曲鸟全栈UI自动化教学:Selenium页面操作原理及如何高效的进行元素定位
Posted 曲鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了曲鸟全栈UI自动化教学:Selenium页面操作原理及如何高效的进行元素定位相关的知识,希望对你有一定的参考价值。
一、前言
上篇文章中我们成功编写并启动了第一个selenium脚本。那Selenium是怎样知道我们想要操作哪个元素的呢?
这篇文章将为你讲解Selenium的页面操作原理和高效的元素定位方法。
(PS:个人在用的人工智能学习网站推荐给大家:captainai,觉得不错请三连支持一下)
文章目录
二、Selenium是如何操作页面元素的?
Selenium首先会查找我们给予的元素地址是否存在,如果存在则进行我们指定的操作。
例如上篇文章中的这行代码,它用于在百度搜索框输入曲鸟 csdn:
# 在输入框输入:曲鸟 csdn
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys('曲鸟 csdn')
代码解释:首先,我们通过【driver.find_element】方法,给予了两个参数:
1.定位的方法:Xpath;
2.元素地址://*[@id="kw"];
通过这两个参数得以让Selenium能够找到百度的搜索框元素,再通过【send_keys】方法传递想要输入的内容曲鸟 csdn,Selenium就会在其进行输入。
上面的例子使用的定位方法是Xpath,除此之外Selenium还支持七种(共八种)定位方法:

是不是感觉有点多?但我们无需全部掌握它们!
我们无需花太多精力在学习定位上,虽然我们的每个自动化操作都需要进行元素定位,但浏览器的调试工具已经可以帮我们获取元素地址了。
有小伙伴会说,通过工具定位出来的元素地址一长串是否会影响调试和体验呢?
其实担心是多余的,首先元素地址不同于代码,它不太需要具备可读性。只要能够定位成功且有一定的稳定性就行了。其次,如果你为了减少元素地址的长度,而花时间去手写元素地址的话,这个时间会是通过工具定位的数倍!自动化测试本就需要高效的完成脚本,减少自动化用例编写的时间占比,从而达到高效自动化的目的。现在为了元素地址的可读性来增加自动化编写的时长是得不偿失的!并且现在随着react、vue的普及,前端组件化应用的越来越多,通过【id、name、class】这些定位方式已经不太适用了 (前提是开发不愿意加唯一标识(唯一的【id、name】等)的情况下) 所以完全没必要花大量的时间去搞懂八种定位,只需要简单了解即可。
另外一点,Xpath定位很强大,花时间搞懂Xpath远比花时间去学习完八种定位要高效的多!
Xpath相对CSS选择器来说更灵活,虽然Xpath性能对于CSS选择器来说性能会差一些,但做自动化测试半秒一秒的差距也毫不影响。
