Linux监控分析
Posted 花醉红尘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux监控分析相关的知识,希望对你有一定的参考价值。
一、linux硬件
CPU(计算、逻辑判断、逻辑处理)、内存(cpu在内存中处理数据(记忆片段))、IO(对磁盘在一段时间内的读写操作)
cpu和内存间有块区域缓存(二级缓存)
cpu高:检查cpu,查看系统的瓶颈点是否在cpu上,看cpu把时间花费在哪个地方了,如果说,在这过程中,cup没有浪费时间,只能加cpu;如果cpu确实有浪费时间的地方,解决这个地方。
cpu低:检查内存里的数据够不够,是否内存和磁盘在进行频繁的IO操作,如果cpu频繁的和磁盘进行IO操作,说明内存比较小,磁盘比较繁忙,这时候,就需要加内存。
二、物理内存、虚拟内存
从磁盘上开辟出来的一块地址空间,把它当作内存使用,这块内存来源于之前系统打开的应用程序消耗的内存空间,关闭后,将这块空间当做内存使用。
如果说,操作系统在运行过程中,使用到了虚拟内存,说明应用程序内存使用得不合理,需要调整物理内存的使用。
三、linux监控命令
1、top
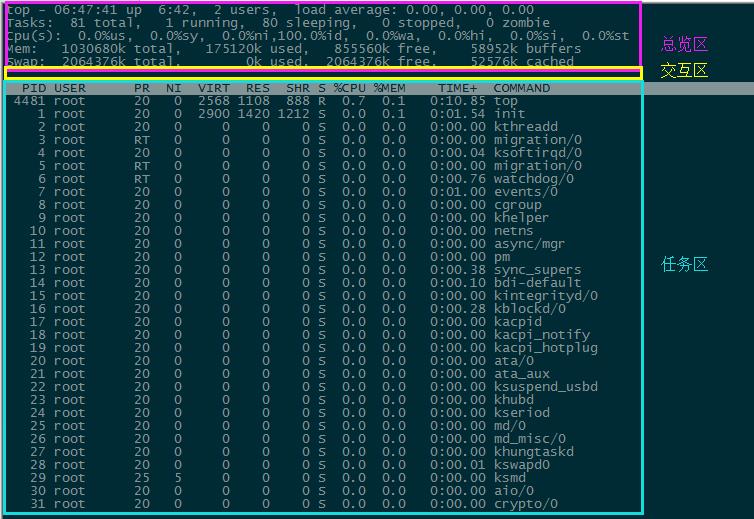
第一部分 总览区
第1行:
load average:三个值分别代表操作系统过去1分钟、5分钟、15分钟内的平均负载,直接反应操作系统压力情况(使用uptime也可以查看)
负载可以理解为:操作系统排队的进程数
在top命令下,输入"1",可以查看cpu的颗粒数
通过查看/proc/cpuinfo这个文件也可以查看cpu的基本信息
如果cpu的颗粒数为2,使用top命令显示的负载值小于2,那么说明cpu的负载是正常的;当top命令的显示值大于2的时候,说明cpu繁忙,出现排队的情况
第2行:
系统总的进程数 正在运行的进程 休眠的进程 停止的进程 僵尸进程
僵尸进程 → 意外终止或者唤醒不了的进程
第3行:
操作系统cpu的平均使用率
多颗cpu单个进程的使用率可以超过100%,cpu的使用率要平均
cpu(s):cpu的平均使用率,不会超过100%
线程是进程的最小单位,一个进程就是一个应用程序,进程占用物理空间,进程是最快也是最稳定的,线程共享进程下的物理空间,线程能支持更大的并发
us → 用户进程消耗的cpu sy → 操作系统进程(内核使用调度)消耗的cpu ni → 优先级高的进程消耗的cpu
id → 空闲状态的cpu的cpu wa → 等待io操作消耗的cpu
cpu使用率高的分析:
判断是用户进程还是系统进程消耗的cpu高:
用户态占用cpu高:
找到占用cpu高的进程,分析该进程消耗cpu的线程,分析线程的运行情况(调用方法、执行请求),从而找到造成cpu使用率高原因
如何查找进程中消耗cpu最高的线程:shift + p
如何监控进程中的线程:top -H -p 进程号
系统态占用cpu高:
如果是因为磁盘繁忙导致(磁盘问题),看是读操作多还是写操作多
