PostgreSQL——查询分析
Posted weixin_47373497
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL——查询分析相关的知识,希望对你有一定的参考价值。
2021SC@SDUSC
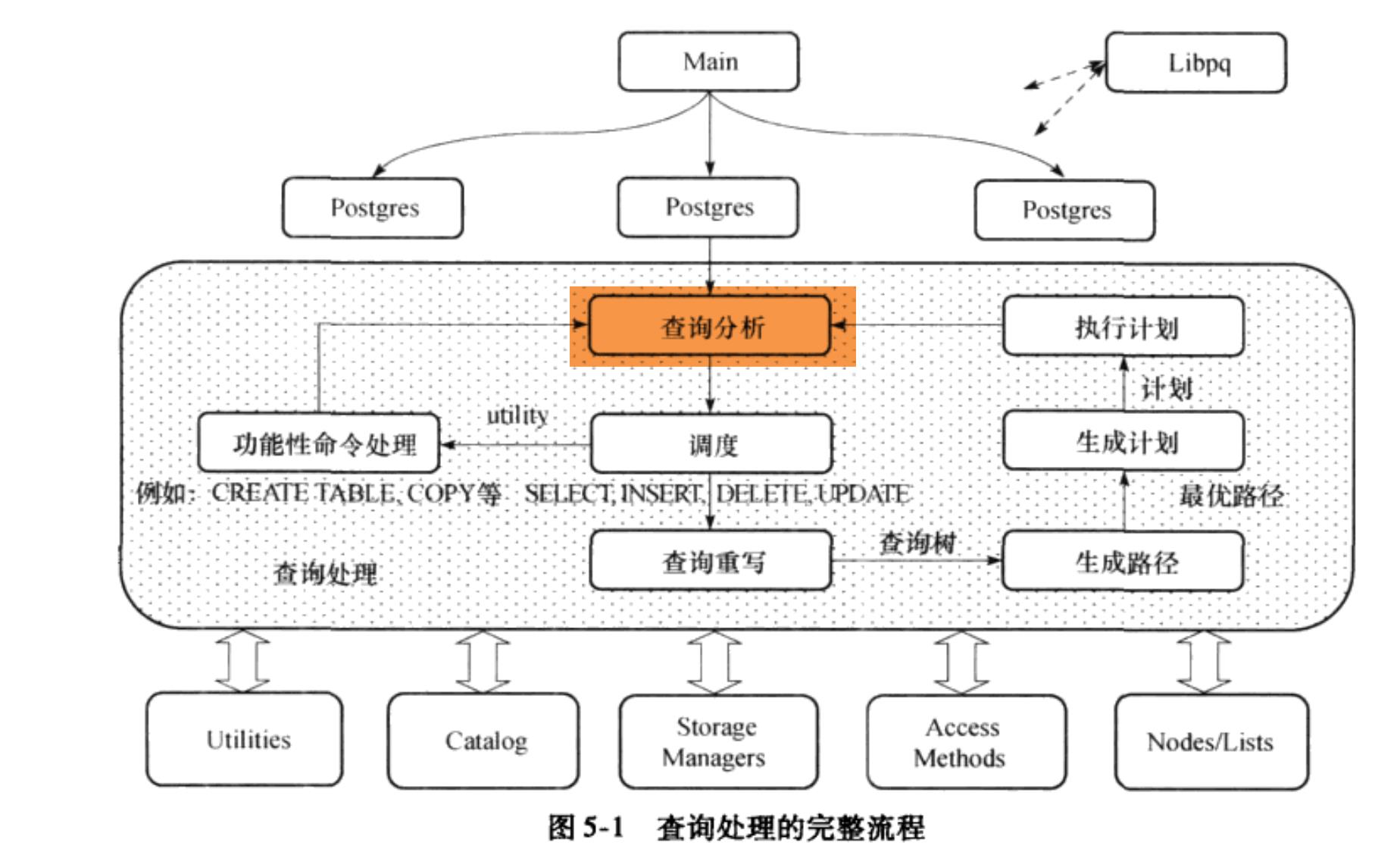
我负责的PostgreSQL代码部分:查询的编译与执行
此篇博客的分析内容:查询分析源码
原因:由查询处理的完整流程图可知:查询分析是处于核心地位的,统领查询重写和调度等相关内容,所以我按照一个清晰的框架,首先从查询分析入手。
查询分析
功能:由SQL查询语句生成查询树
源码路径:src/backend/parser
主要部分:词法分析,语法分析,语义分析
重要源码文件及调用关系:
kwlist.h:SQL关键字定义,注意:关键字名要小写,按照字符串值顺序定义
kwlookup.h:定义结构体ScanKeyword;
kwlookup.c:使用kwlist.h初始化关键字数组ScanKeywords,提供ScanKeywordLookup函数,该函数判断输入的字符串是否是关键字,若是则返回当前标识符指向关键字列表中对应单词的指针,采用二分法查找;
scanup.c:提供几个词法分析时常用的函数。scanstr函数处理转义字符,downcase_truncate_identifier函数将大写英文字符转换为小写字符,truncate_identifier函数截断超过最大标识符长度的标识符,scanner_isspace函数判断输入字符是否为空白字符。
scan.l:定义词法结构,编译生成scan.c;这里会忽略comment等无用信息。
gram.y:定义语法结构,编译生成gram.c;分析后生成语法分析树。
gram.h:定义关键字的数值编号。
辅助脚本:
check_keywords.pl:检查在gram.y 和 kwlist.h 中定义的关键字列表是否一致。
查询分析执行流程:
词法分析和语法分析
词法分析和语法分析主要源文件:parser.c
parser流程:
Postgre命令的词法分析和语法分析是由Unix 工具yacc和lex制作的。它们依赖的文件定义在
src\\backend\\parser下的scan.I和gram.y.词法器在文件scan.I 里定义,负责识别标识符,SQL关
键字等。对于发现的每个关键字或者标识符都会生成一一个记号并且传递给分析器。
分析器在文件gram.y里定义并且包含–套语法规则和触发规则时执行的动作。
核对语法并创建一棵查 询树( 由ParseNode构成)。在分析阶段如果发现语法错误,如输入的命令中
有SQL中不存在的关键字,或者不符合已定义的语法规则。就会返回客户端错误信息并不再执行之后的流,
程。注意在这一阶段是没有事务保护处理。因为这是中间过程,并不会对数据本身产生不良影响。
在分析器完成之后,由parse_ analyze 函数进行进一步处理,又称为转换处理,该阶段接受分析器
传过来的分析树然后做进一步处理,解析那些理解查询中引用了哪个表,哪个函数以及哪个操作符的语意。
所生成的表示这个信息的数据结构叫做查询树。有关字段和表达式结果的具体数据类型也添加到查询树中。
词法分析工具:Lex(利用正则表达式识别模式)
用来生成扫描器,它的功能是识别一个一个的模式,例如数字,字符串,特殊符号等
语法分析工具:Yacc
用来生成语法分析器,从给定的模式中寻找语法结构
parser入口函数分析
raw_parser(const char *str)//入口函数,返回List结构,用于存储生成的分析树
{
core_yyscan_t yyscanner;
