进程在内存中的样子!以及进程的一生
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进程在内存中的样子!以及进程的一生相关的知识,希望对你有一定的参考价值。
1. 什么是进程
简单来讲,进程就是运行中的程序。
进一步讲,进程是在用户空间中,加载器根据程序头提供的信息,将程序加载到内存并运行的实体。
1.1 进程的虚拟空间
ELF 文件头中指定的程序入口地址,以及各个节区在程序运行时的内存排布地址等,指的都是在进程虚拟空间中的地址。
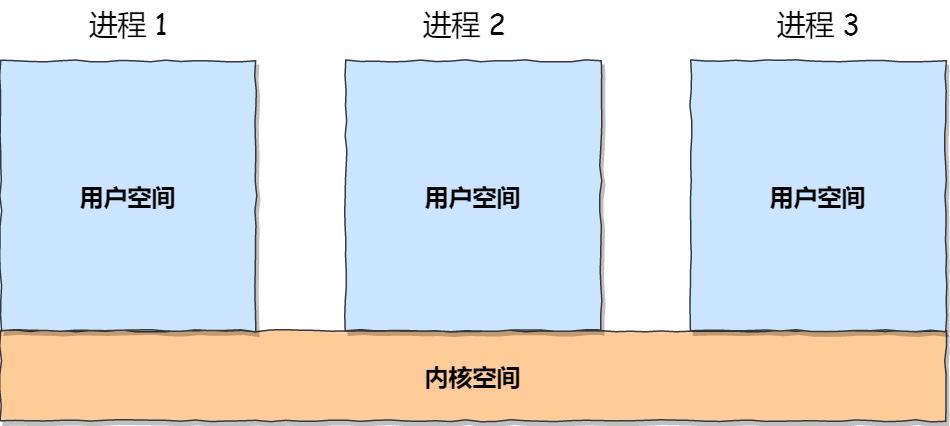
虚拟空间可以认为是操作系统给每个进程准备的沙盒,每个进程只存活在自己的虚拟世界里,却感觉自己独占了所有的系统资源(内存)。
当一个进程要使用某块内存时,它会将自己世界里的一个内存地址告诉操作系统,剩下的事情就由操作系统接管了。操作系统中的内存管理策略将决定映射哪块真实的物理内存,供其使用。操作系统会竭尽全力满足所有进程合法的内存访问请求。一旦发现进程试图访问非法内存,操作系统会把进程杀死,防止它做“坏事”影响到系统或其它进程。
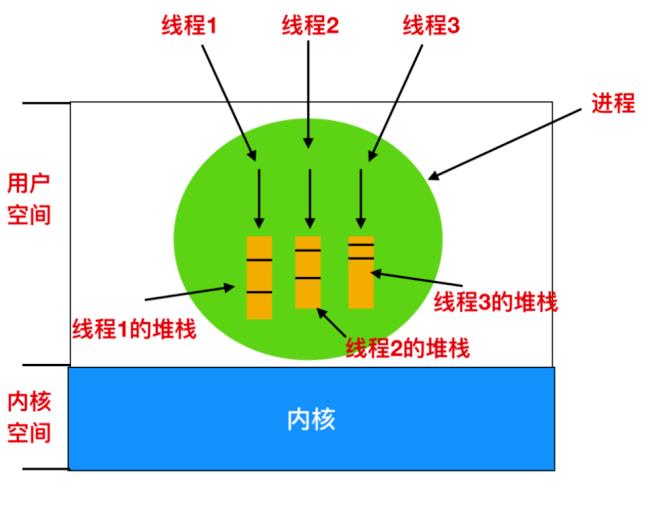
如上图,每个进程都有自己的堆栈、可读可写的数据段等。
1.2 虚拟空间的好处
一方面为了安全,防止进程操作其它进程或者系统内核的数据;
另一方面为了保证系统可同时运行多个进程,且单个进程使用的内存空间可以超过实际的物理内存容量。
该做法的另一个结果则是降低了每个进程内存管理的复杂度,进程只需关心如何使用自己线性排列的虚拟地址,而不需关心物理内存的实际容量,以及如何使用真实的物理内存。
1.3 虚拟空间地址排布
在 32 位系统下,进程的虚拟地址空间有 4G (2^32 Bytes),其中的 1G 分配给了内核空间,用户可以使用剩余的 3G。在 64 位的 Linux 系统上,进程的虚拟地址空间可以达到 256TB,内核和应用分别占用 128TB。目前来看,这样的地址空间范围足够用了。
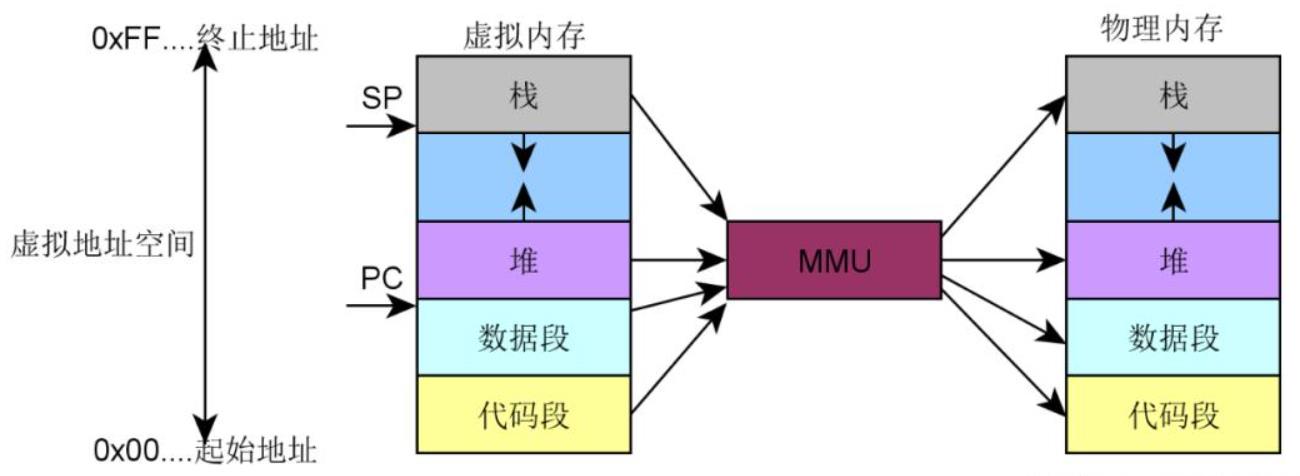
一个典型的内存排布结构如下图所示:

其中,#1 部分是按照 ELF 文件中的程序头信息,加载文件内容所得到的。除此之外,加载器还会为每个应用分配栈区(Stack)、堆区(Heap)和动态链接库加载区。
栈和堆分别向相对的方向增长,系统会有相应的保护措施,阻止越界行为发生。
在 Linux 系统中,使用如下命令可查看一个运行中的进程的内存排布。
cat /proc/PID/maps实例
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
static char static_data[16] = "I'm Static Data";
static char raw_static_data[40960];
static const char const_data[16] = "I'm Const Data";
int main(int args, char **argv)
{
printf("Message In Main\\n");
while (1) {
sleep(1);
}
return 0;
