面试官:给你一段有问题的SQL,如何优化?
Posted 飘渺Jam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:给你一段有问题的SQL,如何优化?相关的知识,希望对你有一定的参考价值。
大家好,我是飘渺!
我在面试的时候很喜欢问候选人这样一个问题:“你在项目中遇到过慢查询问题吗?你是怎么做SQL优化的?”
很多时候,候选人会直接跟我说他们在编写SQL时会遵循的一些常用技巧,比如:
合理使用索引
使用UNION ALL替代UNION
不要使用select * 写法
JOIN字段建议建立索引
避免复杂SQL语句
这里不能说完全错误,因为这些技巧确实可以提高SQL运行效率;但是也不能说完全正确,毕竟我是想问他具体怎么是做SQL优化的。
接下来我问他,我这里有一段复杂的SQL,你可以动手帮我优化一下吗?到这一步的时候就有很多候选人做不好打了退堂鼓。他们有很扎实的理论知识,但是动手能力却差点火候。
今天这篇文章就从实战的角度出发,带大家走一遍SQL优化的真实流程。
找出有问题的SQL?
在实际开发中要判断一段SQL有没有问题可以从两方面来判断:
1、系统层面
CPU消耗严重
IO等待严重
页面响应时间过长
应用的日志出现超时等错误
2、SQL语句层面
冗长
执行时间过长
从全表扫描获取数据
执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,出现问题的频率肯定会更高。更进一步判断SQL问题就必须得从执行计划入手,如下所示:

执行计划告诉我们本次查询走了全表扫描Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
查看SQL执行计划?
找到了有问题的SQL就要确定优化方案,那究竟从何处下手呢?这里必须要通过执行计划来观察。
执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以mysql为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)
