Kafka之从0到1(part1)
Posted ShuSheng007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka之从0到1(part1)相关的知识,希望对你有一定的参考价值。
[版权申明] 非商业目的注明出处可自由转载
出自:shusheng007
概述
用了一段时间Kafka,觉得很有必要总结一下这个神器。文章深度属于入门级的,适合小白入门,待熟练掌握后就可以从官网以及源码中获取更加高级的内容了。
Kafka是啥?
关于这一点比较有意思,Kafka官网说自己是一个事件流平台(event stream platform),但我们大部分时间却认为它和RabbitMQ一样是个消息队列。这就好比你认为你是女神的真命天子,而她却只把你当钱包一样,其实是你刚好提供了钱包这一功能而已。
不论是什么,我们要清楚Kafka是一个分布式系统,具有高吞吐量,高容错,易扩展,高可用的的系统。最初是由LinkedIn(领英) 于2011年开源的,现在归Apache基金会所有。
Kafkan能干啥?
是啥都无所谓啦,关键是它能干啥。下面是官方列出的一些使用场景:
- 实时处理支付和金融交易,例如在证券交易所、银行和保险中。
- 实时跟踪和监控汽车、卡车、车队和货物,例如物流和汽车行业。
- 持续捕获和分析来自 IoT 设备或其他设备(例如工厂和风电场)的传感器数据。
- 收集客户互动和订单并立即做出反应,例如在零售、酒店和旅游行业以及移动应用程序中。
- 监测住院病人并预测病情变化,以确保在紧急情况下得到及时治疗。
- 连接、存储和提供公司不同部门产生的数据。
- 作为数据平台、事件驱动架构和微服务的基础。
牛逼不?有没有感觉学会Kafka在未来社会打遍天下无敌手了,都是极有前途的行业…
整体介绍
其整体设计思想和消息队列很像,要不说它可以当消息队列使呢。关键角色就3个:
- 生产者(producer)
负责产生消息,然后丢给broker
- 中间人(broker)
负责从producer那接收并存储消息,然后提供给consumer消费
- 消费者 (consumer)
负责消费消息
整体大概就是这么个过程,当然细节比这个复杂多了。
下面是我画的一张Kafka框架图,大概描述了各个组件之间的关系,我们就以此图为依据来学习一下Kafka的一些基础知识。有的同学可能不耐烦啦:人家现在Java后端开发都是使用SpringBoot,使用Kafka也是直接使用它封装好的API,学这些有毛用?如果有人和你这么说,你就吐他一脸,然后和他在技术上绝交,这货绝对是个菜鸟,一辈子是个菜鸟。
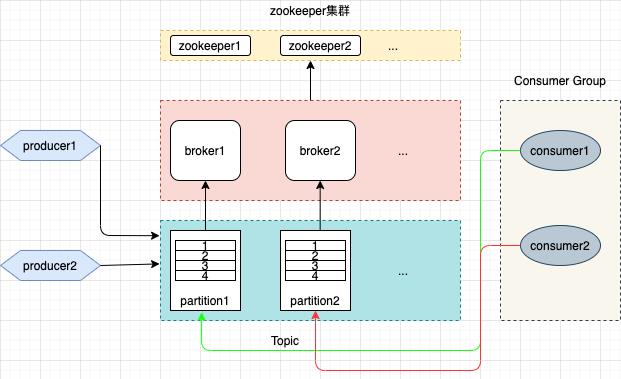
关键概念
要弄清楚Kafka工作原理,首先要弄清楚其中的一些关键组件和概念。为了加深理解,我们以王二狗和林蛋大在百合网上找对象这个事来类比一下。
- Broker
这个其实就是Kafka的Server。Kafka是分布式系统,所以一般是以集群的方式部署,也就是说会同时存在多个Broker实例,这些实例一般部署在不同的服务器上,或者云服务器上。例如Broker1 部署在天津,Broker2 部署在北京,他们提供相同的功能,组成一个集群。这些Broker是通过ZooKeeper协调的,ZooKeeper也可以以集群的方式部署。
这就好比百合网各地的分公司,北京分公司和天津分公司都可以提供相亲服务
- Producer
发送消息的程序,例如我用SpringBoot写个一个服务,此服务向Kafka的Server发送消息,它就是一个producer,producer可以不止一个。
这就好比在百合网注册的单身小姐姐们,她们的注册信息就是一条消息。
- Topic
消息的分类,每一条消息都属于一个Topic,一个Topic可以跨多个Broker。
这就好比那些在百合网注册的小姐姐们每一个人的信息都会被按照主题分类,例如有肤白貌美型的,有事业有成型的,有小鸟依人型的等等。这些分类是跨分公司的,例如牛翠花和上官无雪都属于肤白貌美型的,但是上官无雪是在北京分公司的服务器上,而牛翠花是在天津分公司的的服务器上。
- Partitions
存放具体消息的地方,Kafka是分布式系统,为了横向扩展消息都是以分区的形式存放的。例如我们有两个broker,分别部署在两台服务器上,我们肯定希望数据分布在这两个broker上,而不是只存在其中一个上面。那我们就可以搞两个分区,每个broker上一个。那你有没有想过,当一条消息来了,Kafka怎么怎到把这条消息存放在哪个分区呢?Kafka还会通过冗余分区的形式来保证数据的可靠性。
这就好比当牛翠花和上官无雪注册相亲信息时,系统把牛翠花分配到了天津分公司的数据库,而上官无雪分配到了北京的数据库,而她两都属于肤白貌美型 Topic下的。
- Consumer
消费消息的程序,consumer是通过主动向broker拉取自己感兴趣的topic的消息来消费。consumer 相较于producer复杂了很多,至于为什么后面再说。
这就好比王二狗深人静的时候打开百合App,搜索肤白貌美型的小姐姐,然后查看相关信息。。。
- Consumer Groups
如果数据量很大,就需要多个consumer来同时处理,这些consumer会形成一个group。这个group里的consumer一般只对某一topic的消息感兴趣。值得注意的是,一个partition只能被一个consumer消费,假如你有两个partition,但是你的group里只有一个consumer,那么这个consumer就要负责读取这两个partition的数据。当你再增加一个consumer,那么每个consumer对应一个partition。当你再增加一个consumer呢?现在是只有两个partition,但是有3个consumer,那完了,人浮于事,其中有一个consumer就摸鱼了,啥也不干了。
这就好比王二狗和林蛋大加入了vip客户群( group)可以看到妹子的更到信息,还可以无限发短信,但是有异地限制。身在天津的王二狗只能看天津分公司的资源,而北京的林蛋大只能看北京分公司的资源
- Offsets
这个其实也很重要,当某条消息被存到到某个partition时会获得一个从0开的编号,这个编号就是offset。所以消费者要想定位一条消息需要三个信息:Topic,Partition,Offsets。
翠花在百合网注册时,被分到了天津分公司数据库0号记录,而上官无雪被分配到了北京分公司的5号记录。
总结
本文只是万里长征第一步,接下来就需要实践了,在实践中慢慢成长,然后慢慢理解。 请持续关注后续系列文章
以上是关于Kafka之从0到1(part1)的主要内容,如果未能解决你的问题,请参考以下文章