❤️通宵爆肝两万字xpath教程+实战练习❤️
Posted 川川菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️通宵爆肝两万字xpath教程+实战练习❤️相关的知识,希望对你有一定的参考价值。
文章目录
一、必看内容!!!
1)简短介绍
XPath 是一种用于寻址 XML 文档部分的语言。它在 XSLT 中使用并且是 XQuery 的子集。这个库也可用于大多数其他编程语言。
2)必备知识
- 了解基本的html和xml语法和格式
- 没有了,如果你不会html和xml,超过2000收藏,我出一篇html详细教程,至于怎么达到2000赞,看各位粉丝了。
3)为什么我要写这篇文章?
在我前面的几十篇文章,写了上百万字把python的所有基础已经讲得很明白了,不管你是不是小白,跟着学都能学会,同时在我的粉丝群,我还会对教程中的问题进行答疑,所以包教包会的口号,我从来不是吹的。
这里是我的基础教程专栏:python全栈基础详细教程专栏系列
当然,如果你对qq机器人制作感兴趣请查看专栏:qq机器人制作详细教程专栏
这两个专栏,我为什么放在一起?第一个专栏是基础教程,第二个专栏是进阶,所以你在不会基础之前,请不要冒然学习机器人制作。
说了半天,我还没说为什么写这一篇的原因,前面的基础我已经差不多写完了,基础不会的自己去看我专栏,上百万字写基础,我已经很用心教大家了。基础过后,我们即将开始学爬虫,因此xpath你不得不掌握。认真跟着我学,多看几天就会了。
4)强烈推荐教程专栏
其它专栏,看你自己个人兴趣,这五个专栏我是主打,并是我强烈推荐。
二、开始使用xpath
2.1 常见的 HTML 操作
如果有一段html如下:
<html>
<body>
<a>link</a>
<div class='container' id='divone'>
<p class='common' id='enclosedone'>Element One</p>
<p class='common' id='enclosedtwo'>Element Two</p>
</div>
</body>
</html>
在整个页面中查找具有特定 id 的元素:
//*[@id='divone'] # 返回 <div class='container' id='divone'>
在特定路径中查找具有特定 id 的元素:
/html/body/div/p[@id='enclosedone'] # 返回 <p class='common' id='enclosedone'>Element One</p>
选择具有特定 id 和 class 的元素:
//p[@id='enclosedone' and @class='common'] #返回 <p class='common' id='enclosedone'>Element One</p>
选择特定元素的文本:
//*[@id='enclosedone']/text() # 返回 Element One
2.2 常见XML操作
比如有如下xml:
<r>
<e a="1"/>
<f a="2" b="1">Text 1</f>
<f/>
<g>
<i c="2">Text 2</i>
Text 3
<j>Text 4</j>
</g>
</r>
2.2.1 选择一个元素
用xpath
/r/e
将选择此元素:
<e a="1"/>
2.2.2 选择文字
用xpath:
/r/f/text()
将选择具有此字符串值的文本节点:
"Text 1"
而这个 XPath:
string(/r/f)
返回同样是:
"Text 1"
2.3 浏览器使用xpath调试
步骤如下:
- 按F12进入控制台
- 按ctrl+F进入搜索框
- 将自己写的xpath输入进去,回车看看能不能匹配到
2.3.1演示案例一
以我自己的主页网址为例:
https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343
分析:
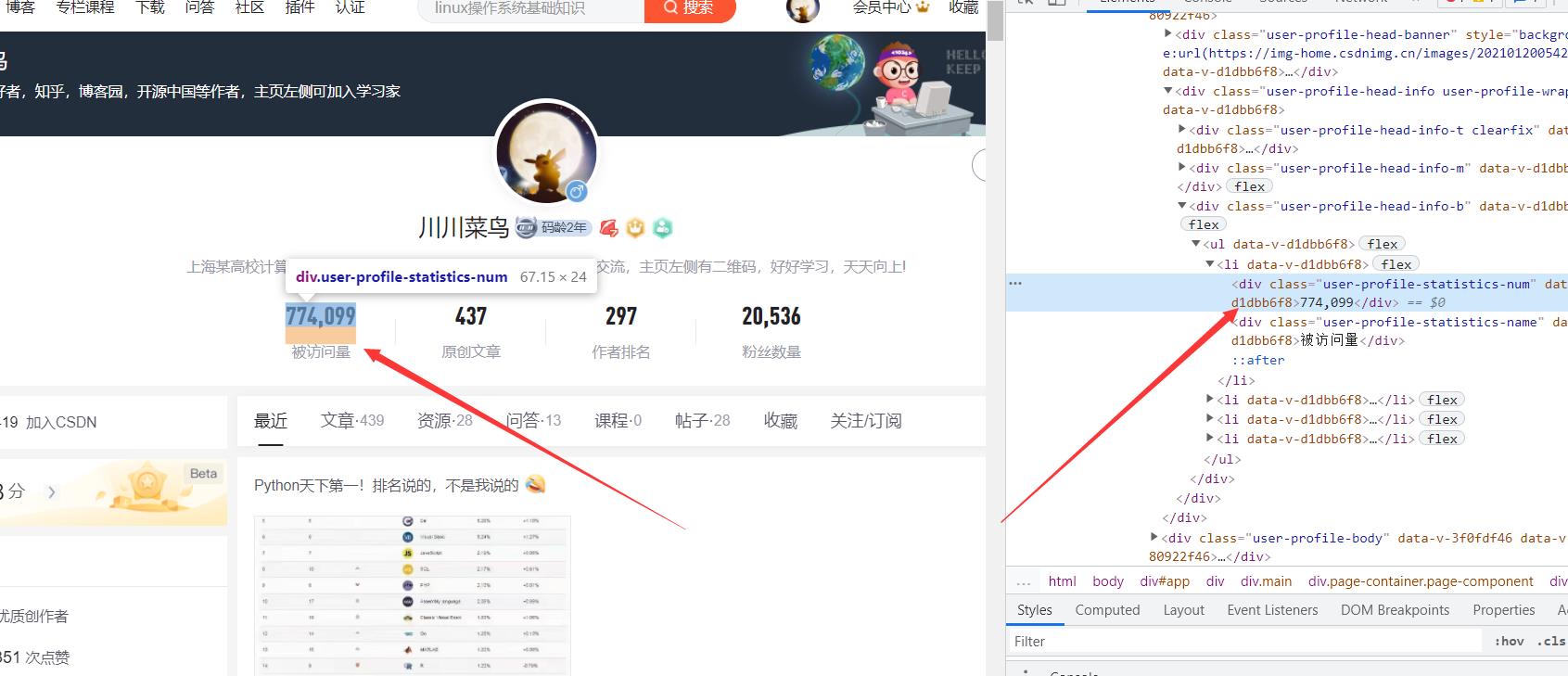
锁定定位为:
user-profile-statistics-num
则xpath写为:
//div[@class="user-profile-statistics-num"]
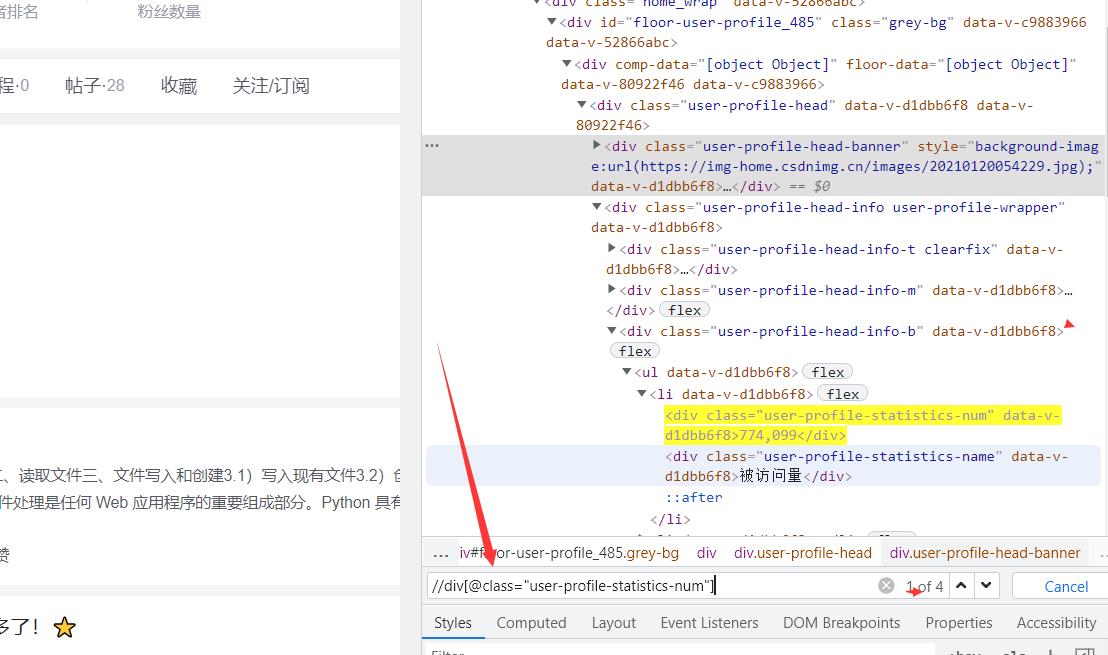
以上就是一种简单的调试xpath方法,难的我就不介绍了,没必要吧,如果大家觉得有必要,评论区留言,人多我就重新编辑补充。
三、检查节点是否存在
我们使用布尔来检查我们写的xpath是否存在,布尔真是一个很不错的东西。
3.1 案例一
这里我就构造一个xml如下:
<House>
<LivingRoom>
<plant name="rose"/>
</LivingRoom>
<TerraceGarden>
<plant name="passion fruit"/>
<plant name="lily"/>
<plant name="golden duranta"/>
</TerraceGarden>
</House>
使用布尔来判断:
boolean(/House//plant)
输出:
true
说明该路径正确。
3.2 案例二
假设有这样一个xml:
<Animal>
<legs>4</legs>
<eyes>2</eyes>
<horns>2</horns>
<tail>1</tail>
</Animal>
使用布尔判断:
boolean(/Animal/tusks)
输出:
false
说明这个路径是错的。
四、检查节点的文本是否为空
语法:
- 布尔(路径到节点/文本())
- 字符串(路径节点)!= ‘’ ”
其他用途:
- 检查节点是否存在
- 检查参数是否不是数字 (NaN) 或 0
4.1 案例一
假设我构造这样一个xml:
<Deborah>
<address>Dark world</address>
<master>Babadi</master>
<ID>#0</ID>
<colour>red</colour>
<side>evil</side>
</Deborah>
用布尔判断:
boolean(/Deborah/master/text())
或者用string判断:
string(/Deborah/master) != ''
输出都为:
true
说明文本不为空。
4.2 案例二
假设我构造这样一个xml:
<Dobby>
<address>Hogwartz</address>
<master></master>
<colour>wheatish</colour>
<side>all good</side>
</Dobby>
用布尔判断:
boolean(/Dobby/master/text())
或者用string判断:
string(/Dobby/master) != ''
输出:
false
说明文本为空。
五、通过属性查询
说一些比较常见的语法:
- /从当前节点选取直接子节点
