MySQL---数据库查询详细教程{分页连接查询自关联子查询数据库设计规范}
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL---数据库查询详细教程{分页连接查询自关联子查询数据库设计规范}相关的知识,希望对你有一定的参考价值。
1.分页
limit start count
limit限制查询出来的数据个数,limit在语句最后
- 查找两个女性
select * from student where gender=1 limit 2;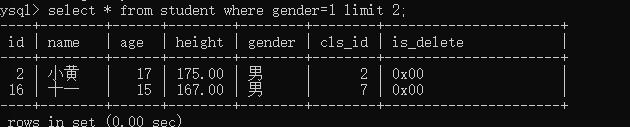
- 从第0个开始查找,往下查5个。
select * from student where gender=1 limit 0,5;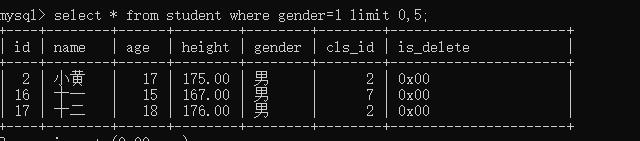
- 从第5个开始查找,往下查5个。
select * from student where gender=1 limit 5,5;
因为一共只有3个,也就是说从第五个起后面五个是不存在的
- 从第2个开始查找,往下查5个。

这里star等于下标
- 每页显示2个,显示第六页的信息,按照年龄大小排序。
select * from student order by age asc limit 5,2;2.连接查询【多表使用】
多个表里合并数据时使用,目前创建了两个表【见相关文章2】
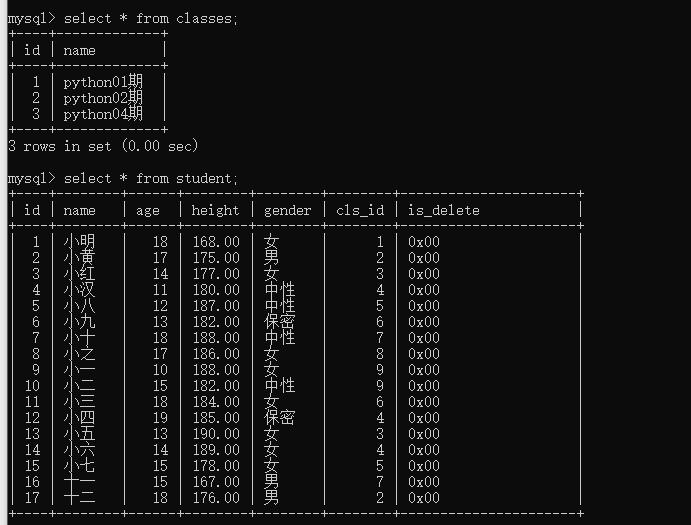
链接查询:inner join ... on(表与表的链接)
select * from student inner join classes;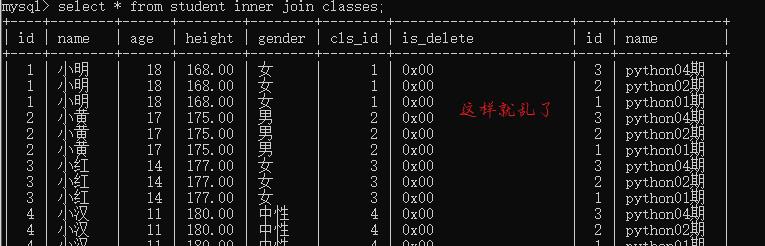
改一下名字:
alter table student rename students;
2.1 交集-内连接
- 查询有能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id=classes.id;
*所有信息都显示,id显示也重复;
- 按要求显示对应另一个表的编号、班级
select students.*, classes.name,classes.id from students inner join classes on students.cls_id=classes.id;
