C++学习:2类和对象
Posted 想文艺一点的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++学习:2类和对象相关的知识,希望对你有一定的参考价值。
目录
回顾一下面向对象的知识点:
- 类、对象
- 成员变量、成员函数
- 封装、继承、多态
自己的编程习惯:
- 全局变量: g_xxx
- 成员变量:m_xxx
- 静态变量: s_xxx
- 常量: c_xxx
一、面向对象
1、类和对象
类:相当于一个数据类型的定义
对象:相当于一个数据结构的实例化
在CPP 当中可以使用struct、 class来定义一个类,区别只是:默认权限不同
- struct 的默认成员权限是 public (外界都可以访问)
- class 的默认成员权限是 private (只有类内成员函数可以访问)

注意:实际开发中,用class表示类比较多,保留 struct 可能是为了让 C 程序员好过渡
2、对象内存

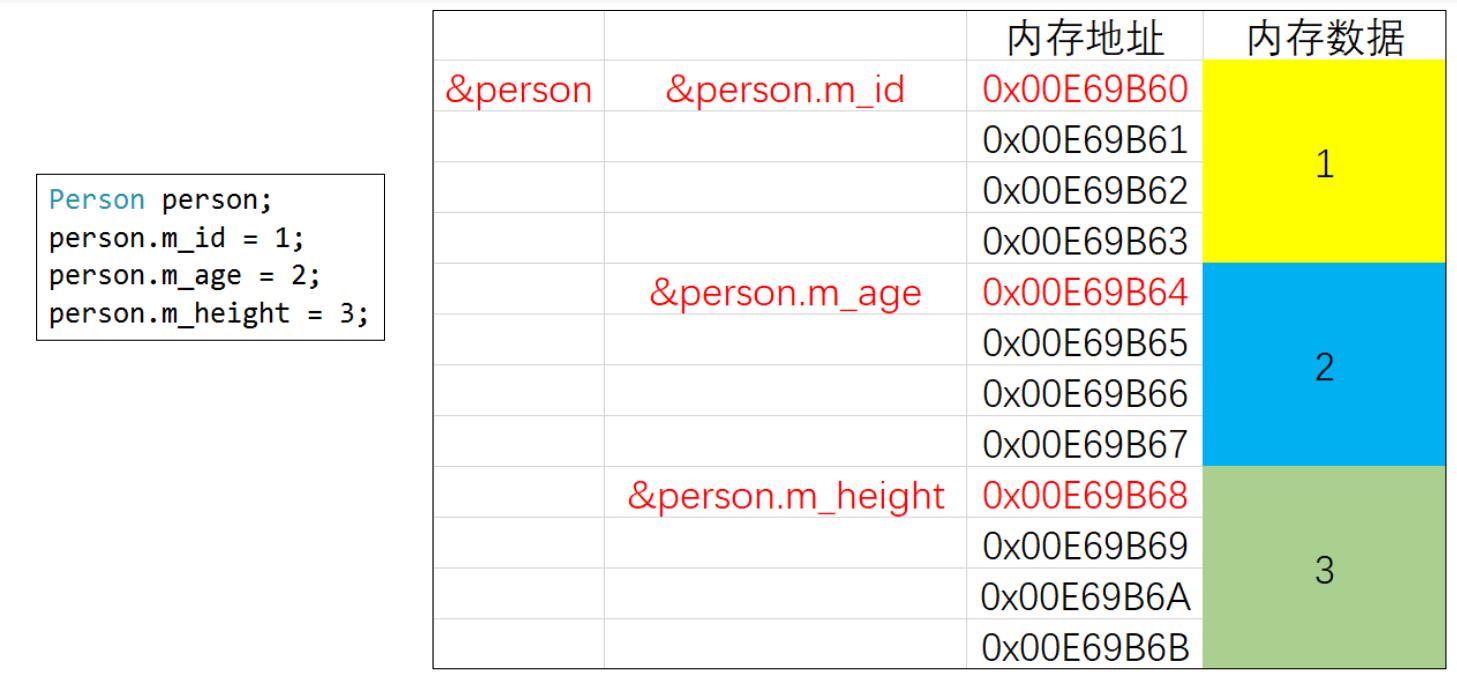
分析:看起来我们的成员函数也写在 class 当中,为什么不占用对象的内存呢?
- 每个对象都有自己的独立空间,都有属于自己的成员变量。(都有自己独特的属性,属性即成员变量)
- 因为每个对象的成员函数都一样,没有必要搞很多份,共用一份就可以。(共用一份方法)
问题:怎么知道使用成员函数的时候,成员函数要访问成员变量,怎么知道它访问的是哪一个成员变量?
答:通过 this 指针
对象的内存可以存在于 3 个地方
- 全局区(数据段):全局变量
- 栈空间:函数里面的局部变量
- 堆空间:动态申请内存(malloc、 new等)

3、this
发明的目的:成员函数只有一份,怎么做到成员函数当中的成员变量不同。
解决问题:哪个对象调用成员函数,那么就把这个对象的地址保存下来,通过这个地址就可以找到这个对象的属性。

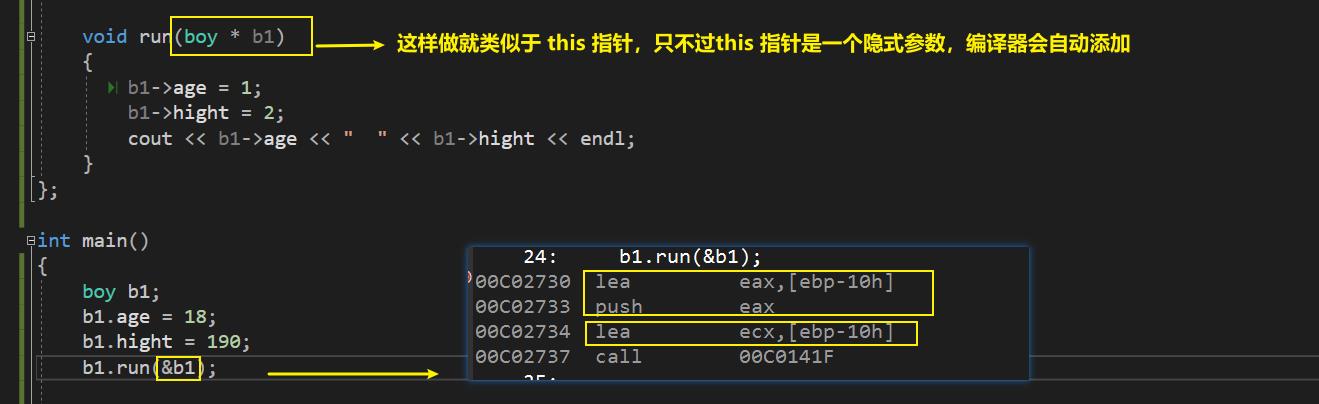
通过指针的方式来调用成员函数(传入的是 p 的值)
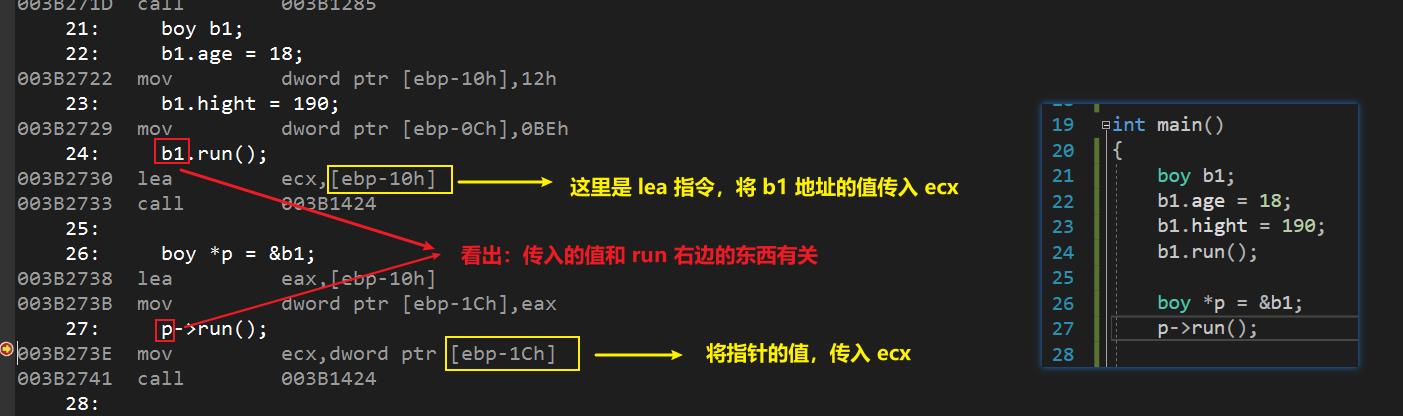
疑问:如果我们将 p 的值更改,那么通过指针访问的 this 的值是不是也会更改?
验证: p的值 == this 的值??

