学习笔记Spark—— 配置Spark IDEA开发环境
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Spark—— 配置Spark IDEA开发环境相关的知识,希望对你有一定的参考价值。
一、配置Spark开发环境
1. 1、配置Spark开发依赖包
- 创建一个Scala工程
(scala插件及工程创建教程:https://www.cnblogs.com/frankdeng/p/9092512.html) - 点击菜单栏中的“File”->“Project Structure”,打开右上图所示的界面
- 选择“Libraries”
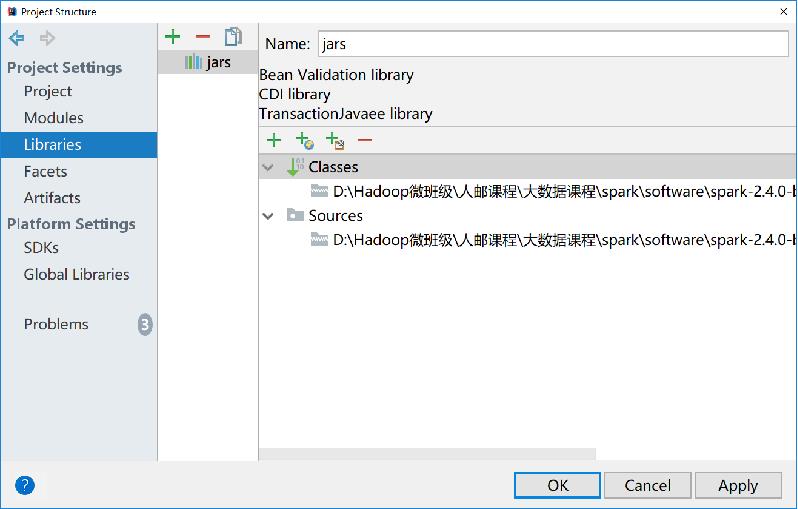
- 单击“+”按钮,选择“Java”选项
- 在弹出的界面中找到Spark安装包下的“jars”文件夹,事先删除该目录下的commons-compiler-3.0.9.jar
- 点击“OK”
二、编写Spark WordCount
2.1、SparkContext介绍
任何Spark程序都是以SparkContext对象开始的,因为SparkContext是Spark应用程序的上下文和入口,无论是Scala、Python、R程序,都是通过SparkContext对象的实例来创建RDD。
因此在实际Spark应用程序的开发中,在main方法中需要创建SparkContext对象,作为Spark应用程序的入口,并在Spark程序结束时关闭SparkContext对象。
2.1.1、初始化SparkContext