读操作多,可能因为内存不足,导致内存向硬盘同步数据
写操作多使用,分析应用系统在往磁盘中写什么,减小写操作
如果不是因为磁盘繁忙导致的:
strace命令跟踪系统内核的调用情况,监控时间段内,操作系统调用哪个内核,什么请求调用这个内核,从而判断系统cpu使用率高的原因
cpu
us → 执行用户程序消耗的cpu
sy → 系统态(内核态)cpu
us+sy=cpu总使用率
用户的进程或者线程的cpu发生中断,进程切换(需要内核进程调度),这时候调用的是系统态的cpu。
所有进程代码里边调用了操作系统内核的都叫内核态cpu
进程的状态:
①running linux区分不了准备好等待cpu调用以及正在运行状态的进程,都叫running
②中断可恢复状态
③中断不可恢复状态
④僵尸进程
假设单核机子的操作系统上启动了4个进程
进程A running(等待运行) → 优先级最高 → running(运行)比方在此处需要进行一次IO操作 → 等待IO(中断可恢复)这时候cpu切换 → running(运行)
进程B running(等待运行) → 优先级次高 → running(运行) → 等待外部变量输入 → 中断不可恢复(因不可预知)
进程C running(等待运行) → 优先级次于B → running(运行) → 这时候假设A处理完毕给cpu发送一个中断信号 → 中断可恢复
进程D running(等待运行)
load(负载)=等待io的进程+等待cpu处理的进程
什么时候会出现:cpu的值很低,负载很高
大量等待磁盘交互的进程,这时候load的值很高,cpu利用率就会低
数据库全表扫描的时候(explain type=ALL)
第4行:
内存 total → 操作系统总内存 used → 已使用的 free → 剩余的
Java应用程序没有内存使用率的说法 jvm开辟内存 gc
第5行:
虚拟内存
第二部分 交互区 用于输入命令
输入h,显示交互区的命令:
第三部分 任务区 选中任务区栏
输入c,显示进程所在的路径
输入shift+f,显示任务栏栏目的开关,如下图:
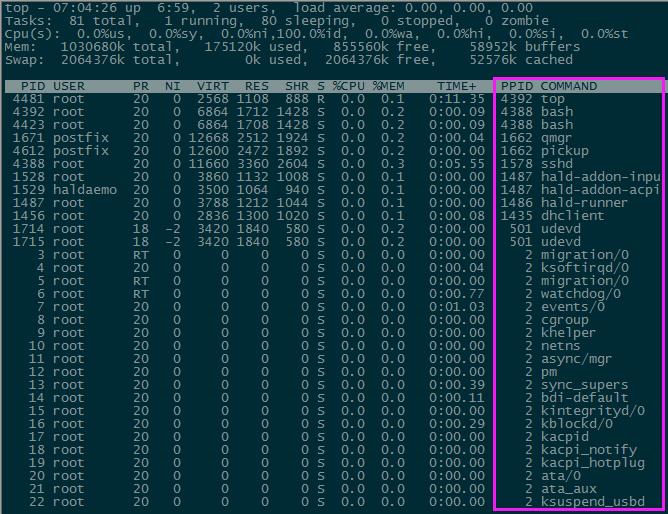
在此界面选择对应的命令,可以在任务栏列表中,增加显示项目,譬如输入b,如下图:
输入shift+p按cpu排序
输入shift+m按内存排序
pid → 进程id user → 进程所有者的用户名 pr → 优先级 ni → nice值,负值标识高优先级、正值标识低优先级
virt → 进程使用的虚拟内存总量 res → 进程使用的、未被换出的物理内存大小 shr → 共享内存大小(kb)
s → 进程状态(d:不可中断的睡眠进程、r:运行、s:睡眠、t:跟踪/停止、z:僵尸进程)
2、vmstat
用法:
vmstat [-a] [-n] [-S unit] [delay [ count]]
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。

