MongoDB之增删改查全套语法锦囊⭐️初学者福利
Posted 王小王-123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB之增删改查全套语法锦囊⭐️初学者福利相关的知识,希望对你有一定的参考价值。
目录
MongoDB概念
点击标题,即可跳转到博主详情文章,本文介绍了MongoDB的概念和基本的知识,至于MongoDB到底可以用来做什么,数据库的存储,而且是大数据的存储,因为MongoDB是基于大数据分布式集群所建立的,广泛的应用在数据量大的操作之上,我们可以把数据存储在MongoDB集群上。

MongoDB Shell 基本命令
1.基本概念
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
| database | db | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
文档的基本结构:{ : , : {}, ... }
封闭符 {}
分隔符 ,
连接符 :
键的数据类型:UTF-8字符,可以用”“引起来,如”name“
的用户命名规则:
(1)'_id' 为保留字段key
(2) 禁止使用'$'符号
(3) 禁止使用'.'符号
(4) 避免同一个{}中使用重复的
值的数据类型:MongoDB支持的任意数据类型
示例一:
{ "_id" : 1, "name" : "Zhang San" }
示例二:
{
"_id" : ObjectId("5e746c62040a548ab32fff13"), //ObjectId对象
"name" : "Zhang San",// 字符串
"age" : 18,// 数字
"alive" : true, // 布尔值
"hobbies" : ["Anime","Comic","Game", 19], // 列表(数组)
"body": {
"height" : 170,
"weight" : 65
}, // 内嵌文档
"courses" : [
{ "coursename" : "nosql" },
{ "coursename" : "mysql" },
{ "coursename" : "python" },
{ "coursename" : "linux" },
{ "coursename" : "kettle" }
] // 内嵌文档的列表
}
MongoDB的基本数据类型
| 数据类型 | 描述 |
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是 合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Arrays | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊 符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时 间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 javascript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
3.数据库(db)
// 查看当前服务器上的数据库
show dbs;
show databases;
// 选择名为mydb的数据库(如果没有则创建)
use mydb;
// 查看当前使用的数据库
db;
// 查看当前数据库的统计信息
db.stats();
// 查看当前数据库的操作信息
db.currentOp();
// 删除当前数据库
db.dropDatabase();3. 集合(collection)
// 查看当前数据库中的集合
show collections;
show tables;
// 创建一个名为mycoll的集合
db.createCollection("mycoll");
// 重命名mycoll集合,新集合名叫mycollection
db.mycoll.renameCollection("mycollectioin")
// 清空一个名为mycollection的集合
db.mycollection.remove({});
// 删除一个名问mycollection的集合
db.mycollection.drop();3.1 添加文档到集合
insert() 方法
注意:db.collection中,collection为你要操作的集合的名称
db.collection.insert(
<document or array of documents>,
{multi: false}
)insertOne() 方法
添加一条文档记录
db.collection.insertOne(
<document>{}
)insertMany() 方法
添加多条文档记录 ([]方括号表示数组)
db.collection.insertMany(
[ <document 1> {} , <document 2> {}, ... ] --jsonArray
)// 添加一条文档记录{"lastname":"wang", "firstname":"xiaowang"}到集合mycollection
db.mycollection.insert({"lastname":"wang", "firstname":"xiaowang"});
db.mycollection.insertOne({"lastname":"wang", "firstname":"wang"});
// 添加一个文档记录对象mydoc到集合mycollection, 使用insert或insertOne方法
var mydoc = {"lastname":"wang", "firstname":"xiaowang"};
db.mycollection.insert(mydoc);
// 3.2版后新的方法:insertOne
db.mycollection.insertOne(mydoc);
// 添加多条记录到集合mycollection,使用insert或insertMany方法
// 多条文档记录,用[]组合,用逗号分隔
db.mycollection.insert(
[
{"lastname":"wang", "firstname":"xiaowang", "role":"teacher",
"teacher_id":"123", "title":"讲师", "courses":[{"coursename":"nosql"},
{"coursename":"mysql"}]},
{"lastname":"wang", "firstname":"xiaowang", "role":"student",
"student_id":"456", "grade":"2019", "class":"1", "score":100}
] )
;
// 添加一个文档数组mydocs(多条文档的数组)到集合mycollection,使用insert或insertMany方法
// 多条文档记录用[]组合到一个数组mydocs中。
// 注意 coursename处于两个花括号中,属于两个内嵌的文档,不算重复的键
var mydocs = [
{
"lastname" : "wang",
"firstname" : "xiaowanag",
"role" : "teacher",
"teacher_id" : "2019814",
"title" : "讲师",
"courses" : [
{ "coursename" : "nosql" },
{ "coursename" : "mysql" },
{ "coursename" : "python" },
{ "coursename" : "linux" },
{ "coursename" : "kettle" }
]
},
{
"lastname" : "xiaowang1",
"firstname" : "wang",
"role" : "student",
"student_id" : "2019000001",
"grade" : "2019",
"class" : "1",
"score" : 80
},
{
"lastname" : "w",
"firstname" : "Er",
"role" : "student",
"student_id" : "2019000002",
