久再去检测文件是否有更新,默认为1s。
max_backoff:Filebea t检测到某个文件到了 EOF 之后,等待检测文件更新的最大时间,默认是10秒。
backoff_factor:定义到达 max_backoff 的速度,默认因子是2,到达 max_backoff 后,变成每次等待 max_backoff 那么长的时间才 backoff 一次,直到文件有更新才会重置为 backoff。
…
Q&A
1、Filebeat 部署 和 服务部署 有先后顺序吗?
无顺序。Filebeat 会频次扫描配置文件指定文件路径,若存在,才会进行 Input 的构建进行下一步的日志收集。
2、Filebeat 是实时收集日志吗?
跟具体配置有关,可认为是实时性质。
3、Filebeat 会出现日志漏发的场景吗?是否可靠呢?
存在,但概率跟小。
可认为 Filebeat 99.999% 准确实时,但是并不会 100% 十分精确。
其发送机制为:至少一次发送,存在多发的场景、且日志旋转速度超过时,存在数据丢失、Linux inode 重用也可能导致跳过行发送
4、至少一次发送里面涉及 inode 重用,什么是 Linux Inode 重用?
Linux文件系统,Filebeat 使用 inode 和设备来识别文件。从磁盘中删除文件时,可将 inode 分配给新文件。在涉及文件旋转的使用情况下,如果旧文件被删除并且之后立即创建新文件,则新文件可能与删除的文件具有完全相同的inode。
附录
负重前行,向阳而生!
以上是关于玩日志的你不了解 Filebeat ,就像搞结拜不认识关二爷!深度解析 Filebeat 工作原理,轻松玩转大数据!的主要内容,如果未能解决你的问题,请参考以下文章