实时音视频通信(RTC)中必须要了解的三种关键算法
Posted HaaS技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时音视频通信(RTC)中必须要了解的三种关键算法相关的知识,希望对你有一定的参考价值。

1、背景
RTC(Real-time Communications),实时通信,是一个正在兴起的风口行业,特别是近两年电商、教育等行业直播的普及以及各种设备之间的音视频通话场景。从技术角度来说,RTC并不是一个新兴技术,从智能手机流行以来,RTC就已经出现在一对一的音视频通话场景中,最初的技术方案也比较直观,当设备通过服务端建立通话连接后,两个设备以点对点的方式直接通信,具体实现方式就是把编码压缩过的音视频数据包通过UDP协议封包后发送给接收方,接收方收到UDP数据包后,就可以进行拆包,解码并播放,这种方式的特点就是简单粗暴,不需要关心网络情况,后果是有可能出现丢包,特别是网络情况发生变化时,会出现听不到声音,画面卡顿等情况,所以整体用户体验会比较差。随着技术的发展进步,考虑到网络情况随时可能发生变化,在原有技术方案的基础上,出现了一些比较有名的网络拥塞控制算法,它可以根据网络变化情况控制数据包发送速率,从而平缓网络抖动造成的一些丢包,卡顿等现象。
在RTC领域,最有名的就是Google的WebRTC,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输,支持网页浏览器进行实时语音对话或视频对话。WebRTC是一个开源项目,从功能流程上来说,它包含采集、编码、前后处理、传输、解码、缓冲、渲染等很多环节。比如,前后处理环节 有美颜、滤镜、回声消除、噪声抑制等,采集有麦克风阵列等,传输有拥塞控制,NetEQ等,编解码有 VP8、VP9、H.264、H.265 等等。这里主要是基于学习的角度,简单介绍WebRTC中比较重要的几个算法:拥塞控制算法,NetEQ以及音频3A(噪声抑制,回声消除以及自动增益)。
2、拥塞控制算法
WebRTC包含三种拥塞控制算法,GCC(Google Congest Control)、BBR和PCC。这里主要想介绍一下GCC。
GCC核心思想就是通过预测可用带宽来控制发送的速率,并结合发送端和接收端两端各自估测的带宽来综合计算,其中发送端的带宽估测主要依赖于丢包率(其实也有延迟),接收端的带宽估测依赖于延迟(的变化)。打个比方,GCC的角色就像是一个繁忙的十字路口的交警,当前方道路车辆太多时,他会阻止后方车辆继续行驶,防止交通堵塞,当前方道路车辆较少时,他会加速放行,让后方车辆尽快通过。当然,GCC实际控制流程远比交警来的复杂。换句话说,GCC主要是依靠丢包、延迟、抖动等网络参数来预估当前的可用带宽进而控制发送的速率从而避免网络拥塞引起的丢包、延迟、抖动等现象,是一个反馈的过程。
