Mybatis源码分析三-数据源模块分析,工厂模式的使用
Posted Dark_King_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis源码分析三-数据源模块分析,工厂模式的使用相关的知识,希望对你有一定的参考价值。
目录
数据源是指数据库应用程序所使用的数据库或者数据库服务器,一般我们程序中可能会用到一个或者多个数据源,那么mybatis是怎么创建和维护这些数据源的呢?我们今天数据源模块重点讲下数据源的创建和数据库连接池的实现;
一、数据源的创建
数据源对象是比较复杂的对象,其创建过程相对比较复杂,对于 MyBatis 创建一个数据源, 具体来讲有如下难点:
- 常见的数据源组件都实现了 javax.sql.DataSource 接口;
- MyBatis 不但要能集成第三方的数据源组件,自身也提供了数据源的实现;
- 一般情况下,数据源的初始化过程参数较多,比较复杂; 综上所述,数据源的创建是一个典型使用工厂模式的场景,实现类图如下所示:

- DataSource:数据源接口,JDBC 标准规范之一,定义了获取获取 Connection 的方法;UnPooledDataSource:不带连接池的数据源,获取连接的方式和手动通过 JDBC 获取连 接的方式是一样的;
- PooledDataSource:带连接池的数据源,提高连接资源的复用性,避免频繁创建、关闭 连接资源带来的开销;
- DataSourceFactory:工厂接口,定义了创建 Datasource 的方法; UnpooledDataSourceFactory:工厂接口的实现类之一,用于创建 UnpooledDataSource(不 带连接池的数据源);
- PooledDataSourceFactory:工厂接口的实现类之一,用于创建 PooledDataSource(带连 接池的数据源);
数据源的创建主要使用了工厂模式,工厂模式又分为简单工厂和工厂。那接下来就跟大家具体介绍一下工厂模式。
二、简单工厂模式
1、简单工厂模式介绍
简单工厂属于类的创建型设计模式,通过专门定义一个类来负责创建其它类的实例,被创建的 实例通常都具有共同的父类。类图如下:
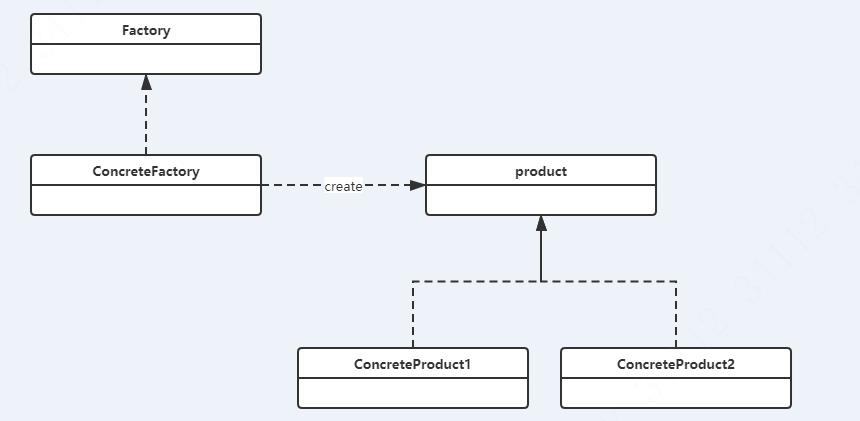
- 工厂接口(Factory):简单工厂的接口,定义了创建产品的方法,具体的工厂类必须实 现这个接口;
- 工厂角色(ConcreteFactory):这是简单工厂模式的核心,由它负责创建全部的类的内 部逻辑。工厂类被外界调用,创建所须要的产品对象。
- 抽象(Product)产品角色:简单工厂模式所创建的全部对象的父类,注意,这里的父 类能够是接口也能够是抽象类,它负责描写叙述全部实例所共同拥有的公共接口。
- 详细产品(Concrete Product)角色:简单工厂所创建的详细实例对象,这些详细的产 品往往都拥有共同的父类。
简单工厂适用场景:简单工厂模式将对象的创建和使用进行解耦,并屏蔽了创建对象可能的 复杂过程,但由于创建对象的逻辑集中工厂类当中,所以简单工厂适合于产品类型不多、需 求变化不频繁的场景;
简单工厂模式的缺点:工厂类负责了所有产品的实例化,违反单一职责原则,如果产品类型 比较多工厂类的代码量会比较大,不利于类的可读性和扩展性;。另外当有新的产品类型加 入时,必须修改工厂类原有的代码,这又违反了开闭原则;
2、示例代码
1、定义产品接口类Game.java
/**
*
* @author DarkKing
*/
public interface Game {
void play();
}2、定义产品实体类SuperMarioGame.java
public class SuperMarioGame implements Game{
private String name;
private String begin;
private String stop;
private String play;
@Override
public void play() {
System.out.println("超级玛丽游戏开始");
}
public SuperMarioGame(String name) {
this.name = name;
}
public SuperMarioGame(String begin, String stop, String play) {
this.begin = begin;
this.stop = stop;
this.play = play;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getBegin() {
return begin;
}
public void setBegin(String begin) {
this.begin = begin;
}
public String getStop() {
return stop;
}
public void setStop(String stop) {
this.stop = stop;
}
public String getPlay() {
return play;
}
public void setPlay(String play) {
this.play = play;
}
}3、定义产品实体类CastlevaniaGame.java
public class CastlevaniaGame implements Game{
private String name;
private String begin;
private String stop;
private String play;
@Override
public void play() {
System.out.println("恶魔城游戏开始");
}
public CastlevaniaGame(String name) {
this.name = name;
}
public CastlevaniaGame(String begin, String stop, String play) {
this.begin = begin;
this.stop = stop;
this.play = play;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getBegin() {
return begin;
}
public void setBegin(String begin) {
this.begin = begin;
}
public String getStop() {
return stop;
}
public void setStop(String stop) {