}liyongjun@Box:~/project/c/C_study/tmp$ ps -ef | grep elfdemo
liyongj+ 19786 19785 0 12:23 pts/0 00:00:00 ./tmp/elfdemo.out
liyongjun@Box:~/project/c/C_study/tmp$ cat /proc/19786/maps
560ca27b1000-560ca27b2000 r--p 00000000 08:05 3014892 /home/liyongjun/project/c/C_study/tmp/elfdemo.out
560ca27b2000-560ca27b3000 r-xp 00001000 08:05 3014892 /home/liyongjun/project/c/C_study/tmp/elfdemo.out
560ca27b3000-560ca27b4000 r--p 00002000 08:05 3014892 /home/liyongjun/project/c/C_study/tmp/elfdemo.out
560ca27b4000-560ca27b5000 r--p 00002000 08:05 3014892 /home/liyongjun/project/c/C_study/tmp/elfdemo.out
560ca27b5000-560ca27b6000 rw-p 00003000 08:05 3014892 /home/liyongjun/project/c/C_study/tmp/elfdemo.out
560ca27b6000-560ca27c0000 rw-p 00000000 00:00 0
560ca37a0000-560ca37c1000 rw-p 00000000 00:00 0 [heap]
7f139d870000-7f139d895000 r--p 00000000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139d895000-7f139da0d000 r-xp 00025000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139da0d000-7f139da57000 r--p 0019d000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139da57000-7f139da58000 ---p 001e7000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139da58000-7f139da5b000 r--p 001e7000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139da5b000-7f139da5e000 rw-p 001ea000 08:05 657544 /usr/lib/x86_64-linux-gnu/libc-2.31.so
7f139da5e000-7f139da64000 rw-p 00000000 00:00 0