初始化SparkContext需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数,属性参数是一种键值对的格式,一般可以通过set(属性名,属性设置值)的方法修改属性。其中还包含了设置程序名setAppName、设置运行模式setMaster等方法。
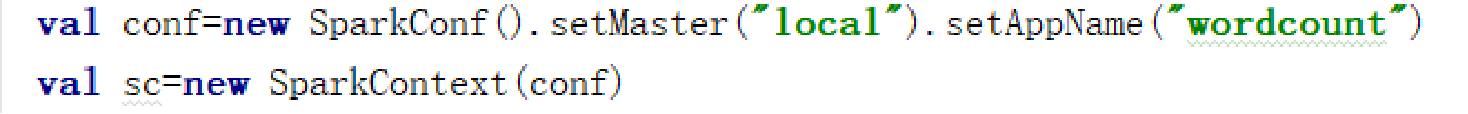
2.1.2、SparkSession
- SparkSession 是 spark2.x 引入的新概念,SparkSession 为用户提供统一的切入点
- SparkConf、SparkContext、SQLContext、HiveContext都已经被封装在SparkSession当中
SparkSession.builder
.master("local") \\\\设置运行模式
.appName("Word Count") \\\\设置名称
.config("spark.some.config.option", "some-value") \\\\设置集群配置
.enableHiveSupport() \\\\ 支持读取Hive
.getOrCreate()
2.2、Spark实现单词计数
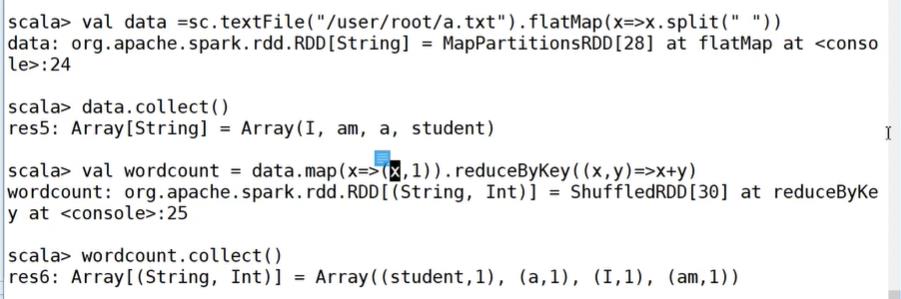
2.2.1、spark shell实现
2.2.2、使用本地模式运行Spark程序
数据:
Hello World Our World
Hello BigData Real BigData
Hello Hadoop Great Hadoop
Hadoop MapReduce
代码:
package demo.spark
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args:Array[String])={