"grade" : "2019",
"class" : "1",
"score" : 70
}
];
db.mycollection.insert(mydocs);
// 3.2版后新的方法:insertMany
db.mycollection.insertMany(mydocs);注意我们的insert方法和insertMany方法,具有一样的效果
3.2 查询文档记录
find() 方法
这里给出了几种常见的查询方法,一般利用查询操作符进行查询
db.mycollection.find({"score":{$gt:70}},{student_id:1});
// 查询集合mycollection中的文档
db.mycollection.find();
// 将查询结果"漂亮化"
db.mycollection.find().pretty();
// 查询集合mycollection中键为role, 值为student的文档记录
db.mycollection.find( {"role" : "student"} );
// 将查询条件写入文档对象ceriteria查询
var criteria = { "role" : "student" };
db.mycollection.find(criteria);
// 使用内嵌对象的字段值查询
db.mycollection.find({"courses.coursename":"mysql"})| 操作 | 操作符 | 范例 | SQL 语句的类似 |
| 等于 | : | db.mycollection.find({"role":"student"}) | whererole='student' |
| 小于 less than | $lt: | db.mycollection.find({"score":{$lt:80}}) | where score < 80 |
| 小于或等于less than /equal | $lte: | db.mycollection.find({"score": {$lte:80}}) | where score <=80 |
| 大于greater than | $gt: | db.mycollection.find({"score":{$gt:80}}) | where score > 80 |
| 大于或等于greater than /equal | $gte: | db.mycollection.find({"score": {$gte:80}}) | where score >=80 |
| 不等于 not equal | $ne: | db.mycollection.find({"score":{$ne:80}}) | where score !=80 |
// 按数据类型查询
// 数值(double):1
// 字符串(string):2
// 对象(object):3
// 数组(array):4
// 二进制数据(binary):5
// 未定义(Undefined):6
// 对象ID(ObjectId): 7
// 布尔值(boolean):8
// 日期(date):9
// 空(null):10
db.mycollection.find({"score":{$type:1}});
// 查询条件的逻辑运算 (AND)
db.mycollection.find({"role":"student","score":80});
// 查询条件的逻辑运算 (OR) , 注意$or是一个数组[]
db.mycollection.find({$or:[{"role":"student"},{"role":"teacher"}]});
// 查询条件的成员运算 (IN)
db.mycollection.find({"student_id":{$in:["2019000001","2019000002"]}})
等价于:
db.mycollection.find({$or:[{"student_id":"2019000001"},
{"student_id":"2019000002"}]})
// 限制查询结果字段
// 查询role是student的文档中的score字段值(只返回_id和score)
// 类比 sql: select score from mycollection where role="student";
// projection格式: { field1: <value>, field2: <value> ... }
db.mycollection.find({role:"student"}, {score:1})
// 使用变量存放 查询文档 和 返回字段文档(包含或者排除字段 1:包含 0:排除,不能混用(可以单独排除_id))
my_query = {$or:[{"student_id":"2019000001"},{"student_id":"2019000002"}]}
my_projection = {"_id":0, "score": 1,"firstname":1, "lastname":1}
db.mycollection.find(my_query, my_projection)范例集合
courses数组中包含一个分布式的课程(course), 而且(AND), courses数组中包含大于80的分数(score)
var 查询条件1 = {
"courses.course":"分布式数据库原理与应用",
"courses.score":{$gt:80}
};
var 查询条件2 = {
"courses":{
$elemMatch:{
"course":"分布式数据库原理与应用",
"score":{$gt:90}
}
}
}; // courses数组中包含一个 分布式课程而且其分数大于80 的数组元素
var 返回条件 = {
_id:0,
sno:1,
// courses:1
courses:{$elemMatch:{"course":"分布式数据库原理与应用"}}
};
db.getCollection("students").find(查询条件2, 返回条件)3.3 更新文档记录
update operators 更新操作符
| Name | Description |
| $currentDate | $currentDate:{'字段名':{$type:'date|timestamp'}} |
| $inc | increase : 字段值+1 |
| $min | 如果更新值更小才更新 |
| $max | 如果更新值更大才更新 |
| $mul | multiply: 字段值乘n |
| $rename | 重命名字段 |
| $set | 设置一个键值对 |
| $setOnInsert | 只在文档不存在需要插入是设置的字段 |
| $unset | 删除一个键值对 |
db.collection.updateOne|updateMany|replaceOne(
<query>,
<update>,
{
upsert: <boolean>,
collation: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如 inc...)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
// 将学号(student_id)为2019000000的记录的score的值更改为90
// 类比sql: update mycollection set score=90 where student_id='2019000000';
db.mycollection.update({"student_id":"2019000000"}, {$set:{"score":90}});// 将所有的学生的的成绩(score)增加5, 注意:修改多条记录要使用{multi:true}
// 类比sql: update mycollection set score=score+5 where role='student';
db.mycollection.update({"role":"student"}, {$inc:{"score":5}}, {multi:true});// 将所有的学生的成绩提高5分
query1 = {"role":"student"}
update1 = {$inc:{"score":5}}
option1 = {}