explain select * from xxx当使用explain sql后会看到执行计划

执行计划中几个重要字段的解释说明,大家需要记住
| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
通过执行计划我们就可以确定优化方案,优化一处后再回过头来观察执行计划,如此往复循环直到找到最优目标为止。
下面给出一段有问题的SQL具体操作一下。
SQL优化案例
慢查询
1、表结构如下:
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);2、有问题的查询SQL
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;a,b,c 三张表关联,查询用户17 在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列
优化步骤
1、先查看各表数据量

2、查看原执行时间,总耗时0.21s
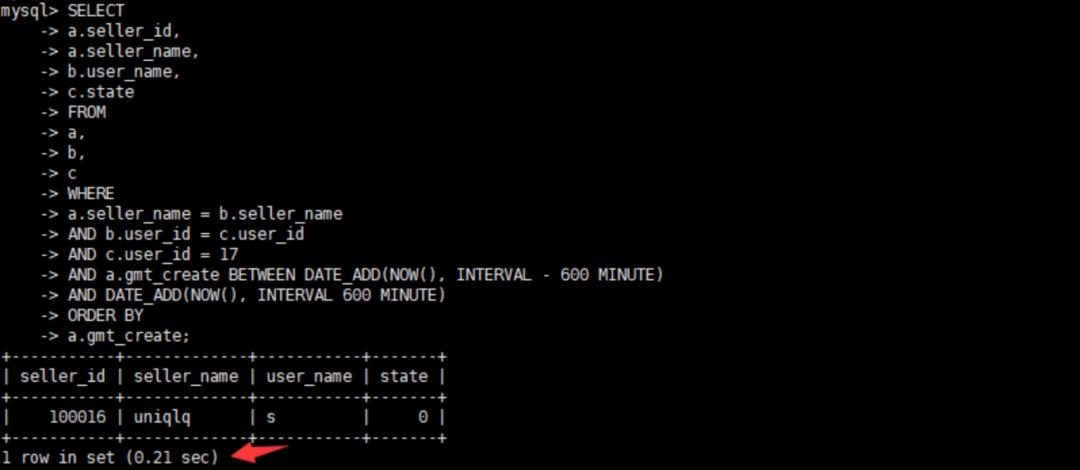
3、查看原执行计划
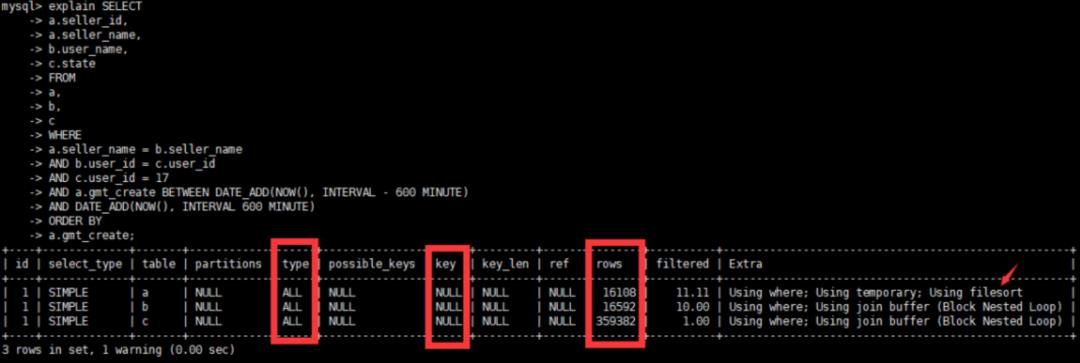
4、通过观察执行计划和SQL语句,确定初步优化方案
SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。因存在b表和c表关联,将b和c表
user_id创建索引因存在a表和b表关联,将a和b表
seller_name字段创建索引利用复合索引消除临时表和排序
初步优化的SQL:
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);查看优化后的执行时间
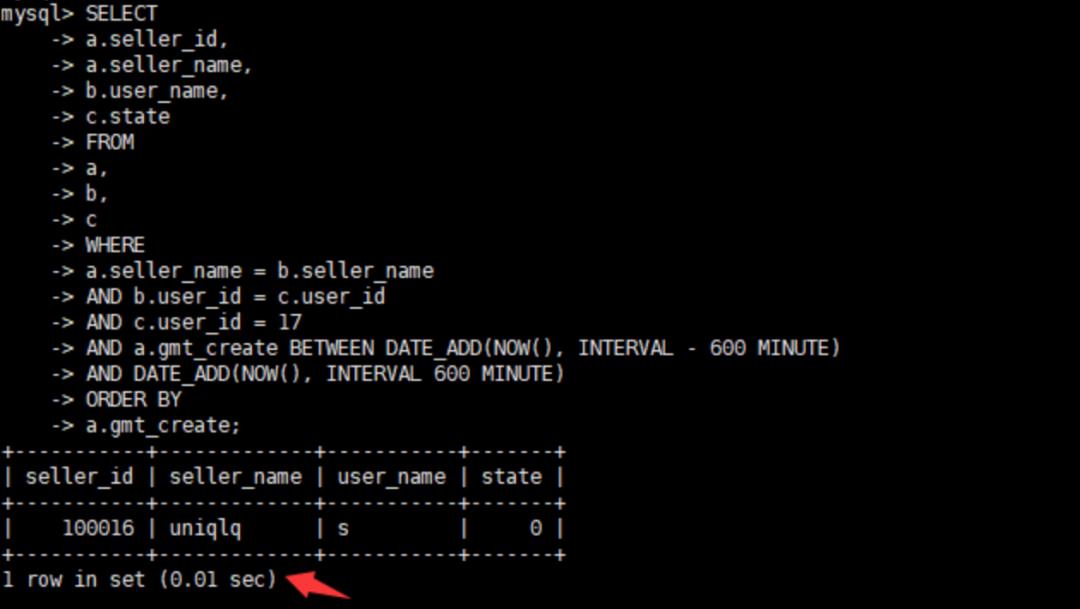
初步优化后执行速度提升了20倍,是否还能继续优化呢?