select students.*, classes.name from students inner join classes on students.cls_id=classes.id;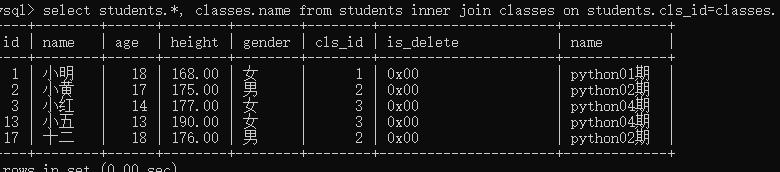
select students.name, classes.name from students inner join classes on students.cls_id=classes.id;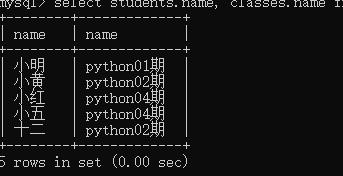
给数据表起名字
select s.name,c.name from students as s inner join classes as c on s.cls_id=c.id;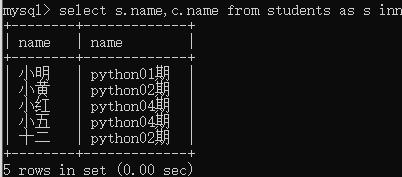
把班级放到第一列:
select classes.name,students.* from students inner join classes on students.cls_id=classes.id;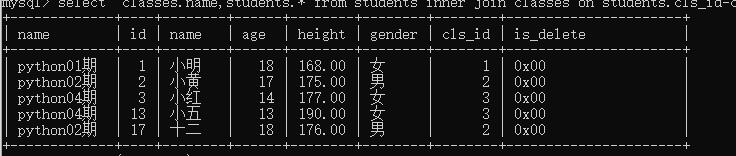
2.2 并集
查询有能够对应班级的学生以及班级信息,按照班级进行排序,若为同班级按照id进行排序。
select c.name, s.* from students as s inner join classes as c on s.cls_id=c.id order by c.name,s.id;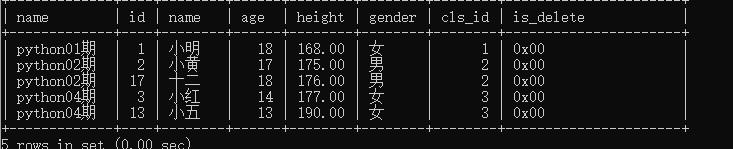
- 外连接
以left join左边为基准,未能匹配则为默认填空 null
select * from students as s left join classes as c on s.cls_id=c.id;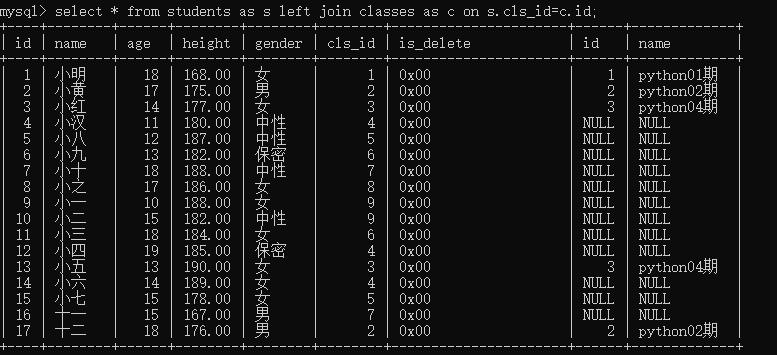
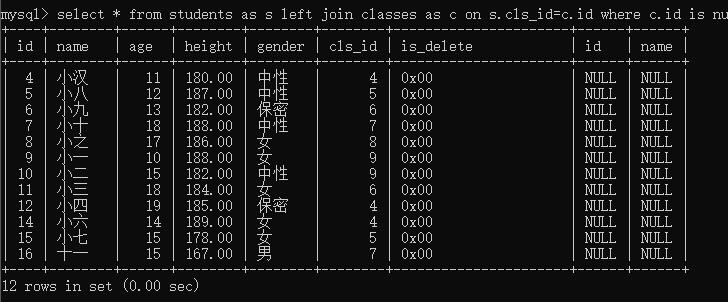
- 查询没有对应班级的学生
select * from students as s left join classes as c on s.cls_id=c.id where c.id is null;select * from students as s left join classes as c on s.cls_id=c.id having c.id is null;where 和 having的区别:
- where使用分组前的筛选【原表判断结果】
- having 用于分组后的筛选【新的结果当作一个集,查询结果】
3.自关联
应用:
表示通过一张表实现逻辑关联查询,类似于省-市-县
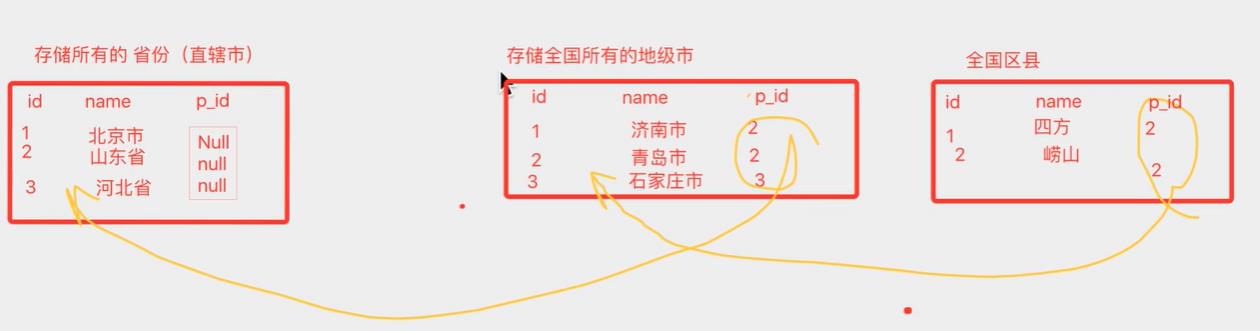
自关联自己关联自己:

数据下载链接: https://download.csdn.net/download/sinat_39620217/29167740
创建数据表:
create table areas(
-> aid int primary key,
-> cid int,
-> atitle varchar(20),
-> pid int);show tables; 

直接输入cmd 在此启动mysql
在cmd模式下输入dir可以查看文件是否在目录下:
show databases;
use ptrhon_test;
show tables;
--导入数据
source areas.sql; 
如果报错:是因为字段数目不统一添加一下即可;上面已经修正用不到了
alter table areas add cid int after aid;
select * from areas; 
查看有多少省:
select * from areas where cid=1;
查看福建有多少地区:
select atitle from areas where cid=4;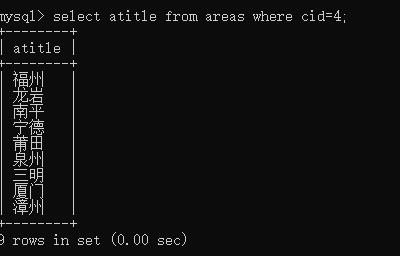
select * from areas where cid=4;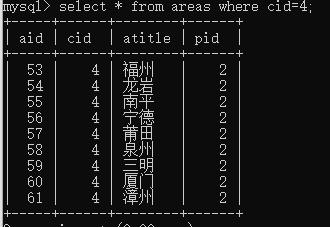
查询江西省有哪些市:一张表变成多个表
select * from areas as province inner join areas as city on city.aid=province.cid having province.pid=2;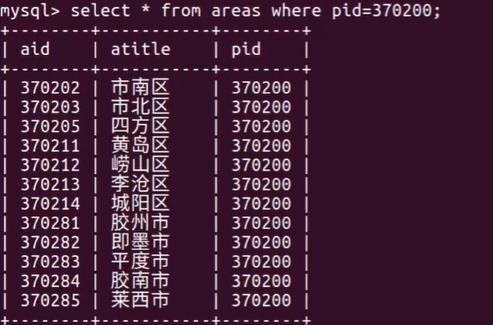
select * from areas as province inner join areas as city on city.pid=province.aid having province.atitle="江西";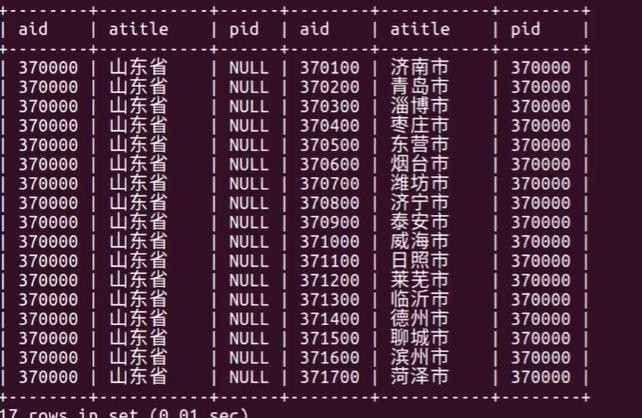