显示列表含义:
R 列表示运行和等待 CPU 时间片的进程数,这个值如果长期大于系统 CPU 个数,说明CPU 不足,需要增加 CPU。
B 列表示在等待资源的进程数,比如正在等待 I/O 或者内存交换等。
memory
swpd 列表示切换到内存交换区的内存大小(单位 KB),通俗讲就是虚拟内存的大小。
如果 swap 值不为 0 或者比较大,只要 si、so 的值长期为 0.这种情况一般属于正常情况。
free 列表示当前空闲的物理内存(单位 KB)。
Buff 列表示 baffers cached 内存大小,也就是缓冲大小,一般对块设备的读写才需要缓冲。
Cache 列表示 page cached 的内存大小,也就是缓存大小,一般作为文件系统进行缓冲,频繁访问的文件都会被缓存,如果 cache 值非常大说明缓存文件比较多,
如果此时 io中的 bi 比较小,说明文件系统效率比较好。
swap
si 列表示由磁盘调入内存,也就是内存进入内存交换区的内存大小。
so 列表示由内存进入磁盘,也就是有内存交换区进入内存的内存大小。
一般情况下,si、so 的值都为 0,如果 si、so 的值长期不为 0,则说明系统内存不足,需要增加系统内存。
io
bi 列表示由块设备读入数据的总量,即读磁盘,单位 kb/s。
bo 列表示写到块设备数据的总量,即写磁盘,单位 kb/s。
如果 bi+bo 值过大,且 wa 值较大,则表示系统磁盘 IO 瓶颈。
system
in 列表示某一时间间隔内观测到的每秒设备中断数。
cs 列表示每秒产生的上下文切换次数。
扩展中断和上下问切换理解:
中断:
所谓中断是指CPU对系统发生的某个事件做出的一种反应,CPU暂停正在执行的程序,保留现场后自动地转去执行相应的处理程序,处理完该事件后再返回断点继续执行被“打断”的程序。中断可分为三类,第一类是由CPU外部引起的,称作中断,如I/O中断、时钟中断、控制台中断等。第二类是来自CPU的内部事件或程序执行中的事件引起的过程,称作异常,如由于CPU本身故障(电源电压低于105V或频率在47~63Hz之外)、程序故障(非法操作码、地址越界、浮点溢出等)等引起的过程。第三类由于在程序中使用了请求系统服务的系统调用而引发的过程,称作“陷入”(trap,或者陷阱)。前两类通常都称作中断,它们的产生往往是无意、被动的,而陷入是有意和主动的。
上下文切换:
多任务系统中,上下文切换是指CPU的控制权由运行任务转移到另外一个就绪任务时所发生的事件. 在操作系统中,CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。上下文切换包括保存当前任务的运行环境,恢复将要运行任务的运行环境。通常在三种情况下可能会发生上下文切换:中断处理,多任务处理,用户态切换。
cpu
us 列表示用户进程消耗的 CPU 时间百分比,us 值越高,说明用户进程消耗 cpu 时间越多,如果长期大于 50%,则需要考虑优化程序或者算法。
sy 列表示系统内核进程消耗的 CPU 时间百分比,一般来说 us+sy 应该小于 80%,如果大于 80%,说明可能存在 CPU 瓶颈。
id 列表示 CPU 处在空闲状态的时间百分比。
wa 列表示 IP 等待所占的 CPU 时间百分比,wa 值越高,说明 I/O 等待越严重,根据经验 wa 的参考值为 20%,如果超过 20%,说明 I/O 等待严重,
引起 I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者此哦按监控器的贷款瓶颈(主要是块操作)造成的。
3、 sar
格式:sar [options] [-A] [-o file] t [n]
在命令行中,n 和 t 两个参数组合起来定义采样间隔和次数,t 为采样间隔,是必须有的参数,n 为采样次数,是可选的,默认值是 1,-o file 表示将命令结果以二进制格式存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar 命令的选项很多,下面只列出常用选项:
-u:CPU 利用率
-v:进程、节点、文件和锁表状态。
-d:硬盘使用报告。
-r:显示系统内存的使用情况。
-q:显示运行队列的大小,它与系统当时的平均负载相同
-B:内存分页情况
-b:缓冲区使用情况。
-W:系统交换活动。
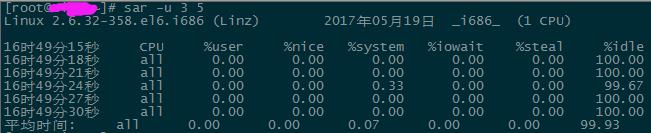
%iowait:I/O 等待所占 CPU 时间百分比。
%idle:CPU 空闲状态的时间百分比。
%iowait 的值过高,表示硬盘存在 I/O 瓶颈, %idle 值高,表示 CPU 较空闲,如果%idle 值高但系统响应慢时,有可能是 CPU 等待分配内存, 此时应加大内存容量。%idle 值如果持续低于 10,那么系统的 CPU 处理能力相对较低,表 明系统中最需要解决的资源是 CPU。
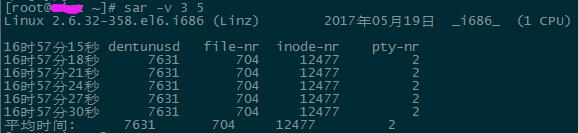
inode-nr:目前核心中正在使用或分配的节点表的表项数。
file-nr:目前核心中正在使用或分配的文件表的表项数。

