再探多线程
Posted 神佑我调参侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了再探多线程相关的知识,希望对你有一定的参考价值。
自己的见解
- 其实多线程并不是说几个任务一起执行,而是将一个cpu分割成几个时间片,然后几个线程去抢这些时间片,是没有顺序的
- 而且进程对应一个地址存储空间,而线程是多个线程对应这一个地址空间,但是对应的这个地址空间的信息,如代码,文件等都是共享的。进程包含线程。
线程函数
首先在使用这个多线程时,要先导入一个库
#include <pthread.h>
每个线程都是有自己的一个线程ID,类型为:pthread_t
创建线程
在创建线程的时候要指定一个处理函数,否则这个线程不能工作!
#include <pthread.h>
int pthread_create(pthread_t *thread, NULL ,void *(*start_routine)(void *), void *arg);
- 线程ID
- 线程属性,写NULL
- 回调函数
- 函数的实参
看一下这个回调函数,类型是void * ,参数也是 void*。
下面看个例子:
#include<pthread.h>
#include<string.h>
#include<iostream>
using namespace std;
void* callback(void* arg)
{
for (int i=0;i<5;i++)
{
cout<<"子线程:i = "<<i<<endl;
}
cout<<"子线程:ID: "<<pthread_self()<<endl;
}
int main()
{
pthread_t tid;
pthread_create(&tid,NULL,callback,NULL);
for(int i=0;i<5;i++)
{
cout<<"主线程:i = "<<i<<endl;
}
cout<<"子线程:ID: "<<pthread_self()<<endl;
return 0;
}
下面是结果:

可以看到阿,主线程是都执行完成了,但是子线程并没有都执行完毕。而是每次运行的结果都不一样,这更说明是时间片靠抢的,但是每次都是主线程抢占先机,并且抢完后就终止了。
这时可以加一个sleep函数就可以解决(ง •̀_•́)ง
线程退出
这个api其实主要是对于主线程的,因为如果是子线程退出的话,主线程并不影响,而主线程用这个函数后,会先退出,但不会干扰其他的子线程。下面说说这个函数:
void pthread_exit(void *retval);
下面我们接着上面那个函数继续书写。
int main()
{
pthread_t tid;
pthread_create(&tid,NULL,callback,NULL);
cout<<"主线程:ID: "<<pthread_self()<<endl;
pthread_exit(NULL);
return 0;
}
如果在主线程退出后,子线程依旧运行完毕,那么我们的实验就成功了。下图说明成功了。

线程回收
作用就是:主线程回收子线程资源,但是这里面不是说全部资源,子线程的用户区的部分自动释放的,然后被其他线程接受,而内核区的部分是由主线程来回收的。
#include<pthread.h>
pthread_join(pthread_t thread,void **retval)
- 这个函数在一定程度上是一个堵塞函数,因为要回收子线程的资源,所以是肯定要等待子线程结束的,如果子线程没有结束,那么就会一直等待!同时这个函数只会对应一个子线程。
- 然后这里面还有一个细节:就是子线程运行结束的时候,其他子线程是不会接受到数据的,运行期间那就更不能传了(多线程不是一起执行),想要接收到就要做一些处理,应用pthread-exit()这个函数,这个函数如果参数是子线程的地址就是有一个返回值的,返回的是一个地址,这个函数里面对应的第二个参数就是这个地址。如果没有参数或者参数是NULL的话,那么一般是在主线程中应用
- 最后总结一下以上两个函数的关系即退出与堵塞,首先明白传递数据是要将这个子线程退出,然后将这个数据传出来,传出来的是地址,堵塞完毕后返回的地址,也就是说堵塞的函数的参数是二级地址。
下面看一个例子:
#include<pthread.h>
#include<string.h>
#include<iostream>
using namespace std;
struct Test
{
int num;
int age;
};
Test t;
void* callback(void* arg)
{
for (int i=0;i<5;i++)
{
cout<<"子线程:i = "<<i<<endl;
}
cout<<"子线程:ID: "<<pthread_self()<<endl;
t.num = 100;
t.age = 6;
pthread_exit(&t);
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid,NULL,callback,NULL);
cout<<"主线程:ID: "<<pthread_self()<<endl;
//pthread_exit(NULL);
void* ptr;
pthread_join(tid,&ptr);
struct Test* pt = (struct Test*)ptr;
cout<<"num= "<<pt->num<<"age= "<<pt->age<<endl;
return 0;
}
简单说下这个函数:从主函数看起:先定义一个线程ID,然后创建线程,然后定义一个无类型指针ptr(虽然什么都可以接收,但是用的时候要强转),这时堵塞会等待子线程结束,子线程结束会返回一个结构体的地址,然后我们这里用ptr接收,

线程分离
这个很好理解,就是互不影响,但是感觉没什么用,最后还是得加一个exit的函数!