this.stop = stop;
}
public String getPlay() {
return play;
}
public void setPlay(String play) {
this.play = play;
}
}
4、定义开发游戏工厂接口 GameFactory .java
/**
* <p>开发游戏工厂类</p>
*
* @author DarkKing
*/
public interface GameFactory {
public Game createGame(String gameName);
}
5、定义开发游戏工厂实现类 GameFactoryImpl .java
/**
* <p>开发游戏工厂类</p>
*
* @author DarkKing
*/
@Component
public class GameFactoryImpl implements GameFactory{
@Override
public Game createGame(String gameName) {
Game game= null;
if(gameName.equals("superMario")){
game = new CangSmallMovie("超级玛丽");
}else if(gameName.equals("Castlevania")){
game= new JiaSmallMovie("恶魔城");
}
//开发游戏过程
//…………
//此处省略一万字
return game;
}
}三、工厂模式
1、工厂模式介绍
工厂模式属于创建型模式,它提供了一种创建对象的最佳方式。定义一个创建对象的接口, 让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。类图如下:

- 产品接口(Product):产品接口用于定义产品类的功能,具体工厂类产生的所有产品都 必须实现这个接口。调用者与产品接口直接交互,这是调用者最关心的接口;
- 具体产品类(ConcreteProduct):实现产品接口的实现类,具体产品类中定义了具体的 业务逻辑;
- 工厂接口(Factory):工厂接口是工厂方法模式的核心接口,调用者会直接和工厂接口 交互用于获取具体的产品实现类;
- 具体工厂类(ConcreteFactory):是工厂接口的实现类,用于实例化产品对象,不同的具 体工厂类会根据需求实例化不同的产品实现类;
2、为什么要使用工厂模式?
答:对象可以通过 new 关键字、反射、clone 等方式创建,也可以通过工厂模式创建。对于 复杂对象,使用 new 关键字、反射、clone 等方式创建存在如下缺点:
- 对象创建和对象使用的职责耦合在一起,违反单一原则;
- 当业务扩展时,必须修改代业务代码,违反了开闭原则; 而使用工厂模式将对象的创建和使用进行解耦,并屏蔽了创建对象可能的复杂过程,相对简 单工厂模式,又具备更好的扩展性和可维护性,优点具体如下:
- 把对象的创建和使用的过程分开,对象创建和对象使用使用的职责解耦;
- 如果创建对象的过程很复杂,创建过程统一到工厂里管理,既减少了重复代码,也方便 以后对创建过程的修改维护;
- 当业务扩展时,只需要增加工厂子类,符合开闭原则;
3、代码示例
1、定义GameFactory抽象工厂类
public interface GameFactory {
public Game createGame();
}2、CastlevaniaGameFactory产品工厂类
@Component
public class CastlevaniaGameFactory implements GameFactory {
@Override
public Game createGame(String GameName) {
Game game = new CastlevaniaGame("恶魔城");
//游戏开发
//…………
//此处省略一万字
return game;
}
}3、SuperMarioGameFactory 产品工厂类
@Component
public class SuperMarioGameFactory implements GameFactory {
@Override
public Game createGame() {
Game game = new SuperMarioGame("超级玛丽");
//游戏开发
//…………
//此处省略一万字
return game;
}
}了解完工厂模式,我们开始学习数据库的连接池技术的实现原理
四、数据库连接池技术解析
1、数据库连接池技术介绍
数据库连接池技术是提升数据库访问效率常用的手段,使用连接池可以提高连接资源的复用 性,避免频繁创建、关闭连接资源带来的开销,池化技术也是大厂高频面试题。MyBatis 内 部就带了一个连接池的实现,接下来重点解析连接池技术的数据结构和算法;先重点分析下 跟连接池相关的关键类:
- PooledDataSource:一个简单,同步的、线程安全的数据库连接池
- PooledConnection:使用动态代理封装了真正的数据库连接对象,在连接使用之前和关 闭时进行增强;
- PoolState:用于管理 PooledConnection 对象状态的组件,通过两个 list 分别管理空闲状 态的连接资源和活跃状态的连接资源,如下图,需要注意的是这两个 List 使用 ArrayList实现,存在并发安全的问题,因此在使用时,注意加上同步控制;
2、获取资源和回收资源的流程

具体流程参考mybatis源码org.apache.ibatis.datasource.pooled.PooledDataSource.popConnection(String, String)
//从连接池获取资源
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();//记录尝试获取连接的起始时间戳
int localBadConnectionCount = 0;//初始化获取到无效连接的次数
while (conn == null) {
synchronized (state) {//获取连接必须是同步的
if (!state.idleConnections.isEmpty()) {//检测是否有空闲连接
// Pool has available connection
//有空闲连接直接使用
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {// 没有空闲连接
if (state.activeConnections.size() < poolMaximumActiveConnections) {//判断活跃连接池中的数量是否大于最大连接数