Kbmemfree:这个值和 free 命令中的 free 值基本一致,所以它不包括 buffer 和 cache 的空间。
kbmemused:这个值和 free 命令中的 used 值基本一致,所以它包括 buffer 和 cache 的空间。
%memused:这个值是 kbmemused 和内存总量(不包括 swap)的一个百分比。
kbbuffers 和 kbcached:这两个值就是 free 命令中的 buffer 和 cache。
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap)。
%commit:这个值是 kbcommit 与内存总量(包括 swap)的一个百分比。

pgpgin/s:表示每秒从磁盘或 SWAP 置换到内存的字节数(KB)。
pgpgout/s:表示每秒从内存置换到磁盘或 SWAP 的字节数(KB)。
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)。
majflt/s:每秒钟产生的主缺页数。

tps:每秒钟物理设备的 I/O 传输总量。
rtps:每秒钟从物理设备读入的数据总量。
wtps:每秒钟向物理设备写入的数据总量。
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s。
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s。

runq-sz:运行队列的长度(等待运行的进程数)。
plist-sz:进程列表中进程(processes)和线程(threads)的数量。
ldavg-1:最后 1 分钟的系统平均负载(System load average)。
ldavg-5:过去 5 分钟的系统平均负载。
ldavg-15:过去 15 分钟的系统平均负载。