select province.atitle,city.atitle from areas as province inner join areas as city on city.pid=province.aid having province.atitle="江西"; 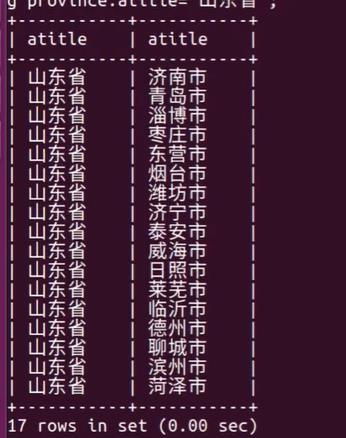
4.子查询
4.1标量子查询;
查询最高的男生信息
select * from students where height=(select max(height) from students);子查询即先执行子语句得到结论,再把这个结论当作条件再执行主语句;
对于:上面河北省自关联可以采用子查询解决:
select* from areas where pid = (select aid from areas where atitle=" 河北省");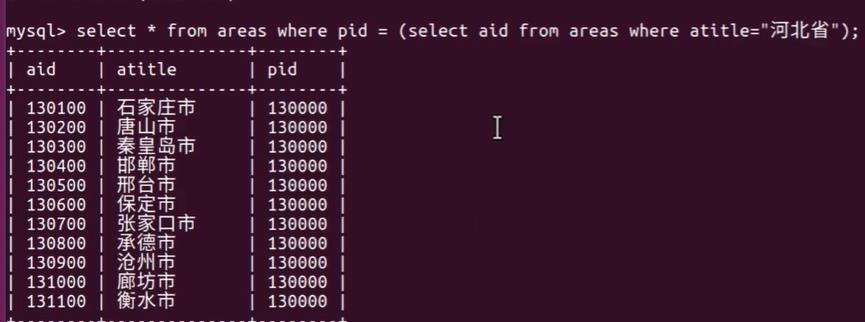
区别在于查询时间,子查询慢一点。
4.2列级子查询
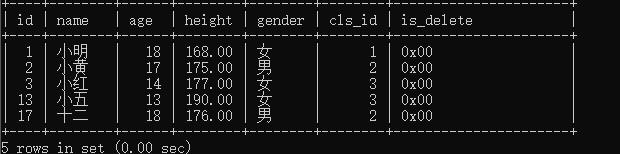
查询学生的班级号能对应学生的信息:
select * from students where cls_id in (select id from classes);
5.数据库设计
- 关系型数据库建议在E-R模型的基础上,我们需要根据产品经理的设计策划,抽取出来模型和关系,制定出表结构。
- 在开发中右很多设计数据库的软件,常用的入power designer,db designer等,这些软件可以只管得看到实体及实体间的关系。
- 设计数据库可能由专人来完成,也可能让开发组的人完成。
5.1 三范式
-
经过研究和对使用中的问题的总结,对于设计数据库提出了一些规范,这些规范称为范式。
-
目前有迹可循的共有8种范式,一般需要遵守3范式即
目前关系型数据库常用的六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。一般来说,数据库只需要满足第三范式就行了。
5.1.2 第一范式:保证每列的原子性
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库满足了第一范式。

一般来说"住址"设计成一个字段就行,但是如果经常访问"住址"中城市的部分,那么就非要将"住址"这个属性重新拆分为"省份"、"城市"、"地址"等多个部分进行存储,修改之后的表结构如图:

5.1.2 第二范式:保证一张表只描述一件事情
首先是1NF,另外包含两部分内容,一是表必须有一个主键【唯一区分】;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分
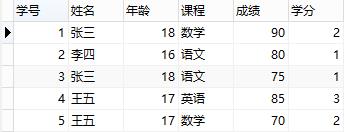
上表满足第一范式,即每个字段不可再分,但是这张表设计得并不好,或者说,这张表的设计并不满足第二范式。因为这张表里面描述了两件事情:学生信息、课程信息,"学分"完全依赖于"课程名称"、"姓名"与"年龄"完全依赖于"学号"。这么做的后果是:
1、数据冗余:同一门课程由n个学生选修,"学分"重复n-1次;同一个学生选修了m门课程,姓名和年龄重复m-1次
2、更新异常:若调整了某门课程的学分,数据表中所有行的"学分"值都需要更新,否则会出现同一门课程学分不同的情况
3、插入异常:假设要开一门新课程,暂时没有人选修,那么由于没有"学号"关键字,"课程"与"学分"也无法记录入数据库
4、删除异常:假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,"课程"和"学分"也被删除了,显然,这最终可能会导致插入异常
所以,此表的结构必须修改,修改后如下:
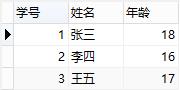

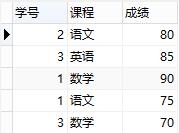
增加了表,将学生信息与课程信息通过一张中间表关联,很好地解决了上面的几个问题,这就是第二范式的中心----保证一张表只讲一件事情。
或者看下面例子:
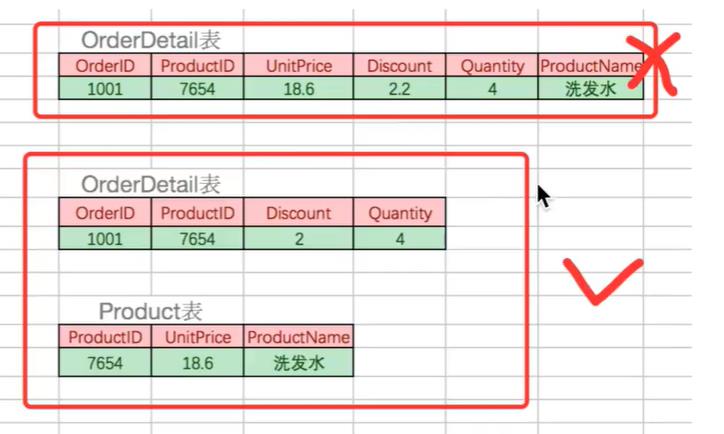
第一个表中,主键是允许有多个的;但是洗发水依赖于产品ID,不符合除主键外全部字段依赖主键;改成下面即可
5.1.3 第三范式----保证每列都和主键直接相关
首先是2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖,即不能存在:非主键列A依赖于非主键列B,非主键列B依赖于主键的情况。
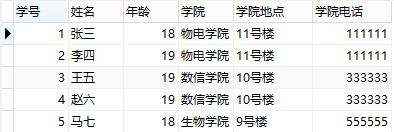