// 没有则可创建新的连接
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {// 如果已经等于最大连接数,则不能创建新连接
//获取最早创建的连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {//检测是否已经以及超过最长使用时间
// 如果超时,对超时连接的信息进行统计
state.claimedOverdueConnectionCount++;//超时连接次数+1
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;//累计超时时间增加
state.accumulatedCheckoutTime += longestCheckoutTime;//累计的使用连接的时间增加
state.activeConnections.remove(oldestActiveConnection);//从活跃队列中删除
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {//如果超时连接未提交,则手动回滚
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {//发生异常仅仅记录日志
/*
Just log a message for debug and continue to execute the following
statement like nothing happend.
Wrap the bad connection with a new PooledConnection, this will help
to not intterupt current executing thread and give current thread a
chance to join the next competion for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");
}
}
//在连接池中创建新的连接,注意对于数据库来说,并没有创建新连接;
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
//让老连接失效
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// 无空闲连接,最早创建的连接没有失效,无法创建新连接,只能阻塞
try {
if (!countedWait) {
state.hadToWaitCount++;//连接池累计等待次数加1
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);//阻塞等待指定时间
state.accumulatedWaitTime += System.currentTimeMillis() - wt;//累计等待时间增加
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {//获取连接成功的,要测试连接是否有效,同时更新统计数据
// ping to server and check the connection is valid or not
if (conn.isValid()) {//检测连接是否有效
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();//如果遗留历史的事务,回滚
}
//连接池相关统计信息更新
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {//如果连接无效
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;//累计的获取无效连接次数+1
localBadConnectionCount++;//当前获取无效连接次数+1
conn = null;
//拿到无效连接,但如果没有超过重试的次数,允许再次尝试获取连接,否则抛出异常
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
3、回收连接资源的过程
连接资源回收流程如下图: 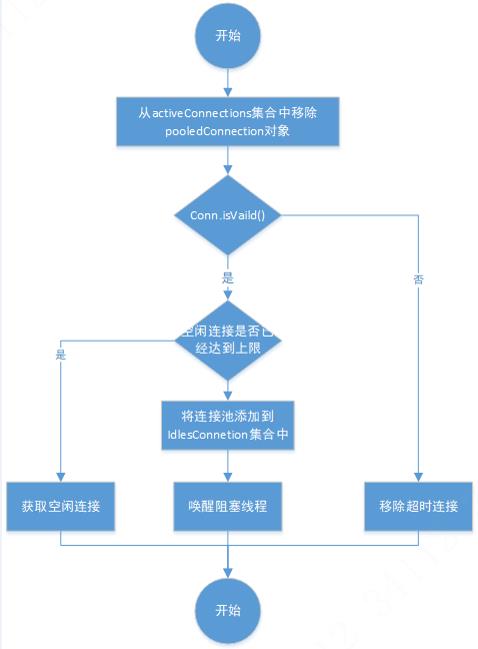
源码分析: org.apache.ibatis.datasource.pooled.PooledDataSource.pushConnection(PooledConnection)
//回收连接资源
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {//回收连接必须是同步的
state.activeConnections.remove(conn);//从活跃连接池中删除此连接
if (conn.isValid()) {
//判断闲置连接池资源是否已经达到上限
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
//没有达到上限,进行回收
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();//如果还有事务没有提交,进行回滚操作
}
//基于该连接,创建一个新的连接资源,并刷新连接状态
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
state.idleConnections.add(newConn);
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
//老连接失效
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
//唤醒其他被阻塞的线程
state.notifyAll();
} else {//如果闲置连接池已经达到上限了,将连接真实关闭
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//关闭真的数据库连接
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
//将连接对象设置为无效
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
state.badConnectionCount++;
}
}
}以上是关于Mybatis源码分析三-数据源模块分析,工厂模式的使用的主要内容,如果未能解决你的问题,请参考以下文章