自然语言处理的句法和形式语法
Posted 人邮异步社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理的句法和形式语法相关的知识,希望对你有一定的参考价值。
我们可以在一些不同结构层次上对语言进行分析,如句法、词法和语义。现在,我们介绍语言研究中的一些关键术语。
词法——对单词的形式和结构的研究,还研究了词与词根以及词的衍生形式之间的关系。
句法——将单词放在一起形成短语和句子的方式,通常关注句子结构的形成。
语义学——语言中对意义进行研究的科学。
解析——将句子分解成语言组成部分,并对每个部分的形式、功能和语法关系进行解释。语法规则决定了解析方式。
词汇——与语言的词汇、单词或语素(原子)有关。词汇源自词典。
语用学——在语境中运用语言的研究。
省略——省略了在句法上所需的句子部分,但是,从上下文而言,句子在语义上是清晰的。
在本节中,我们从句法开始讲解。在13.4节中,我们继续语义和意义分析。
13.3.1 语法类型
学习语法是学习语言和教授计算机语言的一种好方法。费根鲍姆(Feigenbaum)等人将语言的语法定义为“指定在语言中所允许语句的格式,指出将单词组合成形式完整的短语和子句的句法规则”。[27]
麻省理工学院的语言学家诺姆·乔姆斯基(Noam Chomsky)[28]在对语言语法进行数学式的系统研究中做出了开创性的工作,为计算语言学领域的诞生奠定了基础。他将形式语言定义为一组由符号词汇组成的字符串,这些字符串符合语法规则。字符串集对应于所有可能句子的集合,其数量可能无限大。符号的词汇表对应于有限的字母或单词词典。他对4种语法规则的定义如下。
(1)定义了作为变量或非终端符号的句法类别。
句法变量的例子包括<VERB>、<NOUN>、<ADJECTIVE>和<PREPOSITION>。
(2)词汇表中的自然语言单词被视为终端符号,并根据重写规则连接(串联在一起)形成句子。
(3)终端和非终端符号组成的特定字符串之间的关系,由重写规则或产生式规则(见第7章)指定。在这个讨论的上下文中:
<SENTENCE> → <NOUN PHRASE> <VERB PHRASE>
<NOUN PHRASE> → the <NOUN>
<NOUN> → student
<NOUN> → expert
<VERB> → reads
<SENTENCE>→<NOUN PHRASE> <VERB PHRASE>
<NOUN PHRASE>→<NOUN>
<NOUN>→student
<NOUN>→expert
<VERB>→reads
注意,包含在<...>中的变量和终端符号是小写的。
(4)起始符号S或<SENTENCE>与产生式不同,并根据在上述(3)中指定的产生式开始生成所有可能的句子。这个句子集合称为由语法生成的语言。以上定义的简单语法生成了下列的句子:
The student reads.
The expert reads.
重写规则通过替换句子中的词语生成这些句子,应用如下:
<SENTENCE> →
<NOUN PHRASE> <VERB PHRASE>
The <NOUN PHRASE> <VERB PHRASE>
The student <VERB PHRASE>
The student reads.
<SENTENCE>→
<NOUN PHRASE> <VERB PHRASE>
<NOUN PHRASE> <VERB PHRASE>
The student<VERB PHRASE>
The student reads.
