Hbase
Posted Tommy Vercetti
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase相关的知识,希望对你有一定的参考价值。
分布式,可扩展,支持海量数据存储的
N
o
S
Q
L
NoSQL
NoSQL数据库。
实现了在hdfs的CRUD,特别实现了在hdfs上的改、随机写操作。
存储形式:
逻辑上分析存储的格式类似于表结构存储。
实际上底层的物理存储形式是
K
−
V
K-V
K−V形式的存储,类似多维度
m
a
p
map
map。
Hbase的逻辑结构:
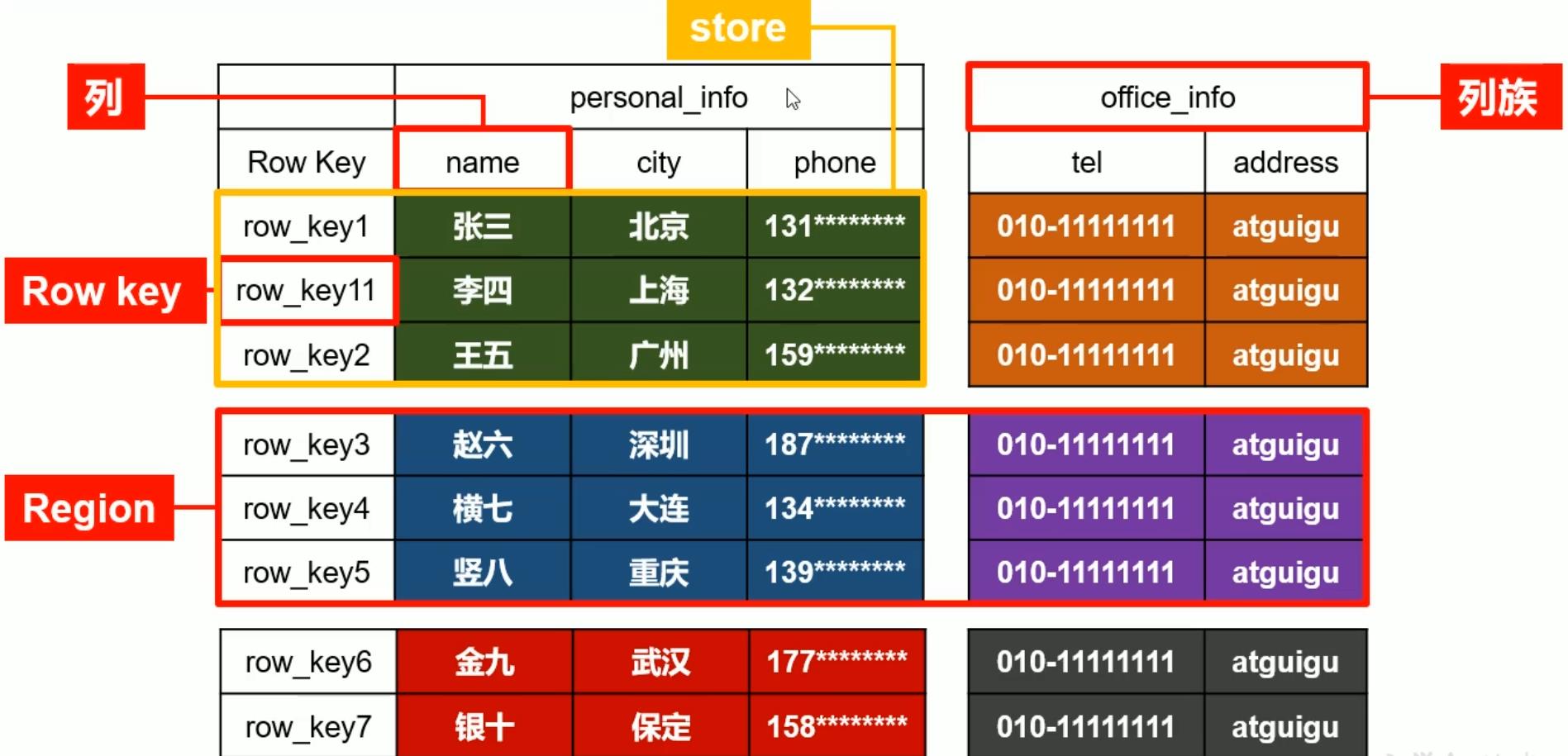
对表横向划分分为不用的
r
e
g
i
o
n
region
region,纵向划分为不同的列族,不同的列族存储在不同的文件夹中,实际存储的数据是
s
t
o
r
e
store
store,行键
R
o
w
K
e
y
Row Key
RowKey必须存在。
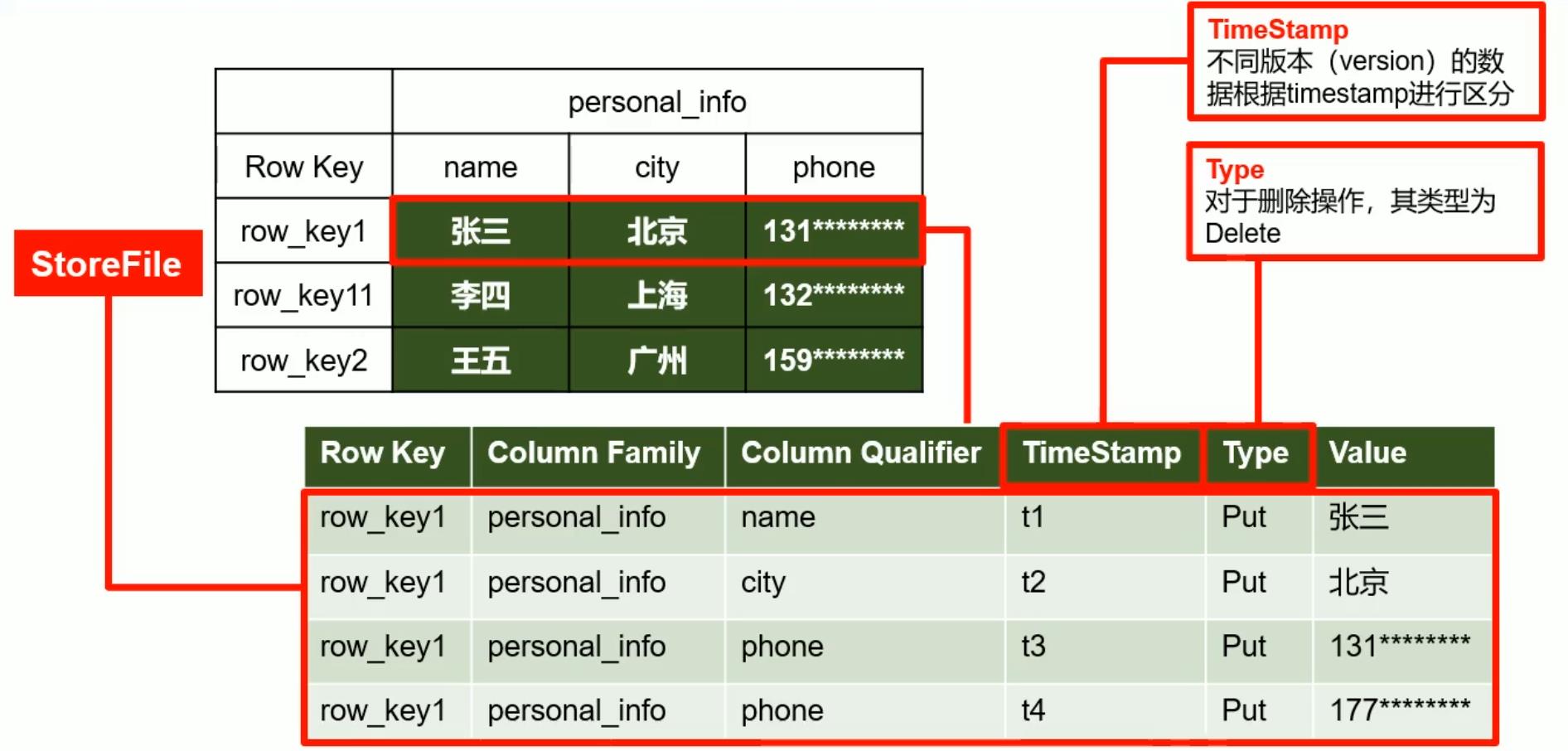
Hbase物理存储结构
数据模型
- 命 名 空 间 命名空间 命名空间,类似于mysql中的databases,命名空间下有很多表,默认有两个自带的命名空间:hbase和default,分别存储hbase系统内置表和用户默认创建的表。
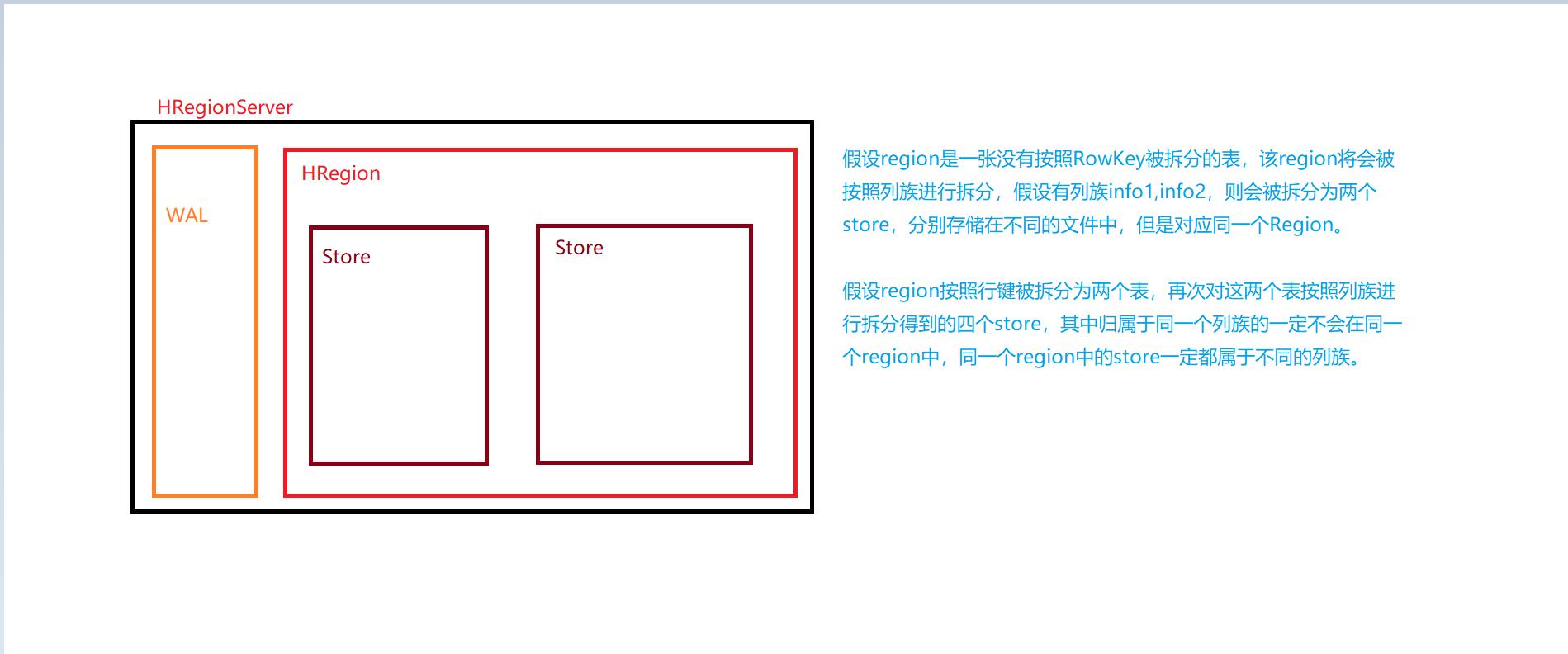
- r e g i o n region region, H b a s e Hbase Hbase定义表时只需要声明列族即可,不需要声明具体的列,因为字段可以动态的按需增加和指定。
