#萌新日志#2. 使用BraTS 2020数据集训练nnUNet(多模态和单模态)
Posted 苏黎世下雪了吗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了#萌新日志#2. 使用BraTS 2020数据集训练nnUNet(多模态和单模态)相关的知识,希望对你有一定的参考价值。
#萌新记录某些日子的学习经历。#
前言
最近在跟着本科导师和课题组学长进行一项科研任务,学长手把手教我,我只是管中窥豹,还未能构建好整个科研任务的上帝视角。目前主要工作是使用BraTS 2020数据集训练nnUNet。对我来说这确实是新奇的体验,过程中我也遇到了一些实际问题,于是想记录一下。
摘要
主要活动基于ssh端口Linux操作系统,使用python脚本辅助处理数据集文件格式。使用BraTS 2020的4个模态以及单个模态训练nnUNet。
关键词 BraTS2020 模态 nnUNet Python脚本 Linux
目录
Experiment planning and preprocessing
BraTS 2020 简介
BraTS 2020是MICCAI脑肿瘤分割比赛的数据集,训练集(TrainingData)有369个病例,验证集(ValidationData)有125个病例。(验证集可作为测试集使用)
每个病例包含4个模态(多模态)和3个分割部分(label)。4个模态分别是t1、t2、flair、t1ce,多模态是医学图像中常用的反应图像的方式,可以理解为它们使用了不同的方式或者说纬度来反映同一个对象。多模态可以让被反映的对象更加全面。3个分割部分(准确来说是包含背景在内的4个标签),分别是背景、坏疽(NET,non-enhancing tumor)、浮肿区域(ED,peritumoral edema)、增强肿瘤区域(ET,enhancing tumor),这四个标签能够共同反映whole tumor(WT), enhance tumor(ET), and tumor core(TC)。
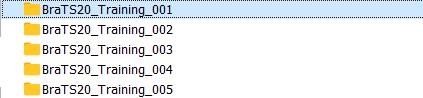
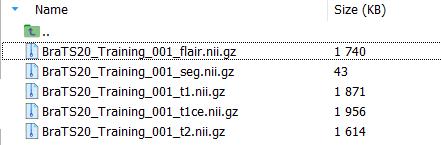
下图是数据集一个病例的文件(举例):
因为这个博客我想主要讲讲怎么使用BraTS 2020数据集训练nnUNet,就不引申讲述太多,更多详细内容可以参考[1][2]。或者我以后可能写一写这个项目的更多内容。
训练nnUNet前的准备工作
我们手上已经有了BraTS 2020数据集和可以使用的nnUNet了(nnUNet下载地址:GitHub - MIC-DKFZ/nnUNet,跟着安装步骤一步步来就好,可以用nnUNet的随便一个指令来测试一下它能不能跑)。
BraTS 2020数据集生肉是不能直接用的,我们在训练模型之前还要把这个数据集进行一些(更多是格式上的)预处理。nnU-Net相比于U-Net的厉害之处在于它能根据所提供的数据集自动设计一个有效的分割管道,简而言之就是说不需要我们调参了,用起来非常简单。 (当然想要理解深层思想需要花功夫)。
我们需要把BraTS 2020数据集先变成能喂给nnUNet吃(训练)的熟肉,主要有两个步骤:Dataset conversion和Experiment planning and preprocessing。不过好在nnUNet同样提供了现成的工具,下面是如何使用它们:
-
Dataset conversion
我们在安装nnUNet时创建了3个文件夹:nnUNet_raw用于输入数据集、nnUNet_preprocessed我们不需要主动去处理它、nnUNet_trained_models会存储训练好的结果。简而言之,我们只需要把合适格式的数据集放入nnUNet_raw_data(nnUNet_raw里面会有两个子文件夹nnUNet_raw_data和nnUNet_cropped_data)中即可。nnUNet_cropped_data内会自动保存下一步裁剪后的数据集,我们也不需要主动去处理它。
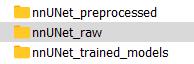
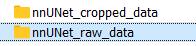
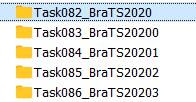
首先我们要在nnUNet_raw_data内新建一个任务文件夹,命名方式"TaskXXX_NAME","XXX"是000-999的三位数字。
文件夹创建好以后,我们直接用现成的脚本傻瓜式把BraTS数据集生肉变熟肉(脚本也在nnUNet内:nnUNet/Task082_BraTS_2020.py at master · MIC-DKFZ/nnUNet · GitHub)。
注意!脚本需要的操作:
1. 改路径(BraTS2020生肉所在路径和nnUNet_raw_data),在主方法里改即可。
2. 假如"from meddec.paper_plot.nature_methods.challenge_visualization_stuff.own_implementation.ranking import \\rank_then_aggregate" 报错,删去这个引用就是了,因为脚本好像没出现它的使用。
接下来运行即可。顺利的话任务文件夹内会得到这样的文件格式:

imagesTr装训练集,imagesTs装测试集(可以是空的),imagesVal装验证集,labelsTr是训练集对应的分割结果。dataset.json保存整个任务数据的信息。
以上Data conversion结束。这就是我们需要的文件格式。
-
Experiment planning and preprocessing
这一步也是傻瓜操作,直接在命令行输入"nnUNet_plan_and_preprocess -t XXX --verify_dataset_integrity" ("XXX" 表示任务编号,3位数)即可。目的是一些数学上的预处理。
Train
准备工作已经完成,可以开始训练模型了。
我使用了Linux的screen命令创建了一个新的空间,在这个空间下使用.sh文件发出训练指令,得到的反馈信息只会显示在screen创造的那个世界,就不会干扰我在主界面的使用。
我的.sh文件如下:

每一行表示一个任务,"CUDA_VISIBLE_DEVICES=X",表示用服务器的第X张显卡;"nnUNet_train 3d_fullres nnUNetTrainerV2"是BraTS 2020对应的指令,"TaskXXX_NAME"表示任务文件名,和上文对应。最后的编号表示是第几折,比如我这里总共跑了5 folds。
确定用哪张显卡前可以先命令行输入:nvidia-smi 看看每张显卡的使用情况(前提是服务器有显卡哈)。
最后命令行输入:sh pipeline1.sh 开始训练。
单模态
上文所讲的都是默认处理BraTS 2020的所有模态,这里讲一讲处理BraTS 2020单个模态(比如t1)的步骤。
单模态和多模态的主要区别在于准备工作的Dataset Conversion(上文)环节。
我们观察多模态文件格式:
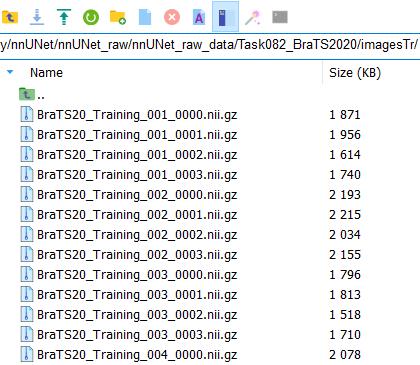
imagesTr、imagesTs、imagesVal中,每个病例有4个模态,从0000-0003,分别对应(从dataset.json可以看到):

所以很简单的思路是:假如我们需要跑0000这个单模态,做两件事
1.修改dataset.json的modality部分,只保留需要的模态和对应的编号。
2.从这三个文件夹内删去0001-0003的文件就好了,写个脚本如下:
import os
def filename_del(target_dir,keepIndex):
try:
for filename in os.listdir(target_dir):
# file = os.path.splitext()
print(filename[-8])
# print(type(filename))
index = filename[-8]
if index != keepIndex:
os.remove(target_dir + filename)
except:
print('error')
if __name__=="__main__":
filename_del('./imagesTr/', '1')
filename_del('./imagesTs/', '1')
filename_del('./imagesVal/', '1')接下来按照上文所说的步骤(Experiment planning and preprocessing)处理就好。
但这个思路是存在问题的,不完善的。保留0000模态不会出现问题,但0001就暴露问题了。
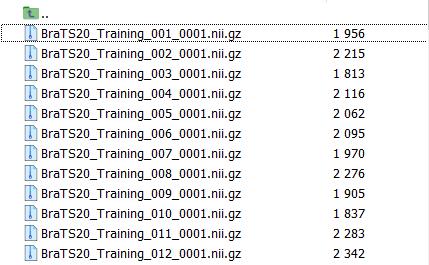

此时文件中只保留了0001的模态,并且dataset.json也做了对应修改。但下一步(Experiment planning and preprocessing)报错说找不到0000文件。于是我去读了一下预处理的.py文件,发现都是处理文件从0000开始的。也就是说单模态需要保证模态编号是0000。于是我又写了个修改文件名的脚本:
import os
def n2Zero(target_dir):
try:
for filename in os.listdir(target_dir):
# file = os.path.splitext()
oldpath = target_dir + filename
print(filename[-8])
# print(type(filename))
newpath = oldpath[0:-8] + '0'+oldpath[-7:]
#print(oldpath,type(oldpath))
print(newpath,type(newpath))
os.rename(oldpath, newpath)
except:
print('error')
if __name__=="__main__":
n2Zero('./imagesTr/')
n2Zero('./imagesTs/')
n2Zero('./imagesVal/')
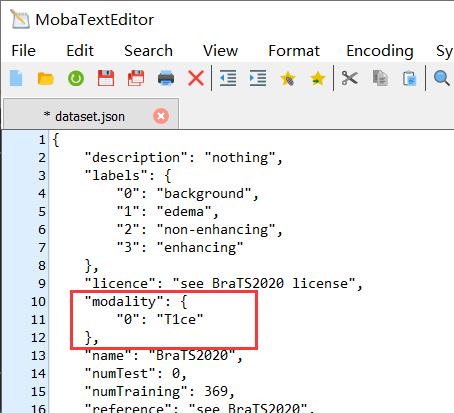
在保证模态文件名称编号是0,dataset.json的modality对应编号是0后。能顺利进行之后的步骤了。
总结
使用BraTS 2020数据集训练nnUNet。基本流程是把数据集通过dataset conversion变成规定的文件存储格式,经过预处理Experiment planning and preprocessing,最后输入训练指令。
如果需要提取单模态或者部分模态,需要删除多余的模态文件,并且剩余的模态编号需要从0开始,dataset.json的"modality"部分也需要对应调整。
感谢阅读,请多指教!
Reference
[1] (11条消息) BraTS数据集处理详解(附代码详解)_刘小花花的博客-CSDN博客_brats
[2](11条消息) [概念]MICCAI+BraTS+多模态t1,t2,flair,t1c+HGG,LGG+WT,ET,TC_程序客栈(@qq704783475)-CSDN博客_hgg是什么意思
感谢退坑了二次元的亚撒西学长的帮助!
以上是关于#萌新日志#2. 使用BraTS 2020数据集训练nnUNet(多模态和单模态)的主要内容,如果未能解决你的问题,请参考以下文章