因此,这很容易看出,语法是如何作为“机器”“创造”出重写规则允许的所有可能的句子的。
必要条件是给定词汇和一组产生式。类似地,使用这种方法,所有编程语言的语法和“结构”都使用Backus-Naur产生式规则生成。通过使用这些句子,我们可以执行所有NLP程序的第一阶段——解析,并且可以反向执行,将明确的句子归入相应的句法类别。
乔姆斯基演示了这种形式语言理论能生成4种基本类型的语法。这个语法被定义为四元组(VN,VT,P,S),其中:
V =词汇表
N =词汇表中的非终端符号
T =词汇表中的终端符号
P =形式X→Y的产生式
S =起始符号
类型0:递归可枚举语法
这种类型的语法对于产生式的形式没有任何限制,太过笼统,没有用处。由这种类型的语法生成的句子,可以被所有现代计算机理论基础的图灵机识别。
类型1:上下文相关语法
这种类型的语法生成形如X→Y的产生式,其限制是右边的Y必须至少包含与左边X一样多的符号。因此,产生式看起来像:
u X v → uYv
其中
X =单个非终端符号
u,v =包含空字符串在内的任意字符串
Y =词汇表V上的非空字符串
这种形式的产生式(重写规则)相当于说“在上下文u、v中,Y可以替代X”。
因此,此类例子的语法有:
规则1 S→xSBC
规则2 S→xBC
规则3 CB→BC
规则4 xB→xy
规则5 yB→yy
规则6 yC→yz
规则7 zC→zz
其中
S =起始符号
A,B,C =变量
x,y,z =终端符号。
根据这种语法的重写规则,我们可以推导出以下的句子:
规则1:xSBC
规则2:xxBCBC
规则3:xxBBCC
规则4:xxyBCC
规则5:xxyyCC
规则6:xxyyzC
规则7:xxyyzz
经过一番分析,读者应该不用太长时间就可以确定这种语法生成的字符串形式为xyz、xxyyzz等。
类型2:上下文无关语法
在上下文无关语法中,左侧必须只包含一个非终端符号。上下文无关意味着,在语言中的每个单词,如果有规则应用于此单词上,则这个规则与单词所在的上下文无关。这种语法最接近于自然语言。
产生式为:
S→aSb
S→ab
生成字符串的形式为ab、aabb、aaabbb等。
让我们看一个例子,来了解上下文无关语法如何使用以下重写规则生成自然语言句子:
<SENTENCE>→<NOUN PHRASE> <VERB PHRASE>
<NOUN PHRASE>→<DETERMINER> <NOUN>
<NOUN PHRASE>→<NOUN>
<VERB PHRASE>→<VERB> <NOUN PHRASE>
<DETERMINER> → the
<NOUN> → dogs
<NOUN> → cat
<VERB> → chase
此派生树或解析树(从句子到语法)如下所示:
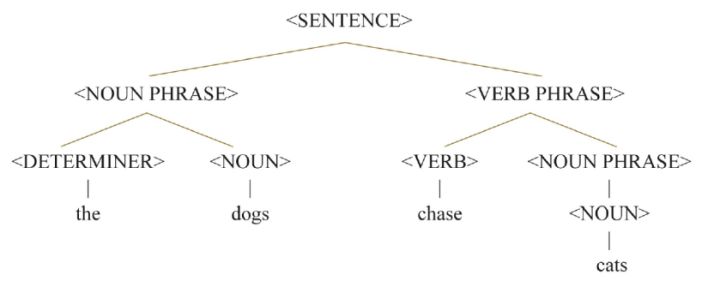
这种上下文无关语法产生了以下句子:
那几只狗追逐几只猫。
但是,按照同样的规则,也可产生以下句子:
那几只猫追逐几只狗。
也可以用相同的语法生成。这表明语法只关心结构,与语义是两码事。
类型3:正则语法
这种类型的语法也称为有限状态语法,根据产生式生成句子:
X→aY
X→a
其中:
X,Y =单个变量
a =单个终端
以下是正则语法:
S → 0S | 0T
T → 1T | ε
生成的语言有至少一个“0”,后面跟着“1s”的任何数字(包括0):
S→0S | 0T
T→1T | ε
注意,从0型语言行进到3型语言时,我们随之也从更一般的语法转向了更具限制性的语法。也就是说,每个正则语法都是上下文无关的,每个上下文无关的语法都可以生成上下文相关的语法,每个上下文相关的语法都是类型0的语法,基本上,类型0的语法是没有限制的。因此,重写规则有越多限制,所生成的语言就越简单。
图13.1显示的层次结构增加了一类,多了第五类,称为“轻度上下文相关语言”。这种语法可以由许多不同的语法形式(包括7.1节中介绍的Post产生式系统)来定义,但是这个内容超出了本书讨论的范围。