- //从当前节点选取子孙节点
- .选取当前节点
- …选取当前节点的父节点
- @选取属性
- *代表所有
例如:
//title[@lang=’chuan’]
这就是一个 XPath 规则,它就代表选择所有名称为 title,同时属性 lang 的值为 chuan的节点。
5.1 查找具有特定属性的节点
假设有这样一个xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径匹配如下:
/Galaxy/*[@name]
或者:
//*[@name]
输出:
<CelestialObject name="Earth" type="planet" />
<CelestialObject name="Sun" type="star" />
5.2 通过属性值的子串匹配来查找节点
假设有如下例子:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径:
/Galaxy/*[contains(@name,'Ear')]
值得补充的是,这里的contains函数就是代表包含的意思,这里就是查找Galaxy路径下,所有name属性中含有Ear的节点。
如上,我们也可以如下方式匹配:
//*[contains(@name,'Ear')]
双引号也可以用来代替单引号:
/Galaxy/*[contains(@name, "Ear")]
输出:
<CelestialObject name="Earth" type="planet" />
5.3 通过属性值的子字符串匹配查找节点(不区分大小写)
假设有xml如下:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径
/Galaxy/*[contains(lower-case(@name),'ear')]
这里又出现了新的东西,加入 lower-case() 函数就是来保证我们可以包括所有的大小写情况。
路径
/Galaxy/*[contains(lower-case(@name),'ear')]
或者
//*[contains(lower-case(@name),'ear')]
或者,使用双引号中的字符串:
//*[contains(lower-case(@name), "ear")]
输出
<CelestialObject name="Earth" type="planet" />
5.4 通过匹配属性值末尾的子字符串查找节点
假设有xml如下:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径
/Galaxy/*[ends-with(lower-case(@type),'tar')]
补充:这里又出现了新的函数,ends-with就是匹配以xx结尾。
或者
//*[ends-with(lower-case(@type),'tar')]
输出
<CelestialObject name="Sun" type="star" />
5.5 通过匹配属性值开头的子字符串查找节点
假设有这个xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径
/Galaxy/*[starts-with(lower-case(@name),'ear')]
补充:这里又出现了新的函数,starts-with就是匹配以什么开头。
或者
//*[starts-with(lower-case(@name),'ear')]