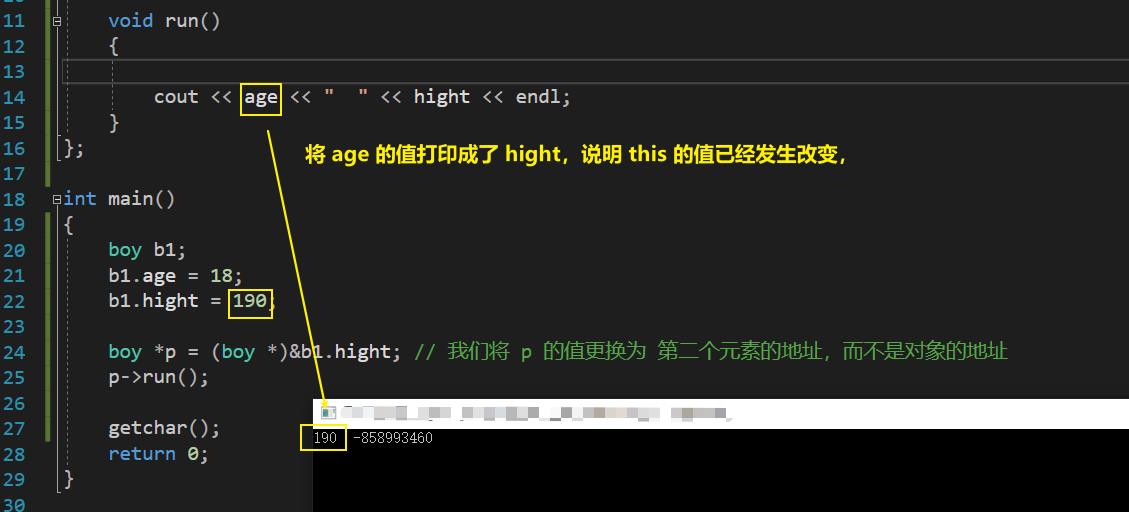
结论:p的值 == this 的值
注意:-858993460 其实是 0xcc, 二进制的 0xcc 其实一个中断向量。
因为栈空间是每次都要使用的,所以肯定是脏的,系统每次都会自动填充 0xcc,意义是断点,让 cpu 停下来,不要瞎运行。
4、封装
定义:
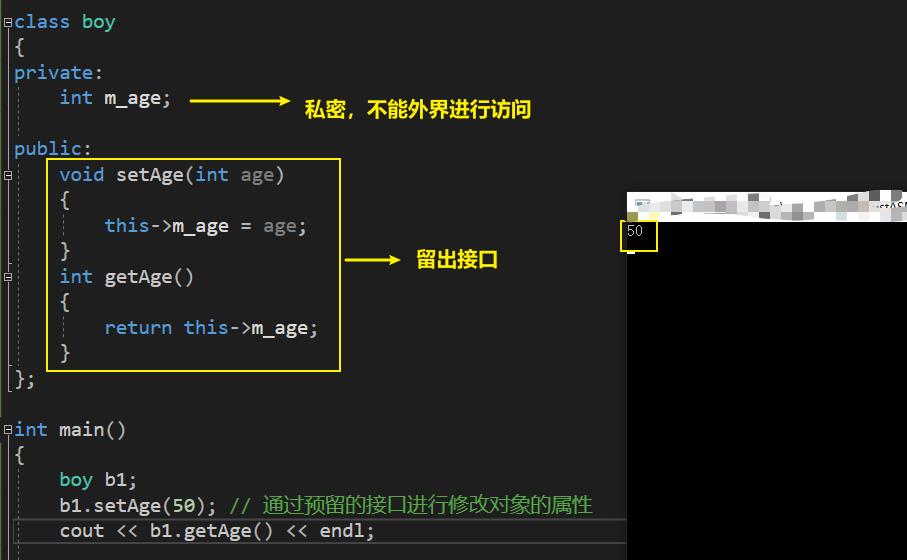
- 即隐藏对象的属性和实现细节,仅对外公开接口,控制在程序中属性的读和修改的访问级别;
- 将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员。
我的理解:
-
private属性 :隐藏了类内的属性,不能让外界函数进行调用。 (对于 C 语言来说就没有这样的特性)
-
成员变量私有化,提供公共的getter和setter给外界去访问成员变量
二、内存空间
1、内存空间
栈空间(.stack)
-
每调用一个函数就会给它分配一段连续的栈空间,等函数调用完毕后会自动回收这段栈空间
-
自动分配和回收
堆空间(.heap)
- 需要主动去申请和释放
代码段(.text)
- 用于存放代码
数据段(.data)
- 数据段(全局区):整个程序运行当中都存在的东西
2、堆内存
目的:在程序运行过程,为了能够自由控制内存的生命周期、大小,会经常使用堆空间的内存
分析:如果没有堆空间那会发生什么?
(1)假设开发植物大战僵尸,所有僵尸对象、 植物对象、子弹对象等等全部放到全局区,会发生什么?
- 这些对象将无法回收,这些对象将会永远放在内存当中。
(2)假设开发植物大战僵尸,所有僵尸对象、 植物对象、子弹对象等等全部放到栈区,会发生什么?
- 如果放在函数里面,函数退出即僵尸死亡。
- 而实际是 当僵尸的血量(属性)没有之后才死亡。
堆空间的申请和释放:
- malloc \\ free :是一个函数,C 语言当中也可以使用。 (返回申请的首字节地址)
- new \\ delete :是一个函数,C++ 当中才可以使用。(new \\ delete 比 malloc \\ free 多一些特性,在构造函数的时候再分析)
- new [ ] \\ delete [ ]
现在的很多高级编程语言不需要开发人员去管理内存(比如Java),屏蔽了很多内存细节,利弊同时存在
- 利:提高开发效率,避免内存使用不当或泄露
- 弊:不利于开发人员了解本质,永远停留在API调用和表层语法糖,对性能优化无从下手
注意:
- malloc 的返回值是 void ( ) 类型的,然后通过强制转化从而达到我们想要访问的效果*。
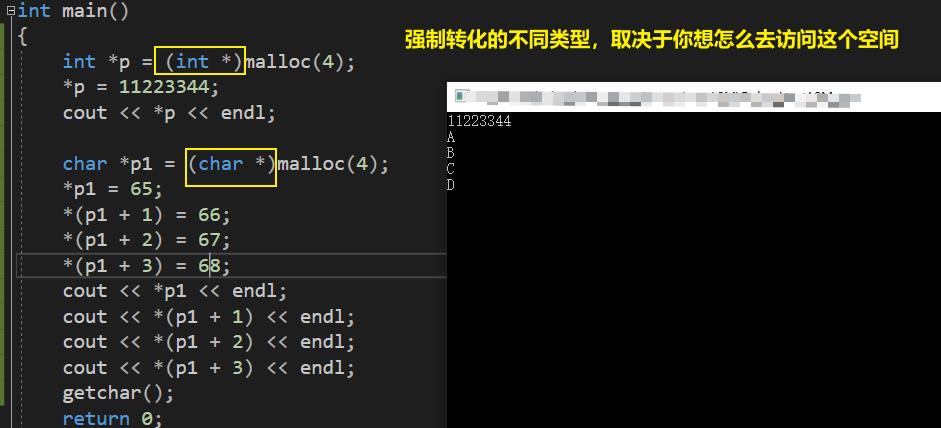
-
函数调用完成之后,栈空间消失,堆空间的内存并不能消失,必须通过 free 来进行释放。

-
new、delete

- 内存空间不足,会导致申请堆空间失败,返回 NULL ,所以每次申请之后,我们可以检测一下有没有申请成功。
堆空间的初始化
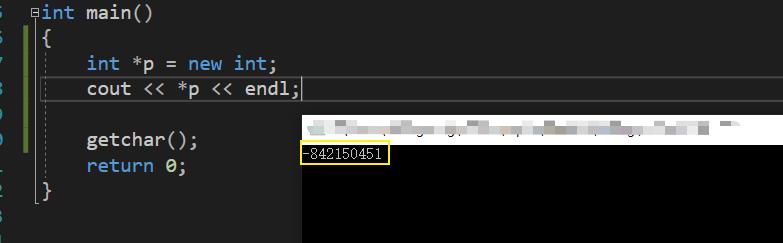
探讨一:我们刚申请堆空间的时候,平台会帮我们进行初始化吗?
答案:windows 下的 VS 并不会帮助我们进行初始化。
探讨二:我们为什么要进行初始化?
- 如果不进行初始化,可以看出指针内部的值是乱的。
- 如果我们这个变量是一个很重要的值,比如控制电流大小,如果出现值很大,那么就会很危险。
探讨三:C++ 当中有几种初始化?

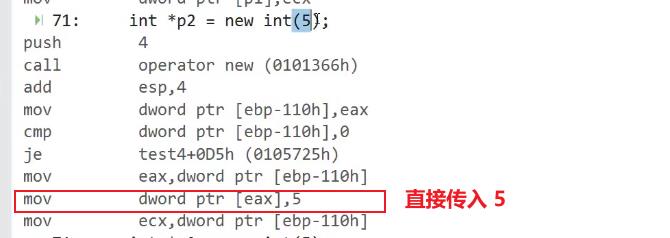
- 加一个 圆括号 :本质还是添加 圆括号 之后,new 函数内部调用了 memset 函数
int *p2 = new int( );

- 加一个 圆括号 ,圆括号里面加一个 5
- 申请连续数组的空间
int *p3 = new int[3] ; // 未初始化
int *p3 = new int[3] { }; //将所有元素初始化为 0
int *p3 = new int[3] { 5 }; // 将第一个元素 初始化为 5
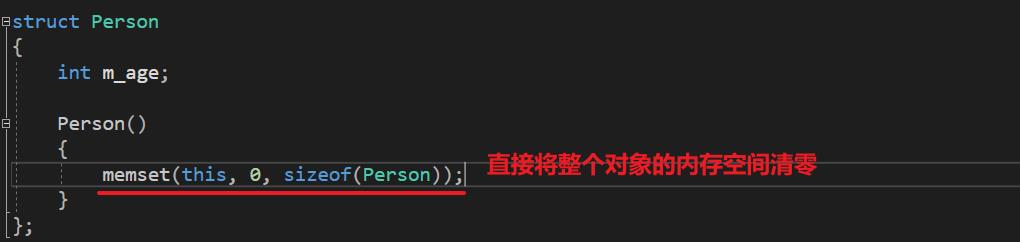
- 通过 memset 的方式来进行初始化:是将较大的数据结构(比如对象、数组等)内存清零的比较快的方法