5、继续查看优化后的执行计划
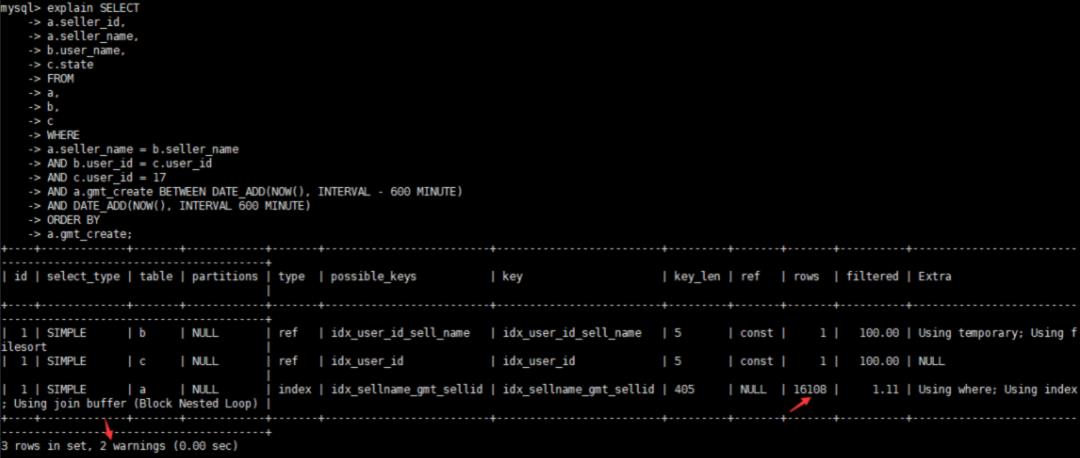
这里只看到查询需要扫描的元素比较大,不过还看到了有两处告警信息,直接查看告警信息
show warnings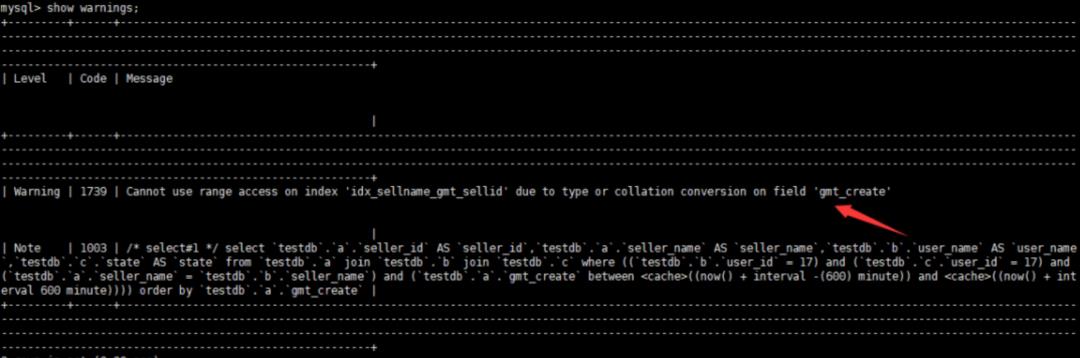
Cannot use range access on index ‘idx_sellname_gmt_sellid’ due to type or collation conversion on field ‘get_create’,这句话是告诉你由于gmt_create列发生了类型转换所以无法走索引。
查看SQL建表语句发现gmt_create字段被设计成了varchar类型,在SQL查询时需要转化成时间格式做查询,确实不能走索引。
所以需要调整一下gmt_create字段格式
alter table a modify "gmt_create" datetime DEFAULT NULL;6、修改字段后再来查看执行时间
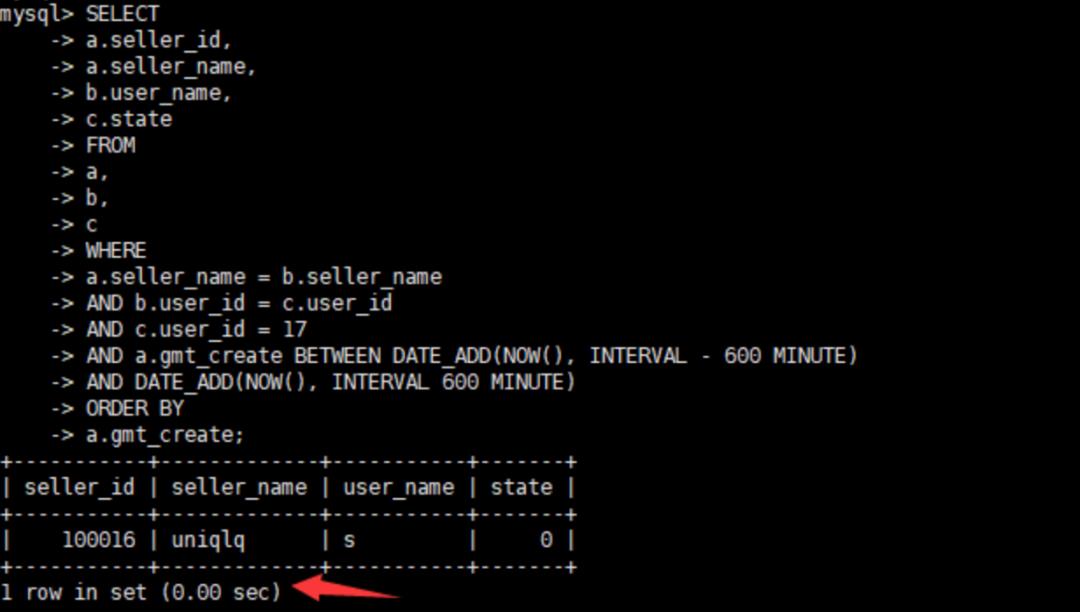
执行速度非常完美。