线程同步
这个就是我们真正能用到的了,就是防止多个子线程同时访问一个数据时起作用的。比如说上洗手间,两个人同时去的洗手间,但就一个洗手间嘛,这时就得一个个来嘛。
互斥锁
这里先说一下互斥锁的技术,通俗的讲就是,这个洗手间有一把锁,那么相对应的有一把钥匙,如果一个人去了洗手间,他把锁给锁上了,钥匙也同时在他手里,那么外面的人就得等它结束后,它用钥匙打开锁,然后外面的人才能进去,然后第二个人也可以上锁,并且由他自己解锁,这让同时访问就变成了有顺序的执行了。
下面看一个例子:
#include<iostream>
#include<pthread.h>
#include<string.h>
#include<unistd.h>
using namespace std;
#define MAX 50
int number;
pthread_mutex_t mutex;
void* func1(void *)
{
for (int i=0;i<MAX;i++){
pthread_mutex_lock(&mutex);
int cur = number;
cur++;
usleep(10);
number = cur;
cout<<"Thread A: ID="<<pthread_self()<<" number="<<number<<endl;
pthread_mutex_unlock(&mutex);
}
return NULL;
}
void* func2(void *)
{
for (int i=0;i<MAX;i++){
pthread_mutex_lock(&mutex);
int cur = number;
cur++;
number = cur;
cout<<"Thread B: ID="<<pthread_self()<<" number="<<number<<endl;
pthread_mutex_unlock(&mutex);
usleep(5);
}
return NULL;
}
int main(){
pthread_t p1,p2;
pthread_mutex_init(&mutex,NULL);
pthread_create(&p1,NULL,func1,NULL);
pthread_create(&p2,NULL,func2,NULL);
pthread_join(p1,NULL);
pthread_join(p2,NULL);
pthread_mutex_destroy(&mutex);
return 0;
}
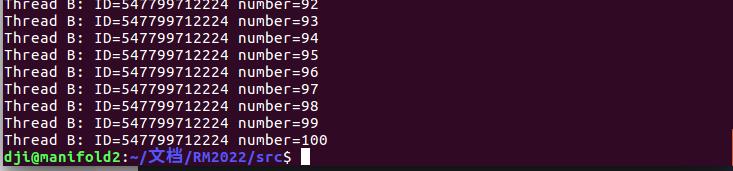
可以看到是A线程先执行完,然后在B线程在执行的,然后说一下这里面的一些函数及其用法:
- 首先要先定义这把锁,要在全局变量中定义
pthread_mutex_t mutex - 然后就是上锁,这里面需要注意的就是要找到那个共同应用的东西,这里的是number,然后在number的上下分别上锁和开锁
pthread_mutex_lock(&mutex) XXXX pthread_mutex_unlock(&mutex) - 最后就是初始化这个锁,并且在最后释放这个锁,这个初始化一定要在子线程使用的前面,并且释放要在最后面
pthread_mutex_init(&mutex,NULL); pthread_mutex_destory(&mutex);
读写锁
其实读写锁本质上和互斥锁差不多的,也是一把锁,但是这把锁有两个形态而已,其实理解了上面那个,这个也应该很好理解,我们直接上案例:
#include<iostream>
#include<pthread.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
using namespace std;
#define MAX 50
int number;
pthread_rwlock_t rwlock;
void* func1(void *)
{
for (int i=0;i<MAX;i++){
pthread_rwlock_rdlock(&rwlock);
cout<<"Thread read: ID="<<pthread_self()<<" number="<<number<<endl;
pthread_rwlock_unlock(&rwlock);
usleep(rand()%5);
}
return NULL;
}
void* func2(void *)
{
for (int i=0;i<MAX;i++){
pthread_rwlock_wrlock(&rwlock);
int cur = number;
cur++;
number = cur;
cout<<"Thread B: ID="<<pthread_self()<<" number="<<number<<endl;
