Facebook宕机的经验
Posted bisal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Facebook宕机的经验相关的知识,希望对你有一定的参考价值。
社交大佬Facebook最近有点烦,因为在美国当地时间4日清晨,有用户反映,再也无法刷新Facebook诸多社交网站,涉及到全球数十个国家和地区的用户,直到宕机近7个小时后,美国当地时间下午三点,Facebook、Instagram等诸多产品才恢复正常访问。
当地时间5日,Facebook表示4号一度出现大范围宕机故障的原因,是工程师错误地发出了一条指令,导致了错误的配置更改,切断了FB的数据中心在全球范围内的所有网络连接,但是目前没有证据表明用户数据因宕机而被泄露。
这个解释是否准确我们无从知晓,作为普通IT从业的人员,最感兴趣的可能是另外一条消息,Theverge网站的高级编辑在Twitter上表示,因为Facebook系统崩溃,安全门禁卡失效,工程师只能带着角磨机器强行锯开数据中心的服务器铁笼。
作为全球顶尖的互联网公司,自动化运维水平可能已经到了大多数IT公司不能企及的高度,或者说“自动化”已经不太准确了,“智能化”更合适,毕竟面对全球顶级的访问流量,靠“人”运维,不太现实,但是"智能"肯定还得有个度,或者至少得有一种能让“人”接管的路径,上面说的“锯子撬铁笼”的段子我不知道是真是假,当然不用怀疑Facebook对各种的异常场景的应急预案是否充分,只是借着这个事情让我们能了解,人工、自动、智能,这几个之间还是需要一定配合的,单纯靠某个,都是不太靠谱的,或者说存在不适用的场景,因此无论是开发、测试、运维,我们在设计时,还是要综合考量,我们不可能穷举出所有的场景,适当的应急方案,或者说降级方案,有时还是需要的。
这篇文章《Understanding How Facebook Disappeared from the Internet》,从技术上还原了整个故障,还是比较清楚的,虽然是英文,基本都是简单的词汇,有兴趣的朋友,可以了解下。
原文链接:https://blog.cloudflare.com/october-2021-facebook-outage/

“Facebook can't be down, can it?”, we thought, for a second.
Today at 15:51 UTC, we opened an internal incident entitled "Facebook DNS lookup returning SERVFAIL" because we were worried that something was wrong with our DNS resolver 1.1.1.1. But as we were about to post on our public status page we realized something else more serious was going on.
Social media quickly burst into flames, reporting what our engineers rapidly confirmed too. Facebook and its affiliated services WhatsApp and Instagram were, in fact, all down. Their DNS names stopped resolving, and their infrastructure IPs were unreachable. It was as if someone had "pulled the cables" from their data centers all at once and disconnected them from the Internet.
This wasn't a DNS issue itself, but failing DNS was the first symptom we'd seen of a larger Facebook outage.
How's that even possible?
Update from Facebook
Facebook has now published a blog post giving some details of what happened internally. Externally, we saw the BGP and DNS problems outlined in this post but the problem actually began with a configuration change that affected the entire internal backbone. That cascaded into Facebook and other properties disappearing and staff internal to Facebook having difficulty getting service going again.
Facebook posted a further blog post with a lot more detail about what happened. You can read that post for the inside view and this post for the outside view.
Now on to what we saw from the outside.
Meet BGP
BGP stands for Border Gateway Protocol. It's a mechanism to exchange routing information between autonomous systems (AS) on the Internet. The big routers that make the Internet work have huge, constantly updated lists of the possible routes that can be used to deliver every network packet to their final destinations. Without BGP, the Internet routers wouldn't know what to do, and the Internet wouldn't work.
The Internet is literally a network of networks, and it’s bound together by BGP. BGP allows one network (say Facebook) to advertise its presence to other networks that form the Internet. As we write Facebook is not advertising its presence, ISPs and other networks can’t find Facebook’s network and so it is unavailable.
The individual networks each have an ASN: an Autonomous System Number. An Autonomous System (AS) is an individual network with a unified internal routing policy. An AS can originate prefixes (say that they control a group of IP addresses), as well as transit prefixes (say they know how to reach specific groups of IP addresses).
Cloudflare's ASN is AS13335. Every ASN needs to announce its prefix routes to the Internet using BGP; otherwise, no one will know how to connect and where to find us.
Our learning center has a good overview of what BGP and ASNs are and how they work.