7、再观察优化后的执行计划
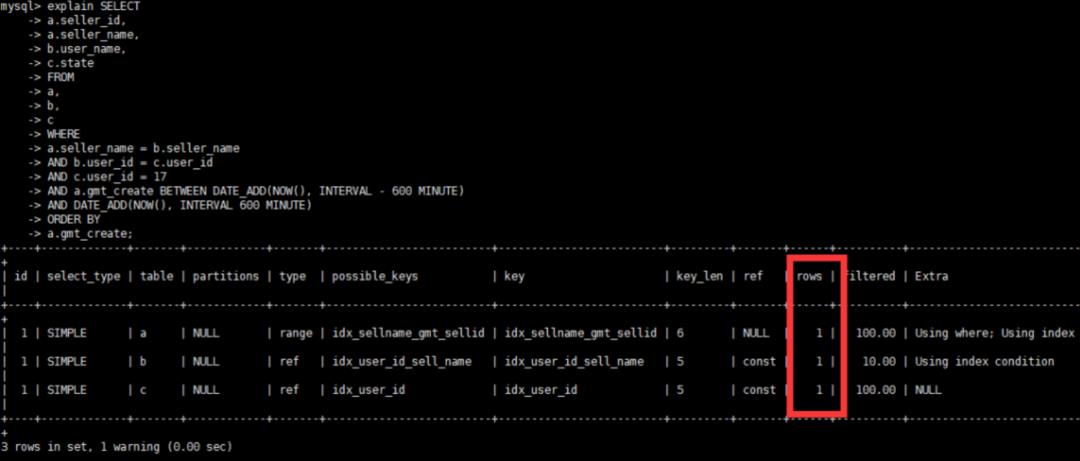
可以看到执行计划也很完美,至此SQL优化结束。
SQL优化小结
这里给大家总结一下优化SQL的套路,再也不怕面试官问你怎么做SQL优化的啦。
查看执行计划 explain
如果有告警信息,查看告警信息 show warnings;
查看SQL涉及的表结构和索引信息
根据执行计划,思考可能的优化点
按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
查看优化后的执行时间和执行计划
如果优化效果不明显,重复第四步操作
在看、点赞、转发,是对我最大的鼓励。您的支持就是我坚持下去的最大动力!
另外我的 知识星球 开通了,点击 知识星球 获取限量40元优惠券加入,每天不到3毛钱。目前更新了SpringCloud alibaba开发实战、Kubernetes云原生实战、分库分表实战、设计模式实战、一起学DDD 等,还有每周的送书活动等着你....

以上是关于面试官:给你一段有问题的SQL,如何优化?的主要内容,如果未能解决你的问题,请参考以下文章