db.mycollection.updateMany(query1, update1, option1)// 将所有2018级的学生改为2019级
query2 = {"grade":"2018"}
update2 = {$set:{"grade":"2019"}}
option2 = {}
db.mycollection.updateMany(query2, update2, option2)// 将学号为2019000003的学生的姓、名、班、级替换为指定的值
// 如果集合中没有2019000003学生,则插入这个学生信息
query3 = {"student_id":"2019000003"}
update3 = {$set:{"score":60, "class":3, "grade":"2019", "firstname":"Yanzu",
"lastname":"Wu"}}
option3 = {"upsert":true}
db.mycollection.updateOne(query3, update3, option3)注意这里使用了,upset这个参数,这个参数在上面的参数介绍里面也有过说明,如果不存在这个那么就会执行插入操作
// 也可以使用replaceOne, 注意update3的写法,不需要使用$set,... 操作符
query3 = {"student_id":"2019000004"}
update3 = {"lastname":"Wu", "firstname":"Yanzu", "grade":"2019", "class":3,
"score":60}
option3 = {"upsert":true}
db.mycollection.replaceOne(query3, update3, option3)update数组中的元素
// $push: 向数组的尾部添加一个元素,如果字段不存在则创建
// $push + $each : 批量push,将$each:[]中的元素依次push到数组中
// $pushAll = $push + $each 批量push
// $addToSet:不重复的set集合
// $pop: 弹出数组的头部元素或尾部元素: -1:头部,1:尾部
// $pull: 删除数组中的值
// 使用小标或者定位操作符$来操作数组 $表示querydoc中确定的数组元素
// 修改内嵌文档数组中第n个元素的值
// 定位操作符$: 查询条件一般是以数组中的元素为条件,使用$符号作为满足查询条件的第一条文档对应的下标值
3.4 删除文档记录
remove() 方法
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)deleteOne() 方法
deleteMany() 方法
db.collection.deleteOne|deleteMany(
<query>,
{
writeConcern: <document>,
collation: <document>
}
)query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值
false,则删除所有匹配条件的文档。
writeConcern :(可选)抛出异常的级别。
范例大全
// 条件删除学号为2019000002的文档记录
// 类比sql: delete from mycollection where student_id='2019000000';
db.mycollection.remove({"student_id":"2019000002"});db.mycollection.deleteMany{"student_id":"2019000002"});// 删除第一条符合条件的文档记录
db.mycollection.remove({"role":"student"},justOne:true);
// 或者
db.mycollection.deleteOne({"role":"student"});
一般的,我们使用remove就可以很好的解决问题
// 删除所有记录
db.mycollection.remove({});remove() 方法 并不会真正释放空间。需要继续执行 db.repairDatabase() 来回收磁盘空间。
db.repairDatabase()
// 或者
db.runCommand({ repairDatabase: 1 })小结:
增: db.collection.insert(newdocs)
-> db.collection.insertOne|insertMany
删: db.collection.remove(querydoc)
-> db.collection.deleteOne|deleteMany
改: db.collection.update(querydoc, updatedoc or newdoc, {upset:true})
-> db.collection.updateOne|updateMany|replaceOne
查: db.collection.find(querydoc, projection)
var query = {"courses.course":"分布式数据库原理与应用"}
var projection = {
_id:0,
major:1,
grade:1,
class:1,
courses:{$elemMatch:{"course":"分布式数据库原理与应用"}}
}
db.students.find(query,projection)4. 游标和脚本
4.1 游标的用法
声明一个游标
var mycursor = db.collection.find()hasNext() next()
var mycursor = db.collection.find()
while(mycursor.hasNext()){
printjson(mycursor.next());
}forEach()
var getScore = function(doc) {
for(i=0;i<doc.courses.length;i++) {
if(doc.courses[i].course == "分布式数据库原理与应用") {
print(doc.name, doc.courses[i].score)
}}}
var query = {"courses.course":/^分布式/};
var proje = {"_id":0, name:1, courses:1};
var curNoSQL = db.students.find(query, proje);
curNoSQL.forEach(getScore)4.2 脚本的执行
我们可以使用Navicat进行直接导入,这个一个软件给我们提供的图形界面,进行操作脚本
交互式命令load(script.js)

注意,windows路径中包含\\,在js中表示转义符,必须使用 \\\\ 来表示\\字符。
mongo命令

4.3 聚合管道 aggregate
$avg: 求平均值
$sum: 求和
$max: 求最大值
$min: 求最小值
// 按专业取所有学生的平均身高
db.getCollection("students").aggregate([
{$group:{_id:"$major", avgHeight:{$avg:"$height"}}}
])// 按专业求女生平均身高低于170的专业平均身高,并排序
/*
SQL: select AVG(height) as avgHeight, major as _id
from students
where gender=0
group by major
having avgHeight>170
sorted by avgHeight DESC
*/
db.getCollection("students").aggregate([
//第一步,查数据
{$match:{gender:0}}
//第二步,限制返回字段
,{$project:{_id:0,major:1, grade:1, class:1, height:1}}
//第三步,分组求平均值
// _id: group by的字段, 字段名要加$符号前缀,表示是一个字段名
// avgHeight: 新生成的平均值字段名
// $avg: 平均值操作符,它的值为要求平均值的字段名,注意加$前缀
,{$group:{_id:"$major", avgHeight:{$avg:"$height"}}
//第四步,筛选聚合结果