- R o w Row Row, Hbase表中的每行数据都由一个 R o w K e y RowKey RowKey和多个 C o l u m n Column Column组成,数据是按照行键的字典顺序存储的,并且查询数据时只能按照行键进行检索,且支持范围检索(指定rowkey的范围,在指定范围内进行检索)。
-
C
o
l
u
m
n
Column
Column Hbase中的每个列都由列族和列名进行限定,例如
info : name,info: age,在建表时,只需要指定列族而不需要先指定列限定符(列明)。 在 H b a s e 中 , 列 相 当 于 数 据 , 在 声 明 数 据 时 声 明 的 。 \\color{red}在Hbase中,列相当于数据,在声明数据时声明的。 在Hbase中,列相当于数据,在声明数据时声明的。 - T i m e S t a m p TimeStamp TimeStamp 时间戳用于标识数据的不同版本,如果不指定会自动加上该字段,其值为写入Hbase的时间戳。
- C e l l Cell Cell 数据中的单元格,由:行键,列族、列标识符、时间戳唯一确定的数据格,存储的数据没有类型,全是以字节码(byte)的形式存储。
Hbase架构
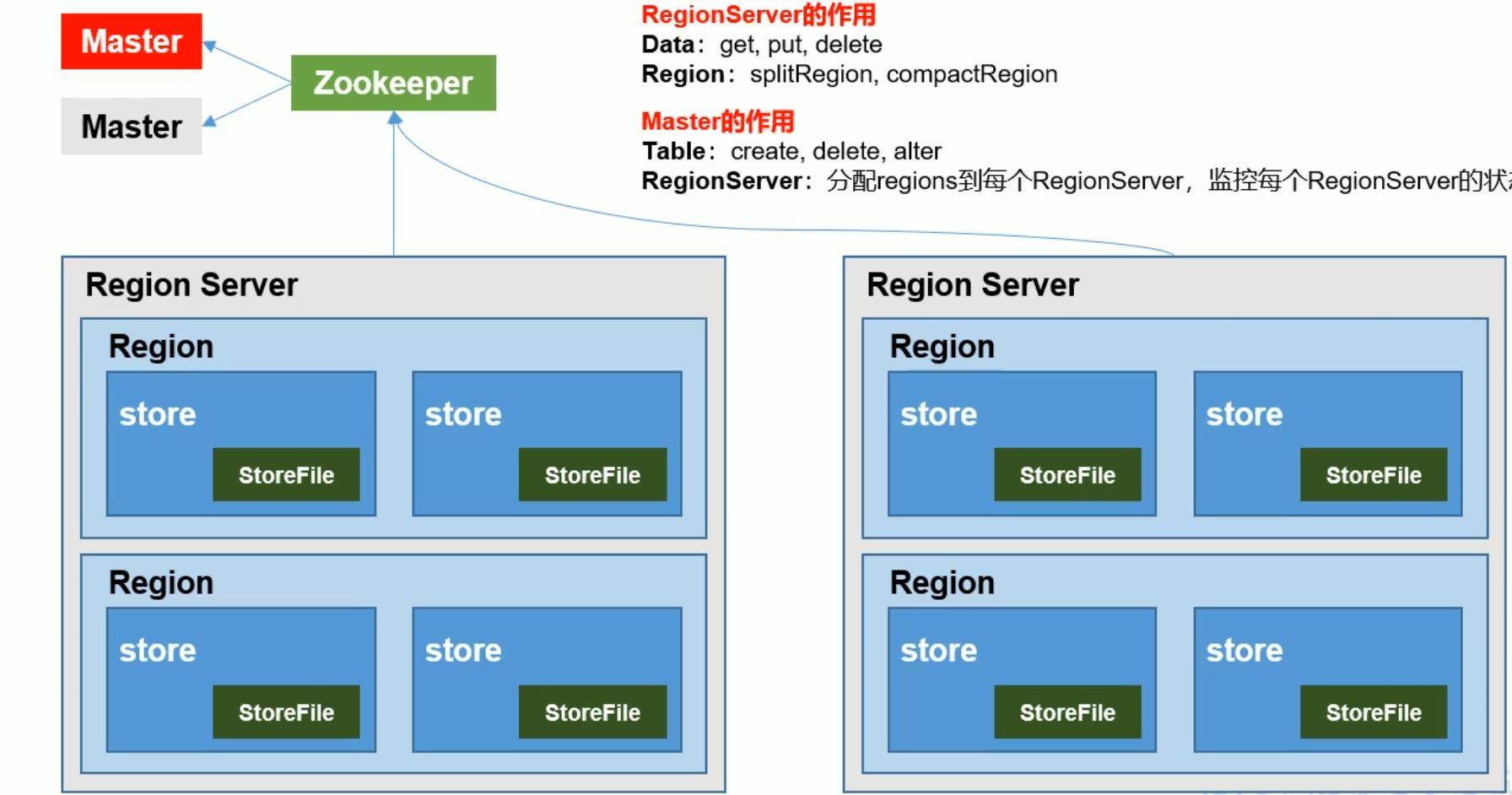
master存在单点故障问题,所以自带高可用特性,直接在不用的节点启动即可。
依赖于zookeeper
Hbase Shell
DDL
list列出所有的用户创建的表describe + '表名':描述该表,如下图所示:

name代表列族,version代表版本,为1代表最后仅仅储存最新的数据,将其余的数据删去,为2则保留两个最新的数据,以此类推。alter:改表的信息:alter 'student', {NAME=>'info', VERSION=>3}仅需要声明需要修改版本的列族即可。drop:删除表,删除之前先disable,再删除,否则报错,操作如下:
>>> disable 'student'
>>> drop 'student'
>>> list 发现没有'student'表了
create创建表:create 'table', 'column family',列族必须给出。
namespace DDL
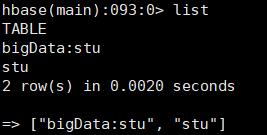
list_namespacecreate_namespace命名空间不需要列族:create_namespace 'bigData'即可创建成功命名空间biogData- 新建命名空间
bigData,在此命名空间下创建表,不同的命名空间下的表名可以相同,但是实际上的list结果是命名空间:表名,建表时不指定命名空间,默认创建到默认的命名空间下,且不显示命名空间的前缀,如下所示:
drop_namespace:
1. disable掉该命名空间下所有的表,并删除之。
2. 待该命名空间为空时,执行`drop_namespace bigData`
DML
put自动按照rowkey按照字典序排序scan 't1', {RAW => true, VERSIONS => 10}查看内存中所有的数据,包括被修改的数据。(特殊手段)delete:delete 'stu', '1001', 'info1:sex'指定到列标识符。deleteall:删除rowkey:deleteall 'stu', '1001'


truncate:清空表,truncate '表名',会自动先执行disable- 列族的verison属性说明:对某一个列族不断进行put后,最终保存的数据版本数。
Hbase详细架构:
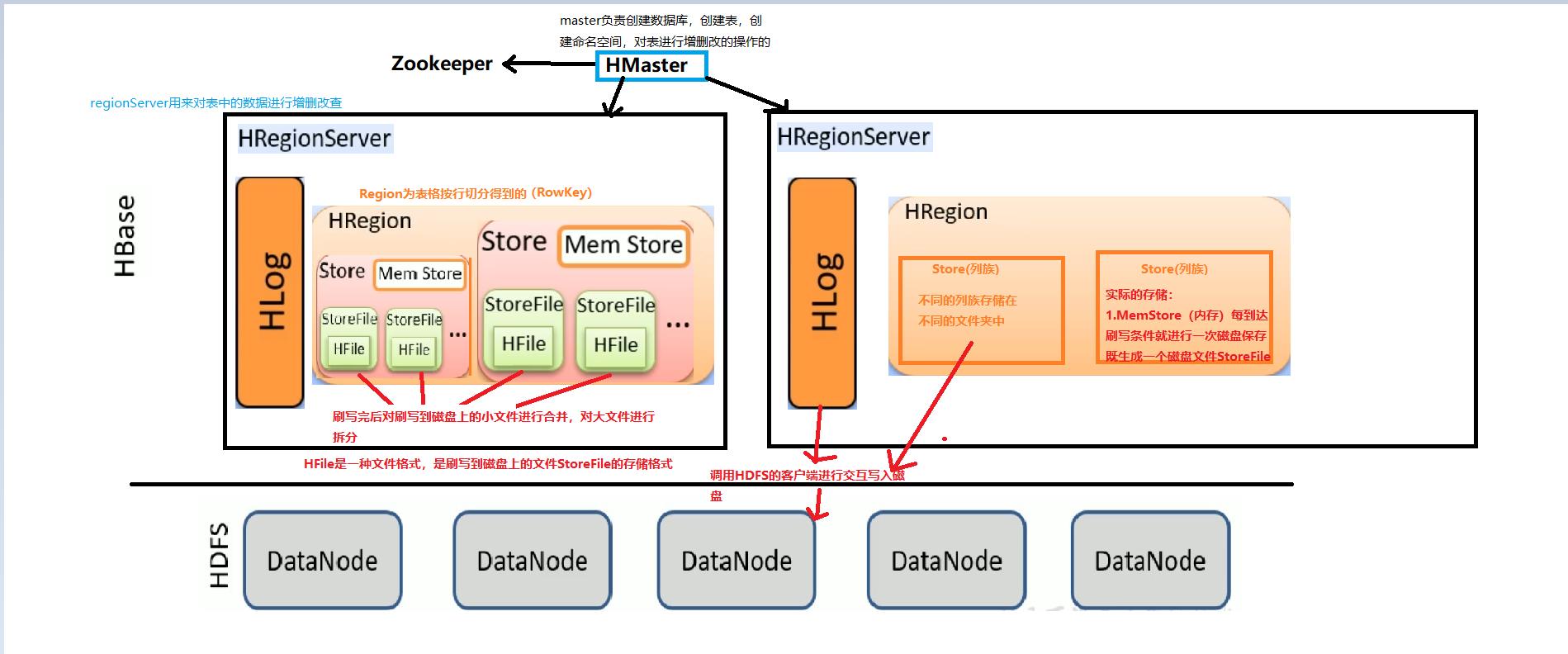
详细说明:
- Hbase底层依赖于HDFS分布式文件系统和ZooKeeper管理机制,优先启动。
- Zookeeper为HMaster分担任务,主要是分担对于表中的数据的增删改的操作。
- 同时HMaster管理HRegionServer,HRegionServer用来进行表格数据的增删改。
- HRegionServer中类似于edits文件的HLOG,预写入日志文件,防止写入过程中数据的丢失,用于状态的恢复。
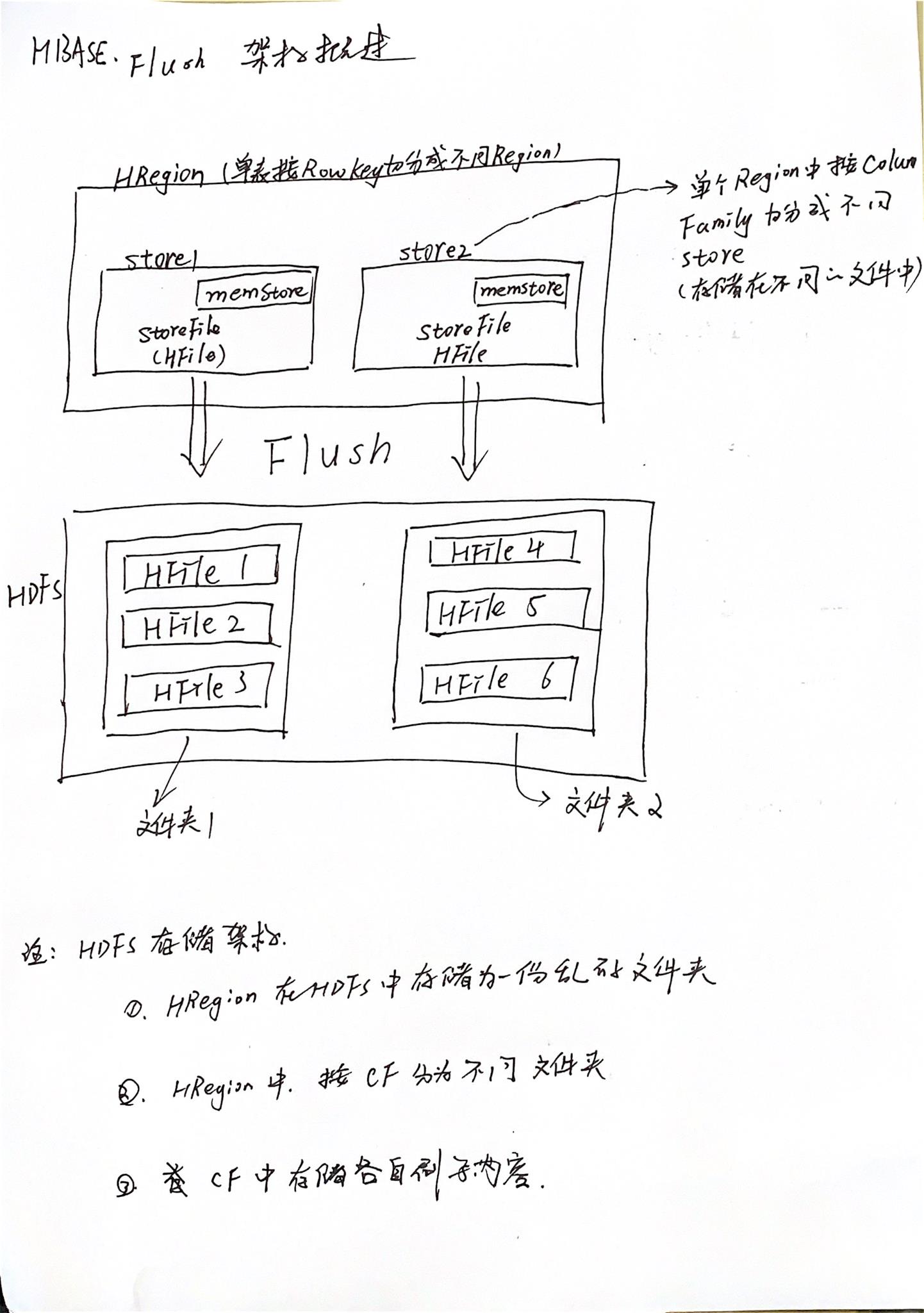
- HRegionServer管理多个HRegion,是表格按照行键切分得到的含有多个列族的数据格式。
- HRegion中存储多个列族(Store),列族之间存储在不同的文件夹中。
- 最终store的数据需要存储在磁盘上,首先存储在内存中,待达到刷写条件之后将数据刷写到磁盘中,以文件的形式储存,其中文件的存储格式是HFile
- 刷写可能产生多个小文件,HDFS将会消耗大量的资源存储小文件,在此之前需要进行小文件的合并,对于大文件,需要进行切分,这是持久化的动态过程。
- 最终在刷写的过程中和HDFS的Client进行交互,成功的将数据刷写到磁盘上。
- 存储关系:(如下图)
写流程
注意:Hbase框架的读比写慢。
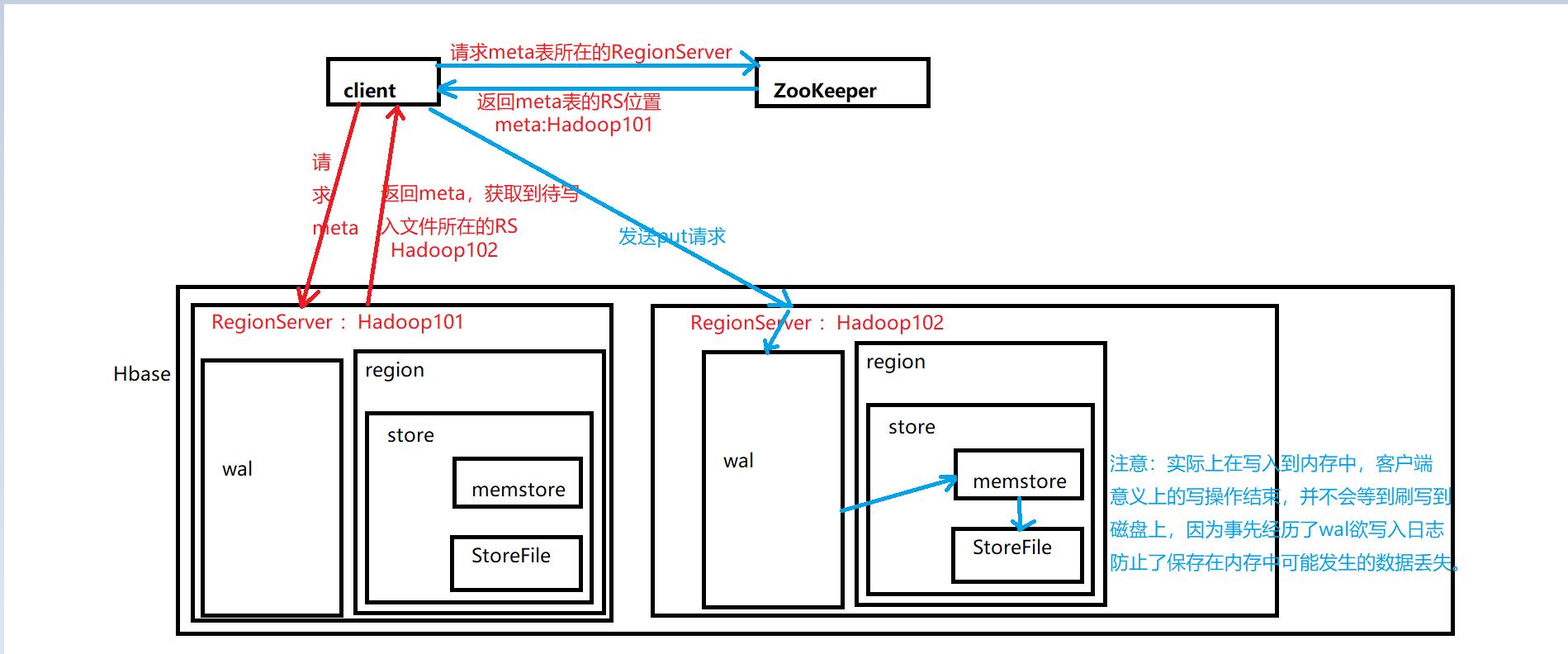
说明:
- zk中存储的是meta的位置信息
- meta表中存储的是用户表的位置信息
老版本hbase说明:
- 老版本中防止meta表格做切分,用
-ROOT-表做维护 - zk中存储的是-root-表的位置信息
- -root-表中存储的是meta表的位置信息