输出
<CelestialObject name="Earth" type="planet" />
5.6 查找具有特定属性值的节点
假设有这个xml:
<Galaxy>
<name>Milky Way</name>
<CelestialObject name="Earth" type="planet"/>
<CelestialObject name="Sun" type="star"/>
</Galaxy>
路径
/Galaxy/*[@name='Sun']
补充:这里就是我开头说到的,星号代表所有,@用来选取属性
或者
//*[@name='Sun']
输出
<CelestialObject name="Sun" type="star" />
六、查找包含特定属性的元素
6.1 查找具有特定属性的所有元素(1)
假设有xml如下:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
xpath匹配:
/root/element[@foobar]
返回:
<element foobar="hello_world" />
6.2 查找具有特定属性值的所有元素(2)
假设有xml如下:
<root>
<element foobar="hello_world" />
<element example="this is one!" />
</root>
以下 XPath 表达式:
/root/element[@foobar = 'hello_world']
将返回
<element foobar="hello_world" />
也可以使用双引号:
/root/element[@foobar="hello_world"]
粉丝群:970353786
七、查找包含特定文本的元素
假设有xml如下:
<root>
<element>hello</element>
<another>
hello
</another>
<example>Hello, <nested> I am an example </nested>.</example>
</root>
以下 XPath 表达式:
//*[text() = 'hello']
将返回<element>hello</element>元素,但不返回元素。这是因为该<another>元素包含hello文本周围的空格。
要同时检索<element>and <another>,可以使用:
//*[normalize-space(text()) = 'hello']
补充:这里又多了新的函数,normalize-space作用就是去除空白的意思。
要查找包含特定文本的元素,您可以使用该contains函数。以下表达式将返回<example>元素:
//example[contains(text(), 'Hello')]
如果要查找跨越多个子/文本节点的文本,则可以使用.代替text()。.指元素及其子元素的整个文本内容。
例如:
//example[. = 'Hello, I am an example .']
要查看多个文本节点,您可以使用:
//example//text()
这将返回:
- “hello, ”
- “I am an example”
- “.”
为了更清楚地看到一个元素的整个文本内容,可以使用该string函数:
string(//example[1])
要不就
string(//example)
依然返回:
Hello, I am an example .