,{$match:{avgHeight:{$lte:170}}}
//第五步,排序,按照avgHeight的值从大到小排序, -1: DESC, 1:ASC
,{$sort:{avgHeight:-1}}
])/*******************************************************
*示例:按专业-年级-班级-性别 列出全校学生的平均升高
- 使用多个字段进行分组
*******************************************************/
db.getCollection("students").aggregate([
//第一步,查数据,可以不要,那么对整个集合的数据进行操作
//{$match:{gender:0}},
//第二步,限制返回字段,也可以不要,那么返回所有的字段
//{$project:{_id:0,major:1, grade:1, class:1, height:1}}
//第三步,分组求平均值,可以以多个字段联合作为分组键,当多个字段的值都相等才是一组
{$group:{_id:{专业:"$major", 年级:"$grade", 班级:"$class", 性别:"$gender"},
avgHeight:{$avg:"$height"}}}
//第四步,筛选聚合结果
// ,{$match:{avgHeight:{$lte:170}}}
//第五步,排序,按照avgHeight的值从大到小排序, -1: DESC, 1:ASC
,{$sort:{avgHeight:-1}}
])/*******************************************************
*示例:按专业-年级-班级 分组计算全校分布式数据库课程的平均分
- 使用变量定义查询条件和返回字段
- 对数组字段中的值进行聚合操作
- 使用多个字段进行分组
- 使用多个字段进行排序
*******************************************************/
var 查询条件 = {"courses.course":"分布式数据库原理与应用"}
var 返回字段 = {_id:0, major:1, grade:1, class:1, courses:1}
db.students.aggregate( [
// 第一步,查询上分布式课程的学生,注意,这里每个学生可能还有别的课程
{$match:查询条件}
// 第二步,指定返回的字段值,这里使用了前面定义的变量
,{$project: 返回字段}
// 第三步,由于课程信息是在一个数组中,所以先将数组拆开,将数据拉平
,{$unwind:"$courses"}
// 第四步,对非分布式数据库的课程信息进行过滤,只匹配分布式数据库课程的分数
,{$match:查询条件}
// 第五步,对分布式数据库的课程分数进行平均值计算
,{$group: {_id:{"m":"$major","g":"$grade",c:"$class"}, avgScore:
{$avg:"$courses.score"} } }
// 第六步,排序,1: ASE(从小到大,正序), -1: DESC(从大到小,反序)
,{$sort:{"_id.m":1,"_id.g":1, "_id.c":1}}
] )4.4 MongoDB MapReduce
1、基本语法
1)定义MapReduce操作
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values[]) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍
历 collection 中所有的记录, 将key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。这个键可以是一个常量,也可以是原始文档中
某个键的值
map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数
组变成一个单一的值value。
out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随
意组合)
sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
// mapreduce
// mapper: 采集单元数据键值对
var mapper = function(){
// key:group by 的字段,分组标准
var key = this.major
// value: 要进行聚合计算的字段
var value = 1
emit(key, value);
// {{grade:2018,gender:1}, 1}
} /
/ map -- conbine+shuffle -> reduce
// {{grade:2018,gender:1}, [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]}
// reducer: 聚合数据, 产生一个单值数据
var reducer = function(key,values){
// key: {grade:2018,gender:1}
// values [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
var result = Array.sum(values)
return result
} /
/ options: 设置输入输出
var options = {out:"output", query:{}}
db.students.mapReduce(mapper, reducer, options)
db.output.find()// 求全体学生的平均身高
// map方法将每一个集合中的文档转化成如 {"全体学生",171},{"全体学生",171}...的输出
var mapper=function(){emit("全体学生",this.height)};
// MongoDB内部将进行聚合
// reduce方法得到如{"全体学生",[171,172,173,...]}的输入,然后对
values[171,172,173,...]数组进行avg()平均值运算,得到一个value
var reducer=function(key,values){return Array.avg(values)};
// options中我们指定输出的数据将存入AvgHeight集合
var options={out:"AvgHeight"};
// 使用定义好的mapper,reducer方法和options设置进行mapReduce运算
db.students.mapReduce(map,reduce,options);
// 查询结果集合AvgHeight
db.AvgHeight.find();// 分专业-年级-班级计算平均身高
// 定义一个mapper方法,从集合中的每一个文档中提取key-value对
var mapper=function(){
// 构造key,key可以是一个字符串,如:"大数据2018-1"
key=this.major+this.grade+"-"+this.class
// 构造key,key可以是一个文档对象,如:{专业:"大数据",年级:2018,班级:1}
// key = {专业:this.major,年级:this.grade,班级:this.class};
// 构造value,这里要计算身高,所以将height字段值作为value
value=this.height;
/* 返回key-value对,如:
{"大数据2018-1":171},{"大数据2018-1":172}, ... ,
{"应数2018-1":170},{"应数2018-1":173},{"应数2018-1":171} ... ,
{"应数2018-2":170},{"应数2018-2":171},{"应数2018-2":172} ... ,
*/
emit(key, value);
}
/* MongoDB将按照key进行数据聚合,得到values数组
{"大数据2018-1":[171,172,...]},
{"应数2018-1":[170,173,171,...]},
{"应数2018-2":[170,171,172,...]},
...