3、成员变量的初始化
- 前提是默认情况下会不会帮助我们进行初始化。
- 如果使用构造函数的话,肯定会通过调用构造函数来进行初始化。

另外一种情况:我们写一个空的、无参的构造函数,看看会不会进行初始化?
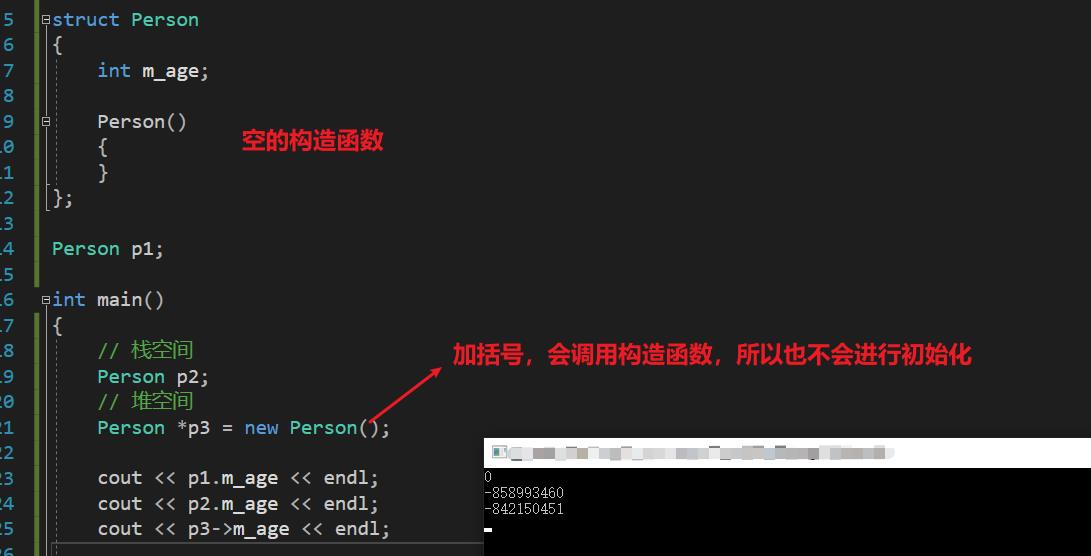
结论:
如果没有定义构造函数
- 全局区会被初始化为 0
- 栈空间不会进行初始化,
- 堆空间加括号之后,会进行初始化。
如果自定义了构造函数
- 全局区会被初始化为 0
- 栈空间、堆空间 并不会进行初始化 ,需要开发人员手动初始化。(不管怎么 new 都不会进行初始化)
有一种做法,不管什么情况,都会初始化为 0
三、构造函数(constryctor)
- 面向对象的语言,都有这个功能。
- 构造函数(也叫构造器),在对象创建的时候自动调用,一般用于完成对象的初始化工作。
特性:
- 函数名与类同名,无返回值,但是不可以写 void
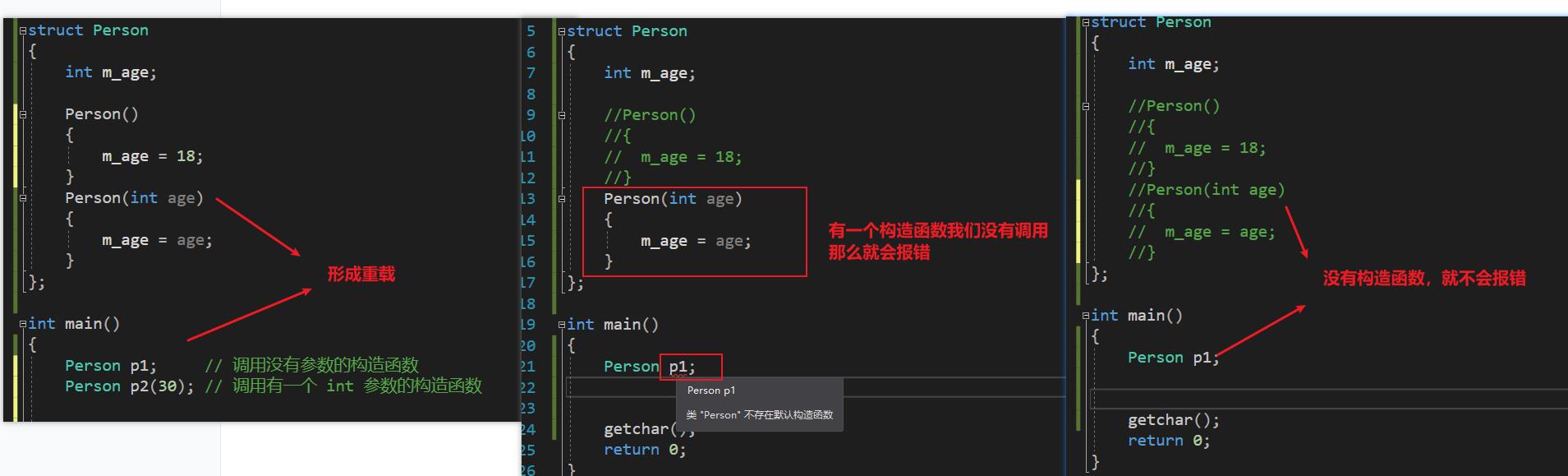
- 可以有参数,可以重载, 可以重载就是说可以有多个同名的构造函数。
- 一旦自定义了构造函数,必须用其中一个自定义的构造函数来初始化对象 (第 2 个图)
注意:通过 malloc 分配的对象不会调用构造函数, 通过 new 分配的对象会调用构造函数。
- 所以 new 比 malloc 会多做一些事情。
- 所以 我们在 C++ 当中一定要使用 new 。

一个广为流传的、很多教程\\书籍都推崇的错误结论:默认情况下,编译器会为每一个类生成空的 无参 的构造函数
正确理解:在某些特定的情况下,编译器才会为类生成空的无参的构造函数
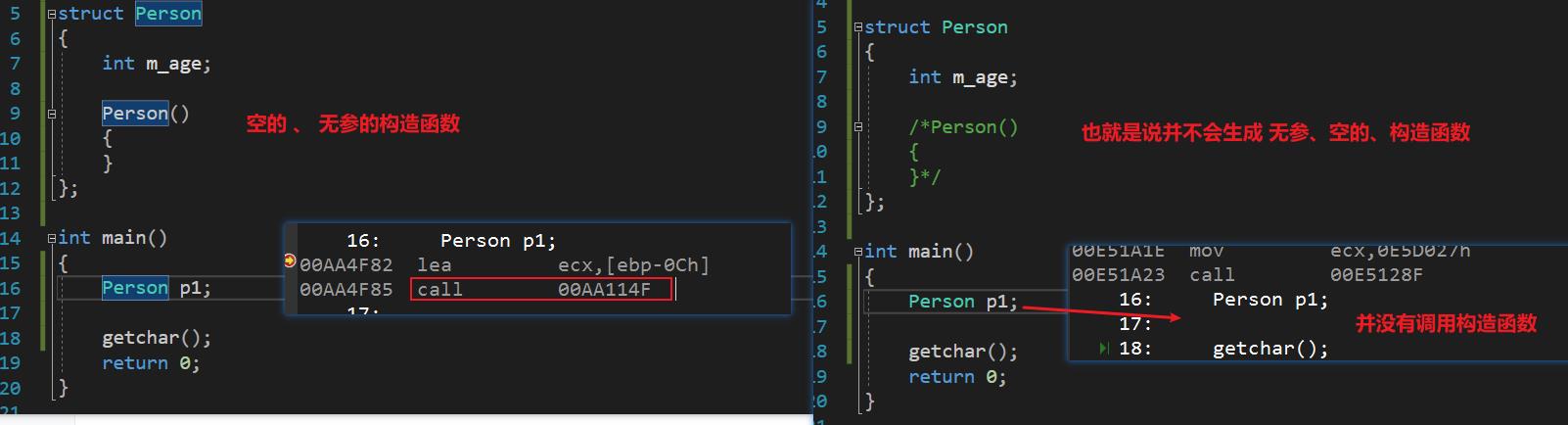
其中的一种情况:

还有哪些特定的情况?以后再提
1、构造函数的调用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BBfFHRtU-1633779190649)(C:\\Users\\duxingdong\\AppData\\Roaming\\Typora\\typora-user-images\\image-20210524222001649.png)]
可以发现,少了两个构造函数。这两个被看作是 函数声明。


四、析构函数(Destructor)
- 面向对象的语言,都有这个功能。
- 析构函数(也叫析构器),在对象销毁的时候自动调用,一般用于完成对象的清理工作。
特点:
-
无返回值(void都不能写)。
-
函数名以~开头,与类同名。
-
无参,不可以重载,有且只有一个析构函数。

注意:
- 通过malloc分配的对象free的时候不会调用析构函数
- 构造函数、析构函数要声明为 public,才能被外界正常使用

1、内存清理
我们知道在对象销毁的时候,会调用析构函数,那么我们在析构函数当中需要做哪些内存清理的工作?
(1)我们用不用清理对象内部的成员变量?
答:不需要,因为在函数结束的时候,我们的对象会被销毁了,栈空间会自己进行回收。
疑问:那么我们析构函数到底要做什么内存清理工作呢?
案例:
#include <iostream>
using namespace std;
struct Car
{
int m_price;
Car()
{
cout << "Car::Car() " << endl;
}
~Car()
{
cout << "Car::~Car() " << endl;
}
};
struct Person
{
int m_age;
Car *m_car; // 包含一个指针,为了使用堆内存
// 用来做一些 初始化的工作
Person()
{
m_age = 0;
m_car = new Car(); // 初始化指针
cout << "Person::Person()" << endl;
}
// 用来做一些 内存清理的工作
~Person()
{
cout << "Person::~Person()" << endl;
}
};
int main()
{
{
Person p1;
}
getchar();
return 0;
}
分析:
- person 类当中包含了 car 类
- person 类当中定义一个 car 类的指针,是为了在堆内存当中使用对象。
运行结果:可以发现car 的对象被定义了,但是没有执行它的析构函数。
Car::Car( )
Person::Person( )
Person::~Person( )
因为:car 对象并没有销毁,所以会造成内存泄露。
解决:在析构函数当中销毁(因为人都不在了,要汽车也没用了)
~Person()
{
delete m_car;
cout << "Person::~Person()" << endl;
}
// 运行结果
Car::Car()
Person::Person()
Car::~Car()
Person::~Person()
如果不在析构函数当中清理,在外面清理,那就太麻烦了。

