FlinkIcebergHive元数据互通性研究
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkIcebergHive元数据互通性研究相关的知识,希望对你有一定的参考价值。
今日原则
不需要任何人的理解或引导,自然选择的试错过程就能实现改进。我们进行的学习也是这个道理。至少有三种学习能促进进化:以记忆为基础的学习(有意识地储存不断出现的信息,以便以后可以记起来);潜意识的学习(从未进入意识的,我们从经验中习得的知识,但也会影响我们的决策);与人类思考无关的“学习”,例如记录物种适应进程的基因的进化。我曾以为以记忆为基础的有意识的学习是最有力的,但后来我明白,试验和适应能带来更快的进步。
举个例子说明自然是如何不依靠思考而进步的,只需看看(能思考的)人类与(连大脑都没有的)病毒斗智斗勇的过程。病毒就像是聪明的国际象棋对手。病毒飞快地进化(通过将不同种类病毒的遗传物质结合在一起),让全球卫生领域里最聪明的人们忙的不可开交,不断思索对付病毒的方法。在当今这个时代,理解这一点尤为有用,因为今天的计算机可以运行大量展现进化过程的模拟程序,帮助我们看到什么是有效的,而什么又是无效的。
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink and Hive using a high-performance table format that works just like a SQL table.
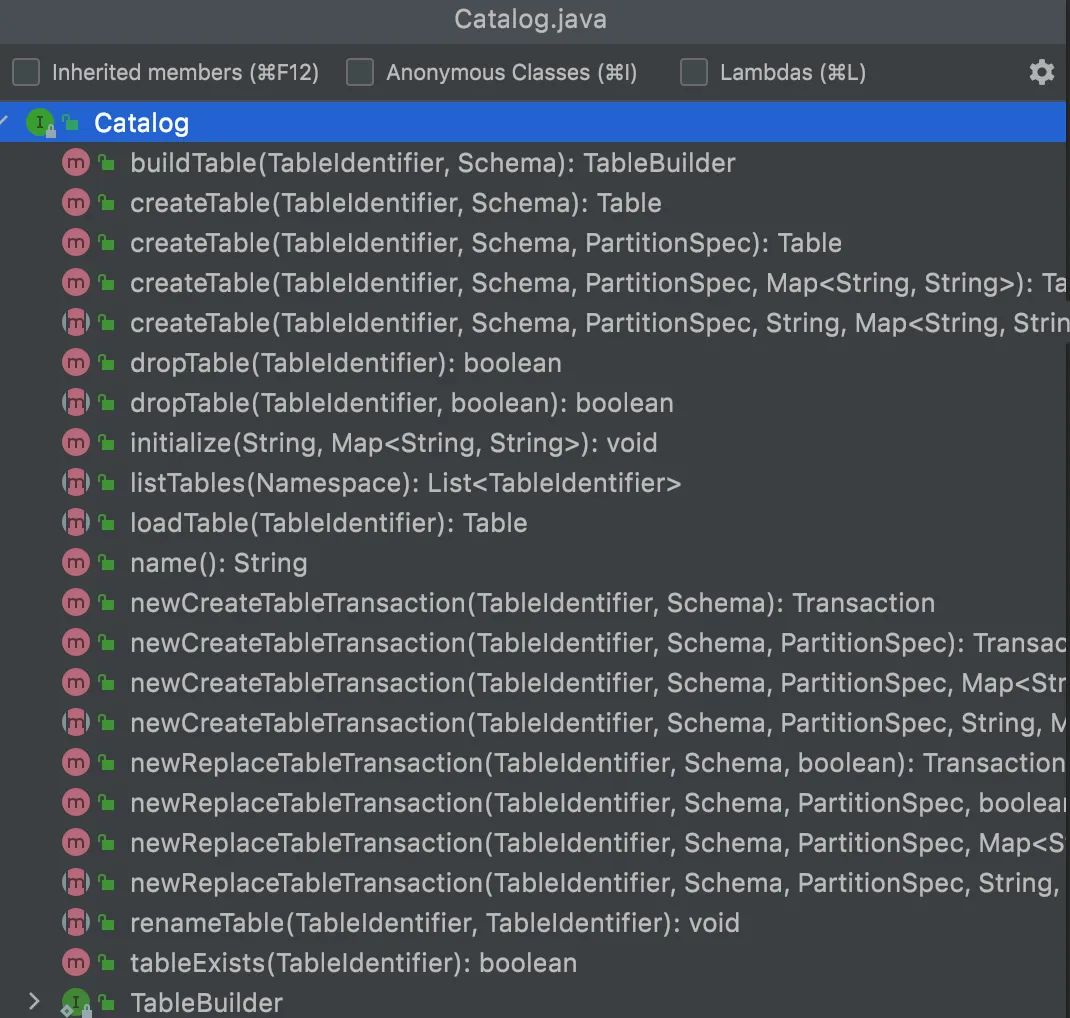
Iceberg作为一种表格式,定义了数据、元数据的组织方式,构建在数据存储格式之上,向上提供统一的“表”的语义。Iceberg通过Catalog来组织所有表,并提供了Catalog API接口来管理这些表,所谓Catalog就是一系列创建、删除、加载表的操作API(A Catalog API for table create, drop, and load operations)。从Catalog 接口可知常见的操作,如下图所示:
从Catalog接口可见,它将传统的用二元组(database,table)来标识表扩展为名字空间,并用实体TableIdentifier来标识:
public class TableIdentifier {
private final Namespace namespace;
private final String name;
public static TableIdentifier of(String... names) {
return new TableIdentifier(Namespace.of(Arrays.copyOf(names, names.length - 1)), names[names.length - 1]);
}
public static TableIdentifier of(Namespace namespace, String name) {
return new TableIdentifier(namespace, name);
}
private TableIdentifier(Namespace namespace, String name) {
this.namespace = namespace;
this.name = name;
}
}名字空间数组Namespace第一项默认为database,比如TableIdentifier.of("db", "ns1","ns2", "tbl")构造的表标识Namespace为["db", "ns1","ns2"],表名字为tbl,其中Namespace数组第一项默认为数据库名。