pswpin/s:每秒系统换入的交换页面(swap page)数量。
pswpout/s:每秒系统换出的交换页面(swap page)数量。
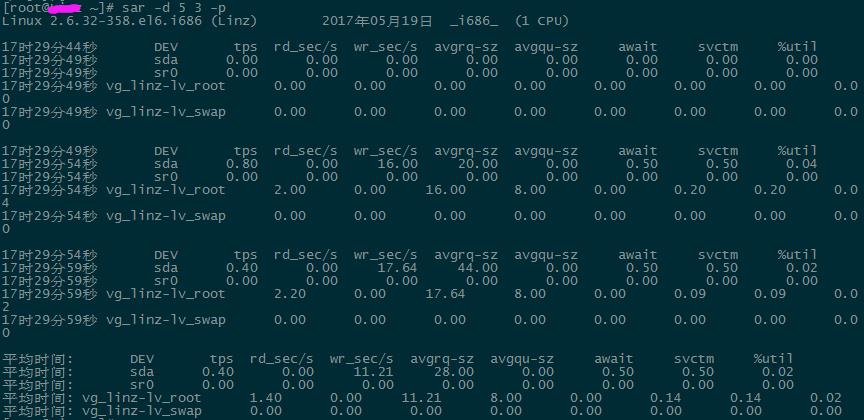
tps:每秒从物理磁盘 I/O 的次数.多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的。
rd_sec/s:每秒读扇区的次数。
wr_sec/s:每秒写扇区的次数。
avgrq-sz:平均每次设备 I/O 操作的数据大小(扇区)。
avgqu-sz:磁盘请求队列的平均长度。
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时,单位是毫秒(1 秒=1000 毫秒)。
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间。
%util:I/O 请求占 CPU 的百分比,比率越大,说明越饱和。
1. avgqu-sz 的值较低时,设备的利用率较高。
2. 当%util 的值接近 1% 时,表示设备带宽已经占满。
总结:
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑 CPU 存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑 I/O 存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
4、iostat
用途:iostat 是对系统的磁盘 I/O 操作进行监控,它的输出主要显示磁盘读写操作的统计信息,同时给出 CPU 的使用情况。同 vmstat 一样,iostat 不能对某个进程进行深入分析,仅对操作系统的整体情况进行分析。
用法:
iostat [ -c | -d ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ device [ ... ] |ALL ] [ -p [ device | ALL ] ][ interval [ count ] ]
-c: 仅显示 CPU 统计信息.与-d 选项互斥.
-d :仅显示磁盘统计信息.与-c 选项互斥.
-x device 输出指定要统计的磁盘设备名称,默认为所有磁盘设备.
-interval :指两次统计间隔时间
- count :按照 interval 指定的时间间隔统计的次数
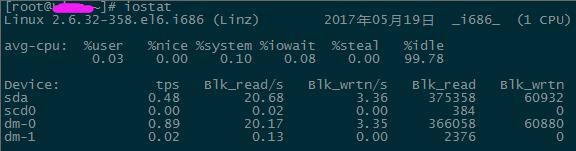
%usr:用户进程消耗的 CPU 时间百分比。
%nice: 运行正常进程消耗的 CPU 时间百分比。
%system:系统进程消耗的 CPU 时间百分比。
%iowait:I/O 等待所占 CPU 时间百分比。
%steal:在内存紧张环境下,pagein 强制对不同的页面进行的 steal 操作。
%idle:CPU 空闲状态的时间百分比。tps:每秒从物理磁盘 I/O 的次数.多个逻辑请求会被合并为一个 I/O 磁盘请求,一次传输的大小是不确定的。
Blk_read/s:每秒读取的数据块数。
Blk_wrtn/s :每秒写入的数据块数。
Blk_read:读取的所有块数。
Blk_wrtn :写入的所有块数。
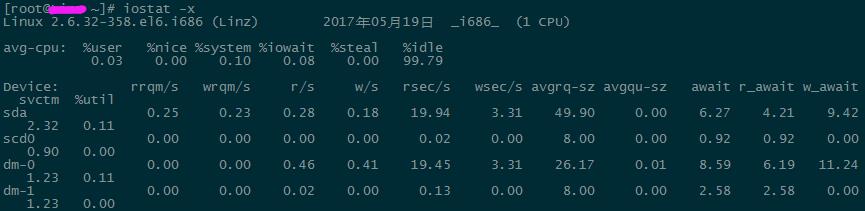
rrqm/s:每秒进行 磁盘的读操作数目,即 delta(rmerge)/s 。
wrqm/s:每秒进行 磁盘的写操作数目,即 delta(wmerge)/s 。
r/s:每秒完成的读 I/O 设备次数,即 delta(rio)/s 。
w/s: 每秒完成的写 I/O 设备次数,即 delta(wio)/s 。
rsec/s:每秒读扇区数,即 delta(rsect)/s。
wsec/s:每秒写扇区数,即 delta(wsect)/s
rkB/s:每秒读 K 字节数,是 rsect/s 的一半,因为每扇区大小为 512 字节。
wkB/s:每秒写 K 字节数,是 wsect/s 的一半
avgrq-sz:平均每次设备 I/O 操作的数据大小 (扇区),即delta(rsect+wsect)/delta(rio+wio) 。
avgqu-sz:平均 I/O 队列长度,即 delta(aveq)/s/1000 (因为 aveq 的单位为毫秒)。
Await:平均每次设备 I/O 操作的等待时间 (毫秒),即 delta(ruse+wuse)/delta(rio+wio) 。
Svctm:平均每次设备 I/O 操作的服务时间 (毫秒),即 delta(use)/delta(rio+wio) 。
%util:一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,即 delta(use)/s/1000 (因为 use 的单位为毫秒) 。
5、netstat
Netstat 命令用于显示本机网络连接、运行端口、路由表等信息