由于WebRTC还有NACK、FEC等策略来解决丢包问题,实际上发送端的带宽估测对较小程度的丢包来说并不太敏感,反而是接收端的带宽估测对延迟的抖动有较大的灵敏度。GCC的接收端通过一系列算法检测当前网络延迟是否有变化,延迟变大的话,在考虑并消除掉数据尺寸变化的影响后,可以认为是网络路由的拥塞,需要降低码率,否则在延迟变小的情况下,认为网络空闲,可以提高码率。所以在延迟抖动较大的情况下,即使没有丢包,GCC也会进行较大程度的带宽调整。也就是说,延迟如果稳定的话,即使值较大,也并不影响带宽的估测,反过来如果平均延迟比较小,但是出现较多较大的抖动,则会迅速将估测带宽调低。
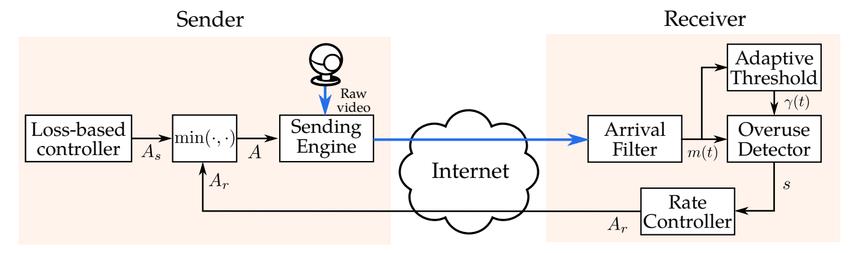
GCC算法主要分成两个部分,一个是基于丢包的拥塞控制,一个是基于延迟的拥塞控制。在早期的实现当中,这两个拥塞控制算法分别是在发送端和接收端实现的。
对发送端来讲,GCC算法主要负责两件事:
- 接收来自接收端的数据包信息反馈,包括来自RTCP RR报文的丢包率和来自RTCP REMB报文的接收端估计码率,综合本地的码率配置信息,计算得到目标码率A。
- 把目标码率A生效于目标模块,包括PacedSender模块,RTPSender模块和ViEEncoder模块等。
对于接收端来讲,GCC算法主要负责两件事:
- 统计RTP数据包的接收信息,包括丢包数、接收RTP数据包的最高序列号等,构造RTCP RR报文,发送回发送端。
- 针对每一个到达的RTP数据包,执行基于到达时间延迟的码率估计算法,得到接收端估计码率,构造RTCP REMB报文,发送回发送端。
由此可见,GCC算法由发送端和接收端配合共同实现,接收端负责码率反馈数据的生成,发送端综合两个控制算法的结果得到一个最终的发送码率,并以此码率发送数据包。
3、NetEQ算法
NetEQ是webRTC中音频技术方面的两大核心技术之一,另一核心技术是音频3A算法(AEC、ANS以及AGC)。在音视频实时通信领域,网络环境是影响音视频质量最关键的因素,当网络质量比较差时,再好的音视频算法都显得有些心有余而力不足。网络质量差的表现主要有延时、乱序、丢包、抖动,其中丢包和抖动是最常见的。抖动是数据在网络上的传输忽快忽慢,丢包是数据包经过网络传输,因为各种原因被丢掉了,所以处理好丢包和抖动,是获得优质音视频体验的关键因素。
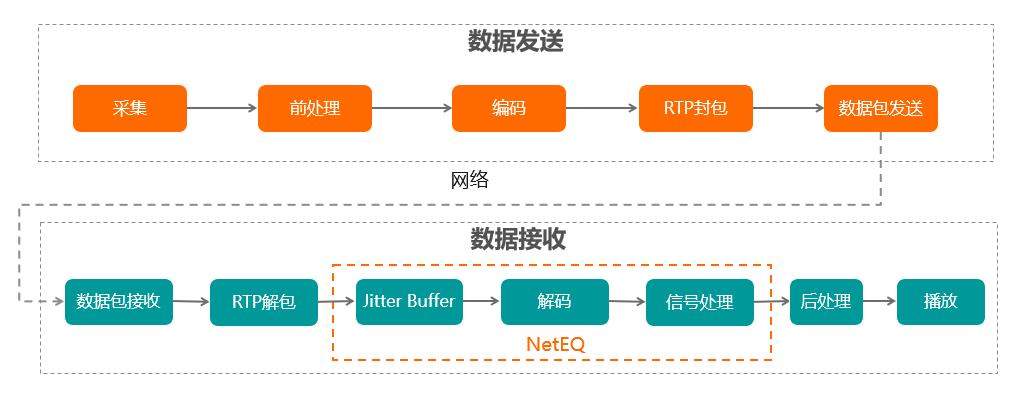
RTC音频通讯部分正常的工作流程如下:首先在发送端采集音频数据,并对采集到的声音信号进行回声消除,噪声抑制以及自动增益控制等前处理,然后进行语音压缩编码,封装成RTP包并通过网络发送到接收端,接收端接收到数据后,进行RTP解包,然后进行抖动消除,丢包隐藏,解码等操作,最后将处理过后的音频数据送给播放器播放。其中NetEQ涉及的操作包含抖动消除,解码以及相应的音频信号处理,简单来讲,NetEQ本质上就是一个音频的抖动缓冲器(JitterBuffer),它工作在音频数据接收端,通过抖动消除,丢包隐藏等操作达到音频流畅播放的目的。