Iceberg元数据操作
Catalog元数据本身既可以存储到Hadoop HDFS文件系统也可以存储在Hive Metastore(HMS),前者提供元数据的分布式存储解决方案。下面代码是基于HadoopCatalog的存储方式示例:
File warehouse = new File("warehouse");
String warehouseLocation = warehouse.getAbsolutePath();
HadoopCatalog hadoopCatalog = new HadoopCatalog(new Configuration(), warehouseLocation);
TableIdentifier tbl1 = TableIdentifier.of("db", "tbl1");
TableIdentifier tbl2 = TableIdentifier.of("db", "tbl2");
TableIdentifier tbl3 = TableIdentifier.of("db", "ns1", "tbl3");
TableIdentifier tbl4 = TableIdentifier.of("db", "metadata", "metadata");
Lists.newArrayList(tbl1, tbl2, tbl3, tbl4).forEach(t ->
hadoopCatalog.buildTable(t, SCHEMA)
.withPartitionSpec(PartitionSpec.unpartitioned())
.create());
List<TableIdentifier> tbls1 = hadoopCatalog.listTables(Namespace.of("db"));
Table table = hadoopCatalog.loadTable(tbl1);
Set<String> tblSet = Sets.newHashSet(tbls1.stream().map(t -> t.name()).iterator());构造HadoopCatalog需要提供Configuration配置Hadoop的属性信息和warehouse Location位置信息,Location这里用本地文件系统目录来代替远程hdfs文件,本地目录结构演示如下:
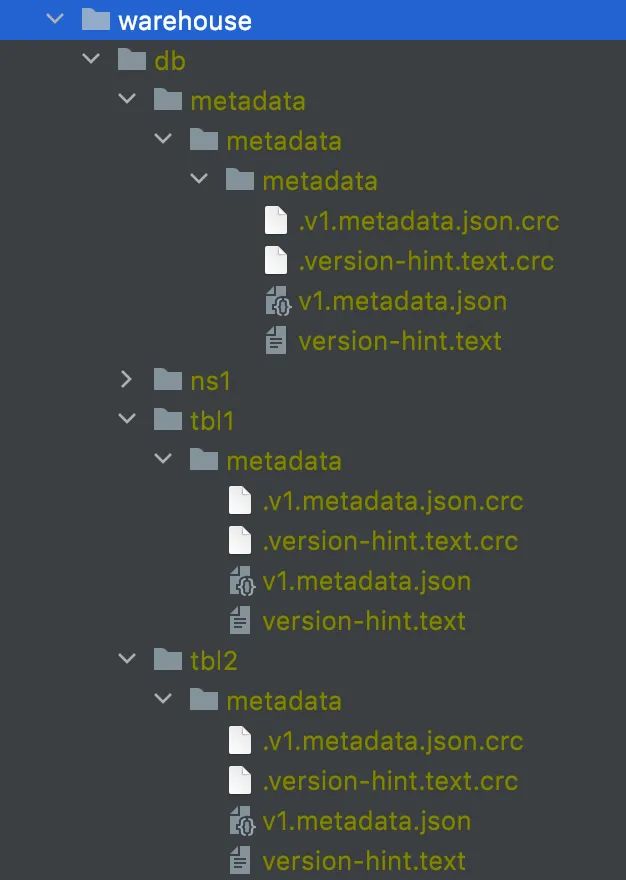
其中最后一级目录metadata即为Iceberg表的元数据所在目录。下面代码是基于HiveCatalog的加载表的方式示例:
Map<String, String> properties = new HashMap<>();
properties.put("type", "iceberg");
properties.put("property-version", "1");
properties.put("warehouse", parameterTool.get("warehouse"));
String catalogType = parameterTool.get("catalog_type","hive");
CatalogLoader catalogLoader = null;
properties.put("catalog-type", catalogType);
String thriftUri=String.format("thrift://localhost:%s", parameterTool.get("port","51846"));