*/
// 对于每个key的values数组进行reduce操作,这里我们要用数组的avg方法对[171,172,...]进行平
均值计算
var reducer=function(key,values){
return Array.avg(values);
}
// options中我们指定输出的数据将存入AvgHeight集合
var options={out:"AvgHeight"};
// 使用定义好的mapper,reducer方法和options设置进行mapReduce运算
db.students.mapReduce(mapper,reducer,options);
// 查询结果集合AvgHeight, 可以对结果进行排序
db.AvgHeight.find().sort();4.5 单一功能聚合函数
// 查询students集合中2019级的学生数量
db.students.count({"grade":2019})
// 查询students集合中有哪些单独的课程名
db.students.distinct("courses.course")//任务1:给全校分布式数据库课程考试班级平均分前三名的班级中每个学生发奖
// (1)求分布式课程的班级平均分
// (2)排序取前三名的班级
// (3)更新前三名班级的学生文档,增加一个prize字段
var mapper = function() {
for(var i=0;i<this.courses.length;i++) {
if(this.courses[i].course=="分布式数据库原理与应用") {
var key = {课程:this.courses[i].course,专业:this.major,年
级:this.grade,班号:this.class};
var value = this.courses[i].score;
emit(key,value);// {课程:"分布式数据库原理与应用",班级:应用统计2018-2}, 79
}}}
// {课程:"分布式数据库原理与应用",班级:应用统计2018-2}, [79,87,67,99,......]
var reducer = function(key, values){
return Array.avg(values)
}
// mapreduce结果数据输出到nosql_avg_score集合
var options = {out:"nosql_avg_score"}
// 执行mapreduce运算
db.students.mapReduce(mapper, reducer, options)
// 查询mapreduce得到的前三名的班级信息,将查询结果放入一个游标
var cursor = db.nosql_avg_score.find().sort({"value":-1}).limit(3)
// 定义一个变量n,记录游标中的位置,由于游标next方法从第一个开始获取,而且游标中的数据在前面已经做了sort排序,所以第一条数据就是第一名, 注意,在每一次while循环结束时,n会增加1
var n=1;
while(cursor.hasNext()){
// 从游标中获取一条数据
var doc = cursor.next();
// 查询条件
var querydoc = {major:doc._id.专业, grade:doc._id.年级, class:doc._id.班号}
// 更新条件,设置一个prize字段,值为“第几名”
var updatedoc = {$set:{prize:"第"+n+"名"}}
// 执行数据更新
db.students.updateMany(querydoc, updatedoc)
n++; // 循环题末尾,n自增1
}
// 查询students表验证结果
db.students.find({prize:{$type:2}})
db.students.find()// 任务1升级版:给全校每门课程考试班级平均分前三名的班级中每个学生发奖
// (1)求各门课程的班级平均分
// (2)按课程,平均分排序
// (3)遍历排序后的数据,对每门课程前三名的班级去更新对应的学生数据
// 数据的分片采集: key:{major,grade,class}, value:courses.$.score =>
var mapper = function() {