- 一个对象在栈空间,另外一个对象在堆空间
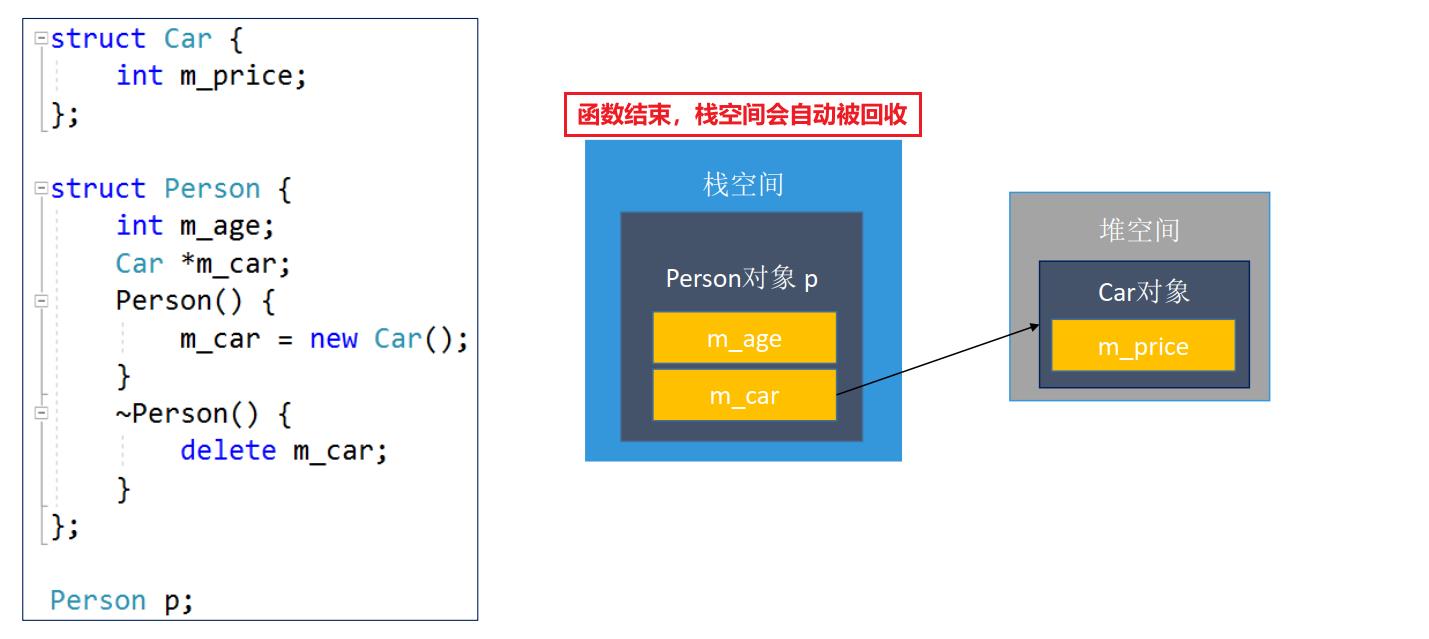
- 两个对象都在栈空间

- 两个对象都在堆空间
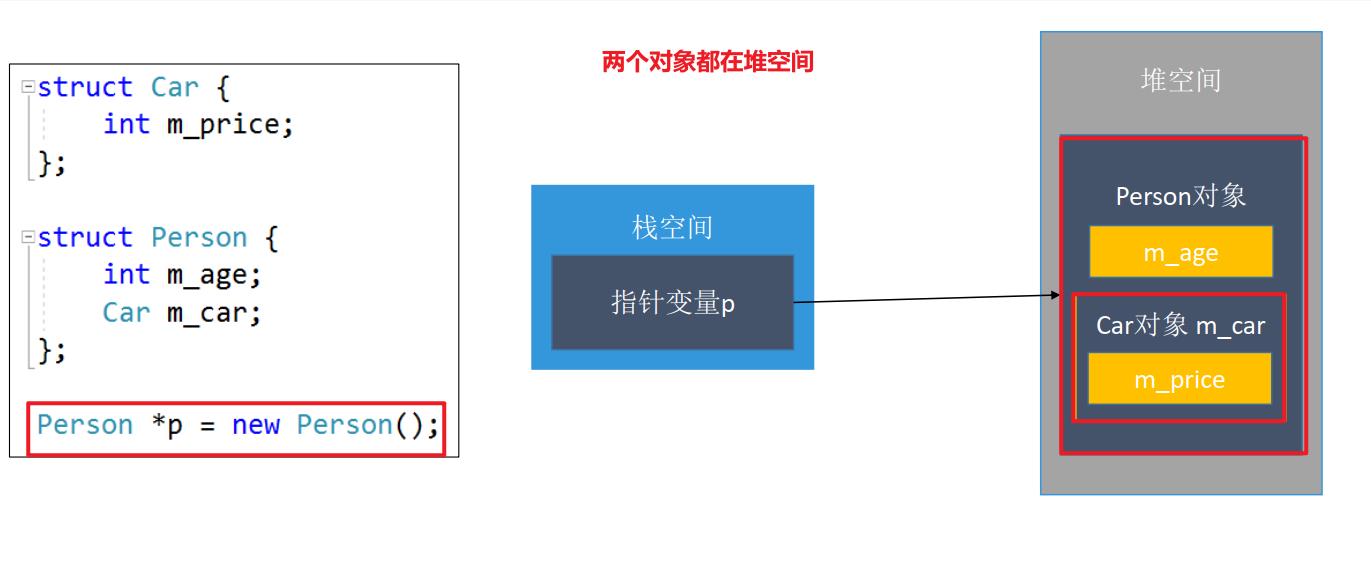
- 两个对象都在堆空间 (在类内定义,那么就应该在类内进行回收)
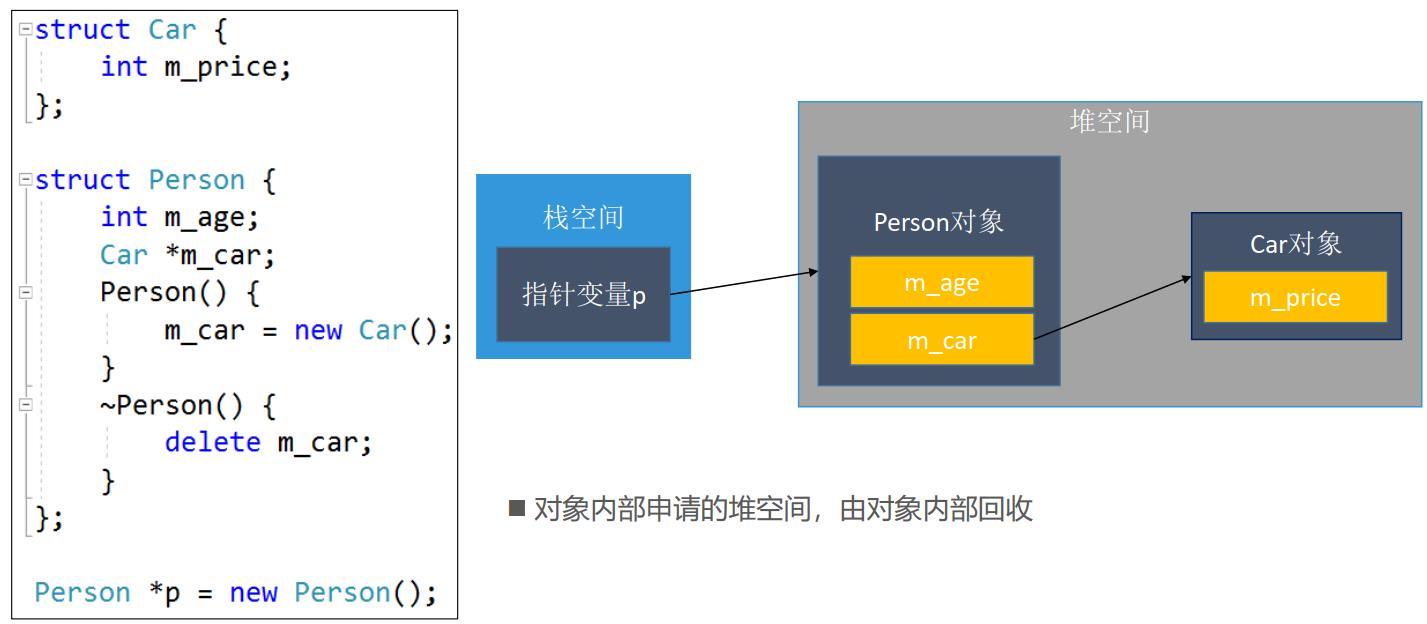
总结一句话:在类内定义的变量,那么就应该在类内的析构函数进行回收
五、程序优化
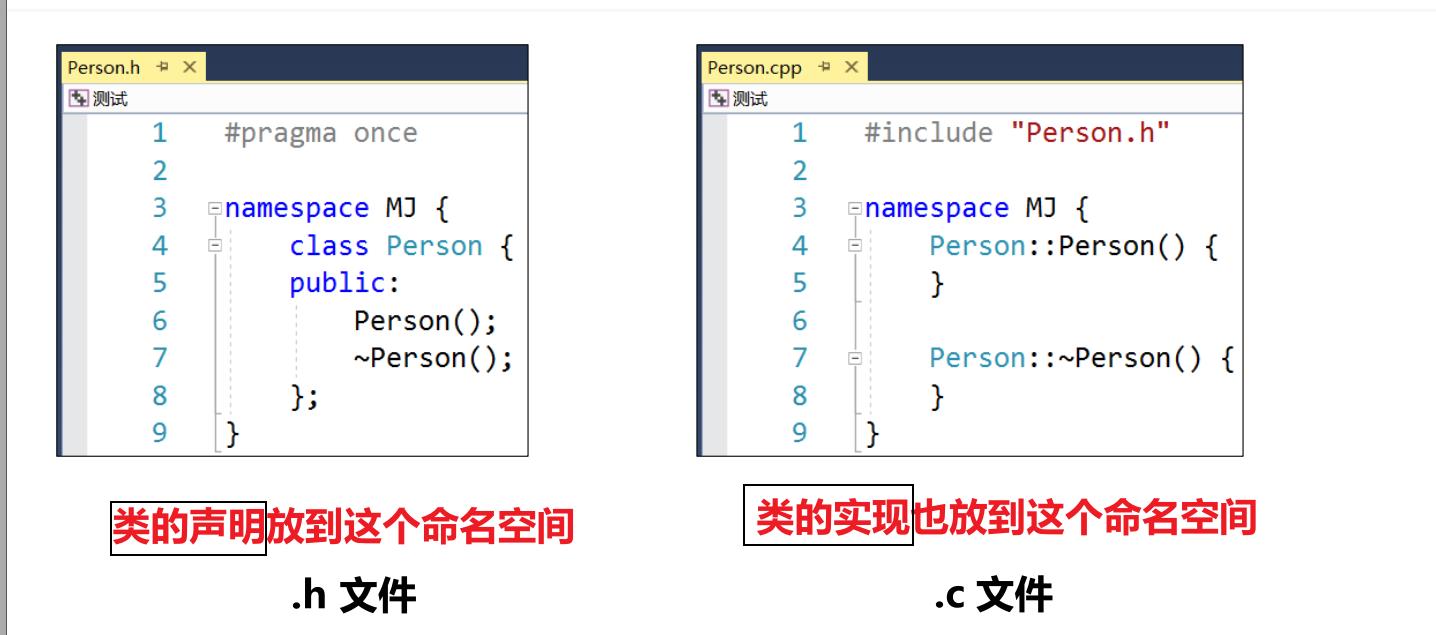
1、声明和实现分离
- 在 .h 文件 当中进行声明
- 在 .c 文件 当中进行实现

2、命名空间
- 命名空间可以用来避免命名冲突
什么是命名冲突呢?

解决办法:
- 使用命名空间来解决
- 相当于我们户口登记,一个城市是一个命名空间。

- 也可以通过增加前缀来解决这个问题(但是不灵活)
class zhangsan_Person
{
};
class lisi_Person
{
};
怎么使用命名空间?
- 在类名称前面添加 命名空间

-
使用 using namespace 命令

解析 :using namespace std; 命令
如果没有这条指令:很多标准函数,我们必须添加前缀
std :: cout << "hello_world" << std :: cin;
如果使用了这条指令,我们就不需要添加前缀了
using namespace std;
cout << "hello world" << endl;
所以肯定有一个文件在 std 的命名空间当中实现了很多标准函数
namespace std
{
cout( )
{
}
cint ( )
{
}
}
- 使用命名空间 单独访问命名空间某个元素。

思考
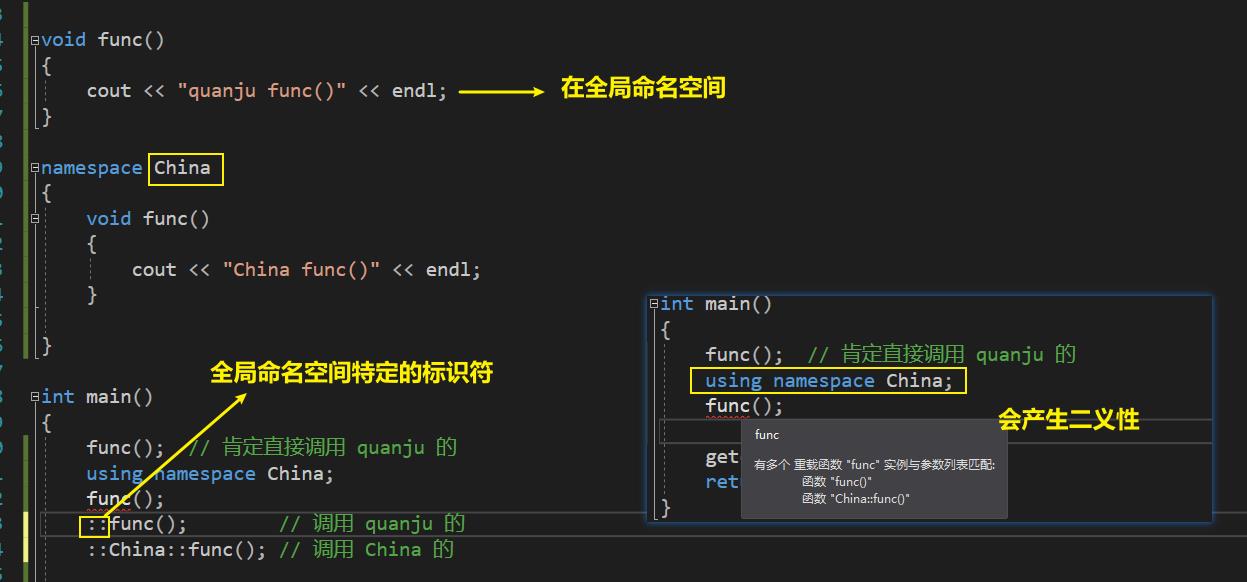
同时使用两个命名空间,可以编译通过吗?