三、高效的定位方法和Xpath定位讲解
1. 利用浏览器工具
【Chrome】浏览器自带了定位方式的获取工具,按下F12(右键鼠标,点击"检查")也可以,按图中的步骤操作就可以获取到需要操作的元素地址
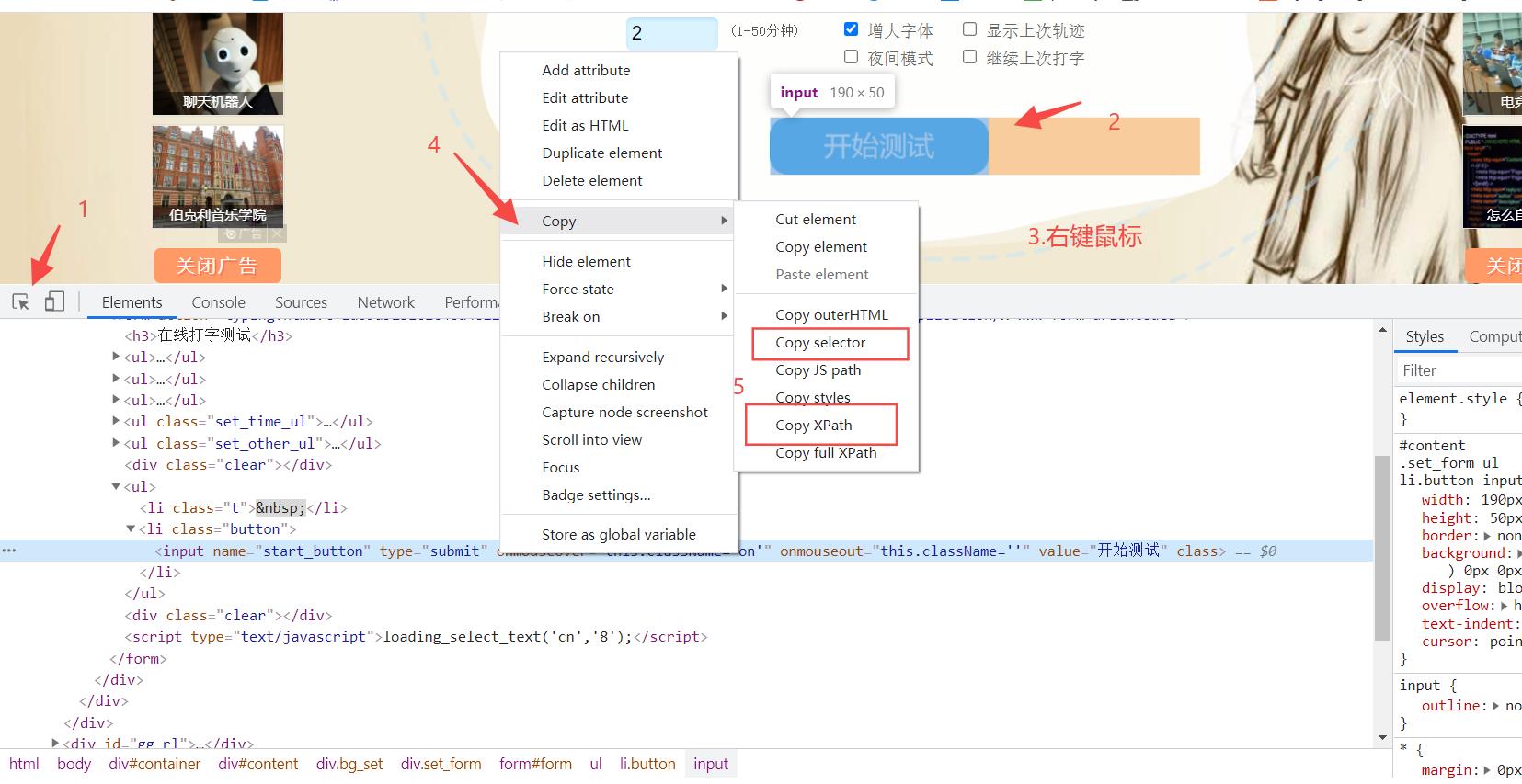
但在我们实际应用过程中,会出现定工具获取的Xpath定位地址,代码跑起来定位不到的情况!这种情况一般可能是因为元素的id是动态的(重新访问页面元素的id会变)或者所属层级冲突(操作页面步骤的顺序改变导致层级优先级不同)这个时候就可以借助Xpath的高级运用(文本关键字匹配,条件匹配等)来解决。
2.Xpath定位简单介绍
1. 绝对定位
通过【Chrome】自带的定位工具,选择【Copy full XPath】得到的就是xpath绝对路径 (非特殊情况不建议使用,使用相对定位即可)

路径代码
/html/body/div/div[2]/div[5]/div[1]/div/form/span[1]/input
2. 相对定位
通过【Chrome】自带的定位工具,选择【Copy XPath】得到的就是xpath相对路径 (推荐使用)
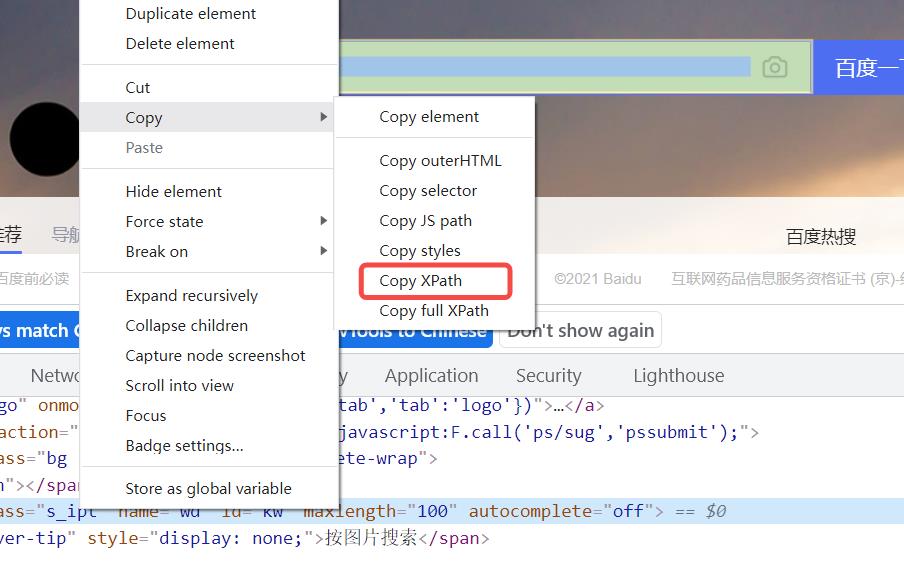
路径代码
下面的代码会查找id等于kw的元素:
//*[@id="kw"]
3. Xpath代码解释
1. //和/的区别和含义:
//代表会在所有节点去进行查找,如果要指定层级或逐层查找的话可以使用/。
举个例子:
下面的xml代码含义:一个班级下有两个学生【曲鸟 男】、【张三 女】:
<class>
<student>
<name>曲鸟</name>
<gender>男</gender>
</student>
<student>
<name>张三</name>
<gender>女</gender>
</student>
</class>
1)现在我们想获取第一个学生的信息可以这样写:
/class/student[1]
输出结果
<name>曲鸟</name>
<gender>男</gender>
2)想获取第一个学生的名称可以这样写:
/class/student[1]/name
输出结果
曲鸟
上面的代码是一层一层(class->student->name),那是否可以不指定层级,直接查找名称呢?
3)通过//获取学生名称:
/class/name
甚至还可以这样写
//name
输出结果
张三
虽然获取到姓名了,但变成张三了,如果你通过//name[1]的方式来获取的话,会发现执行失效!
所以,//是不能够指定下标的,如果想获取曲鸟的话可以通过校验文本的方式来匹配:
//name[text()="曲鸟"]
Xpath在线练习地址:https://www.bejson.com/testtools/xpath/
