CS224W摘要15.Deep Generative Models for Graphs
Posted oldmao_2000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS224W摘要15.Deep Generative Models for Graphs相关的知识,希望对你有一定的参考价值。
文章目录
CS224W: Machine Learning with Graphs
公式输入请参考: 在线Latex公式
这节和上节都是讲图的生成模型,上节讲传统方法,这节讲DL方法。
本节两个任务:
1.Realistic graph generation(重点)
2.Goal-directed graph generation(创建带有Constraint或者objective的图),例如:Drug molecule generation/optimization
Graph Generative Models
这块先复习生成模型的知识点,之前在别的地方有讲过。大略记一下:
从给定的数据中通过采样得到图
p
d
a
t
a
(
G
)
p_{data}(G)
pdata(G)(这里的
d
a
t
a
data
data相当于所有的真实数据,是无穷无尽的,没法穷举,因此只能尽量多的采样来样本来推测整体数据)
通过采样的数据,从中可以学习到数据的分布
p
m
o
d
e
l
(
G
)
p_{model}(G)
pmodel(G),再利用
p
m
o
d
e
l
(
G
)
p_{model}(G)
pmodel(G)来生成图

Setup
要从一个点数据集
{
x
i
}
\\{x_i\\}
{xi}中学习一个生成模型。
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)是真实数据分布,这个分布是真实存在但由于数据的无穷性又无法直接学到,因此我们可以对其进行采样:
x
i
∼
p
d
a
t
a
(
x
)
x_i\\sim p_{data}(x)
xi∼pdata(x)
p
m
o
d
e
l
(
x
;
θ
)
p_{model}(x;\\theta)
pmodel(x;θ)是我们要学习的模型,
θ
\\theta
θ是模型参数,可以根据模型来估计真实的数据分布
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)。
这个过程类似人口普查,我们不可能完全统计所有人,但是我们可以通过采样某个小区域的人口,来推断整个区域的人口的分布。
整个过程大概就是两个步骤
1.学习到模型
2.模型生成图结构
步骤1
学习到模型就是要使得
p
m
o
d
e
l
(
x
;
θ
)
p_{model}(x;\\theta)
pmodel(x;θ)越接近
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)越好,这里通常使用(对数)最大似然的方式来进行估计Maximum Likelihood:
θ
∗
=
arg max
θ
E
x
∼
p
d
a
t
a
log
p
m
o
d
e
l
(
x
∣
θ
)
\\theta^*=\\underset{\\theta}{\\argmax}\\mathbb{E}_{x\\sim p_{data}}\\log p_{model}(x|\\theta)
θ∗=θargmaxEx∼pdatalogpmodel(x∣θ)
找到最优化的参数
θ
∗
\\theta^*
θ∗使得模型最有可能生成观测数据
x
x
x
步骤2
模型生成图结构就是从
p
m
o
d
e
l
(
x
;
θ
)
p_{model}(x;\\theta)
pmodel(x;θ)采样数据,常用方法:
先从搞屎分布中采样:
z
i
∼
N
(
0
,
1
)
z_i\\sim N(0,1)
zi∼N(0,1)
然后对采样结果
z
i
z_i
zi通过
f
(
⋅
)
f(\\cdot)
f(⋅)(一般用DNN)进行变化:
x
i
=
f
(
z
i
;
θ
)
x_i=f(z_i;\\theta)
xi=f(zi;θ)
得到的结果
x
i
x_i
xi就是服从复杂分布的结果
Auto-regressive models
这里使用的这个模型和VAE,GAN等模型不一样,VAE,GAN一般有两个部分构成:encoder+Decoder或者generator+discriminator,两个部分分别做数据的表征和生成,这个模型只有一个部分,直接用来做数据的density estimation and sampling。
模型类似语言模型,使用条件概率来表示联合概率:
p
m
o
d
e
l
(
x
;
θ
)
=
∏
t
=
1
n
p
m
o
d
e
l
(
x
t
∣
x
1
,
⋯
,
x
t
−
1
;
θ
)
p_{model}(x;\\theta)=\\prod_{t=1}^np_{model}(x_t|x_1,\\cdots,x_{t-1};\\theta)
pmodel(x;θ)=t=1∏npmodel(xt∣x1,⋯,xt−1;θ)
如果是语言模型,则是用前
t
−
1
t-1
t−1个词
x
t
−
1
x_{t-1}
xt−1预测第
t
t
t个词
x
t
x_t
xt,从而得到整个句子。
这里的图模型,
x
t
x_t
xt代表第
t
t
t个动作(添加节点或边)。
下面看具体的模型。
GraphRNN
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models.