7f139da76000-7f139da77000 r--p 00000000 08:05 657540 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f139da77000-7f139da9a000 r-xp 00001000 08:05 657540 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f139da9a000-7f139daa2000 r--p 00024000 08:05 657540 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f139daa3000-7f139daa4000 r--p 0002c000 08:05 657540 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f139daa4000-7f139daa5000 rw-p 0002d000 08:05 657540 /usr/lib/x86_64-linux-gnu/ld-2.31.so
7f139daa5000-7f139daa6000 rw-p 00000000 00:00 0
7ffe3e71b000-7ffe3e73c000 rw-p 00000000 00:00 0 [stack]
7ffe3e7e1000-7ffe3e7e4000 r--p 00000000 00:00 0 [vvar]
7ffe3e7e4000-7ffe3e7e5000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]2. 进程的启动
从用户角度来看,启动一个进程有许多种方式,可以配置开机自启动,可以在 shell 中手动运行,也可以从脚本或其它进程中启动。
而从开发人员角度看,无非就是两个系统调用,即 fork() 和 execve()。下面就来探究下这两个系统调用的行为细节。
2.1 fork() 系统调用
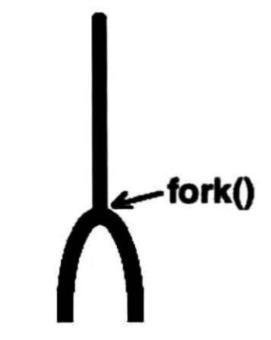
fork() 系统调用将创建一个与父进程几乎一样的新进程,之后继续执行下面的指令。程序可以根据 fork() 的返回值,确定当前处于父进程中,还是子进程中——在父进程中,返回值为新创建子进程的进程 ID,在子进程中,返回值是 0。一些使用多进程模型的服务器程序(比如 sshd),就是通过 fork() 系统调用来实现的,每当新用户接入时,系统就会专门创建一个新进程,来服务该用户。
fork() 系统调用所创建的新进程,与其父进程的内存布局和数据几乎一模一样。在内核中,它们的代码段所在的只读存储区会共享相同的物理内存页;而可读可写的数据段、堆及栈等内存,内核会使用写时拷贝技术,为每个进程独立创建一份。
在 fork() 系统调用刚刚执行完的那一刻,子进程即可拥有一份与父进程完全一样的数据拷贝。对于已打开的文件,内核会增加每个文件描述符的引用计数,每个进程都可以用相同的文件句柄访问同一个文件。
深入理解了这些底层行为细节,就可以顺理成章地理解 fork() 的一些行为表现和正确使用规范,无需死记硬背,也可获得一些别人踩过坑后才能获得的经验。
比如,使用多进程模型的网络服务程序中,为什么要在子进程中关闭监听套接字,同时要在父进程中关闭新连接的套接字呢?
