解读:为什么C语言没有重载?
Posted 白龙码~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读:为什么C语言没有重载?相关的知识,希望对你有一定的参考价值。
在了解这部分之前,我们需要回顾一下编译链接部分的知识,具体可参考这篇博客:程序的编译与链接
接下来我带大家简单回顾一下与我们这部分相关的知识——
首先,工程的每一个源文件都是单独编译的,而编译阶段会有一个步骤:形成符号表。
假如,test.c文件中有这样的内容:
#include <add.h>
int main()
{
int ret = add(1,2);
return 0;
}
add函数是定义在其他源文件中的,而add.h中包含了这个函数的声明,也就是:int add(int a, int b);由于我们包含了这个头文件,因此这个头文件中的内容就会在预编译阶段展开,于是这个程序就变成了这样:
int add(int a, int b);
int main()
{
int ret = add(1,2);
return 0;
}
那么这个源文件形成的符号表就可能是这样的:
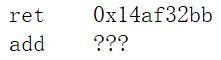
第一列对应的是符号的内容,而第二列对应的是符号的地址。
比如这里,ret的地址是0x14af32bb,但是add函数的地址未知,为什么呢?因为在这个文件中,我们仅仅有add函数的声明,没有它的定义。
声明的作用仅仅是告诉编译器:add函数是的确存在的,只是没在这个源文件中实现。因此,能够使编译通过,但是它无法告诉编译器add函数的地址是多少。
寻址的步骤是在链接阶段。
链接时,编译器将所有源文件的符号表进行合并,那么此时,test.c这个源文件中符号表的???就可以填补上了。

那么我们这里注意到一个问题:C语言的编译器对于符号的修饰规则很简单,函数名是啥,那么它对应的符号就是啥。
于是乎,函数重载对于C语言就可望不可即了。为什么呢?
我们设想一下,在add.c中有两个函数:
int add(int a, int b)
{
return a + b;
}
double add(double a, double b)
{
return a + b;
}
那么在编译初步形成符号表的时候就会有一个问题:这里有两个重名的符号,但是对应了两个不同的地址,哪个地址是对的呢?这时候编译器就蒙了。
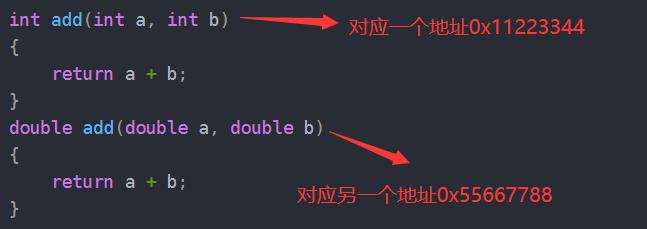
那么姑且我们认定,一个符号表可以出现两个相同的符号,那么就会是这样:
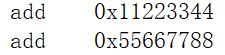
那么在链接时又会有问题:add.c有两个add,可链接器无法区分哪个才是使用者真正需要的,它懵了。

所以,对于C语言,函数重载的实现太难了。那C++又是如何解决这个问题的呢?
很简单,有问题那就解决问题。你不是说两个函数形成的符号时一样的吗,那就修改C++的符号修饰规则,函数的符号不再与函数名相同,而是采取这样的方式(仅作了解即可):
_Z + 函数名长度 + 函数名 + 参数类型的缩写(linux下的修饰规则)
比如,int add(int a, int b)就变成了_Z3addii
ps:windows下对于C++符号的修饰规则更加复杂,这里不再赘述。
我们继续说。
既然函数的修饰规则变了,那么尽管它们是同名函数,但是由于参数的个数、类型、顺序不同,就导致它们形成的符号有所差异,所以在链接的时候链接器就能够很容易的锁定目标。
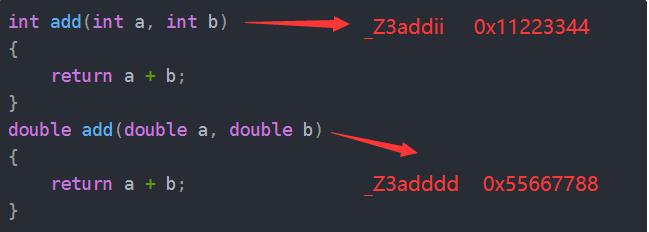

看到这里想必大家应该理解为什么C++可以支持重载了吧。
那么这里再继续补充解释重载的必要条件:
- 为什么参数顺序不同但是必须类型也不同才构成重载。
因为对于int add(int a, int b)和int add(int b, int a),它们的符号都是_Z3addii - 为什么仅有返回值类型不同不能构成重载
因为C++的符号修饰规则与返回值类型无关,它只考虑了函数名、函数名长度、参数类型以及参数顺序。
可是为什么C++没有考虑到根据返回值类型不同构成重载呢?
很简单的一个例子:
int func();
bool func();
或许编译器可以根据接收返回值的变量类型判断调用的是哪一个函数
int main()
{
int a = func();
bool b = func();
return 0;
}
但是肯定也会有这种情况:
int main()
{
func();
return 0;
}
此时编译器根本就不能判断应该调用哪个重载了。
你,明白了吗??
以上是关于解读:为什么C语言没有重载?的主要内容,如果未能解决你的问题,请参考以下文章