- meta表中存储的是用户表的位置信息
但是事实上证明meta表在实际业务中并不会做切分。
Menstore Flush
对客户端而言,写数据流程在将数据写到内存memstore中时结束。
对于用户及Hbase系统而言,写数据流程需要memstore数据持久化到磁盘才会结束。
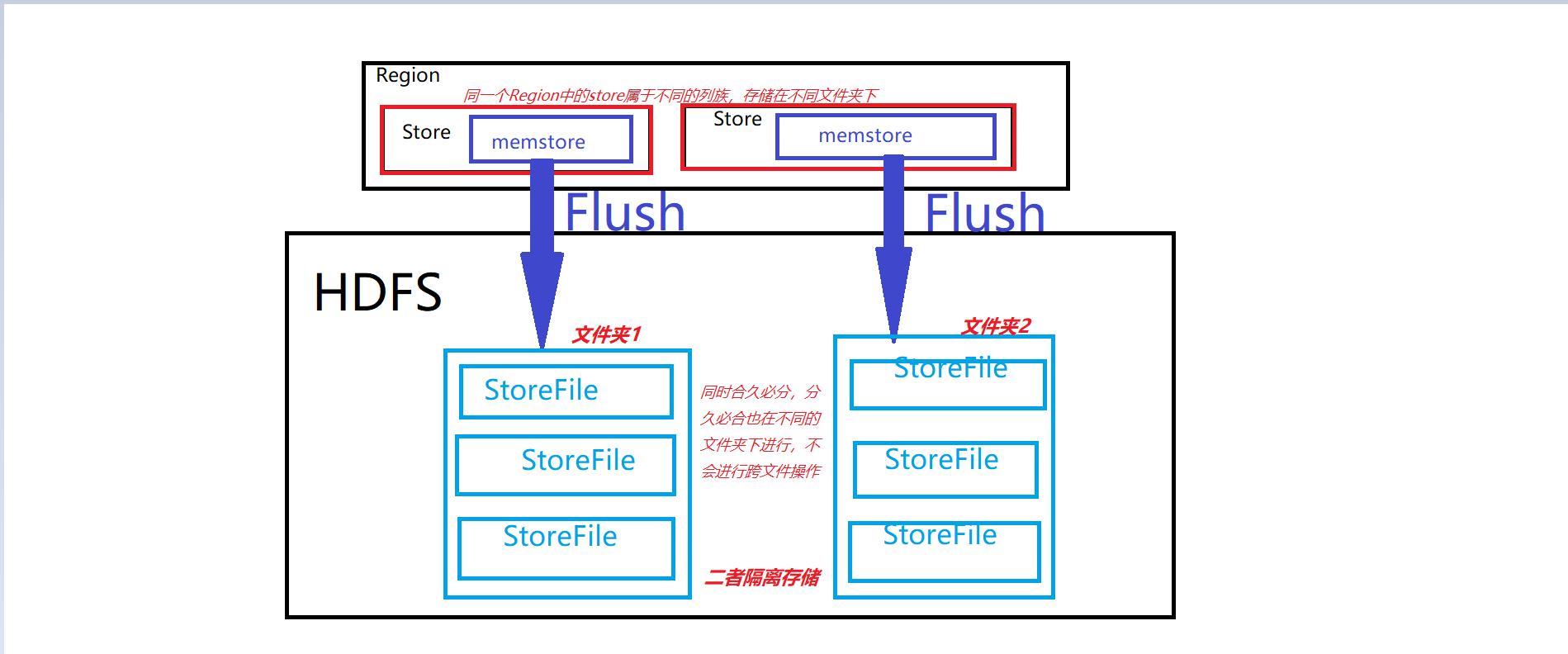
刷写时机:
-
hbase.regionserver.global.memstore.size:
RegionServer的全局memstore大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionServer级别的flush会阻塞客户端读写。 -
hbase.regionserver.global.memstore.size.lower.limit:
开始刷写的最低下限,达到hbase.regionserver.global.memstore.size的95%时开始刷写,此时的刷写不阻塞客户端的写,为防止写的速度大于刷写的速度,而导致该指标一直上升,导致磁盘爆,所以当达到hbase.regionserver.global.memstore.size时,将会阻塞客户端的写入操作,只进行刷写,当指标降下来,继续支持客户端的写入操作。 -
hbase.regionserver.optionalcacheflushinterval:
内存中文件在自动刷新之前能够存活的最长时间,默认是一小时,这里指的时间是最后一次操作开始计时。 -
hbase.hregion.memstore.flush.size:
单个region中的memstore大小超过了默认的128m,则整个region就会进行flush -
老版本的Hbase的HLog关于Flush相关的默认配置:
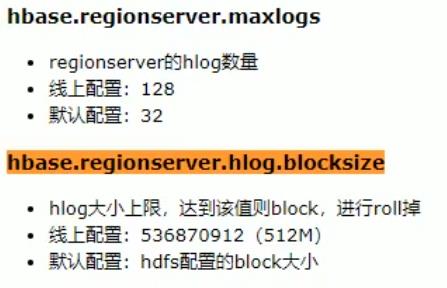
目前该配置已不暴露给用户。
刷写操作的详细解释:
在hbase中新建一张表名为stu,定义两个列族:info1, info2;
在HDFS中实际的存储结构如下图所示:

插入一条数据:put 'stu', '1001', 'info1:name', 'zza',并刷写到磁盘中(flush 'stu')
在info1文件夹中出现了刷写到磁盘中的数据,此时数据由内存memstore刷写到磁盘上,memstore中已无此数据,插入第二条数据后再次刷写,并不会将第一条插入的数据进行刷写,因为在内存中已被清除。
读流程
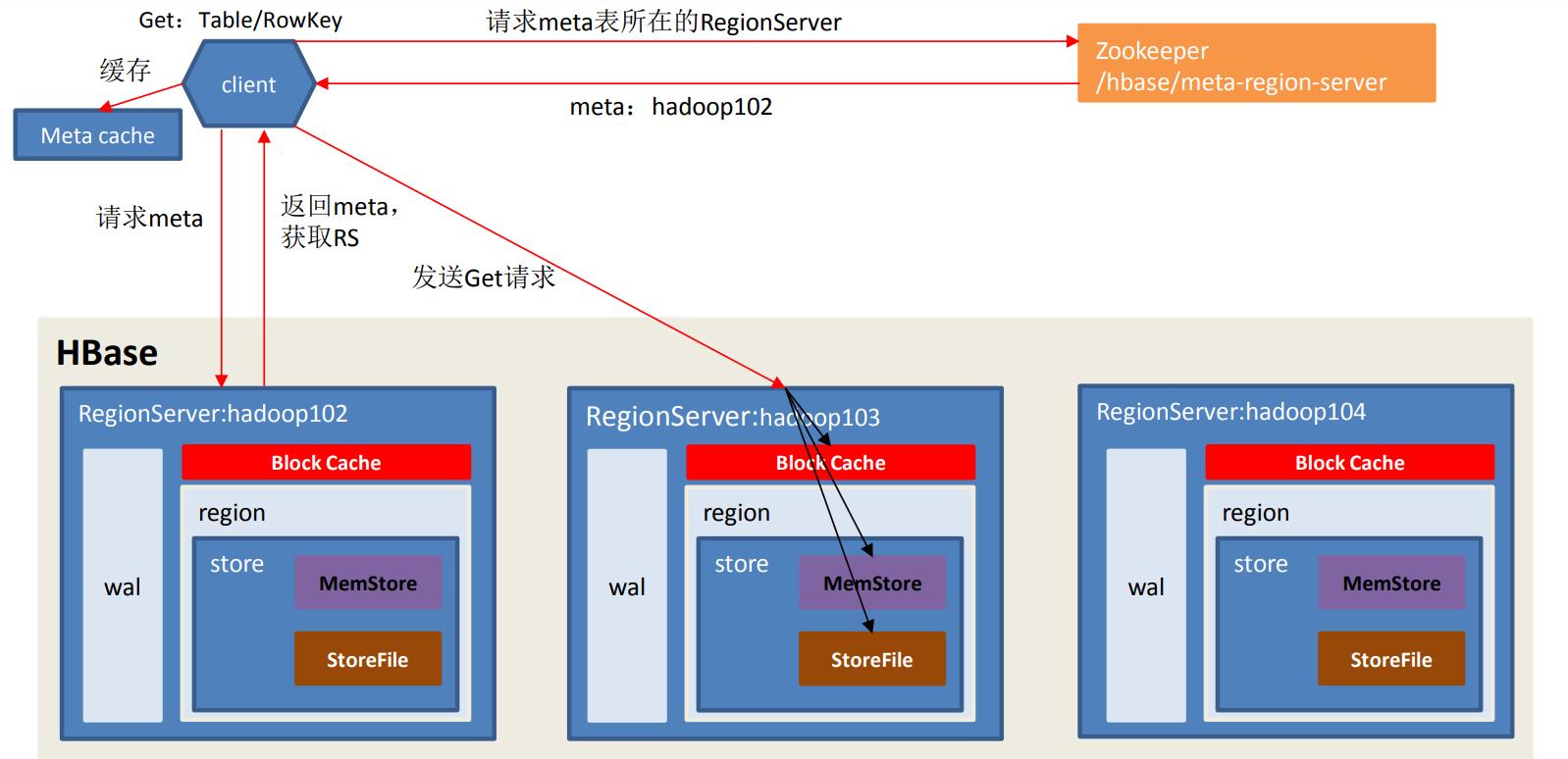
注解:读流程和写流程的前期操作一样,都是先对操作文件进行定位,定位后向RegionServer发送Get请求。
文件可能存在的位置为:磁盘(StoreFile)、内存(memstore)、内存缓存区(blockCache),读取时如果待读取的文件在BlockCache中已经存在,则略过到磁盘扫描的操作,反之进行磁盘和内存中进行扫描,将扫描得到的数据进行merge,将时间戳最大的检索数据作为读取结果返回,既最终决定数据的是时间戳。
StoreFile Compaction
定期的刷写过程会产生许多小文件,会定期执行文件的合并。
分类:
- Minor Compaction
将所有的小文件合并成一个,不会做全局合并 - Major Compaction
将store中的所有文件合并成一个文件,是全局合并。
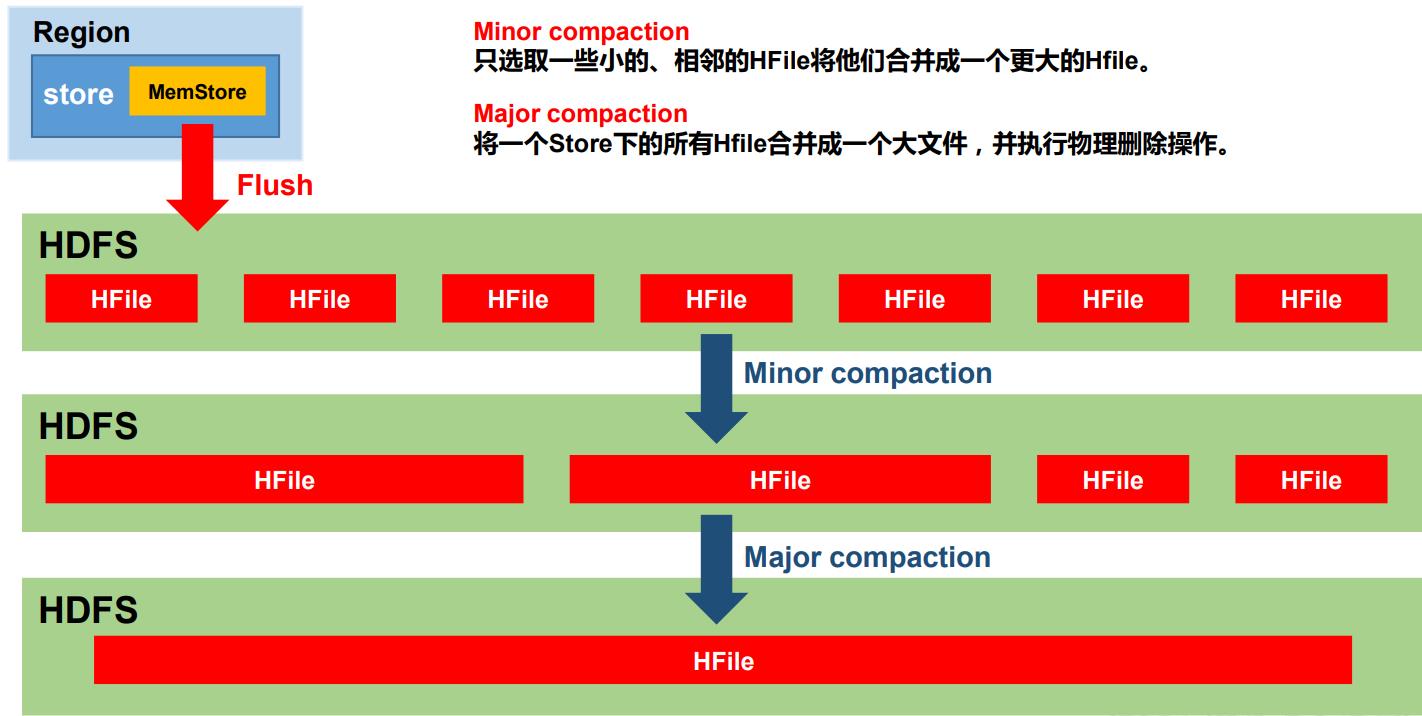