原因在于 fork() 执行之后,所有已经打开的套接字都被增加了引用计数,在其中任一个进程中都无法彻底关闭套接字,只能减少该文件的引用计数。因此,在 fork() 之后,每个进程立即关闭不再需要的文件是个好的策略,否则很容易导致大量没有正确关闭的文件一直占用系统资源的现象。这让我想到了管道,父子进程各自关闭自己不使用的一端,当时很疑惑,干嘛要关啊,不用就不用呗,放那碍你啥事了,现在想想,出于安全考虑,关闭确实是个好习惯。
2.2 execve() 系统调用
execve() 系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。
execve() 系统调用通常与 fork() 系统调用配合使用。从一个进程中启动另一个程序时,通常是先 fork() 一个子进程,然后在子进程中使用 execve() 变身为运行指定程序的进程。例如,当用户在 Shell 下输入一条命令启动指定程序时,Shell 就是先 fork() 了自身进程,然后在子进程中使用 execve() 来运行指定的程序。
需要注意的是,exec 系列函数的返回值只在遇到错误的时候才有意义。如果新程序成功地被执行,那么当前进程的所有数据就都被新进程替换掉了,所以永远也不会有任何返回值。
对于已打开文件的处理,在 exec() 系列函数执行之前,应该确保全部关闭。因为 exec() 调用之后,当前进程就完全变身成另外一个进程了,老进程的所有数据都不存在了。如果 exec() 调用失败,当前打开的文件状态应该被保留下来。让应用层处理这种情况会非常棘手,而且有些文件可能是在某个库函数内部打开的,应用对此并不知情,更谈不上正确地维护它们的状态了。
所以,对于执行 exec() 函数的应用,应该总是使用内核为文件提供的执行时关闭标志(FD_CLOEXEC)。设置了该标志之后,如果 exec() 执行成功,文件就会被自动关闭;如果 exec() 执行失败,那么文件会继续保持打开状态。使用系统调用 fcntl() 可以设置该标志。
3. 监控子进程状态
在 Linux 应用中,父进程需要监控其创建的所有子进程的退出状态,可以通过如下几个系统调用来实现。
pid_t wait(int * statua)一直阻塞地等待任意一个子进程退出,返回值为退出的子进程的 ID,status 中包含子进程设置的退出标志。
pid_t waitpid(pid_t pid, int * status, int options)可以用 pid 参数指定要等待的进程或进程组的 ID,options 可以控制是否阻塞,以及是否监控因信号而停止的子进程等。
int waittid(idtype_t idtype, id_t id, siginfo_t *infop, int options)提供比 waitpid 更加精细的控制选项来监控指定子进程的运行状态。
wait3() 和 wait4() 系统调用可以在子进程退出时,获取到子进程的资源使用数据。
更详细的信息请参考帮助手册。
重点讨论:即使父进程在业务逻辑上不关心子进程的终止状态,也需要使用 wait 类系统调用,原因如下:
在 Linux 的内核实现中,允许父进程在子进程创建之后的任意时刻用 wait() 系列系统调用来确定子进程的状态。
也就是说,如果子进程在父进程调用 wait() 之前就终止了,内核需要保留该子进程的终止状态和资源使用等数据,直到父进程执行 wait() 把这些数据取走。
在子进程终止到父进程获取退出状态之间的这段时间,这个进程会变成所谓的僵尸状态,在该状态下,任何信号都无法结束它。如果系统中存在大量此类僵尸进程,势必会占用大量内核资源,甚至会导致新进程创建失败。
如果父进程也终止,那么 init 进程会接管这些僵尸进程并自动调用 wait ,从而把它们从系统中移除。但是对于长期运行的服务器程序,这一定不是开发者希望看到的结果。所以,父进程一定要仔细维护好它创建的所有子进程的状态,防止僵尸进程的产生。
4. 进程的终止
正常终止一个进程可以用 _exit 系统调用来实现,原型为:
void _exit(int status);其中 status 会返回 wait() 类的系统调用。进程退出时会清理掉该进程占用的所有系统资源,包括关闭打开的文件描述符、释放持有的文件锁和内存锁、取消内存映射等,还会给一些子进程发送信号。该系统调用一定会成功,永远不会返回。
在退出之前,还希望做一些个性化的清理操作,可以使用库函数 exit() 。函数原型为:
void exit(int status);这个库函数先调用退出处理程序,然后再利用 status 参数调用 _exit() 系统调用。这里的退出处理程序可以通过 atexit() 或 on_exit() 函数注册。其中 atexit() 只能注册返回值和参数都为空的回调函数,而 on_exit() 可以注册带参数的回调函数。退出处理函数的执行顺序与注册顺序相反。它们的函数原型如下所示:
int atexit(void (*func)(void));
int on_exit(void (*func)(int, void *), void *arg);通常情况下,个性化的退出处理函数只会在主进程中执行一次,所以 exit() 函数一般在主进程中使用,而在子进程中只使用 _exit() 系统调用结束当前进程。
以上是关于进程在内存中的样子!以及进程的一生的主要内容,如果未能解决你的问题,请参考以下文章