图13.1 转载自Jurafsky和Martin的著作(2008,第530页), 这幅图说明了维恩图中所谓的“乔姆斯基层次”
在这一点上,重要的是强调,尽管在设计编程语言和解密大部分自然语言中,上下文无关语法都是有用的,但是乔姆斯基觉得它们不能完全代表自然语言(如英语)。同样,这强调了一个结论:句法/语法对于理解自然语言是必要的,但就其本身而言,这是不够的。Firebaugh[29]注意到了用于语言解释的语法与问题求解的命题逻辑之间的类比。虽然在某些明确界定的情况下任何一种都适用,但是没有一种方法适用于大型的一般问题情况。[29]
13.3.2 句法解析:CYK算法
通常用解析树的形式表示自然语言的句法结构。句子通常是模糊的,可以用许多不同的方式进行解析,因此,找到最佳的解析是表示句子正确含义、揭示句子正确意图的关键一步。找到最佳解析的一种方法是将解析作为搜索问题。对于输入的句子,搜索空间包含所有可能的解析树,并且通过搜索此空间,必须找到最佳解析。通过这种方法,我们可以采用两种主要的策略:自上而下的搜索和自下而上的搜索。
自上而下搜索从起始符号S开始,并尝试构建所有的解析树,这些解析树将输入的句子作为叶节点,将开始点S作为根节点。这个策略为语法中的每个产生式规则构建单独的解析树,其中S在左侧。因此,在进程的第一阶段之后,对于使用语法扩展S的每一个产生式规则,都会有一颗独立的解析树。继续到树的下一层,由S生成的最左边的符号首先得到扩展。这个符号每个可能的扩展将生成单独的解析树。这个过程一直持续,直到所有解析树都探索到了树的最底层,并将叶节点与输入的句子进行比较。从搜索中驳回和删除错误的解析,同时保留对输入句子的成功、正确的解析。
相比之下,自下而上的搜索从输入句子的单词开始,试图从叶节点向上构建一棵树。这个策略尝试将输入的单词与非终端符号进行匹配,这个非终端符号可以扩展产生该单词。如果可以从非终端符号产生一个单词那么在解析树中,这个非终端符号将作为单词的父节点。如果这个单词可以从几个不同的非终端符号产生,那么由于这些可能的扩展,则必须构建单独的解析树。从叶节点到上一层,这个策略向上移动,直至到达根节点S为止。无法到达S的解析树将被从搜索中删除。
这两种搜索策略的问题是,存储所有可能的解析树需要大量内存。这是不切实际的,更实际的替代方案是使用回溯策略(见2.2.1节)探索解析树,直到它成功地得到解,或者直到它不再继续作为可行的解;然后搜索返回到搜索空间中的较早状态,返回到还未扩展的状态,构建解析树。
回溯有其自身的效率问题,这主要是因为,从一个扩展到另一个扩展,树的大部分是重复的。如果一棵树无法到达解,即使在下一个可能的解中树的大部分被重复,但是这棵树还是会被丢弃。通过使用动态规划算法,可以避免这种低效率的操作。动态编程方法将中间结果存储在表中,这样它们就可以得到重复使用。子树存储在表中,这样允许在每次寻找可能的解时,如果需要,就可以查找这些子树。
为了更详细地了解CYK算法,感兴趣的读者可以阅读《一种上下文无关语法的有效的识别和语法分析算法》(Kasami,T. 1965,马萨诸塞州贝德福德剑桥空军研究实验室,科学报告AFCRL-65-758)。
CYK算法(由科克(Cocke)、卡西米(Kasami)和扬格(Younger)开发的)是动态规划算法(见第3章),并且是句法解析中最常用的技术之一。
为了使用该算法,输入的语法必须是乔姆斯基范式(Chomsky Normal Form),这意味着产生式规则必须采用以下两种形式之一:A→BC或A→x。右侧必须有两个非终端节点,或者必须有一个终端节点。在此应用中,乔姆斯基范式非常有用,因为它确保了每个非终端节点都有两个子节点或者有一个单子节点,这个节点是一个终端符号,是叶节点。
如果语法是乔姆斯基范式(Chomsky Normal Form)的,则CYK算法可以构建一个(n + 1)×(n + 1)的矩阵,其中n是输入句中的单词数。表中的每个单元格[i,j]都包含了从位置i到位置j相关单词的信息。具体来说,每个单元格包含非终端符号集,这个非终端符号集可以产生从位置i到位置j的单词。