- 当store中的文件数超过三个文件时,执行小合并(MinorCompact)会触发大合并(MajorCompact),执行的结果和大合并一样;小于三个只能手动触发大合并达到大合并的效果。
- compact和MajorCompact的区别:
- Minor Compaction
会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据 - Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。
- Minor Compaction
默认合并条件:
Hbase配置文件分析:
<property>
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
<description>The time (in miliseconds) between 'major' compactions of
all
HStoreFiles in a region. Default: Set to 7 days. Major compactions tend to
happen exactly when you need them least so enable them such that they
run at
off-peak for your deploy; or, since this setting is on a periodicity that is
unlikely to match your loading, run the compactions via an external
invocation out of a cron job or some such.
</description>
</property>
一个region进行 major compaction合并的周期,在这个点的时候, 这个region下的所有hfile会进行合并,默认是7天,major compaction非常耗资源,建议生产关闭(设置为0),在应用空闲时间手动触发
<property>
<name>hbase.hstore.compactionThreshold</name>
<value>3</value>
<description>
<!-- more than >= -->
If more than this number of HStoreFiles in any one HStore
(one HStoreFile is written per flush of memstore) then a compaction
is run to rewrite all HStoreFiles files as one. Larger numbers
put off compaction but when it runs, it takes longer to complete.
</description>
</property>
一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当达到3个hfile的时候就会对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长
读写流程不需要master的参与,但是没有master的集群是不健康的,但是基本数据的读写是可以进行的。
补充
以上是关于Hbase的主要内容,如果未能解决你的问题,请参考以下文章
Hbase 出现 org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet 错误(示例代码