val spark = SparkSession.builder().master("local").appName("wordcount").getOrCreate()
val sc = spark.sparkContext
val wordCount = sc.textFile("D:\\\\data\\\\words.txt")
.flatMap(x=>x.split(" "))
.map(x=>(x,1)).reduceByKey(_+_)
wordCount.foreach(x=>println(x))
}
}
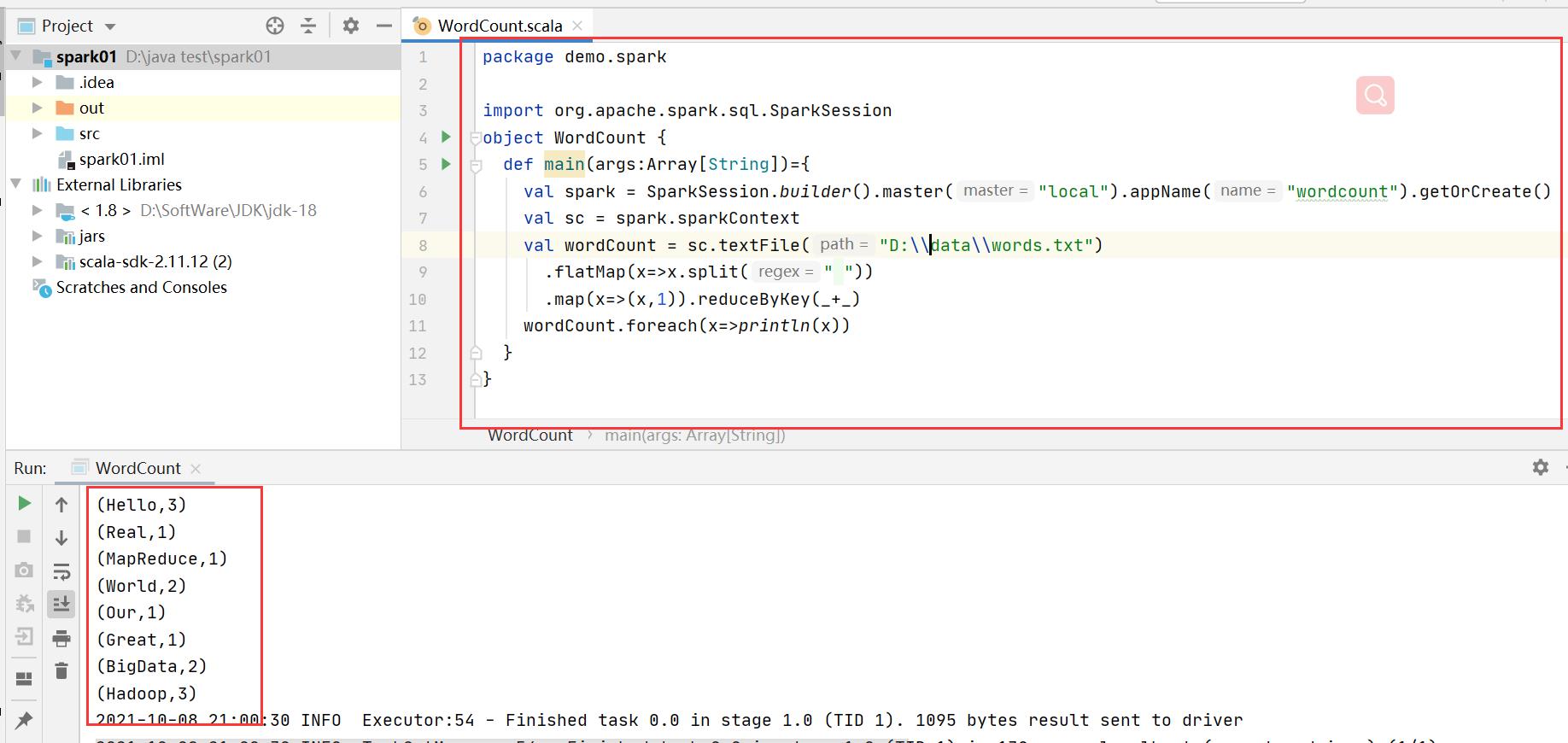
改成自己传参(文件路径,分隔符):

2.3、使用集群模式运行Spark程序
2.3.1、开发环境下运行Spark
- 点击“Run”→“Edit Configurations…”,弹出对话框如图所示
- 如果程序有自定义的输入参数,继续点击“Program arguments”参数值设置
2.3.2、提交程序到集群中运行
- 编写程序,可不设置运行模式
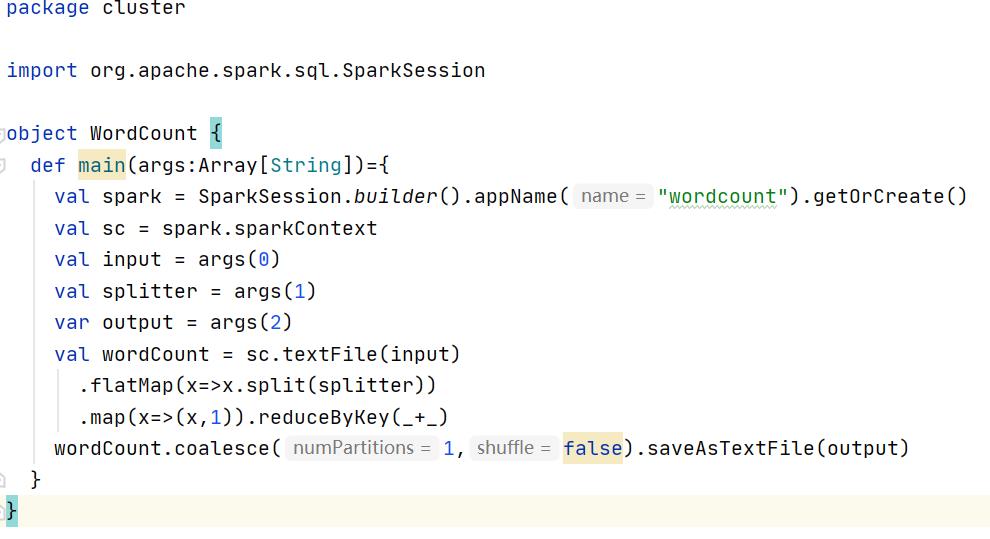
2.3.3、在IDEA中将程序打成jar包
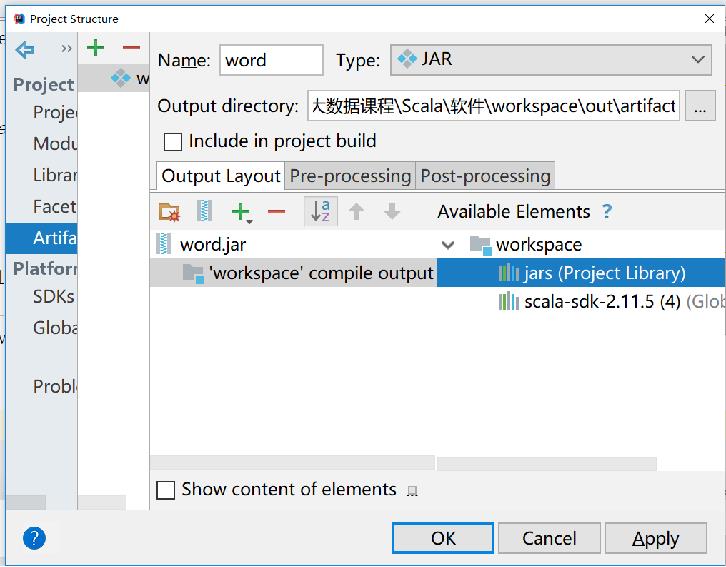
- 选择“File”→“Project Structure”命令
- 在弹出的对话框中选择“Artifacts”选项
- 选择“+”下的“JAR”选项中的“Empty”