单元格[0,1]包含了可以产生句子中第一个单词的非终端符号。类似地,单元格[1,2]表示句子中的第二个单词(位置1和位置2之间的单词)。这个单元格包含的非终端符号可能会产生在句子中第二个单词。
单元格[0,2]的计算更加复杂。这个单元格表示了从位置0跨越到位置2之间的单词信息。这种组合的单词跨度可以分为两部分:第一部分是从位置0到位置1,第二部分是从位置1到位置2。这两个部分分别由单元格[0,1]和[1,2]表示。这两个单元格中的非终端符号以各种可能的组合方式进行组合,并且算法搜索任何可能产生这些组合的产生式规则。如果存在这样的产生式规则,那么规则左侧的非终端符号将被放置在单元格[0,2]中。
类似地,单元格[0,3]表示了从位置0跨越到位置3的单词信息。但是,由于这个跨度可以按几种不同的方式划分。它或者可以从位置1后开始划分,将其分为两部分:第一部分在位置0和位置1之间,第二部分在位置1和位置3之间。又或者,它可以从位置2后开始划分,第一部分在位置0和位置2之间,第二部分在位置2和位置3之间,因此这个单元格值的计算更加困难。
如果在位置1之后开始划分,那么我们将使用单元格[0,1]和[1,3],并组合它们的非终端符号;如果在位置2之后开始划分,我们将使用单元格[0,2]和[2,3],并组合它们的非终端符号。我们必须使用这两个划分方法来获取单元格[0,3]的非终端符号的总数。以这种方式继续,我们使用先前单元格的中间结果构建表,直至达到[0,n]。这个单元格表示位置0和n之间的词,这些词组成了整个输入的句子因此,单元格[0,n]包含了所有非终端符号,这些符号可以用来为输入的句子构建一棵解析树。在表中,我们可以使用反向指针,将最终单元格与生成它的中间单元格连接起来,获得在句子解析中正确的非终端符号序列。
自然语言处理书籍推荐
自然语言处理实战 利用Python理解、分析和生成文本

1.本书是构建能够阅读和解释人类语言的机器的实用指南;
2.读者可以使用现有的Python 包来捕获文本的含义并相应地做出响应;
3.本书扩展了传统的自然语言处理方法,包括神经网络、现代深度学习算法和生成技术,用于解决真实世界的问题,如提取日期和名称、合成文本和回答无固定格式的问题;
4.提供源代码。
本书是介绍自然语言处理(NLP)和深度学习的实战书。NLP已成为深度学习的核心应用领域,而深度学习是NLP研究和应用中的必要工具。本书分为3部分:第一部分介绍NLP基础,包括分词、TF-IDF向量化以及从词频向量到语义向量的转换;第二部分讲述深度学习,包含神经网络、词向量、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)网络、序列到序列建模和注意力机制等基本的深度学习模型和方法;第三部分介绍实战方面的内容,包括信息提取、问答系统、人机对话等真实世界系统的模型构建、性能挑战以及应对方法。
本书面向中高级Python开发人员,兼具基础理论与编程实战,是现代NLP领域从业者的实用参考书。
Python自然语言处理

《Python自然语言处理》是自然语言处理领域的一本实用入门指南,旨在帮助读者学习如何编写程序来分析书面语言。《Python自然语言处理》基于Python编程语言以及一个名为NLTK的自然语言工具包的开源库,但并不要求读者有Python编程的经验。全书共11章,按照难易程度顺序编排。第1章到第3章介绍了语言处理的基础,讲述如何使用小的Python程序分析感兴趣的文本信息。第4章讨论结构化程序设计,以巩固前面几章中介绍的编程要点。第5章到第7章介绍语言处理的基本原理,包括标注、分类和信息提取等。第8章到第10章介绍了句子解析、句法结构识别和句意表达方法。第11章介绍了如何有效管理语言数据。后记部分简要讨论了NLP领域的过去和未来。
《Python自然语言处理》的实践性很强,包括上百个实际可用的例子和分级练习。《Python自然语言处理》可供读者用于自学,也可以作为自然语言处理或计算语言学课程的教科书,还可以作为人工智能、文本挖掘、语料库语言学等课程的补充读物。
以上是关于自然语言处理的句法和形式语法的主要内容,如果未能解决你的问题,请参考以下文章