properties.put("uri",thriftUri);
String HIVE_CATALOG = "iceberg_hive_catalog";
catalogLoader = CatalogLoader.hive(HIVE_CATALOG, new Configuration(), properties);
Catalog catalog = catalogLoader.loadCatalog();
TableIdentifier tableIdentifier =
TableIdentifier.of(Namespace.of(parameterTool.get("hive_db")), parameterTool.get("hive_table"));
Table table = catalog.loadTable(tableIdentifier);
TableOperations operations = ((BaseTable) table).operations();
TableMetadata metadata = operations.current();
TableLoader tableLoader = TableLoader.fromCatalog(catalogLoader, tableIdentifier);示例中创建了一个通用的CatalogLoader,它能够根据指定参数来创建HadoopCatalog或者HveCatalog。如果是HveCatalog,需要提供的基本属性为:

如果是HadoopCatalog,需要提供的基本属性为:

其中type,catalog-type,uri和warehouse必选。基于HveCatalog创建的表,按照Hive Metastore兼容的格式存储表的字段、分区、属性等基本信息,而跟Iceberg有关的表元数据信息仍然存储在warehouse指定的目录文件里面,比如下面图中示例表的创建语句:
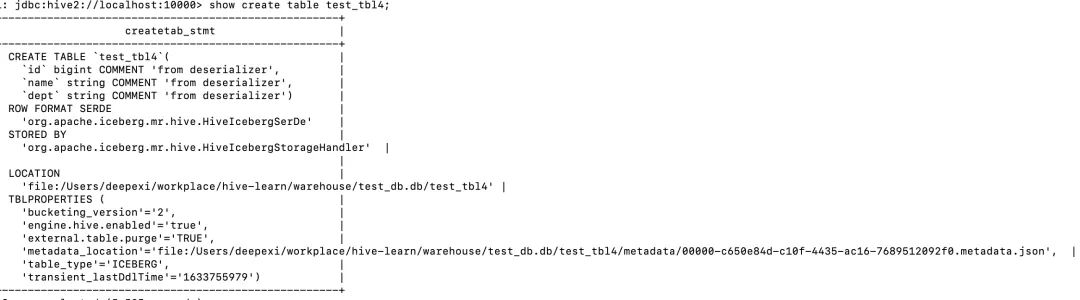
其中比较重要的属性metadata_location指向了Iceberg表的元数据文件路径,基于此属性,就可以通过HMS定位到Iceberg表的所有信息。
Iceberg通过上述SDK提供了操作表的接口,从而统一不同的计算引擎使用入口,下面结合常用的Flink和Hive来看,它们如何跟Iceberg元数据打通。
Flink操作Iceberg元数据
下表列举了Flink 1.11.x支持的SQL操作:
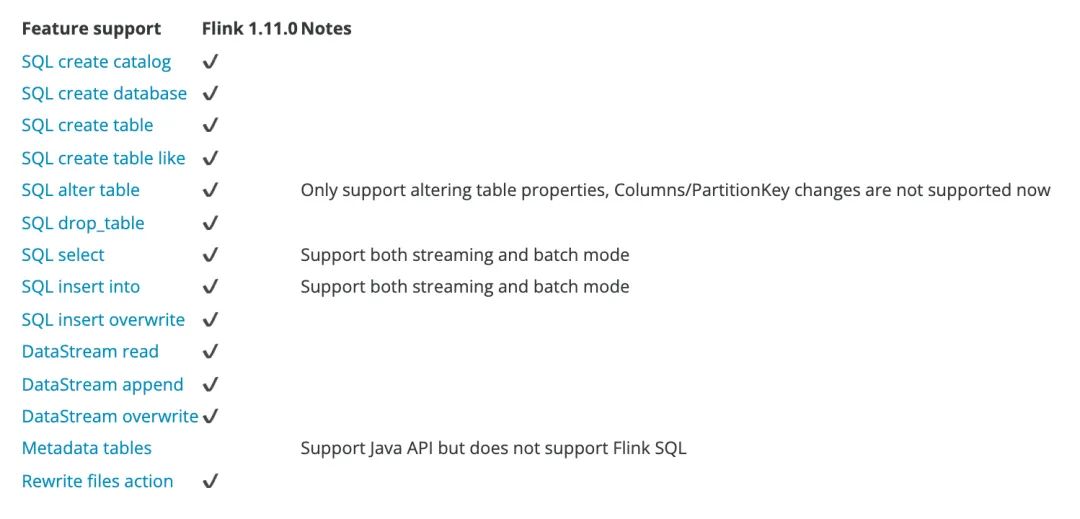
下面代码是Flink 创建HadoopCatalog Iceberg的示例:
String createCartalogSql="CREATE CATALOG hadoop_catalog WITH (" +
"'type'='iceberg',"+
"'catalog-type'='hadoop'," +
String.format("'warehouse'='%s',",warehouseLocation)+
"'property-version'='1'"+
")";
System.out.println(createCartalogSql);
tableEnvironment.executeSql(createCartalogSql);
tableEnvironment.executeSql("USE catalog hadoop_catalog");
tableEnvironment.executeSql("CREATE DATABASE iceberg_db");
