Python爬虫编程思想(46):使用Chrome验证XPath
Posted 蒙娜丽宁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫编程思想(46):使用Chrome验证XPath相关的知识,希望对你有一定的参考价值。
验证XPath代码是否正确,并不一定要使用lxml以及其他解析库,直接使用Chrome浏览器的开发者工具就可以搞定。
仍然拿京东商城为例,显示首页的开发者工具,然后定位到首页导航条的“秒杀”代码的位置,并安装上一节的方法复制该位置的XPath代码。然后在开发者工具中切换到Console选项卡,并输入如下的代码:
$x('//*[@id="navitems-group1"]/li[1]/a')其中$x是用来运行XPath的函数,参数需要指定XPath代码。如果XPath代码中包含的是双引号,参数要使用单引号括起来,如果XPath代码中包含的单引号,参数要使用双引号括起来。输入完成后,按Enter键,如果XPath可以至少选择一个节点,那么在下方就是显示这些节点,展开节点后,会看到节点中的各种属性的值,如图1所示。
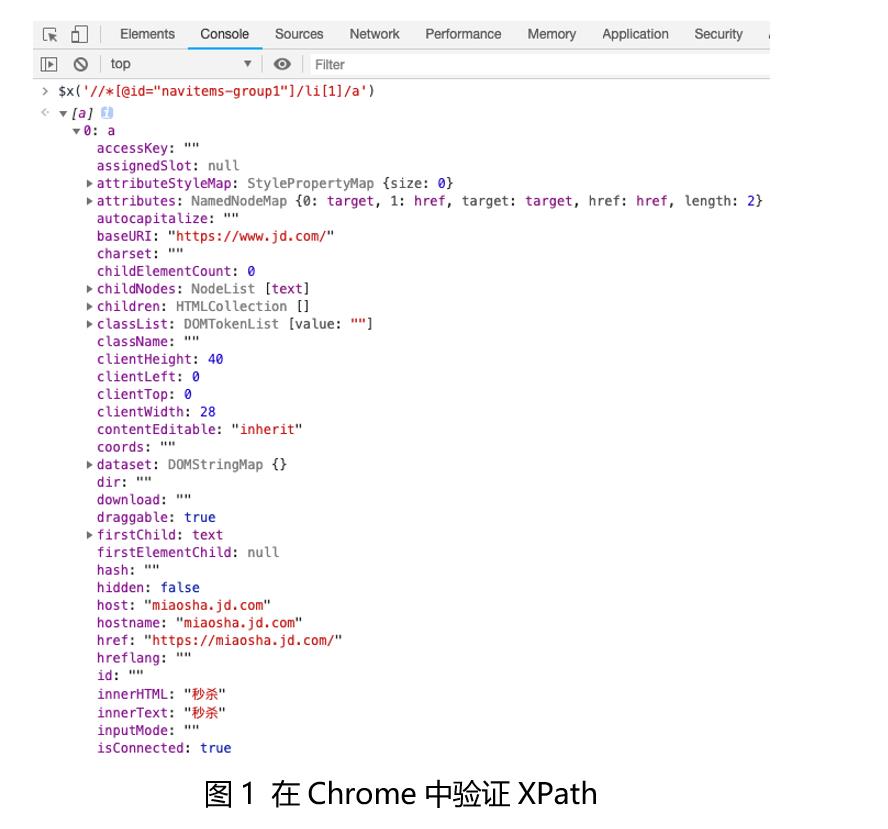
上面的XPath代码用于选择包含“秒杀”文本的<a>节点。从图1所示的选择结果可以看出,“秒杀”文本在<a>节点的innerhtml属性和innerText属性中。读者在编写或得到一行XPath代码时,可以用这种方式验证XPath代码是否正确。
以上是关于Python爬虫编程思想(46):使用Chrome验证XPath的主要内容,如果未能解决你的问题,请参考以下文章