尤里组的工作,感觉整个课程基本都是老师的研究方向。。。
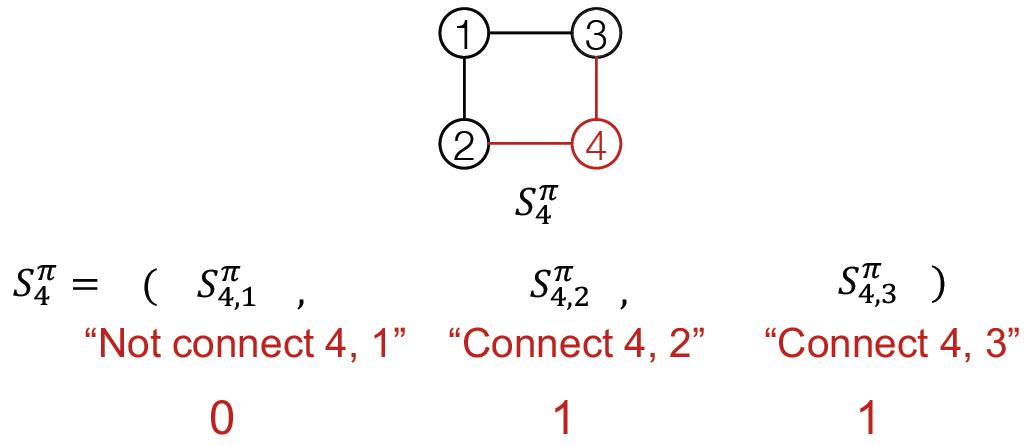
将生成图的过程看成一个序列,例如对于下面的图:
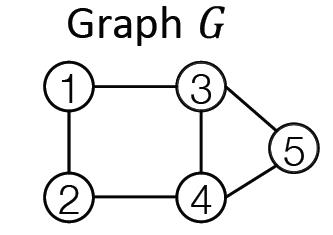
每个步骤记如下:
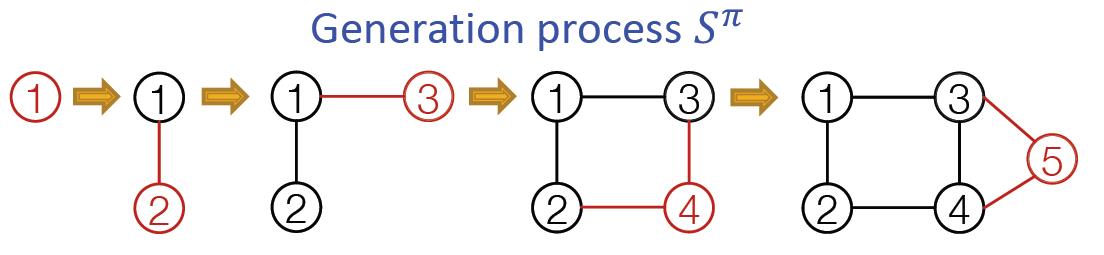
其中
π
\\pi
π是图
G
G
G的节点序列(这个当然有必要,因为之前说图是无序的,不知道这里如果不一样生成的模型会不会相同1),经过扩展可以将其对应到添加节点和边的动作序列:
S
π
S^{\\pi}
Sπ
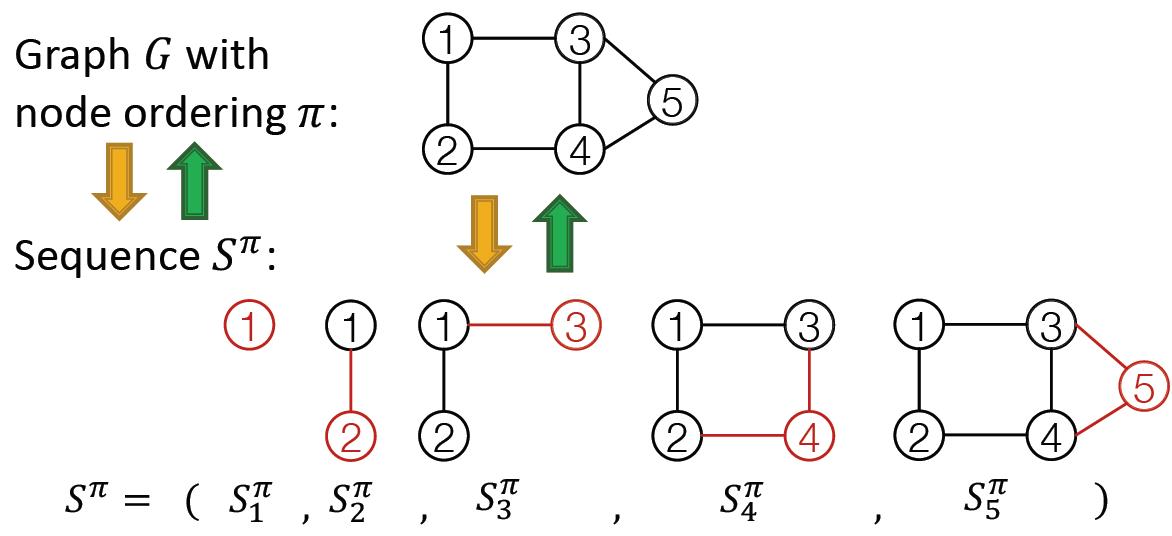
图与序列的映射
由于动作包含两层意思:
Node-level:每次添加一个节点;
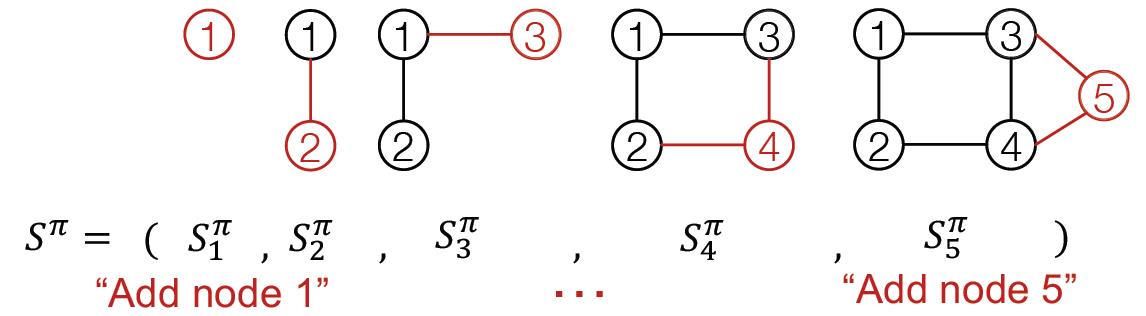