抖动现象是怎么产生的呢?如上图,在没有技术干预的情况下,发送端按照20ms的时间间隔发送音频数据包,由于网络延迟等影响,数据包到达的时间并不是均匀的,这时候如果直接送到播放器播放,我们听声的声音是存在抖动现象的,为了避免这种情况,我们通常做法是通过抖动缓冲技术来消除,即在接收方建立一个缓冲区,语音包达到接收端时,首先进入缓冲区暂存,随后系统再以平滑的速率将语音包从缓冲区取出,经过解码后播放出来。当然,只是简单的设一个缓冲区是远远不够的,因为缓冲区设的太小,有可能起不到缓冲效果,设的太大,有可能导致音频延迟,那缓冲区到底要设多大呢?这个就要看具体情况了。抖动消除思想的理想状态是每个数据包在网络传输中的延迟与其在抖动缓冲区中缓冲的延迟之和应该相等,因此一般的抖动消除思想是将抖动缓冲区大小设为目前测到的最大网络延迟大小,而且每个包在网络中的延迟加上其在抖动缓冲区中缓冲产生的延迟之和应该等于抖动缓冲区大小。
目前抖动缓冲控制算法包含静态抖动缓冲控制算法和自适应抖动缓冲控制算法,静态抖动缓冲控制算法指的是缓冲区大小是固定值,对于超出缓冲区大小的数据包将会丢弃。这种算法模型小,实现起来比较简单,但在弱网情况下比较容易丢包;自适应抖动缓冲控制算法的缓冲区大小是随着实际网络的抖动情况而调整的,接收端将收到的数据包延迟与当前保存的延迟信息进行比较,得到当前网络最大抖动,从而选择合适的缓冲区大小。这种算法的优点是网络抖动较大时丢包率较低,网络延迟小时,语音延迟相对也比较小。NetEQ采用的抖动消除技术属于自适应抖动缓冲算法。
除了抖动缓冲,NetEQ还实现了丢包隐藏(Packet Loss Concealment),所谓的丢包隐藏,指的是发生丢包时,产生一个与丢失语音包相似的替代语音。NetEQ中的丢包隐藏技术和解码器是密切相关的,它在解码端根据收到的数据逐帧解码过程中,先判断当前帧是否完整,如果是完整的,则按照正常的解码流程进行解码,如果发现数据丢失,那么进入特殊的丢包隐藏模块进行数据包补偿,这种补偿方式比较复杂,这里就不多做介绍了。
4、音频3A算法
音频3A算法指的是在发送端对发送信号依次进行回声消除、降噪以及音量均衡操作,它包含三个算法:AEC(回声消除),ANS(噪声抑制)和AGC(自动增益控制)。音频3A是在数据发送端进行的,当发送端采集到音频数据后,在编码之前,会先进行信号处理,这里的信号处理主要指的就是音频3A。不同于拥塞控制算法和NetEQ,音频3A算法和网络无关,它是纯粹的音频信号处理算法,目前很多设备的音频3A实际上是通过硬件实现的。
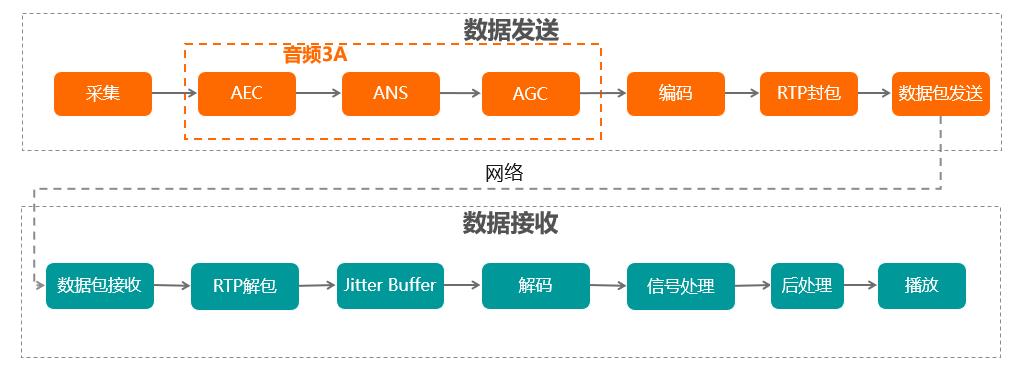
4.1、AEC(回声消除)
在正常的音频通话流程中,我们说话的声音除了第一次直接被麦克风捕捉到,还会经过多次空间反射再次被麦克风捕捉并采集到系统中,此时音频的输入既有本人说话的声音,又有空间反射的回声,如果不做处理,远端听到的声音是带有回音的,还有一种情况是远端传过来的声音经过设备扬声器播放后,又被设备的麦克风采集到,如果不做处理,对方能出自己设备的扬声器中听到自己刚才讲话的声音,这对于用户来说是一种非常差的体验。
在真实的语音场景中,麦克风采集到的声音是一个混合体,它包含近端以及远端的声音,简单来讲,AEC期望的是从混合的近端信号中消除不需要的远端信号,保留近端人声发送到远端。因此,回声消除的关键就是如何区分近端和远端的声音,如果我们能够产生一种信号,中和掉远端的声音,那么自然就能消除掉回声。那具体该如何做呢?我们以远端传过来的声音经过设备扬声器播放后,又被设备麦克风采集到并发送回去产生的回声为例,简单来讲分三步:
- 首先找出扬声器信号跟麦克风信号之间的延迟;
- 其次根据扬声器信号估计出麦克风信号中的线性回声成分,并将其从麦克风信号中减去,得到残差信号。
- 最后通过非线性的处理将残差信号中的残余回声给彻底抑制掉。
所以回声消除也由三个大的算法模块组成:延迟估计(Delay Estimation),线性自适应滤波器(Linear Adaptive Filter)以及非线性处理(Nonlinear Processing)。
其中延迟估计决定了AEC的下限,线性自适应滤波器决定了 AEC 的上限,非线性处理决定了最终的通话体验。
4.2、ANS(噪声抑制)
所谓噪声抑制就是我们平常所说的降噪,我们常用的降噪耳机就是基于此打造的。噪声分为平衡噪声和瞬时噪声两类,平稳噪声的频谱稳定,瞬时噪声的频谱能量方差小,利用噪声的特点,对音频数据添加反向波形处理,即可消除噪声。噪声跟语音信号不同,降噪过程中其实是通过在频域做一些处理。对于一些平稳的噪声,比如常见的空调声、电脑风扇声、车内的一些风噪声,它的时间变化比较慢,但是语音是一个多变的信号,正是通过它们两个的不同,我们来判断哪些信号是语音,哪些是降噪,然后把它给去掉。关于噪声抑制的介绍,相关的资料也不少,具体就不详细介绍了。
4.3、AGC(自动增益控制)
AGC单纯从名词解释上比较不好理解,什么是自动增益控制?我们可以先以现实场景中的音视频会议为例,在真实场景中,不同参会人由于距离远近以及每个人说话音量不同,当设备通过麦克风采集到音频数据后,如果不做处理,那么远端听到的音量大小会有很大的差异,所以对发送端音量的均衡在上述场景中显得尤为重要,自动增益控制算法的目标是能够统一音频音量大小,缓解由设备采集差异、说话人音量大小、距离远近等因素导致的音量的差异。
在3A音频处理算法中,AGC位于最后的位置,它主要在发送端作为均衡器和压限器调整推流音量,针对不同的接入设备 WebRTC AGC 提供了三种模式:固定数字增益(FixedDigital),自适应模拟增益(AdaptiveAnalog)以及自适应数字增益 (AdaptiveDigital), 其中固定数字增益模式最基础的增益模式也是 AGC 的核心,其他两种模式都是在此基础上扩展得到。固定数字增益主要是对信号进行固定增益的放大,最大增益不超过设置的增益能力,自适应模拟增益,顾名思义,就是能够增对模拟增益进行动态调整,它主要工作在PC端,自适应数字增益为了满足智能手机和平板设备,这些移动端并没有类似 PC 端调节模拟增益的接口,它的工作原理类似于自适应模拟增益。
5、小结
RTC领域积累了很多音视频以及流媒体相关的高质量算法,我们介绍的拥塞控制,NetEQ以及音频3A算法是其中比较重要的,业界也有很多深入的讲解,本文主要基于学习和科普的角度做一些简单介绍,更详细的内容大家可以参考相关文章以及WebRTC代码实现。
参考文章
开发者支持
如需更多技术支持,可加入钉钉开发者群,或者关注微信公众号。

更多技术与解决方案介绍,请访问HaaS官方网站https://haas.iot.aliyun.com
以上是关于实时音视频通信(RTC)中必须要了解的三种关键算法的主要内容,如果未能解决你的问题,请参考以下文章