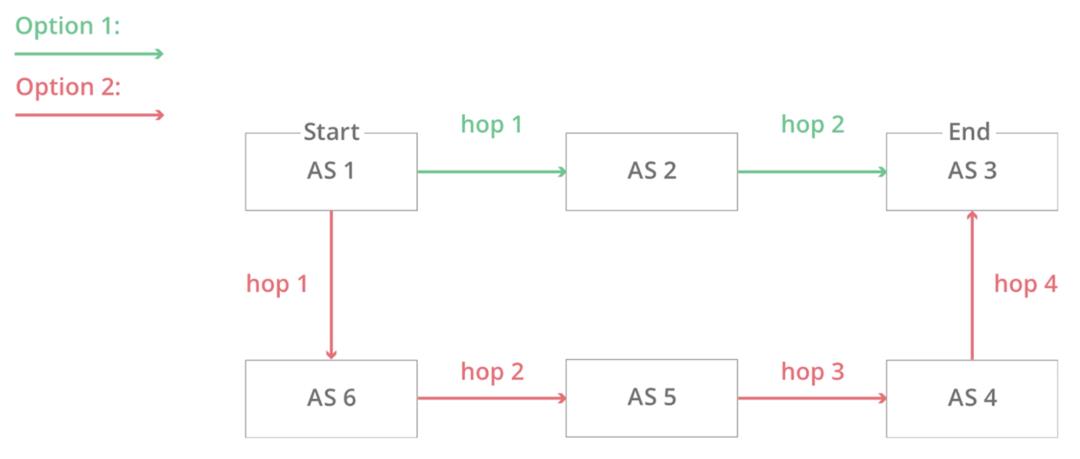
In this simplified diagram, you can see six autonomous systems on the Internet and two possible routes that one packet can use to go from Start to End. AS1 → AS2 → AS3 being the fastest, and AS1 → AS6 → AS5 → AS4 → AS3 being the slowest, but that can be used if the first fails.
At 15:58 UTC we noticed that Facebook had stopped announcing the routes to their DNS prefixes. That meant that, at least, Facebook’s DNS servers were unavailable. Because of this Cloudflare’s 1.1.1.1 DNS resolver could no longer respond to queries asking for the IP address of facebook.com.
route-views>show ip bgp 185.89.218.0/23
% Network not in table
route-views>
route-views>show ip bgp 129.134.30.0/23
% Network not in table
route-views>Meanwhile, other Facebook IP addresses remained routed but weren’t particularly useful since without DNS Facebook and related services were effectively unavailable:
route-views>show ip bgp 129.134.30.0
BGP routing table entry for 129.134.0.0/17, version 1025798334
Paths: (24 available, best #14, table default)
Not advertised to any peer
Refresh Epoch 2
3303 6453 32934
217.192.89.50 from 217.192.89.50 (138.187.128.158)
Origin IGP, localpref 100, valid, external
Community: 3303:1004 3303:1006 3303:3075 6453:3000 6453:3400 6453:3402
path 7FE1408ED9C8 RPKI State not found
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
route-views>We keep track of all the BGP updates and announcements we see in our global network. At our scale, the data we collect gives us a view of how the Internet is connected and where the traffic is meant to flow from and to everywhere on the planet.
A BGP UPDATE message informs a router of any changes you’ve made to a prefix advertisement or entirely withdraws the prefix. We can clearly see this in the number of updates we received from Facebook when checking our time-series BGP database. Normally this chart is fairly quiet: Facebook doesn’t make a lot of changes to its network minute to minute.
But at around 15:40 UTC we saw a peak of routing changes from Facebook. That’s when the trouble began.

If we split this view by routes announcements and withdrawals, we get an even better idea of what happened. Routes were withdrawn, Facebook’s DNS servers went offline, and one minute after the problem occurred, Cloudflare engineers were in a room wondering why 1.1.1.1 couldn’t resolve facebook.com and worrying that it was somehow a fault with our systems.

With those withdrawals, Facebook and its sites had effectively disconnected themselves from the Internet.
DNS gets affected
As a direct consequence of this, DNS resolvers all over the world stopped resolving their domain names.
➜ ~ dig @1.1.1.1 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @1.1.1.1 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
➜ ~ dig @8.8.8.8 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @8.8.8.8 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN AThis happens because DNS, like many other systems on the Internet, also has its routing mechanism. When someone types the https://facebook.com URL in the browser, the DNS resolver, responsible for translating domain names into actual IP addresses to connect to, first checks if it has something in its cache and uses it. If not, it tries to grab the answer from the domain nameservers, typically hosted by the entity that owns it.
If the nameservers are unreachable or fail to respond because of some other reason, then a SERVFAIL is returned, and the browser issues an error to the user.
Again, our learning center provides a good explanation on how DNS works.