Iface:表示网络设备的接口名称。
MTU:表示最大传输单元,单位为字节。
RX-OK/TX-OK:表示已经准确无误地接收/发送了多少数据包。
RX-ERR/TX-ERR:表示接收/发送数据包时候产生了多少错误。
RX-DRP/TX-DRP:表示接收/发送数据包时候丢弃了多少数据包。
RX-OVR/TX-OVR:表示由于误差而丢失了多少数据包。
Flg 表示接口标记,其中
B 已经设置了一个广播地址。
L 该接口是一个回送设备。
M 接收所有数据包(混乱模式)。
N 避免跟踪。
O 在该接口上,禁用 AR P。
P 这是一个点到点链接。
R 接口正在运行。
U 接口处于“活动”状态。
其中 RX-ERR/TX-ERR、 RX-DRP/TX-DRP 和 RX-OVR/TX-OVR 的值应该都为 0,如果不为 0,并且很大,那么网络质量肯定有问题,网络传输性能也一代会下降。
6、strace
strace 常用来跟踪进程执行时的系统调用和所接收的信号。 Linux中进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace 可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
参数:
-p:跟踪指定的进程。
-f:跟踪由 fork 子进程系统调用。
-r:打印每一个系统调用的相对时间。
-c:统计每种系统调用所执行的时间,调用次数,出错次数。
7、lsof
lsof 命令的原始功能是列出打开的文件的进程,LINUX 下,所有的设备都是以文件的行式存在的,所以,lsof 的功能很强大。
-a :列出打开文件存在的进程
-c<进程名> :列出指定进程所打开的文件
-g :列出 GID 号进程详情
-d<文件号> :列出占用该文件号的进程
+d<目录> :列出目录下被打开的文件
+D<目录> :递归列出目录下被打开的文件
-n<目录> :列出使用 NFS 的文件
-i<条件> :列出符合条件的进程。
-p<进程号>: 列出指定进程号所打开的文件
-u 后面跟 username:列出该用户相关进程所打开文件
-U :仅列出系统 socket 文件类型
-h:显示帮助信息
-v:显示版本信息

ulimit -n 65535 → 修改打开文件句柄的数量
四、图形化监控工具nmon
nmon要严格对应操作系统内核的版本及位数
uname -a → 查看操作系统位数
下载对应版本的nmon:
执行,如下图:
出现了乱码,猜测应该是字体编码或者终端类型的问题,SecureCRT的默认一般是ANSI或者Linux
尝试把SecureCRT终端类型设为vt100,重新连接Session,再执行nmon命令:

nmon界面说明了基本的用法,分别按下c,m,d的效果:

nmon具有离线分析的功能,使用"./nmon_x86_centos6 -ft -s 1 -c 60"命令
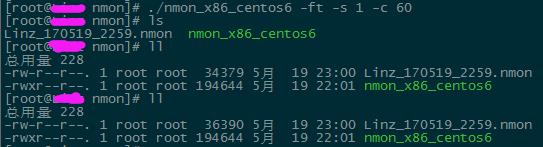
文件夹中多了一个以nmon结尾的文件,使用sz将该文件下载到windows环境下,使用nmon analyser v33g.xls打开,如下图:
无监控,不分析。
-------------------------------------------

以上是关于Linux监控分析的主要内容,如果未能解决你的问题,请参考以下文章