八、多次强调的语法
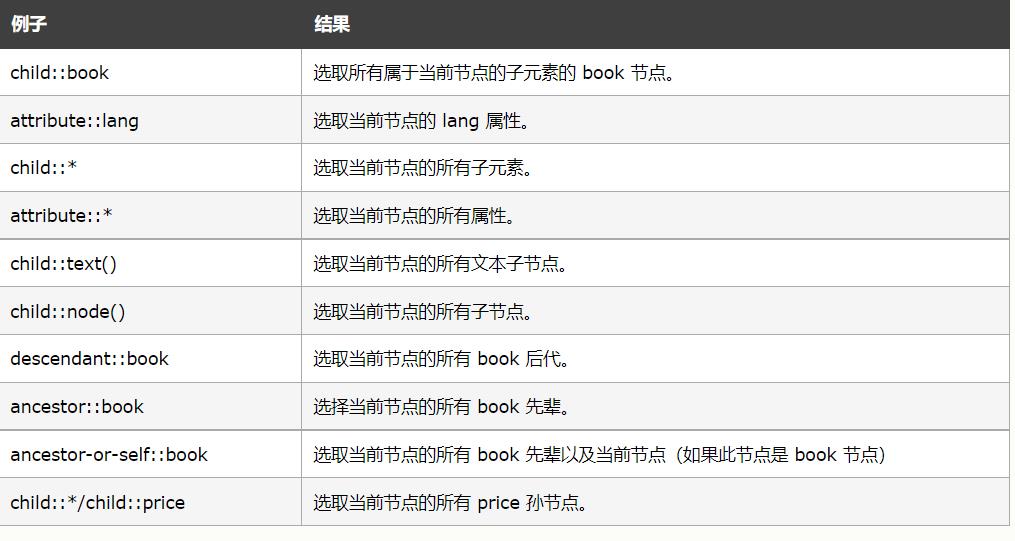
8.1 XPath 轴的语法
现在我们要补充新的东西,又要开始记住了:
ancestor 选取当前节点的所有先辈(父、祖父等)。
ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
attribute 选取当前节点的所有属性。
child 选取当前节点的所有子元素。
descendant 选取当前节点的所有后代元素(子、孙等)。
descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。
following 选取文档中当前节点的结束标签之后的所有节点。
namespace 选取当前节点的所有命名空间节点。
parent 选取当前节点的父节点。
preceding 选取文档中当前节点的开始标签之前的所有节点。
preceding-sibling 选取当前节点之前的所有同级节点。
self 选取当前节点。
8.2 XPath选取节点语法
为什么我在这里又来强调一下?因为很重要!
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
在下面的表格中,列出了一些路径表达式以及表达式的结果:
bookstore 选取 bookstore 元素的所有子节点。
/bookstore 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。
//book 选取所有 book 子元素,而不管它们在文档中的位置。
bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。
//@lang 选取名为 lang 的所有属性。
8.3 Xpath谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
看一些例子就知道了:
路径表达式 结果
/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
8.4 Xpath选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述
* 匹配任何元素节点。
@* 匹配任何属性节点。
node() 匹配任何类型的节点。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果
/bookstore/* 选取 bookstore 元素的所有子元素。
//* 选取文档中的所有元素。
//title[@*] 选取所有带有属性的 title 元素。
8.5 Xpath选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果:
路径表达式 结果
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
//title | //price 选取文档中的所有 title 和 price 元素。
/bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
九、获取相对于当前节点的节点
假设我们有xml如下:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
9.1 基本语法

其实这些内容,大可不必都掌握,但是你一定要知道,你想用的时候,再来本文查一下会用就行。
这是相关实例:
问题是:这里提到的祖先,孩子,兄弟,父母节点,大家知道吗?如果你会html的话,你应该知道。超过2000赞我可以出一篇html的教程,本篇我就暂时默认大家知道了。
9.2 寻找祖先节点
假设有xml如下:(这里已经很形象说明了祖先,孩子,兄弟,父母节点的关系了,仔细看看)
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male"/>
<brother name="Goten" gender="male"/>
</Dad>
</GrandFather>
路径
//Me/ancestor::node()
输出:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
9.4 寻找兄弟节点
假设有xml如下:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<brother name="Goten" gender="male" />
<Me name="Gohan" gender="male" />
<brother name="Goten" gender="male" />
</Dad>
</GrandFather>
路径:
//Me/following-sibling::brother
输出:
<brother name="Goten" gender="male" />
9.5 寻找祖父节点(2)
假设有xml如下:
<GrandFather name="Bardock" gender="male" spouse="Gine">
<Dad name="Goku" gender="male" spouse="Chi Chi">
<Me name以上是关于❤️通宵爆肝两万字xpath教程+实战练习❤️的主要内容,如果未能解决你的问题,请参考以下文章