解决:可以使目标明确一点,前面加上作用域,就不会有二义性了。
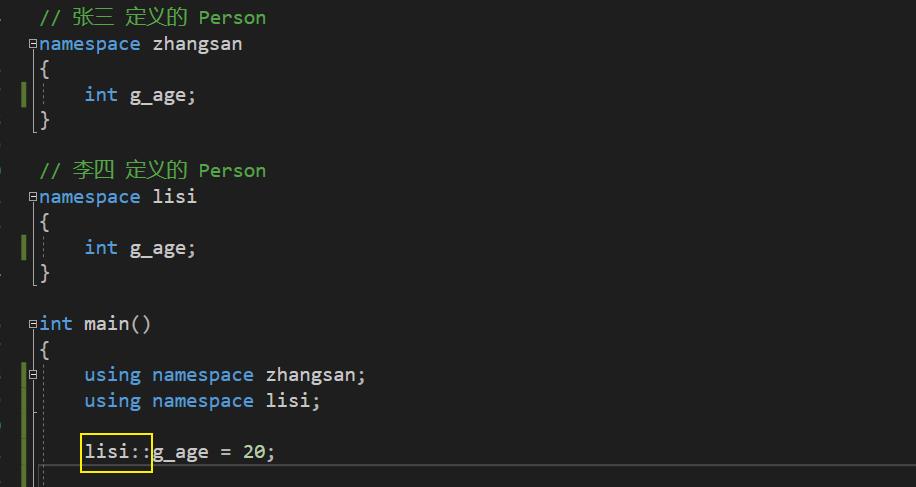
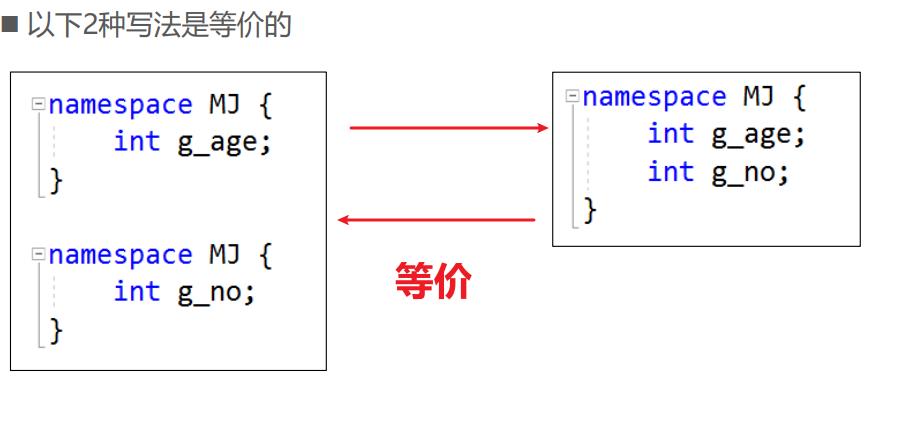
命名空间的嵌套、合并

- 有个默认的全局命名空间
- 我们创建的命名空间默认都嵌套在 全局命名空间 里面

命名空间的合并:
应用场景:
六、继承
含义:可以让子类拥有父类的所有成员(变量\\函数)
问题:如果两个类当中有很多相同的特性,也有很多自己的特性。
- 我们应该将共性的东西抽离出来作为父类。
- 将 特性的东西留下来,然后让他们去继承父类。

关系描述:
- Student 是子类(subclass,派生类)
- Person 是父类(superclass,超类)

1、继承的内存布局
- 父类成员在前面
- 子类成员在后面

明确一点:子类对象到最后确实占用空间很大,因为包含了基类的所有成员。
问题:如果基类的成员没有用到,那么子类的空间不就浪费了吗?
-
如果整个程序的所有对象,都没有用到,那确实是浪费了。
-
但是如果有一个对象用到,那就不能算是浪费。
-
这个不是 C++ 本身语法的问题,而是写代码的人的问题,既然所有对象都用不到,那么为什么要将他设计进去。
2、成员访问权限、继承方式
首先 成员访问权限 有三种:
- public:公共的,任何地方都可以访问(struct默认),可以被继承
- protected:子类内部、当前类内部可以访问, 也可以被继承
- private:私有的,只有当前类内部可以访问(class默认) ,子类也没有访问权限
其次 子类继承父类的方式 也有三种:
- public:保持原来基类的所有属性权限 (同理 struct 默认是 public 继承)
- protected:
- private:将继承来的成员变量,重新进行修饰 (同理 class 默认是 private 继承)
对继承方式的理解:对所继承的成员变量,进行权限修饰。