pthread_rwlock_unlock(&rwlock);
}
return NULL;
}
int main(){
pthread_t p1[5],p2[3];
pthread_rwlock_init(&rwlock,NULL);
for (int i=0;i<5;i++){
pthread_create(&p1[i],NULL,func1,NULL);
}
for (int i=0;i<3;i++){
pthread_create(&p2[i],NULL,func2,NULL);
}
for (int i=0;i<5;i++){
pthread_join(p1[i],NULL);
}
for (int i=0;i<3;i++){
pthread_join(p2[i],NULL);
}
pthread_rwlock_destroy(&rwlock);
return 0;
}
条件变量(生产者,消费者模型)
条件变量与互斥锁联合使用
#include<iostream>
#include<pthread.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
using namespace std;
pthread_cond_t cond;
pthread_mutex_t mutex;
struct Node
{
int number;
struct Node* next;
};
Node* head = NULL;
void* producer(void *)
{
while(1){
pthread_mutex_lock(&mutex);
Node* new_node = (struct Node*) malloc(sizeof(struct Node));
new_node->number = rand()%1000;
new_node->next = head;
head = new_node;
cout<<"生产者id:"<<pthread_self()<<"number: "<<new_node->number<<endl;;
pthread_mutex_unlock(&mutex);
pthread_cond_broadcast(&cond);
sleep(rand()%3);
}
return NULL;
}
void* consumer(void *)
{
while(1)
{
pthread_mutex_lock(&mutex);
while(head == NULL){
pthread_cond_wait(&cond,&mutex);
}
struct Node* node = head;
cout<<"消费者id:"<<pthread_self()<<"number: "<<node->number<<endl;
head = head->next;
free(node);
pthread_mutex_unlock(&mutex);
sleep(rand()%3);
}
return NULL;
}
int main(){
pthread_mutex_init(&mutex,NULL);
pthread_cond_init(&cond,NULL);
pthread_t t1[5],t2[5];
for(int i=0;i<5;i++){
pthread_create(&t1[i],NULL,producer,NULL);
}
for(int i=0;i<5;i++){
pthread_create(&t2[i],NULL,consumer,NULL);
}
for(int i=0;i<5;i++){
pthread_join(t1[i],NULL);
}
for(int i=0;i<5;i++){
pthread_join(t2[i],NULL);
}
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
return 0;
}
这个例子非常好,把这个搞懂了的话就可以应用了,这里面应用到了一个核心的东西就是生产消费者模型,然后这也是我首次接触到数据结构的应用,说实在的大现在我还是不太懂链表的应用,其实我概念还是很理解的,但是如何应用就是另一件事了,而像一些条件变量的应用我说实在的并不难的,因为这个和我当时的想法就差不多,但是没有加数据结构嘛,这里先说一下链表操作的那个地方:
先创建一个节点的结构体,然后定义一个头的地址为NULL;然后使用时先开辟一个节点的空间,然后写入数据,这里注意一下,有个操作是交换地址,这个操作可能是最难理解的,先是该节点链接的节点地址指向链表头的地址,然后将该节点的地址给到head,之后在新建一个节点~~~~
后面的内容等我用到在更新,现在学得足够我看懂相机文件的代码了。
以上是关于再探多线程的主要内容,如果未能解决你的问题,请参考以下文章