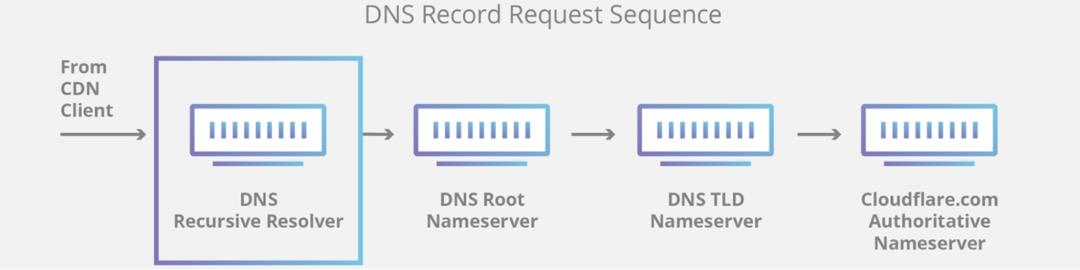
Due to Facebook stopping announcing their DNS prefix routes through BGP, our and everyone else's DNS resolvers had no way to connect to their nameservers. Consequently, 1.1.1.1, 8.8.8.8, and other major public DNS resolvers started issuing (and caching) SERVFAIL responses.
But that's not all. Now human behavior and application logic kicks in and causes another exponential effect. A tsunami of additional DNS traffic follows.
This happened in part because apps won't accept an error for an answer and start retrying, sometimes aggressively, and in part because end-users also won't take an error for an answer and start reloading the pages, or killing and relaunching their apps, sometimes also aggressively.
This is the traffic increase (in number of requests) that we saw on 1.1.1.1:
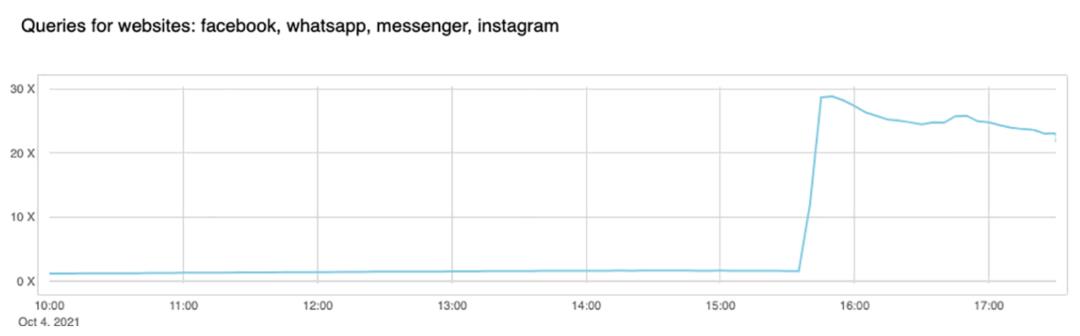
So now, because Facebook and their sites are so big, we have DNS resolvers worldwide handling 30x more queries than usual and potentially causing latency and timeout issues to other platforms.
Fortunately, 1.1.1.1 was built to be Free, Private, Fast (as the independent DNS monitor DNSPerf can attest), and scalable, and we were able to keep servicing our users with minimal impact.
The vast majority of our DNS requests kept resolving in under 10ms. At the same time, a minimal fraction of p95 and p99 percentiles saw increased response times, probably due to expired TTLs having to resort to the Facebook nameservers and timeout. The 10 seconds DNS timeout limit is well known amongst engineers.
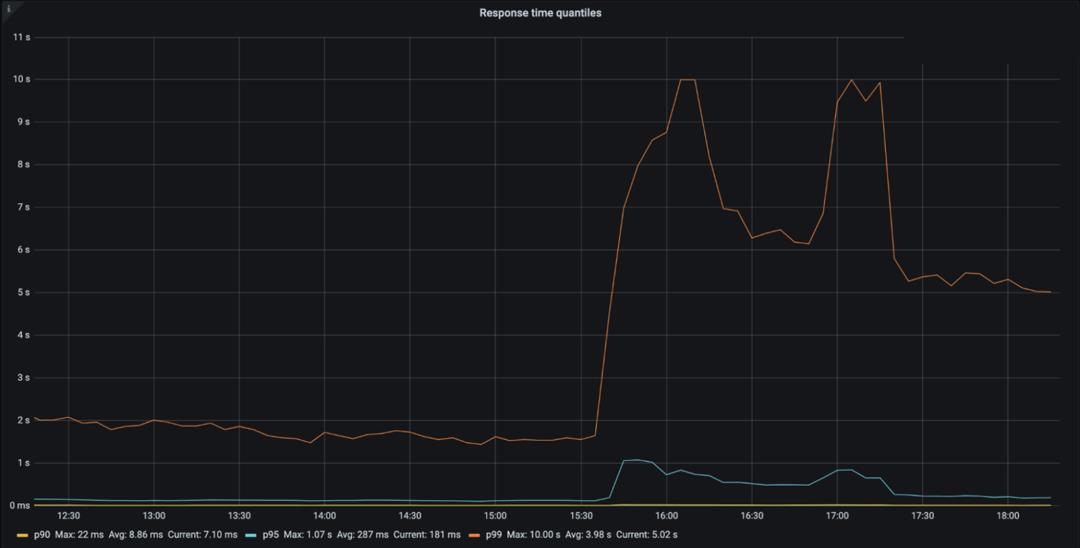
Impacting other services
People look for alternatives and want to know more or discuss what’s going on. When Facebook became unreachable, we started seeing increased DNS queries to Twitter, Signal and other messaging and social media platforms.