总结:GoodStudent 能不能访问父类当中的成员取决于两点:
- Person 当中使用什么权限?
- Student 使用什么方式继承?
- GoodStudent 的访问权限,就是上面两者的权限最小的。
一般我们写 public 继承:
-
public 继承可以很好的将父类原有的权限继承下来。
-
因为取权限的最小值,所以原来是 protected ,继承之后还是 protected
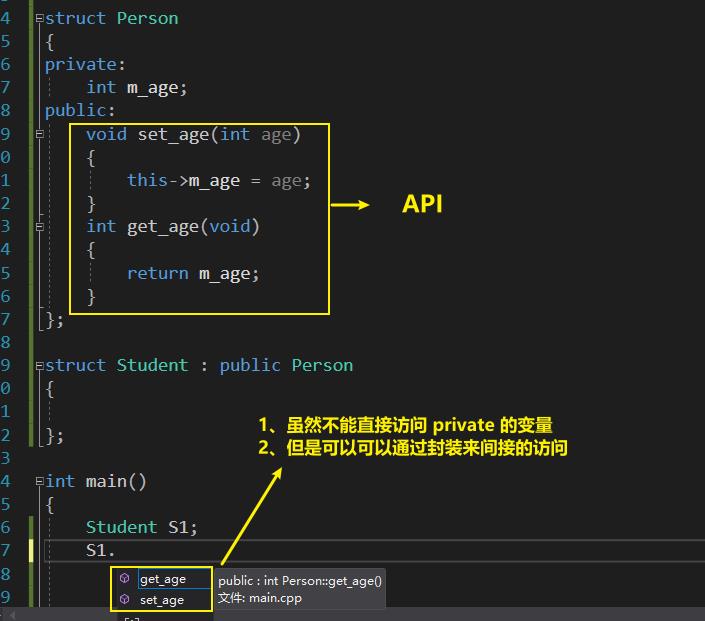
问题:既然我们子类没有访问父类 private 成员的权限,那么这个成员还会被继承下来吗?这个成员还占用内存吗?
答:访问权限不影响继承的内存布局
- 会将成员继承下来
- 只是我们不能直接进行访问,但是对象内存当中还是有这个变量。
- 我们可以通过封装进行间接访问。
问题:既然我们不能直接访问,那么留下这个成员变量还有什么意义?
- 封装
- 间接访问
- 如果我们子类对象内存当中都没有 m_age 这个变量, 这些 API 也根本不可以进行更改。
七、初始化列表
发明目的:顾名思义,初始化列表,就是为了初始化发明的。
特点:
- 只能用在构造函数中
- 一种 便捷的初始化成员变量 的方式
- 初始化顺序只跟成员变量的声明顺序有关
怎么理解更加便捷呢?
- 可以通过汇编代码来分析,底层其实是一样的。
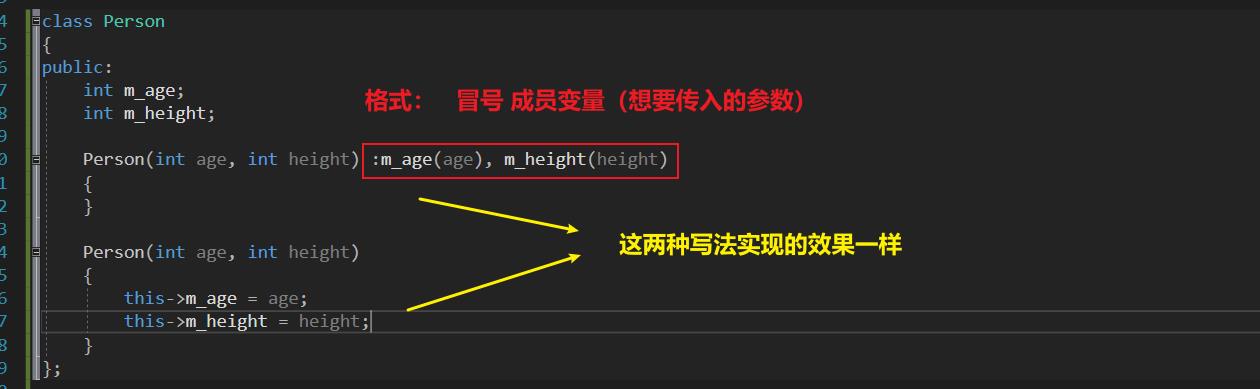
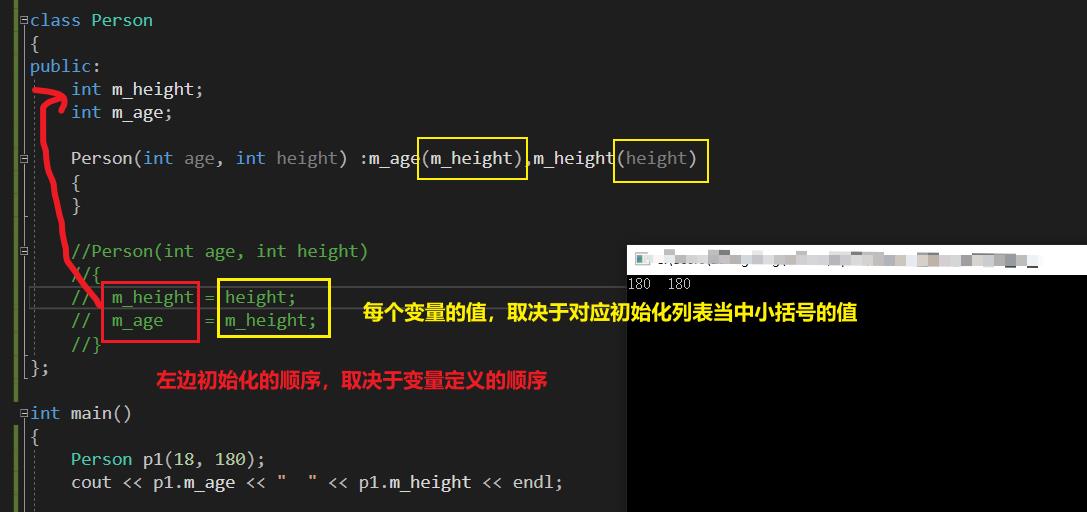
1、思考:初始化列表的本质
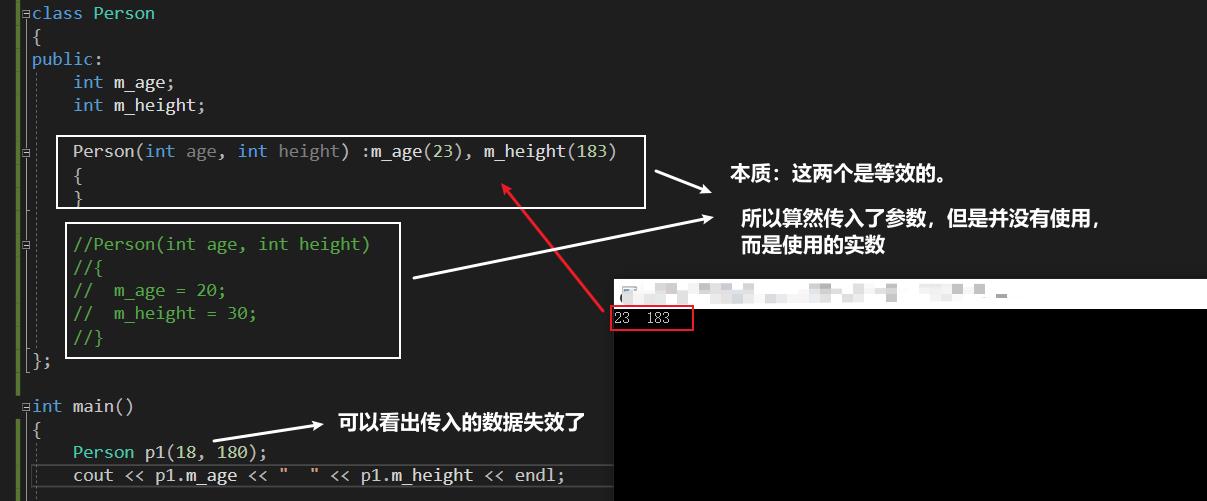
m_age、 m_height的值是多少?
答案: 23, 183。
总结:
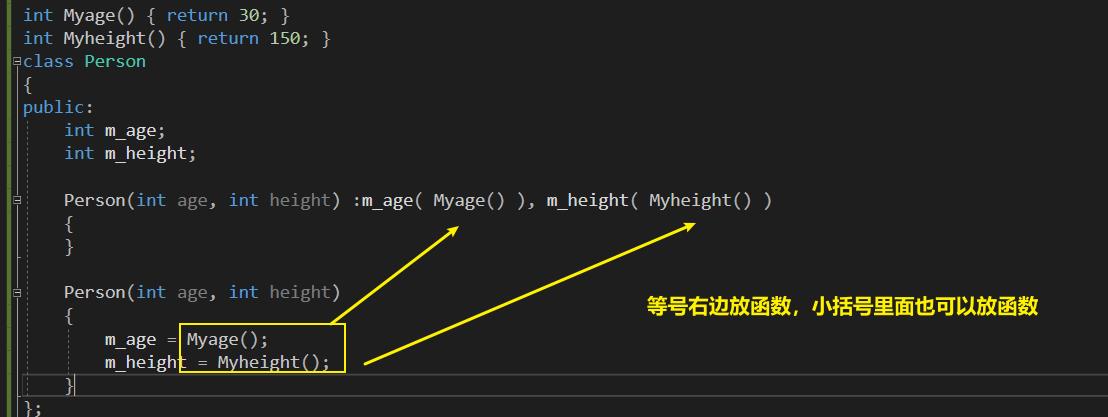
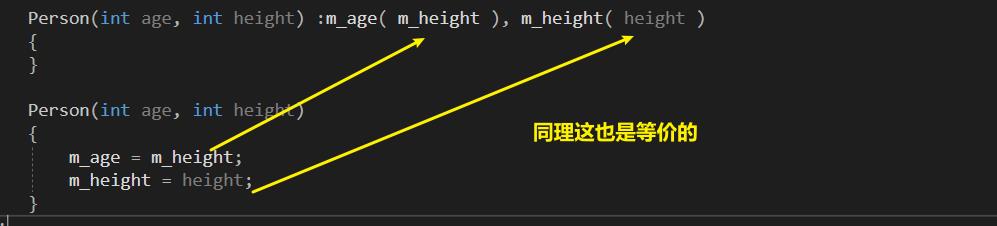
- m_age = 和 m_height 的等号右边能放什么,初始化别表的小括号里面就可以放什么。
2、思考:初始化的先后顺序

我们想:如果我们先初始化 m_height 的话,那么 m_age 就不会是乱码了。
尝试一:更改初始化列表的变量的顺序

尝试二:更改 成员变量声明的顺序:
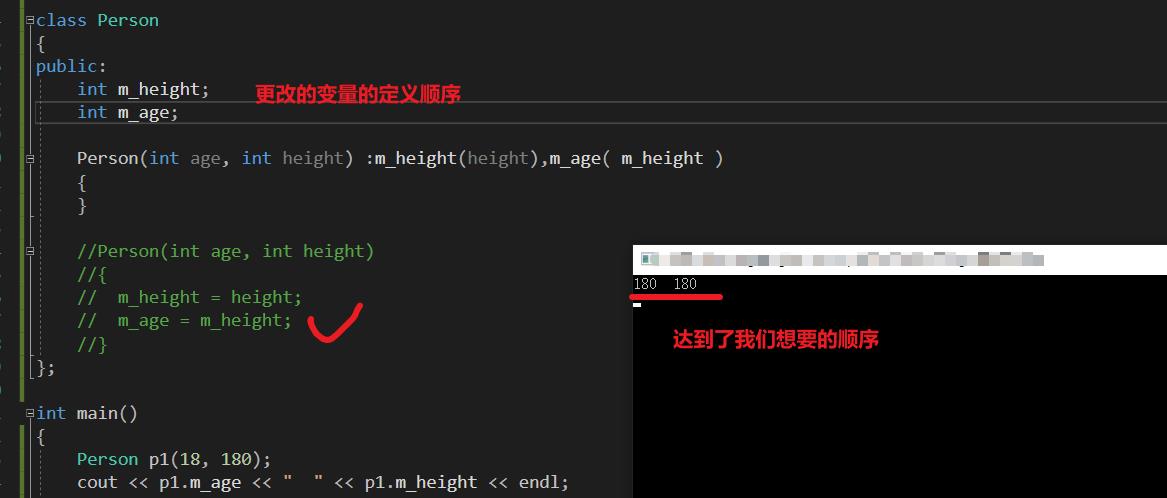
总结:
- 成员变量的初始化顺序,只和成员变量的定义相关。
- 成员变量的初始化值, 取决于初始化列表当中对应变量小括号里面的值。
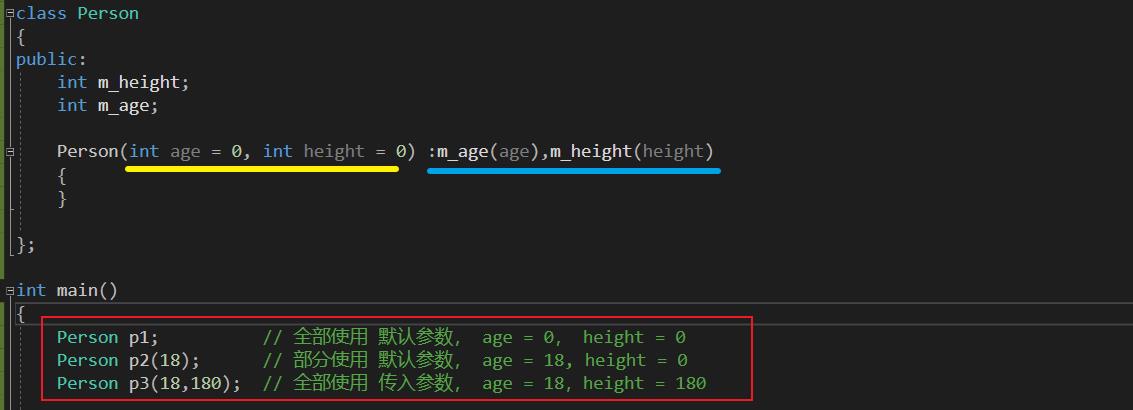
3、初始化列表与默认参数配合使用
可以实现一种效果:仿佛有三种构造函数
- 无参的(全部使用默认参数)
- 有一部分参数(部分使用默认参数,部分使用传入的参数)
- 全部是指定参数(全部使用传入的参数)
注意:如果函数声明和实现是分离的(声明在类里面,实现在类外面)
- 初始化列表只能写在函数的实现中
- 默认参数只能写在函数的声明中
八、再论构造函数
首先我们要开拓眼界:
- 构造函数里面不仅仅是初始化成员变量
- 我们还可以 定义一个类
- 我们还可以 调用其他子函数
1、构造函数的互相调用
- 下面的写法是错误的,初始化的是一个临时对象
- 在构造函数当中调用构造函数,相当于创建了一个临时的对象。
- 然后将10、20 赋值为临时的对象。
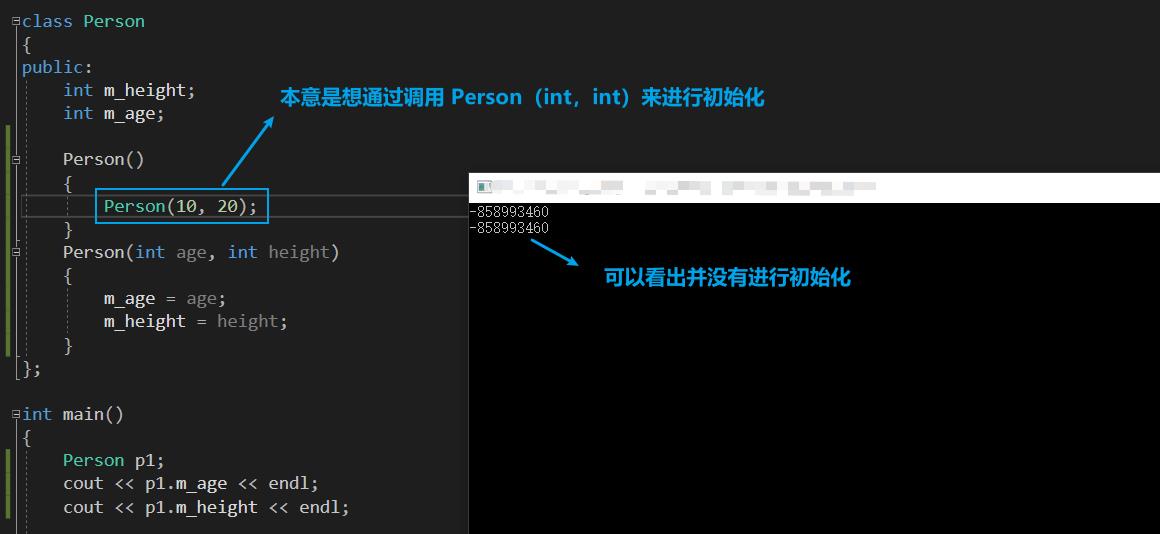