Edge-level:为新加节点与已存在的节点建立边(可以多条)
从邻接矩阵上来看,可以看到两个序列(实际上是序列的序列)关系如下:
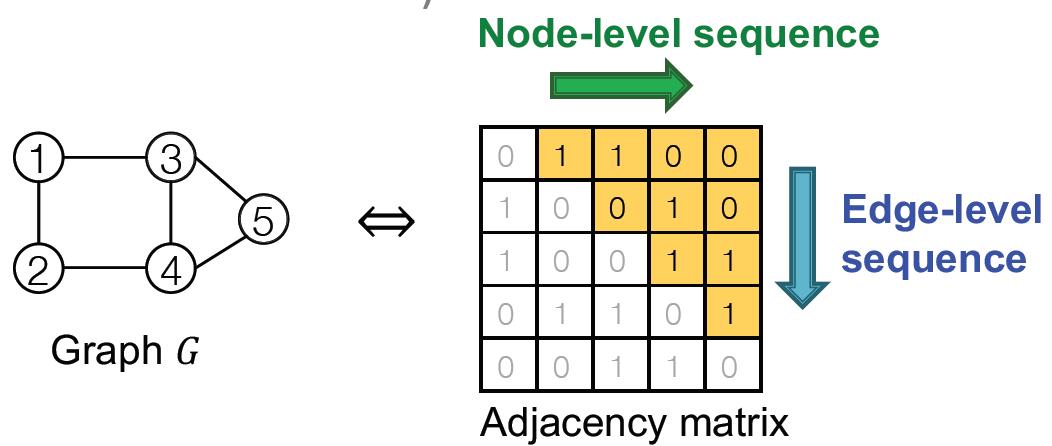
经过图到序列的转化后,就将图生成问题变成了序列生成问题,不过需要处理两个序列:
- Generate a state for a new node (Node-level sequence)
- Generate edges for the new node based on its state (Edge-level sequence)
RNN
这里复习了一把RNN,RNN是用来处理序列数据的。
它吃输入序列,并更新它的隐状态
隐状态包含之前所有序列的信息
更新关键就是RNN Cells
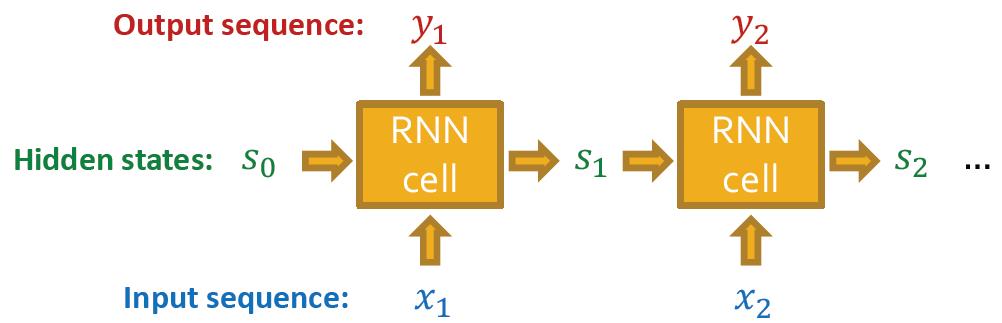
s
t
s_t
st: State of RNN after step
t
t
t
x
t
x_t
xt: Input to RNN at step
t
t
t
y
t
y_t
yt: Output of RNN at step
t
t
t
RNN cell保护三个可训练参数:
𝑊
,
𝑈
,
𝑉
𝑊,𝑈, 𝑉
W,U,V
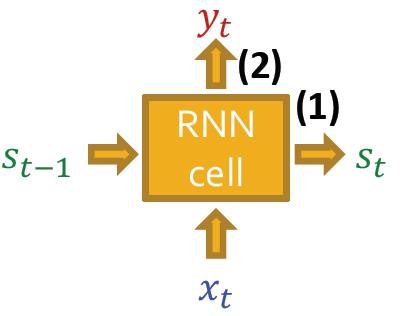
(1) Update hidden state:
s
t
=
σ
(
W
⋅
x
t
+
U
⋅
s
t
−
1
)
s_t=\\sigma(W\\cdot x_t+U\\cdot s_{t-1})
st=σ(W⋅xt+U⋅st−1)
(2) Output prediction:
y
t
=
V
⋅
s
t
y_t=V\\cdot s_t
yt=V⋅s