We can also see another side effect of this unreachability in our WARP traffic to and from Facebook's affected ASN 32934. This chart shows how traffic changed from 15:45 UTC to 16:45 UTC compared with three hours before in each country. All over the world WARP traffic to and from Facebook’s network simply disappeared.
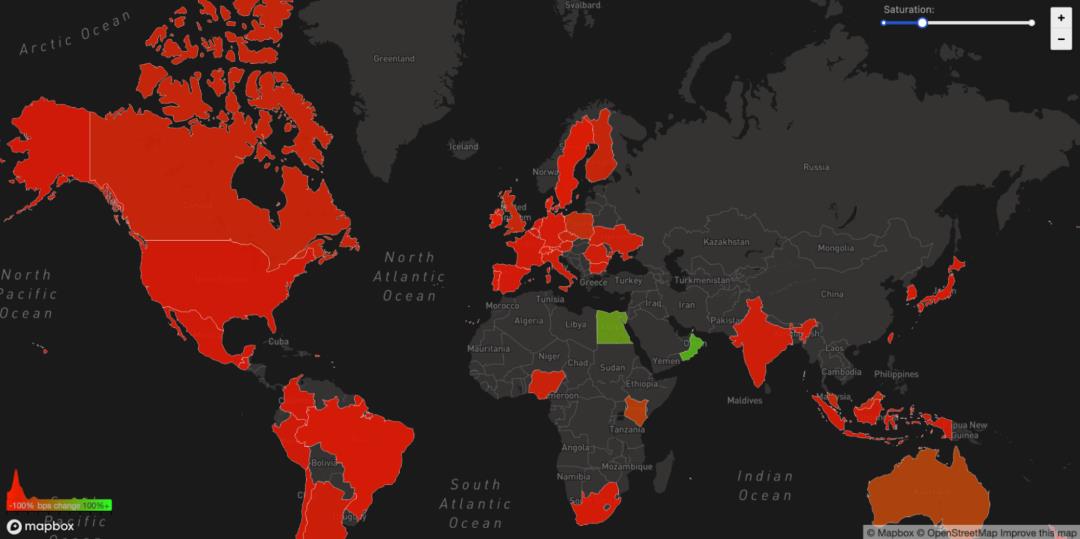
The Internet
Today's events are a gentle reminder that the Internet is a very complex and interdependent system of millions of systems and protocols working together. That trust, standardization, and cooperation between entities are at the center of making it work for almost five billion active users worldwide.
Update
At around 21:00 UTC we saw renewed BGP activity from Facebook's network which peaked at 21:17 UTC.

This chart shows the availability of the DNS name 'facebook.com' on Cloudflare's DNS resolver 1.1.1.1. It stopped being available at around 15:50 UTC and returned at 21:20 UTC.
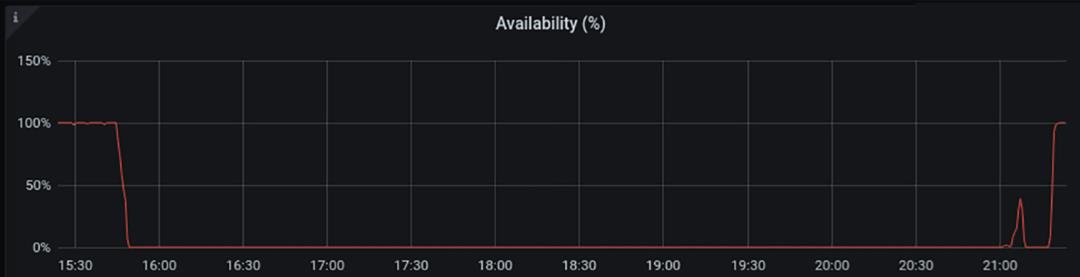
Undoubtedly Facebook, WhatsApp and Instagram services will take further time to come online but as of 21:28 UTC Facebook appears to be reconnected to the global Internet and DNS working again.
从以上的描述中,还可以了解到面对这种问题,工程师定位问题的整体思,值得借鉴和学习。
近期更新的文章:
文章分类和索引:
以上是关于Facebook宕机的经验的主要内容,如果未能解决你的问题,请参考以下文章