Facebook宕机背后,我们该如何及时发现DNS问题
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Facebook宕机背后,我们该如何及时发现DNS问题相关的知识,希望对你有一定的参考价值。
简介: 国庆期间,Facebook 及其旗下 Instagram 和 WhatsApp 等应用全网宕机,停机时间将近 7 小时 5 分钟,Facebook 市值损失 643 亿美元。针对Facebook的宕机问题,我们该如何未雨绸缪,看看云拨测如何帮助客户避免该类问题。
在我们享受国庆假期的时候,大洋对岸的互联网世界却出了一件重大“事故”:Facebook 及其旗下 Instagram 和 WhatsApp 等应用全网宕机,停机时间将近 7 小时 5 分钟,浏览器在尝试打开时显示 DNS 错误。这对于旗下应用群月活和日活高达 35.1 亿和 27.6 亿的 Facebook 而言,可谓损失惨重。据投资机构估计,7 小时宕机导致超过 9.68 亿美元影响成本。并直接让 Facebook 市值损失 643 亿美元,其创始人马克·扎克伯格净资产蒸发 70 亿美元。
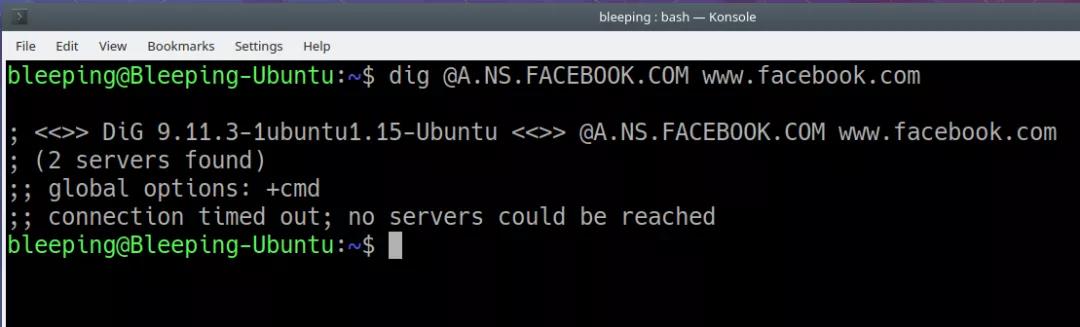
Facebook 表示,故障根本原因是例行维护工作出了问题,协调数据中心之间网络流量的骨干路由器配置变化,继而导致其 DNS 服务器发生问题并致使内部工具和系统被关闭,运维人员无法远程访问设备以便恢复网络。因此,运维人员不得不进入有着流程措施严格的数据中心进行人工重启。因此,MTTR 被严重拖长。
一句话总结,一条糟糕的命令、一款有缺陷的审核工具、一套阻碍成功恢复网络的 DNS 系统以及繁琐的数据中心流程,共同导致了 Facebook 长达 7 个小时的重大故障。