tableEnvironment.executeSql("USE iceberg_db");
tableEnvironment.executeSql("CREATE TABLE `hadoop_catalog`.`iceberg_db`.`sample` (" +
"id BIGINT COMMENT 'unique id'," +
"data STRING" +
")");
String [] tables=tableEnvironment.listTables();
TableLoader tableLoader = TableLoader.fromHadoopTable(warehouseLocation+"/iceberg_db/sample");
tableLoader.open();
Table table=tableLoader.loadTable();
Flink 读取Hadoop Iceberg
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable(warehouseLocation+"/iceberg_db/sample");
DataStream<RowData> batch = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false)
.build();
// Print all records to stdout.
batch.print();
// Submit and execute this batch read job.
env.execute("Test Iceberg Batch Read");
Flink 写入Hadoop Iceberg
StreamExecutionEnvironment env = ...;
DataStream<RowData> input = ... ;
Configuration hadoopConf = new Configuration();
TableLoader tableLoader = TableLoader.fromHadoopTable(warehouseLocation+"/iceberg_db/sample", hadoopConf);
FlinkSink.forRowData(input)
.tableLoader(tableLoader)
.build();
env.execute("Test Iceberg DataStream");Hive操作Iceberg元数据
下表列举了Hive不同版本支持的SQL功能,最新Hive版本基于3.1.2。

从Hive引擎视角来看,它只有一个全局的运行时Catalog概念,而Iceberg可以支持不同的Catalog类型,Hive、Hadoop、第三方厂商的Catalog如AWS Glue和自定义Catalog。在实际应用场景中,Hive可能使用上述任意Catalog,甚至跨不同Catalog类型join数据,为此Hive提供了org.apache.iceberg.mr.hive.HiveIcebergStorageHandler(位于包iceberg-hive-runtime.jar)来支持读写Iceberg表,并通过iceberg.catalog属性来决定加载Iceberg表的方式。

上图说明了如何注册不同类型的Catalog,下面根据不同的使用方式举例说明。
1. 如果iceberg.catalog属性没有设置,默认使用HiveCatalog来加载
SET iceberg.catalog.another_hive.type=hive;