base_yy_extra_type yyextra;
int yyresult;
//初始化flex扫描器
yyscanner = scanner_init(str, &yyextra.core_yy_extra, &ScanKeywords, ScanKeywordTokens);
//str用户的输入;&yyextra.core_yy_extra是base_yy_extra_type结构体变量里的一个变量;ScanKeywords是存储所有关键词的一个列表;
//ScanKeywordTokens是uint16类型const uint16 ScanKeywordTokens[] 存储的是来自parser/kwlist.h里面的关键字
/* base_yylex() only needs this much initialization */
yyextra.have_lookahead = false;
// 初始化 bison parser
parser_init(&yyextra);
//实现语法分析,并返回语法分析树
yyresult = base_yyparse(yyscanner);
//释放内存
scanner_finish(yyscanner);
if (yyresult)
return NIL;
return yyextra.parsetree;
}
raw_parser函数相关数据结构
core_yyscan_t数据结构:
typedef struct core_yy_extra_type
{
char *scanbuf;
// scanner实际扫描的字符串,这个可以低代价计算出当前标记的偏移量(yytext)
Size scanbuflen;
const ScanKeywordList *keywordlist;
// 要使用的关键词列表,以及相关的语法标记代码。
const uint16 *keyword_tokens;
int backslash_quote;
bool escape_string_warning;
bool standard_conforming_strings;
char *literalbuf; /* palloc'd expandable buffer */
int literallen;
//记录实际的字符串长度
int literalalloc;
//当前字符串大小
int xcdepth;
char *dolqstart;
int32 utf16_first_part;
bool warn_on_first_escape;
bool saw_non_ascii;
} core_yy_extra_type;
base_yy_extra_type数据结构:
typedef struct base_yy_extra_type
{
core_yy_extra_type core_yy_extra;
//base_yylex()的状态变量
bool have_lookahead;
//判断读写前面的信息是否正确
//token相关变量
int lookahead_token;
core_YYSTYPE lookahead_yylval;
YYLTYPE lookahead_yylloc;
char *lookahead_end;
char lookahead_hold_char;
//属于语法的状态变量
List *parsetree; /* final parse result is delivered here */
} base_yy_extra_type;
scan.l规则段
{identifier} {
const ScanKeyword *keyword;
char *ident;
SET_YYLLOC();