具体而言,运维人员对骨干网络的一部分进行断网维护。例行维护的一部分就是评估全球骨干网容量的可用性,但无意间中断开了骨干网络所有连接,也断开了 Facebook 全球数据中心的连接。与此同时, 由于 Facebook 的架构设计是根据服务器可用性来扩展或缩减 DNS 服务。当服务器可用性因网络故障而降至零时,就会停用所有 DNS 服务器。自动响应骨干网崩溃似乎成为导致 DNS 瘫痪的原因。这种停用通过 Facebook 的 DNS 名称服务器向互联网边界网关协议(BGP) 路由器发送消息来完成的,这些路由器存储用来抵达特定 IP 地址的路由方面的信息。这些路由通常被公告给路由器,让路由器了解如何适当地引导流量。
Facebook 的 DNS 服务器发送的 BGP 消息禁用了公告给路由,因此无法将流量解析成 Facebook 骨干网络上的任何对应内容。最终结果就是,即使 DNS 服务器仍在运行,也访问不了,用户也会因试图访问的网络崩溃而丢失服务。更不幸的是,DNS 服务用于面向客户的网站,还将其用于自己的内部工具和系统。
看到这里我们会发现,DNS 在这其中扮演着重要的角色,那么 DNS 又是什么?DNS 即Domain Name System 的缩写,域名系统以分布式数据库的形式将域名和IP地址相互映射。简单的说,DNS 是用来解析域名的,在正常环境下,用户的每一个上网请求会通过 DNS 解析指向到与之相匹配的IP地址,从而完成一次上网行为。DNS 作为应用层协议,主要是为其他应用层协议工作的,包括不限于 HTTP 和 SMTP 以及 FTP,用于将用户提供的主机名解析为 IP 地址,具体过程如下:
(1)用户主机(PC 端或手机端)上运行着 DNS 的客户端;
(2)浏览器将接收到的 URL 中抽取出域名字段,就是访问的主机名,比如阿里云-上云就上阿里云 , 并将这个主机名传送给 DNS 应用的客户端;
(3)DNS 客户机端向 DNS 服务器端发送一份查询报文,报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式 DNS 集群的工作);
(4)该 DNS 客户机最终会收到一份回答报文,其中包含有该主机名对应的IP地址;
(5)一旦该浏览器收到来自 DNS 的 IP 地址,就可以向该 IP 地址定位的 HTTP 服务器发起 TCP 连接。