var cls = {major:this.major, grade:this.grade, class:this.class}
for(var i=0;i<this.courses.length;i++) {
cls.course = this.courses[i].course;
var score = this.courses[i].score;
//print(cls.major, cls.grade, cls.class, score);
emit(cls, score);
}
} // 数据的聚合处理
var reducer = function(cls, scores) {
return Array.avg(scores)
} // 数据的输入输出
var options = {out:"avgScore"}
db.avgScore.drop()
db.students.mapReduce(mapper,reducer,options)
// 将已经存在的奖prize删除掉, 避免类型错误
db.students.updateMany({},{$unset:{"prize":1}});
// 得到按课程和平均分排序的班级列表
var cursor = db.avgScore.find().sort({"_id.course":1,"value":-1})
// 定义个变量n,表示第几名,由于数据已经按照课程和分数排序,第一个获取的分数就是第1名
var n = 1;
// 定义2个变量,存放当前处理的数据的课程字段和上一次处理的课程字段
var curCourse, lstCourse;
while(cursor.hasNext()) {
var doc = cursor.next();
var query = {"major":doc._id.major, "grade":doc._id.grade,"class":doc._id.class};
// 将当前处理的课程字段赋值给curCoourse
curCourse = doc._id.course;
// 如果当前处理的字段和上一次处理的字段一样
if(curCourse==lstCourse) {
n+=1;
// 只取前3名,当n小于等于3是,是前三名,更新学生prize数组
if(n<=3) {
var prizename = curCourse+"第"+n+"名";
var updatedoc = {$push:{prize:prizename}};
db.students.updateMany(query,updatedoc);
}
else //只取前3名,所以n大于3的情况下,这个班级不处理,直接跳过
{
lstCourse = curCourse;
continue;
}
}
else // 如果当前处理的课程curCourse和上一次处理的课程不一样,要重置名词变量n,重新取新
课程的前三名
{
n=1;
var prizename = curCourse+"第"+n+"名";
var updatedoc = {$push:{prize:prizename}};
db.students.updateMany(query,updatedoc);
} // 处理一条数据后,将当前处理的课程赋值给lstCourse
lstCourse = curCourse;
}
db.students.find({prize:{$type:2}})
// db.students.find()4.6 导入与导出
Navicat 转储js脚本 备份数据库/集合
(1)右键点数据库或者集合
(2)选择“转储脚本文件” > “结构和数据”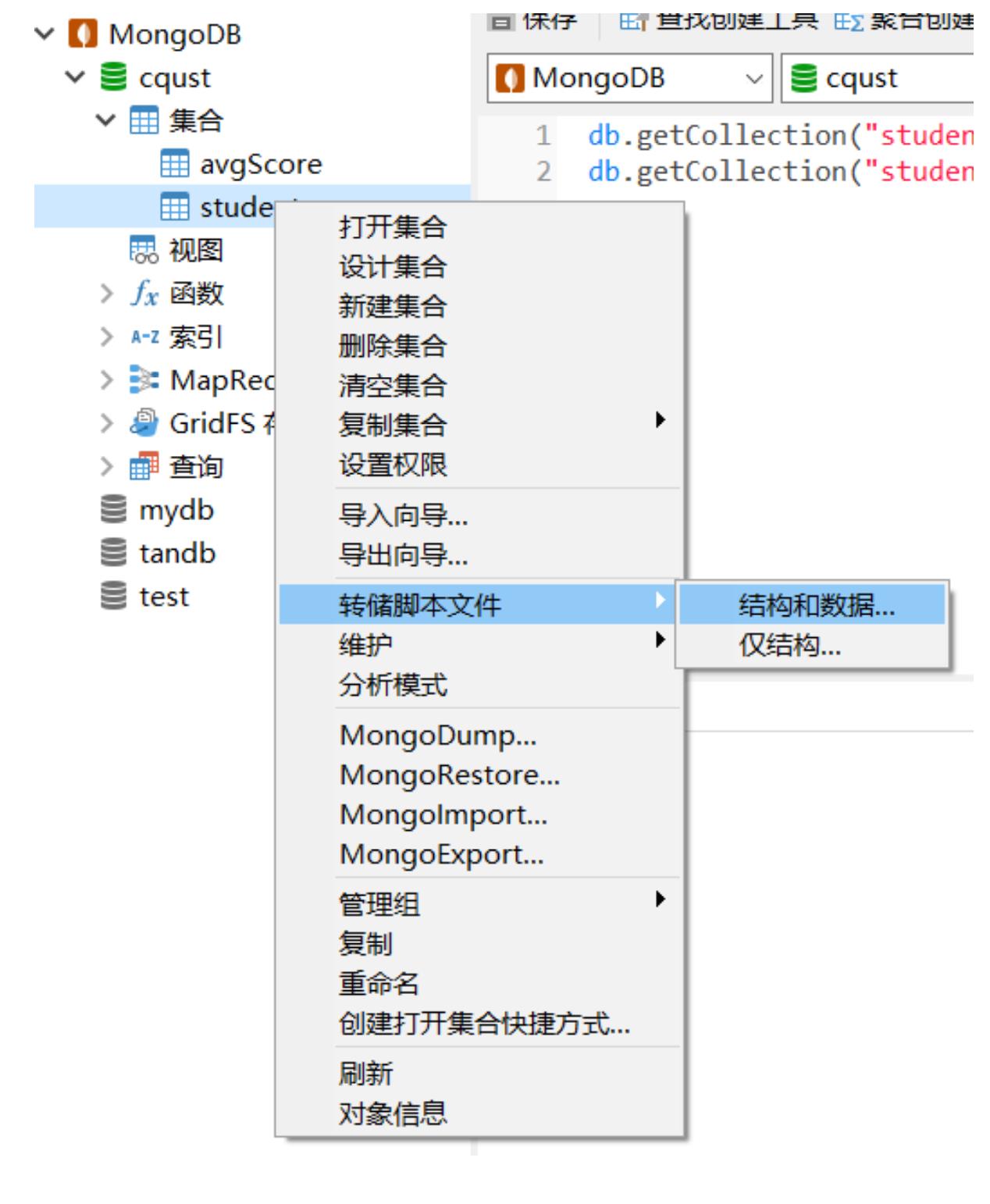
Navicat 执行js脚本 还原数据库/集合
(1) 右键点数据库
(2) 选择“运行脚本文件”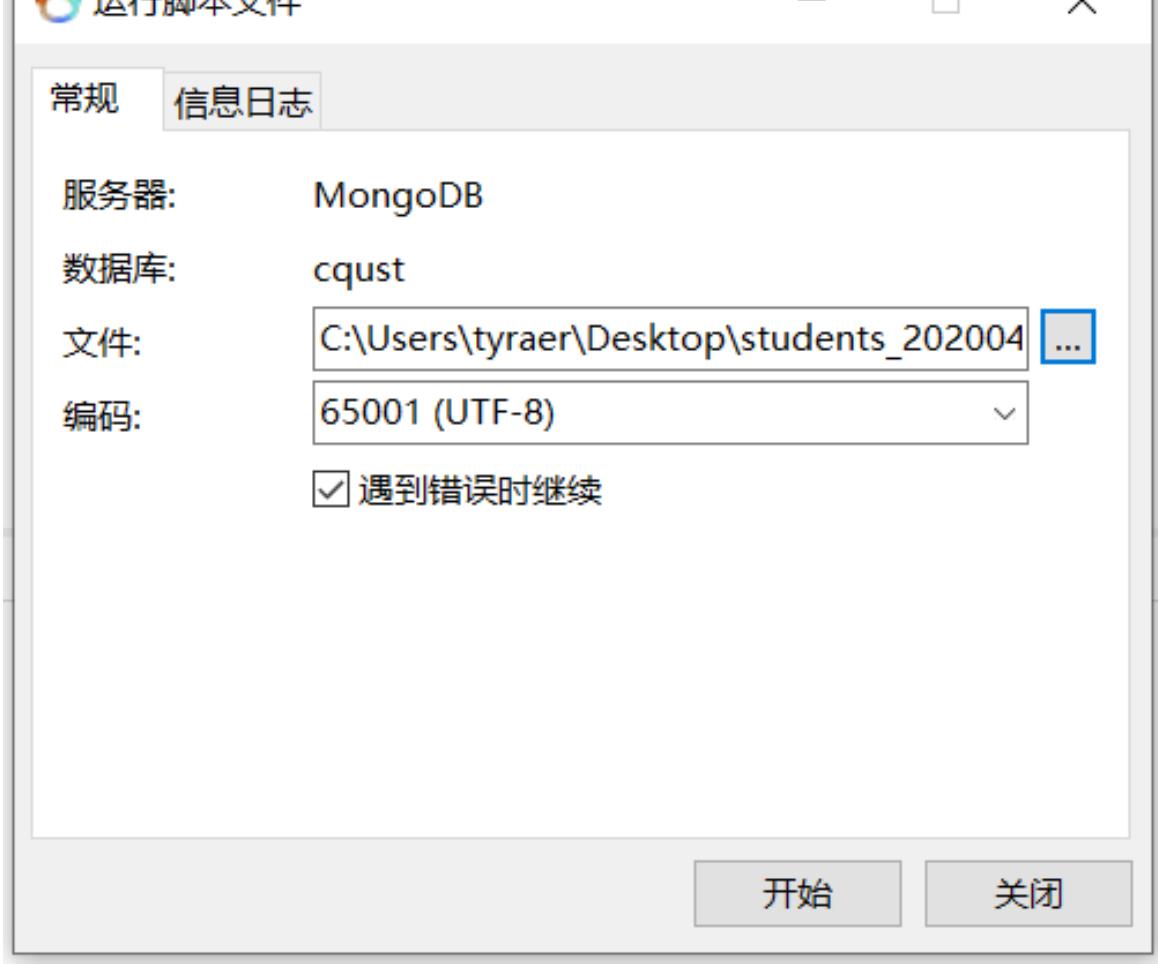
注意:文件编码应根据js文件具体设置,默认UTF-8
Navicat 导出向导
Navicat 导入向导
mongoexport
关键参数说明:
-h,--host :代表远程连接的数据库地址,默认连接本地Mongo数据库;
--port: 代表远程连接的数据库的端口,默认连接的远程端口27017;
--uri: 使用mongodb:// 连接uri, 如:"mongodb://localhost:27017/cqust"