SET iceberg.catalog.another_hive.uri=thrift://localhost:55452;
SET iceberg.catalog.another_hive.clients=10;
SET iceberg.catalog.another_hive.warehouse=/Users/deepexi/workplace/hive-learn/warehouse;
CREATE TABLE test_db.test_tbl1 (
id bigint, name string
) PARTITIONED BY (
dept string
) STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';2. 如果iceberg.catalog属性设置了catalog名字,就用对应类型的catalog加载
SET iceberg.catalog.hadoop_cat.type=hadoop;
SET iceberg.catalog.hadoop_cat.warehouse=/Users/deepexi/workplace/hive-learn/hadoop_cat;
CREATE TABLE test_db.test_tbl2(
id bigint, name string
)
PARTITIONED BY (
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES ('iceberg.catalog'='hadoop_cat');3. 如果iceberg.catalog属性设置为location_based_table,就用HadoopCatalog从指定的location加载
CREATE TABLE test_db.test_tbl3 (
id bigint, name string
)
PARTITIONED BY (
dept string
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION '/Users/deepexi/workplace/hive-learn/warehouse/test_db/test_tbl3'
TBLPROPERTIES ('iceberg.catalog'='location_based_table');小结
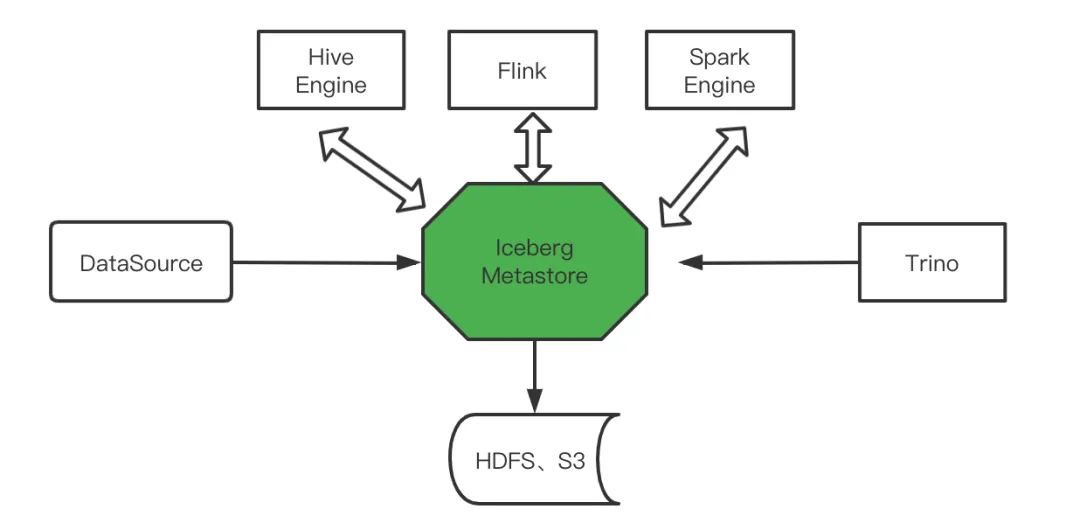
Iceberg作为开放的数据存储组织格式,衔接了数据存储和计算引擎,并且以一种通用的元数据存储方案出现,展现出相对于Hive Metastore更大的优势,比如支持元数据的分布式存储和扩展能力,在系统部署上排除了对HMS的依赖,降低了系统的复杂度。除此之外,Iceberg丰富的、更细粒度的统计元数据为上层应用提供更多的可能,因此基于HDFS(S3)等分布式系统存储的元数据系统方案是一个值得探索的方案,如下图中可以Iceberg SDK创建相应数据源的存储表并导入数据之后,再借助各种分布式计算引擎对数据进行消费处理,结果元数据既可以通过它们跟Iceberg互通的元数据操作能力,也可以基于Iceberg SDK创建表的方式注册到Iceberg Metastore,数据本身存储在独立的分布式文件(对象)系统中,而数据查询依然可以原生地通过Trino访问Iceberg Metastore。
参考链接
https://iceberg.apache.org/flink/
https://iceberg.apache.org/hive/
以上是关于FlinkIcebergHive元数据互通性研究的主要内容,如果未能解决你的问题,请参考以下文章