Facebook 此次宕机持续近 7 小时影响了约 8500 万用户,是自 2008 年以来最严重的一次。作为旁观者回顾这次故障,我们会发现一个非常关键的问题点:但据了解,当日不断有用户反映,Facebook 旗下 Facebook、移动聊天服务 Messenger 和 WhatsApp、图片社交服务 Instagram 等四大社交平台网站和应用均发生响应服务器错误,导致无法刷新。Facebook 在欧洲、美洲、大洋洲几乎完全下线,在亚洲的日本、韩国、印度等国也无法访问,影响到全球数十个国家和地区用户。似乎 Facebook 似乎并没有在第一时间发现这些问题。只在全球多个国家和地区用户进行反馈后才发现了问题。
即使是庞大如 Facebook 这样的企业,也没有在第一时间发现 DNS 故障,并遭受严重的经济损失。设身处地的面对这样故障,我们该如何第一时间发现并监控产品以及 DNS 的运行状况?并且及时了解全球不同国家和地区的用户使用情况?
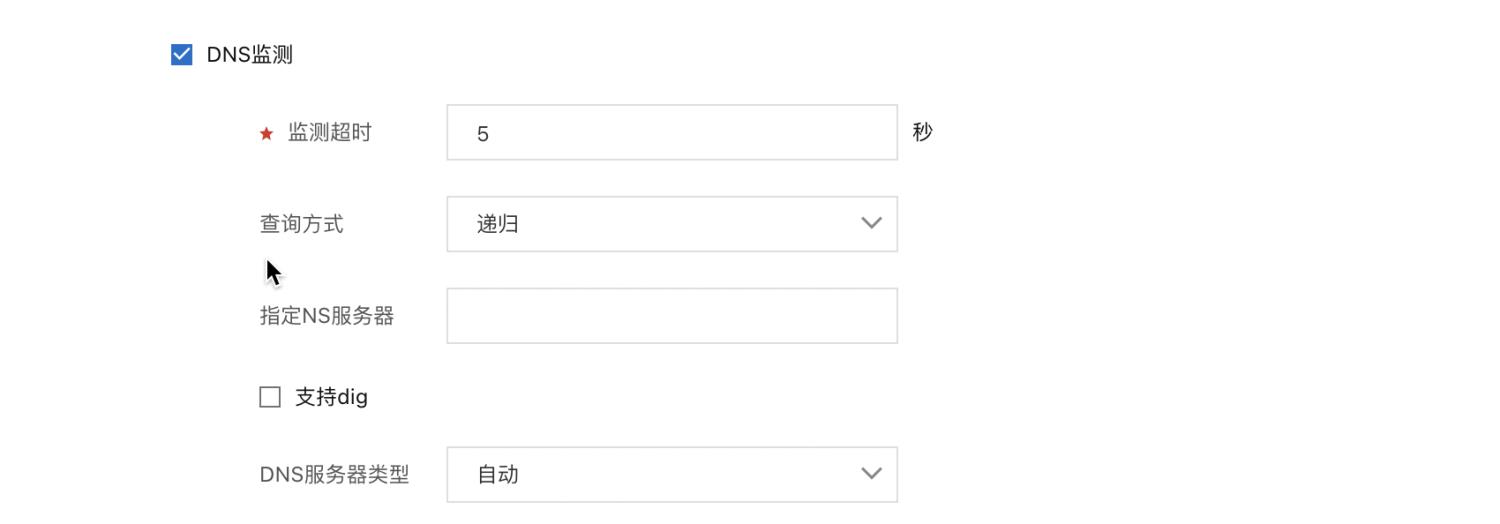
纵观各类 APM 产品,无侵入的云拨测成为最佳的解决方案。阿里云拨测通过遍布全球的 1000+ 监测点,包括真实用户监测,全天候 24 小时对目标域名发起网络请求,帮助用户监测 DNS 服务对可用性和解析性能,同时 DNS 拨测支持指定递归、迭代不同查询方式以及解析服务器,通过灵活的拨测参数配置尽可能模拟真实用户的访问。
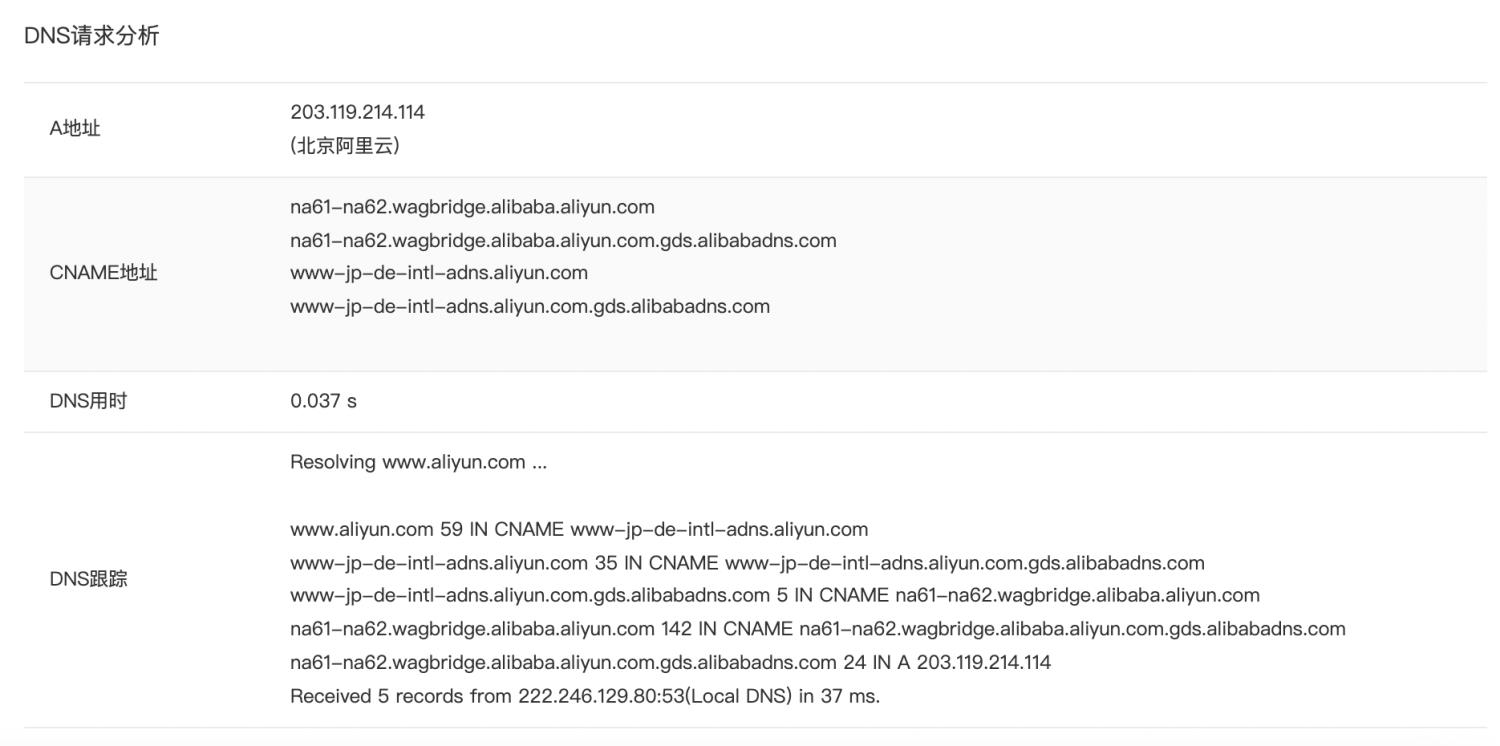
经过定时的拨测任务,阿里云拨测可以生成不同地区的 DNS 解析用时的报表,同时针对每次拨测都清晰的列出 DNS 请求对详情,包括 A 地址、DNS 用时、DNS 解析过程等,能给帮助用户快速分析和定位 DNS 解析的问题。
另外通过配置 DNS 告警,针对于 DNS 的可用性问题和解析性能问题,也可以先于用户感知并问问题的修复争取时间,提高用户的满意度,降低经济损失。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于Facebook宕机背后,我们该如何及时发现DNS问题的主要内容,如果未能解决你的问题,请参考以下文章