第三范式和第二范式有点像,从这张数据库表结构中可以看出,"姓名"、"年龄"、"学院"和主键"学号"直接关联,但是"学院地点"、"学院电话"却不直接和主键"学号"相关联,和"学院电话"直接相关联的是"学院",如果表结构这么设计,同样会造成和第二范式一样的数据冗余、更新异常、插入异常、删除异常的问题。
修改之后的表结构如下图:

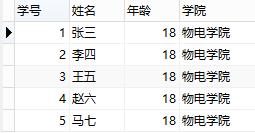
或者如下:

用户id依赖于产品id,但是用户信息是依赖于用户id再间接依赖产品id
最终表结构:
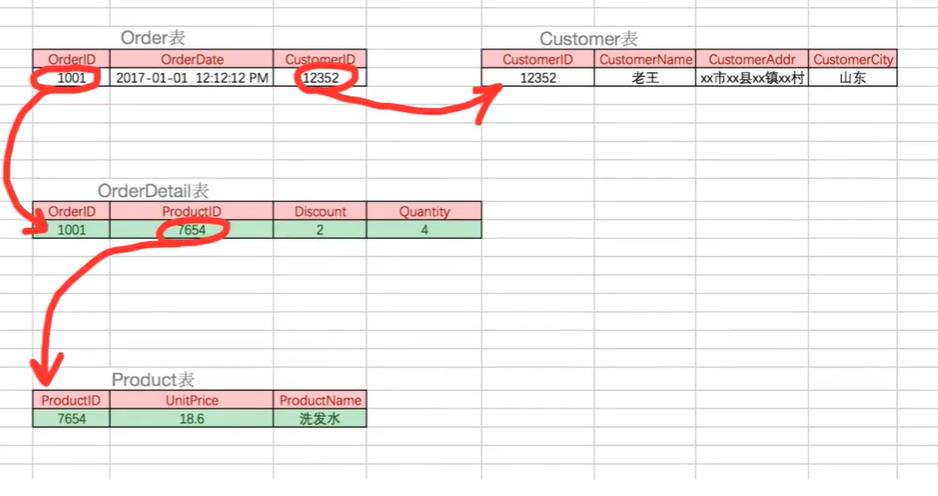
5.2 E-R模型:Entity-relationship model实体联系模型
基本的ER模型包含三类元素:实体、关系、属性
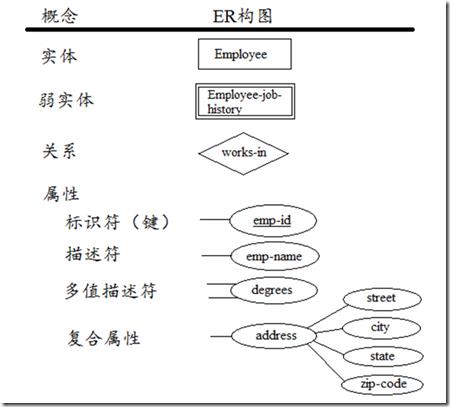
实体(Entities):实体是首要的数据对象,常用于表示一个人、地方、某样事物或某个事件。一个特定的实体被称为实体实例(entity instance或entity occurrence)。
关系(Relationships):关系表示一个或多个实体之间的联系。关系依赖于实体,一般没有物理概念上的存在。关系最常用来表示实体之间,一对一,一对多,多对多的对应。
属性(Attributes):属性为实体提供详细的描述信息。一个特定实体的某个属性被称为属性值。Employee实体的属性可能有:emp-id, emp-name, emp-address, phone-no……。属性可被分为两类:标识符(identifiers),描述符(descriptors)。Identifiers可以唯一标识实体的一个实例(key),可以由多个属性组成。ER图中通过在属性名下加上下划线来标识。多值属性(multivalued attributes)用两条线与实体连接,eg:hobbies属性(一个人可能有多个hobby,如reading,movies…)。复合属性(Complex attributes)本身还有其它属性。
辨别强实体与弱实体:强实体内部有唯一的标识符。弱实体(weak entities)的标识符来自于一个或多个其它强实体。弱实体用双线长方形框表示,依赖于强实体而存在。
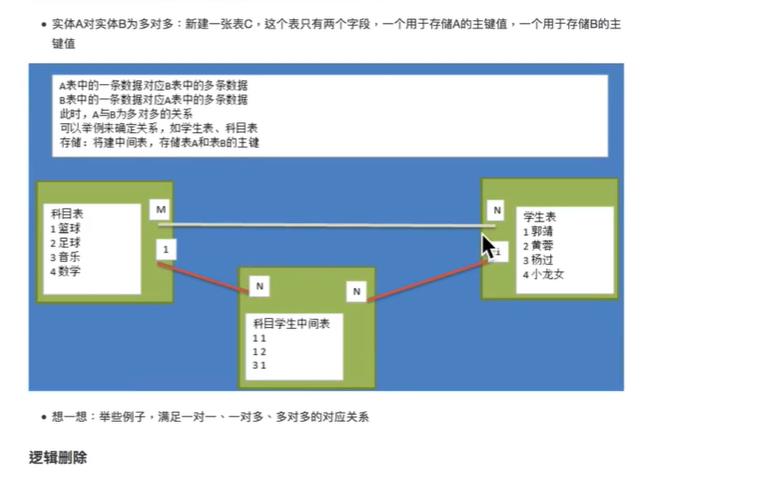
中间的表称谓聚合表
总结:设计数据库,先满足范式;在考虑是一对一,一对多,多对多的对应。
以上是关于MySQL---数据库查询详细教程{分页连接查询自关联子查询数据库设计规范}的主要内容,如果未能解决你的问题,请参考以下文章