Spark2.4.8 共享变量之累加器
Posted 若兰幽竹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.4.8 共享变量之累加器相关的知识,希望对你有一定的参考价值。
一、共享变量
通常,当传递给Spark操作(例如map或reduce)的函数在远程集群节点上执行时,它会在函数中使用的所有变量的单独副本上工作。这些变量被复制到每台机器上,远程机器上变量的更新不会传播回驱动程序。支持跨任务的通用、读写共享变量将是低效的。但是,Spark为两种常见的使用模式提供了两种有限的共享变量类型:广播变量和累加器。
spark通过广播变量和累加器实现共享变量。
二、累加器
累加器是只能通过关联和交换操作添加的变量,因此可以有效地并行支持。它们可以用于实现计数器(如MapReduce)或求和。Spark本地支持数字类型的累加器,程序员可以添加对新类型的支持。作为用户,您可以创建命名或未命名的累加器。如下图所示,一个命名的累加器(在这个实例计数器中)将显示在修改累加器的stage的web UI中。Spark在Tasks表中显示任务修改的每个累加器的值。
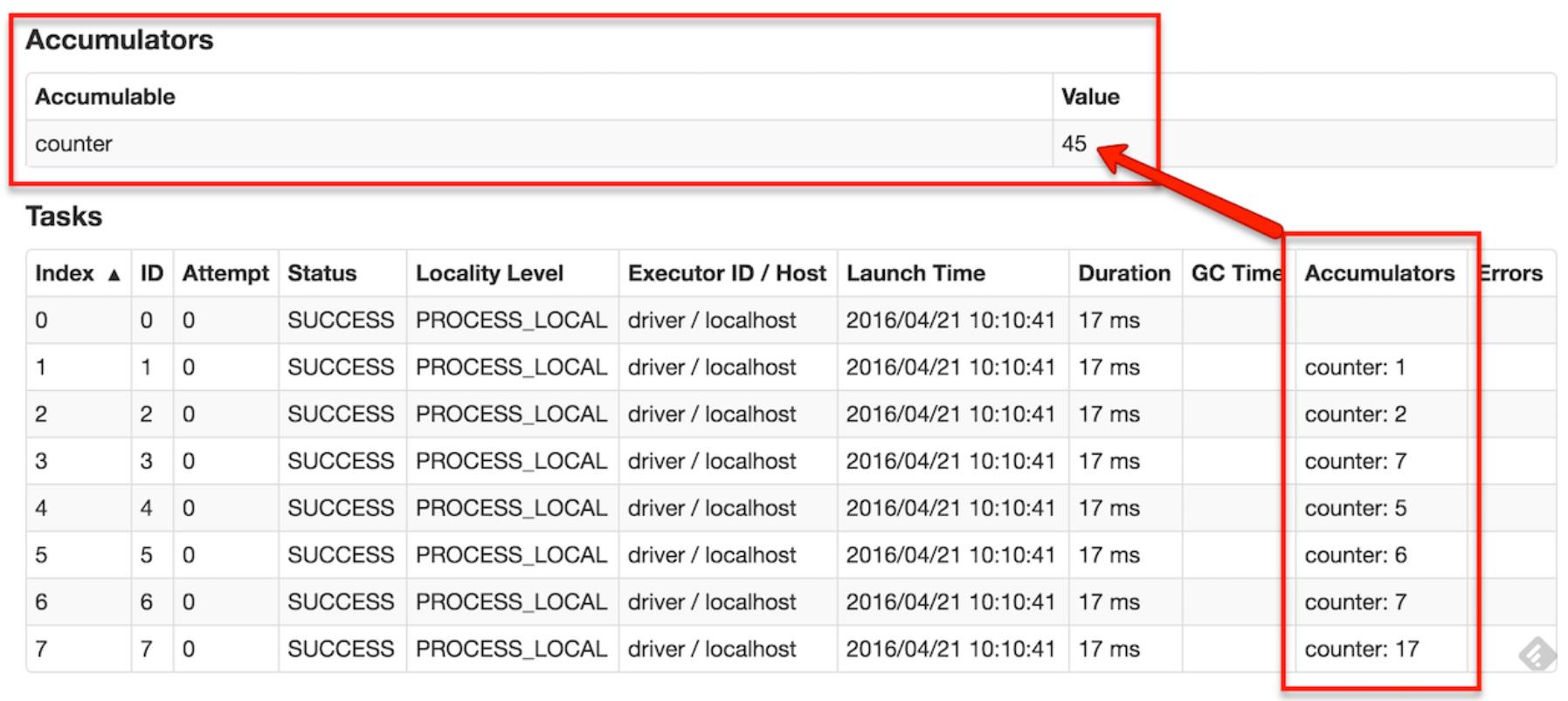
三、基础演示
- 需求描述:利用累加器统计出worker上所有task运行次数
- 演示环境:
三台虚拟机组成的集群 - 运行环境:
spark-shell - 步骤:
- 启动spark-shell:
bin/spark-shell --master spark://niit01:7077 - 编写如下代码:
scala> val ac1 = sc.longAccumulator("ac1") ac1: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(ac1), value: 0) scala> sc.parallelize(1 to 20).map(x => {ac1.add(1);x+1}).reduce(_+_) // 在map中统计出当前的map task 运行的次数 res0: Int = 230 // reduce的结果 scala> ac1.value // 获取累加器的值 res1: Long = 20 // 累加器进行了20次
- 启动spark-shell:
四、实验案例
- 实验要求:利用累加器完成对特定条件下的task任务运行次数统计,如统计出某数列中的奇数项被计算的次数
- 代码如下:
scala> val ac1 = sc.longAccumulator("ac1") // 创建累加器 scala> ac1.value // 获取累加器初始值 res0: Long = 0 scala> sc.parallelize(1 to 20).map(x => { // 统计奇数被执行的次数 | if (x % 2 != 0) | {ac1.add(1) } | x}).reduce(_+_) scala> ac1.value // 获取累加器的数值,只被累加了10次 res2: Long = 10 - 在webui上查看,如下:

五、简要分析
- 上述的实验案例在webui上查看发现两台worker节点上每台节点上各自执行了5次。故,对于任意一个job而言,其所有的task的总数是集群中所有task之和。另外,对于累加器而言,每个task都可以共享累加器,底层利用分布式锁来确保每个task在使用累加器前其值都是最新的,每个task在原来的数值上进行累计。下面我们来查看下每个task运行时累加器的数值变化:
把上面的代码改写成如下:scala> val ac2 = sc.longAccumulator("ac2") // 创建累加器 scala> sc.parallelize(1 to 20).map(x => { | if( x % 2 != 0) | { | | | var hostname = java.net.InetAddress.getLocalHost.getHostName; | val ac2Val = ac2.value | var str = hostname + " : " + Thread.currentThread().getName + " => ac2 before add: " + ac2Val; | ac2.add(1) | val ac2Val2 = ac2.value | str = str + " => ac2 after add: " + ac2Val2 + "\\r\\n" | val socket = new java.net.Socket(hostname,9999); | val out = socket.getOutputStream; | out.write(str.getBytes()) | out.flush() | out.close() | socket.close() | } | x }).reduce(_+_)注意:上述加入了Socket,故需要在worker节点上按照nc进行查看效果,关于nc的按照有两种,推荐使用在线安装,执行: yum install -y nc - 运行上述代码后查看其他两台节点控制台输出,查看前需要分别在两台从节点上启动nc,执行:
nc -lk 9999回车,效果如下:- niit02从节点

- niit03从节点

在web ui上查看,如下所示:
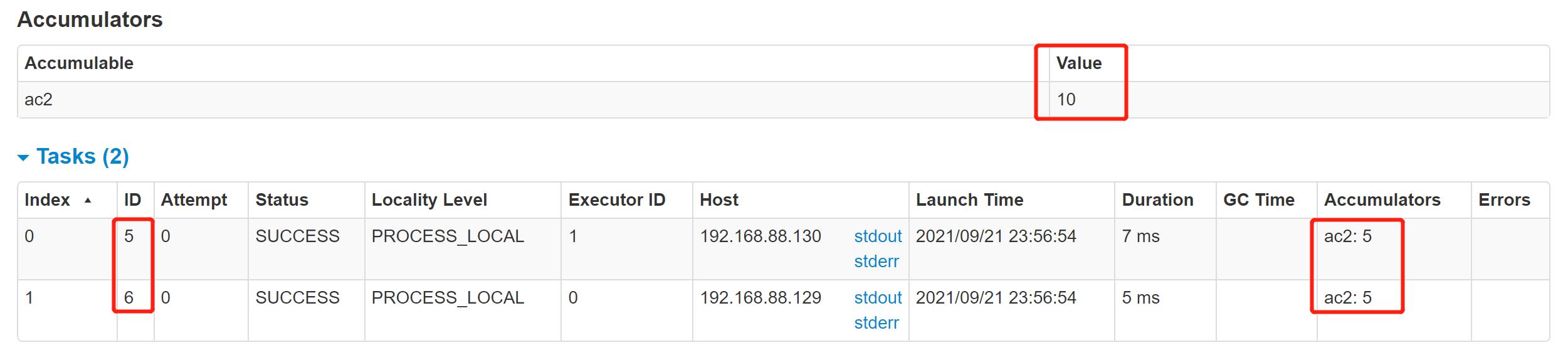
每个Task对累加器更新了5次。
至此,对累加器的介绍就到这里,如对你有所帮助,你的赞将是对我最大的鼓励,谢谢~!!
- niit02从节点
以上是关于Spark2.4.8 共享变量之累加器的主要内容,如果未能解决你的问题,请参考以下文章