-u,--username:代表连接远程数据库的账号,如果设置数据库的认证,需要指定用户账号;
-p,--password:代表连接数据库的账号对应的密码;
-d,--db: 代表连接的数据库;
-c,--collection:代表连接数据库中的集合;
-f, --fields: 代表集合中的字段,可以根据设置选择导出的字段;
--type: 代表导出输出的文件类型,包括csv和json文件;
-o, --out: 代表导出的文件名;
-q, --query: 代表查询条件;
--skip: 跳过指定数量的数据;
--limit: 读取指定数量的数据记录;
--sort: 对数据进行排序,可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列,如sort({KEY:1})。
当查询时同时使用sort,skip,limit,无论位置先后,最先执行顺序 sort再skip再limit。
# 导出students集合中全部的数据到JSON文件
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=json
--out=".\\export\\students.json"
# 导出students集合中全部的数据到JSON文件(jsonArray格式)
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=json
--out=".\\export\\students.json" --jsonArray
# 使用JSON文件导入数据到students_recover集合
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\\export\\students.json"
# 使用JSON文件导入数据到students_recover集合
# 使用upsert mode更新/插入数据
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\\export\\students.json" --mode=upsert
# 使用JSON文件导入数据到students_recover集合(jsonArray格式)
# 使用--drop先删除目标集合
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type json --file=".\\export\\students.json" --jsonArray --drop
# 导出students集合的指定字段数据到CSV文件
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=csv -
-out=".\\export\\students.csv" -
fields="name,gender,height,phone,role,sno,major,grade,class,courses"
# 导出students集合的指定字段(使用字段文件,每个字段写一行)数据到CSV文件
mongoexport --host=localhost:27017 --db=cqust --collection=students --type=csv -
-out=".\\export\\students.csv" --fieldFile="fields.txt"
# 导入CSV文件中的数据到students_recover集合(用--drop选项先删除目标集合)
# 使用--headerline选项从CSV文件头行获得字段名
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type csv --file=".\\export\\students.csv" --headerline --drop
# 导入CSV文件中的数据到students_recover集合(用drop选项先删除目标集合)
# 使用--columnsHaveTypes选项以指定的JSON数据类型导入
# 使用--fields选项指定导入字段(字段名.数据类型格式是配合--columnsHaveTypes使用的)
# 使用--parseGrace=skipRow跳过头行(在数据类型转换失败时跳过)
mongoimport --host=localhost:27017 --db=cqust --collection=students_recover --