- 在弹出的对话框(下图)中修改“Name”为自定义的JAR包的名字“word”,双击右侧栏工程下的“‘workspace’compile output”,它会转移到左侧,wordspace表示工程名
2.3.4、编译生成Artifact
- 选择菜单栏中的“Build”→“Build Artifacts”命令
- 在弹出的方框(右下图)中选择“word” →“build”
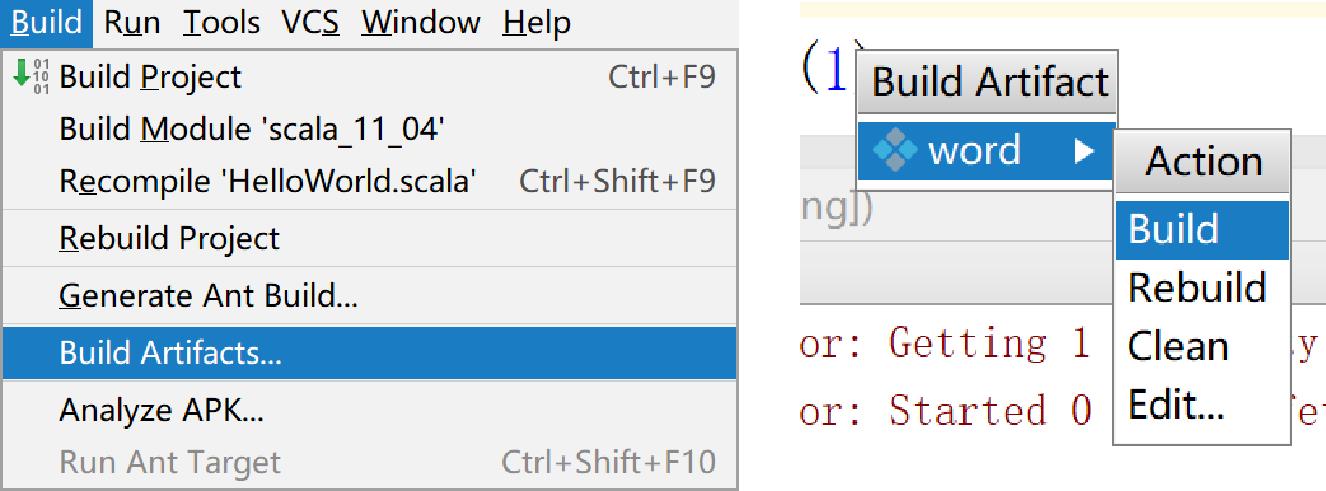
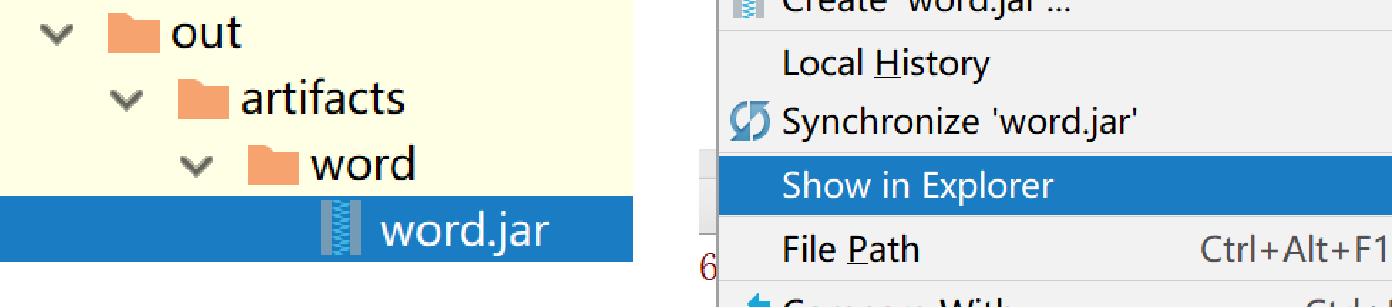
- 生成Artifact后,在工程目录中会有一个/out目录,可以看到生成的JAR包,如右上图所示
- 在JAR包处单击右键,在弹出菜单中选择“Show in Explorer”命令,直接到达JAR包路径下
2.3.5、上传jar包及相关文件
- 将JAR包上传到Linux的/opt目录下
- 将Windows本地的words.txt文件也上传到/opt目录下
- 将/opt/words.txt上传到HDFS的/user/root下
2.3.6、提交任务
spark-submit提交任务
spark-submit --master<master-url> \\
--deploy-mode <deploy-mode> \\
--conf <key>=<value> \\
... # other options
--class <main-class> \\
<application-jar> \\
application-arguments
参数解释:
--class:应用程序的入口点,指主程序。
--master:指定要连接的集群URL。
--deploy-mode:是否将驱动程序部署在工作节点(cluster)或本地作为外部客户端(client)。