2. *的含义
*代表匹配任何元素节点,通过分析下图百度搜索框的源码发现它的标签为input,那么我们将代码改为这样//input[@id="kw"]也是可行的。

3. []的含义
[]中用于放置具体的匹配规则,之前代码中的[@id="kw"]代表匹配id等于kw的元素;分析上图红框标签的属性会发现,如果替换为[@name="wd"]也是能够匹配成功的;还可以改写为[@class="s_ipt"];
4. Xpath的模糊匹配和条件匹配
Xpath中=用于全匹配,那它支持模糊匹配吗?
答案是支持的,Xpath中=必须一模一样才算匹配成功。Xpath也可以通过contains进行模糊匹配,之前代码中的[@id="kw"]可以改写为[contains(@id, "k")]这样也能够匹配成功。它的含义为匹配id名称包含k的元素。
如果有两个id都包含k那不是就匹配失败了吗?
是的,这个时候就可以使用Xpath的条件判断,例如有两个元素,他们的id分别为:kw1、kw2。我们想通过模糊匹配来匹配kw1的话,可以这样写[contains(@id,"k") and contains(@id,"1")],代码含义为匹配id名称既包含k又包含1的元素。
Xpath支持的条件【and、or、not、contains、starts-with、string(.)】:
//input[@type="text" and @name="wd"]
//input[@type="text" or @name="wd"]
//input[@type="text" and not(contains(@name,'wd'))]
//input[starts-with(@text,"te")]
//input[ends-with(@text,"te")]
//input[contains(@name, 'wd')]
Xpath可以通过显示的文本进行匹配吗?
可以的,下面是百度页右上角【新闻】标签的源码

通过文本匹配的话,代码可以这样写 (类似于八大定位方式中的By.LINK_TEXT):
//*[text()="新闻"]
通过闻字模糊匹配的话可以这样写 (类似于八大定位方式中的By.PARTIAL_LINK_TEXT):
//*[contains(text(),"闻")]
四、总结
Xpath的功能还有很多,但对于自动化来讲掌握上述这几种常用方法已经足够了!万一还不够用,我们还可以通过airtest【图像识别】的定位方法来解决。
可以阅读 重复元素如何定位区分?Selenium的缺点让图像识别来弥补 这篇文章进行了解。后续也会在该专栏的实战篇中进行详细图像识别定位的教学,欢迎订阅本专栏!
以上是关于曲鸟全栈UI自动化教学:Selenium页面操作原理及如何高效的进行元素定位的主要内容,如果未能解决你的问题,请参考以下文章