type csv --file=".\\export\\students.csv" --
fields="name.string(),gender.string(),height.double(),phone.string(),role.string
(),sno.double(),major.string(),grade.string(),class.string(),courses.auto()" --
parseGrace=skipRow --columnsHaveTypes --drop4.7 备份与恢复
# mongodump 备份数据库cqust 到当前目录下的dump目录(默认)
mongodump --host=localhost:27017 --db=cqust
# mongorestore 从默认备份目录dump恢复数据
# 不使用--drop:只恢复数据库中没有的数据
mongorestore --host=localhost:27017
# 使用--drop:先删除原有数据再完全
mongorestore --host=localhost:27017 --drop
# mongodump 备份数据库cqust的集合students 到cqustdump目录(指定备份文件目录)
mongodump --host=localhost:27017 --db=cqust --collection=students --
out="D:\\MongoDB\\output\\cqust_students_dump"
# --nsInclude=cqust.students <=> --db=cqust --collection=students
mongodump --host=localhost:27017 --nsInclude=cqust.students --
out="D:\\MongoDB\\output\\cqust_students_dump"
# mongorestore 从备份目录中的BSON文件恢复集合students的数据(使用--drop先删除集合再恢复)
mongorestore --host=localhost:27017 --nsInclude=cqust.students --
dir="D:\\MongoDB\\output\\cqustdump\\cqust\\students.bson" --drop
mongorestore --host=localhost:27017 --db=cqust --collection=students --
dir="D:\\MongoDB\\output\\cqustdump\\cqust\\students.bson.gz" --gzip --drop
# mongodump 备份数据库cqust的集合students 到一个存档文件
mongodump --host=localhost:27017 --db=cqust --collection=students --
archive="D:\\MongoDB\\output\\cqust-students.dump"
# mongorestore 从存档文件中恢复数据(使用--drop先删除集合再恢复)
mongorestore --host=localhost:27017 --archive="D:\\MongoDB\\output\\cquststudents.dump" --drop
# mongorestore 从存档文件中恢复cqust数据库students集合的数据到数据库cqust的recover集合中
mongorestore --host=localhost:27017 --archive="D:\\MongoDB\\output\\cquststudents.dump" --nsInclude=cqust.students --nsFrom=cqust.students --
nsTo=cqust.recover
其实到了这一步,我们应该也就了解到了,我们的MongoDB的基本的操作语法,但是如果你是初学者,我建议你先看完上面的全部的语法案例和详解,有利于学习和夯实MongoDB的基础,至于我们的实际运用,如何去真正的增删改查,后面的文章我会给出比较详细的案例的!
每文一语
喜欢毫无理由
以上是关于MongoDB之增删改查全套语法锦囊⭐️初学者福利的主要内容,如果未能解决你的问题,请参考以下文章