/* 在关键字列表yyextra->keywords中查找匹配的字符串是否为关键字
* ScanKeywordLookup函数被声明在keywords.h中keywords.h被包含在scanner.h中
* scanner.h被包含在gramparse.h中,gramparse.h被scan.l引用
*/
/* 变量yyextra->keywords是我们传入的kwlist.h中的所有关键字. */
keyword = ScanKeywordLookup(yytext,yyextra->keywords,yyextra->num_keywords);
if (keyword != NULL)//如果找到 在kwlist.h中存在PG_KEYWORD("delete", DELETE_P, UNRESERVED_KEYWORD)
{
yylval->keyword = keyword->name;//token 对应的值这里为 “delete”
return keyword->value;//返回token, 这里为宏“DELETE_P”
}
/*
* No. Convert the identifier to lower case, and truncate
* if necessary.
*/
ident = downcase_truncate_identifier(yytext, yyleng, true);
yylval->str = ident;
return IDENT;
}
进行语法分析和词法分析后生成以selectstmt为根的查询。形如:
select opt-distinct,targetlist,into-clause,from-clause,where-clause,group-clause,having-clause
SelectStmt结构体
typedef struct SelectStmt
{
NodeTag type;
//节点类型,用于标识节点的内容,在SelectStmt中会取值为T_SelectStmt
//以下属性只作为SelectStmt的叶子结点
List *distinctClause;
//distinct字句
IntoClause *intoClause;
//select into/create table as字句
List *fromClause;
//from 子句
Node *whereClause;
//where子句
List *groupClause;
//group by字句
Node *havingClause;
//having 字句
List *windowClause;
//窗口字句
List *valuesLists;
//Values 列表,产生常量表,常量表可以作为虚拟表出现在from中
List *sortClause;
//order by 字句
Node *limitOffset;
//offset 字句
Node *limitCount;
//limit 字句
List *lockingClause;
//for update字句
WithClause *withClause;
SetOperation op;
//查询语句的集合操作,交/并/差
bool all;
//在集合操作时是否指定了ALL关键字
struct SelectStmt *larg;
//左孩子节点
struct SelectStmt *rarg;
//右孩子节点
} SelectStmt;
总结
通过源码分析,大致了解了PostgreSQL查询解析的流程以及lex和yacc,flex,bison的基本功能。
感谢批评指正
以上是关于PostgreSQL——查询分析的主要内容,如果未能解决你的问题,请参考以下文章