我们来进行证明:使用汇编语言
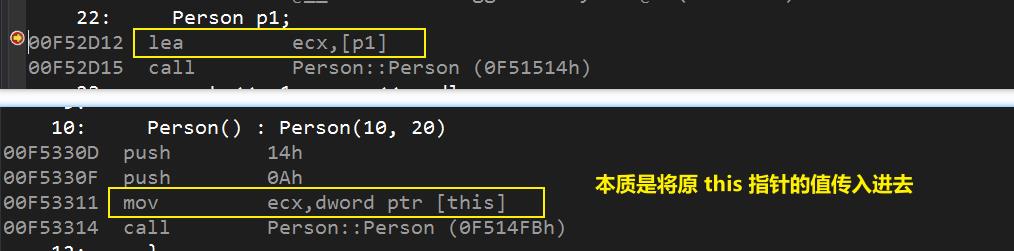
第一步:确认 this 指针和 调用构造函数
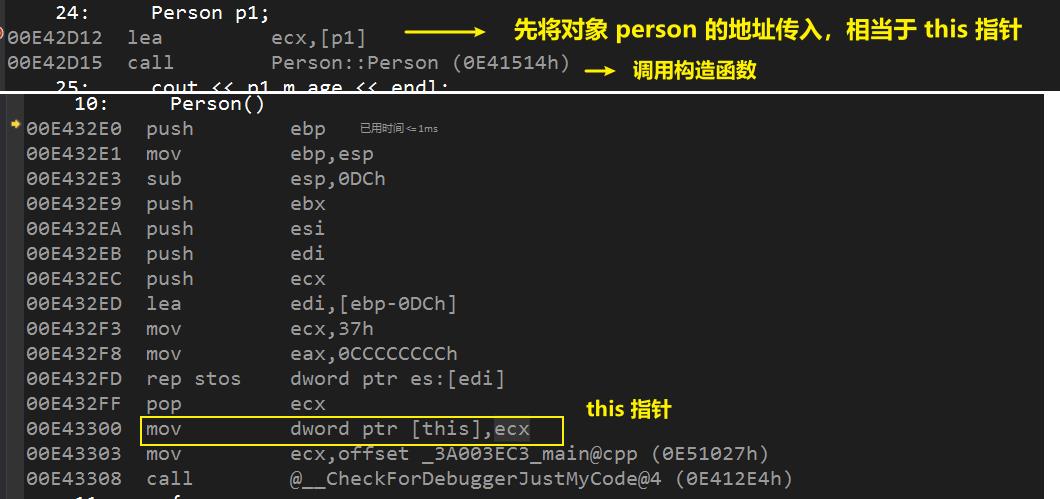
第二步:确认传给第二个构造函数的 this 指针
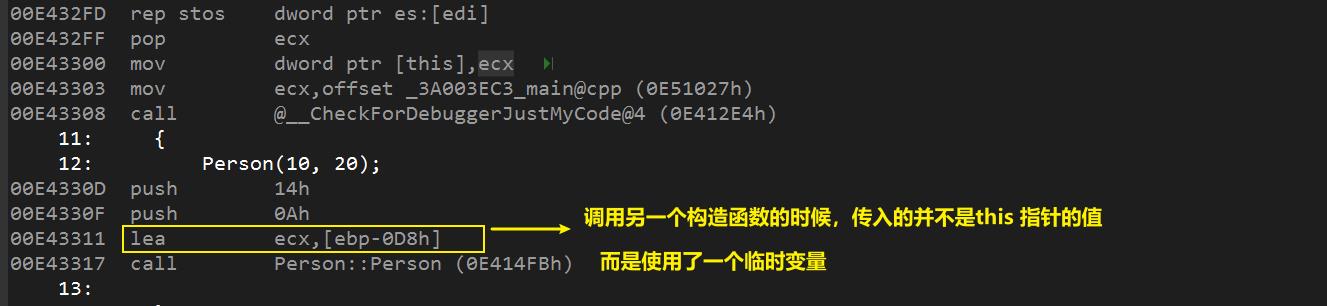
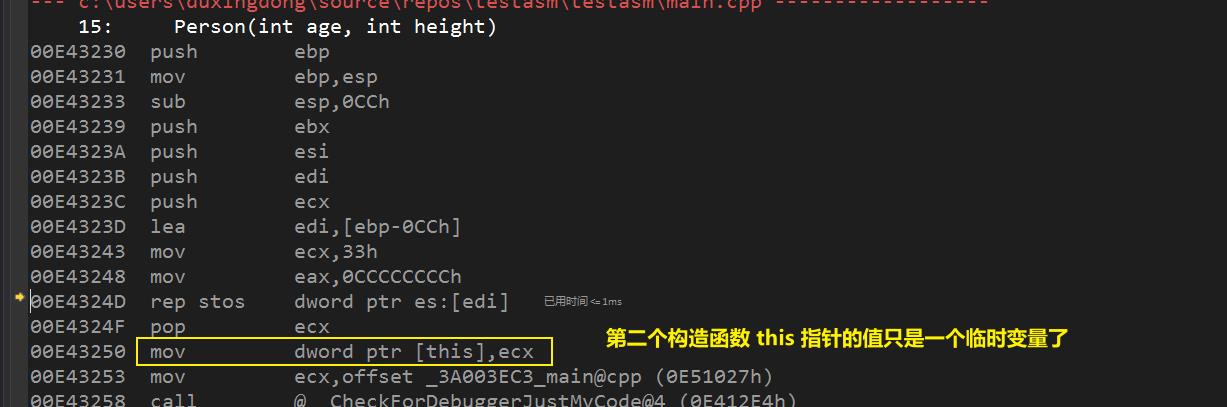
总结:
1、构建对象的时候,第一个构造函数的 this 指针确实是本对象的地址。
2、第二个构造函数的 this 指针却是一个临时对象的地址。(所以并不会将原来的对象进行初始化)
我们将,构造函数应该放到初始化列表当中
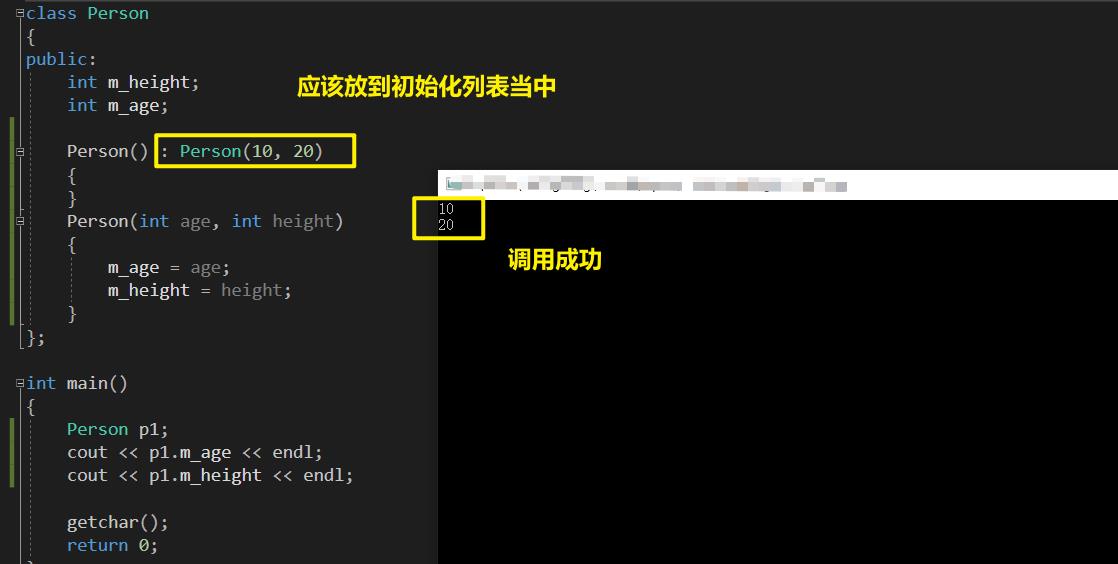
使用汇编进行分析:
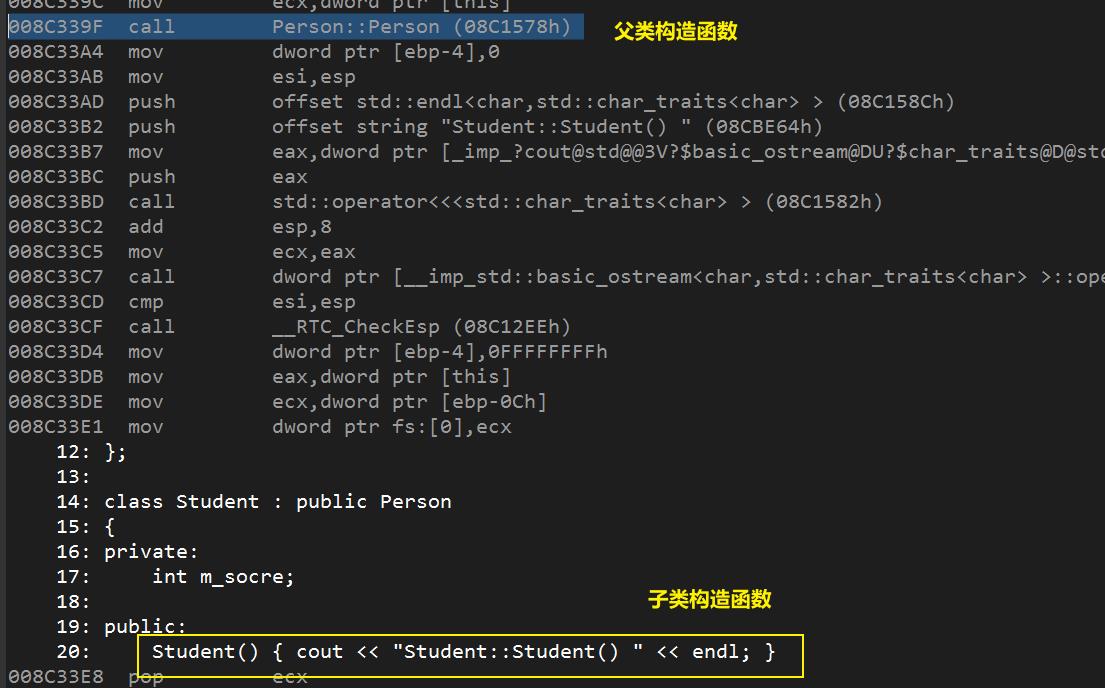
2、父类的构造函数(继承)
1、子类的构造函数,默认会调用父类的无参构造函数
2、如果子类的构造函数显式地调用了父类的有参构造函数,就不会再去默认调用父类的无参构造函数
3、如果父类缺少无参构造函数,子类的构造函数必须显式调用父类的有参构造函数
接下来一条一条进行分析
分析这么做是为了什么:
- 子类的构造函数只是初始化子类特有的成员变量。
- 而基类的成员变量,理所应当的在基类当中的构造函数里面进行初始化。
- 所以在初始化子类成员变量之前,应该先将父类的成员变量进行初始化。
1、子类的构造函数,默认会调用父类的无参构造函数
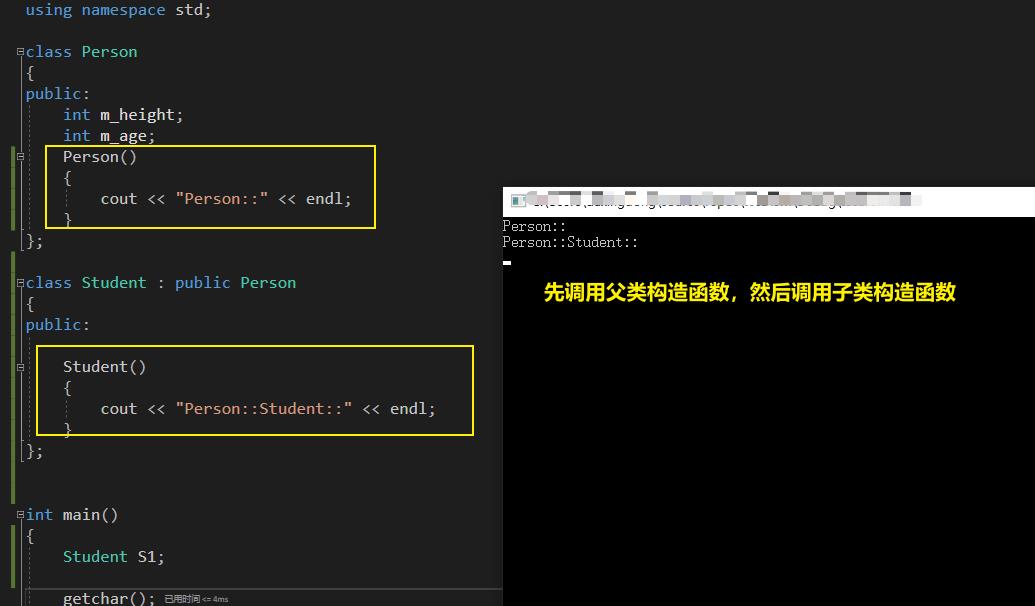
分析汇编:

2、如果子类的构造函数显式地调用了父类的有参构造函数,就不会再去默认调用父类的无参构造函数
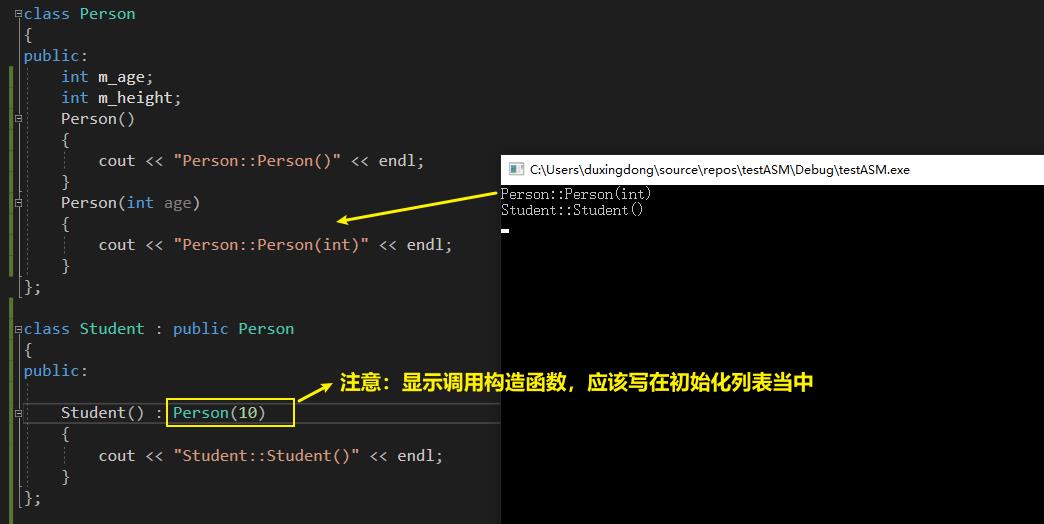
3、如果父类缺少无参构造函数,子类的构造函数必须显式调用父类的有参构造函数


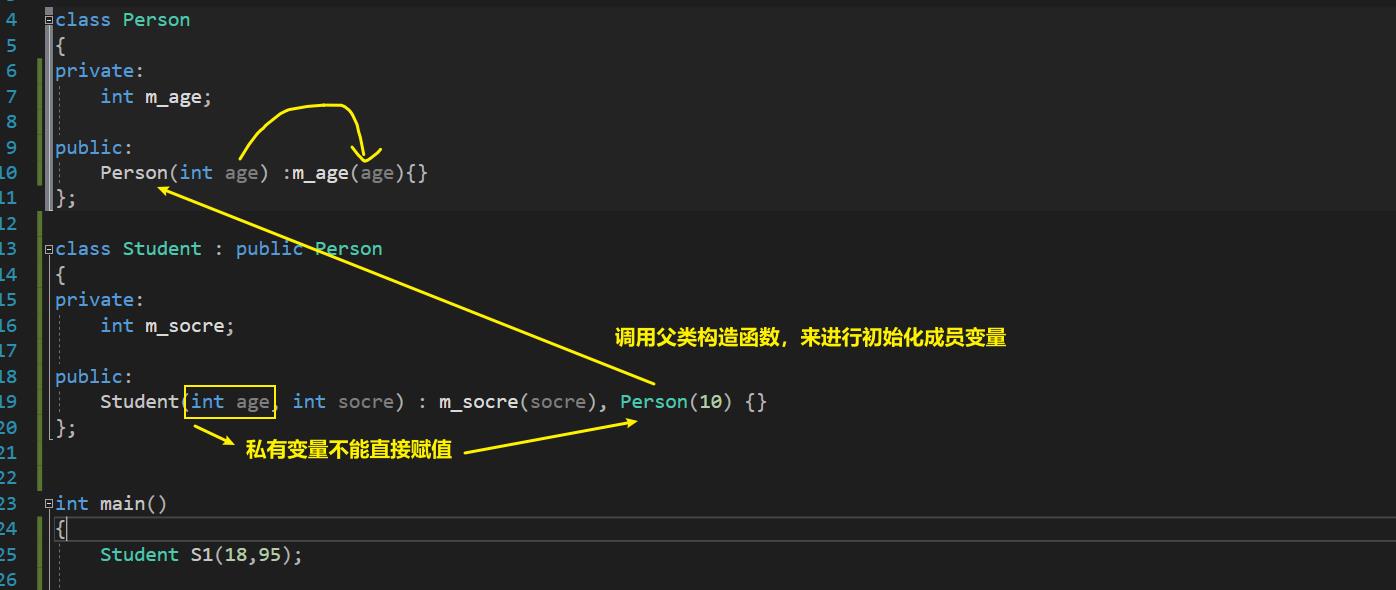
我们正式开发的写法:
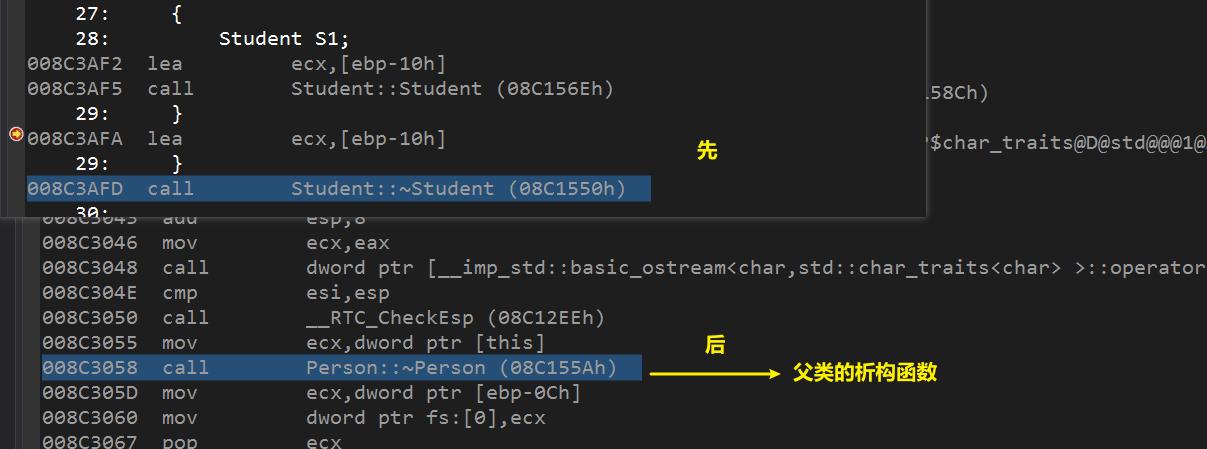
3、构造和析构的顺序
- 首先明确:子类构造函数会主动调用父类的构造函数,子类的析构函数也会主动去调用父类的析构函数
构造函数: 先初始父类,后初始子类。
析构函数: 先释放子类,后释放父类。

汇编分析:
以上是关于C++学习:2类和对象的主要内容,如果未能解决你的问题,请参考以下文章