--conf:设置任意Spark配置属性,即允许使用key=value格式设置任意的SparkConf配置选项。
application-jar:包含应用程序和所有依赖关系的捆绑JAR的路径。
application-arguments:传递给主类的main方法的参数。
运行模式

spark-submit运行示例
1、提交到yarn-cluster集群

- - -master设置运行模式为yarn-cluster集群模式
- - -class设置程序入口,然后设置JAR包路径,输入文件路径,输出文件路径,设置运行结果存储在HDFS
2、提交到spark集群
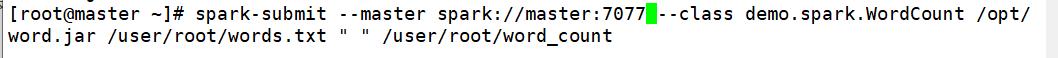
2.4、设置应用程序使用的集群资源
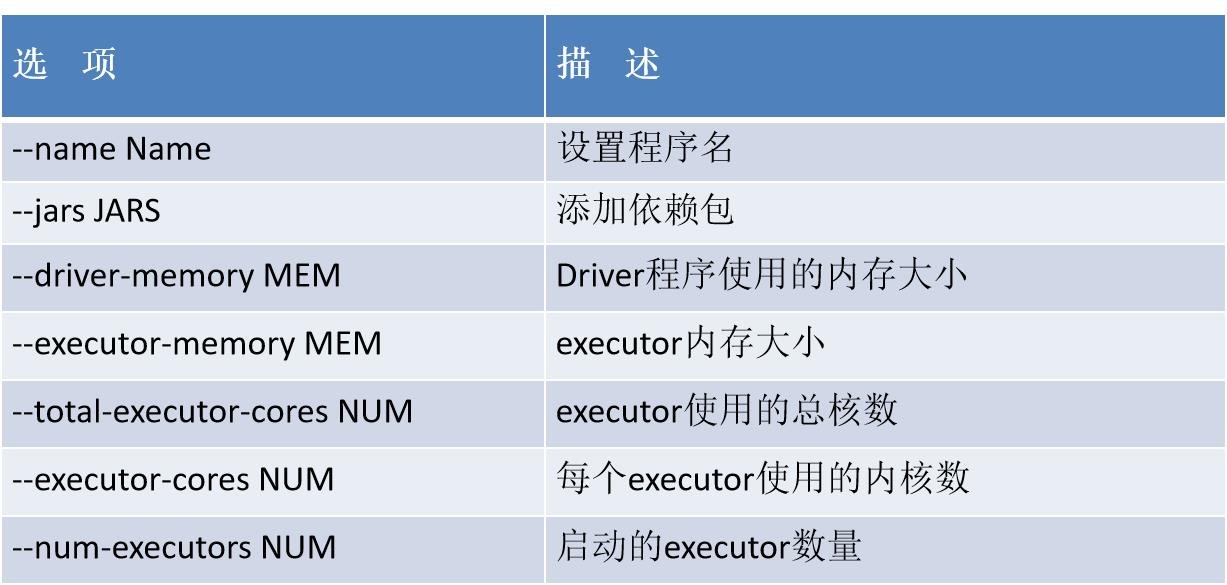
2.4.1、park-submit常用的配置项
2.4.2、设置spark-submit提交时的资源配置
设置spark-submit提交单词计数程序时的环境配置,设置运行时所启用的资源
spark-submit --master spark://master:7077 --executor-memory 512m --executor-cores 2 --class demo.spark.WordCount /opt/word.jar /user/root/words.txt " " /user/root/word_ count2

(浏览器:master:8080查看)

以上是关于学习笔记Spark—— 配置Spark IDEA开发环境的主要内容,如果未能解决你的问题,请参考以下文章