PolarDB-X 全局 Binlog 解读之性能篇(下)
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PolarDB-X 全局 Binlog 解读之性能篇(下)相关的知识,希望对你有一定的参考价值。
多级多路归并
在上篇文章中,我们通过一系列的测试,针对全局binlog的同步能力,得出了几个核心结论 BPS可以达到500M+/s EPS可以达到220w+/s * TPS可以达到35w+/s
测试实例的的规格为:8CN + 8DN + 2CDC 单CN节点规格:32核128GB 单DN节点规格:32核128GB * 单CDC节点规格:16核32GB
此处我们将DN节点的数量由8个调整为16个,进行复测,看看性能是否依然可以达到如上标准。以TPS为例,使用上篇中的48张表的sysbench数据导入进行测试
sysbench --config-file='sysb.conf' --create-table-options='dbpartition by hash(`id`) tbpartition by hash(id) tbpartitions 8' --tables='48' --threads='48' --table-size='10000000' oltp_point_select prepare测试结论
TPS只能达到19w+/s的水平,链路出现比较高的延迟,如下图所示:

并且此时多路归并线程已经满负荷运转,如下图所示:
并且此时多路归并线程已经满负荷运转,如下图所示:
这是因为系统默认只开启了单级归并,如下图所示:
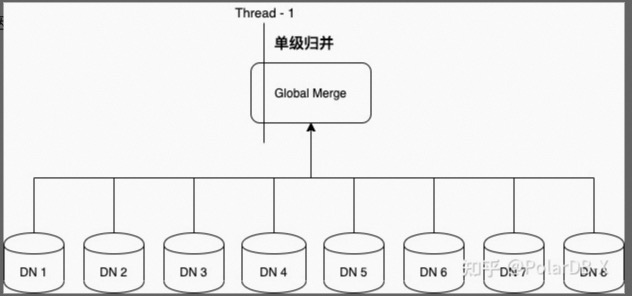
随着DN数量的增多,参与归并排序的队列长度也会随之增大,性能则相应出现衰减(另附多路归并核心代码:LogEventMerger.java),解决办法是开启多级归并,通过“分治”和“并发”来解决性能瓶颈,如下所示:

开启多级归并后,吞吐能力恢复至正常水平,如下所示:
如上是多级归并的逻辑示意图,反映到实际的运行时拓扑,多级归并可以是线程级的,如下所示:
也可以是进程级的,如下所示:
前者用来解决较小规模集群(<=64DN)的性能瓶颈,后者用来解决更大规模集群(>64DN)的性能瓶颈。当DN数量不太多时(如32个),优先考虑通过提升单个节点的配置,采用线程级别的多级归并来提升性能,避免不必要的网络传输开销;当DN数量非常多时(如256个),很难靠单个节点承担计算、内存或网络资源的压力,此时可以通过进程级别的多级归并来提升性能。当然,多级归并也不是“银弹”,全局Binlog会有一个Global Merge Point,当DN数量足够多时,仍然会有单点瓶颈问题(尤其是网络瓶颈),可以通过多流Binlog进行解决,我们的后续文章会对PolarDB-X的多流Binlog进行介绍。
下面表格是oltp_insert场景下的测试数据,分隔行以上的部分是单级归并可支撑的压力范围,当QPS高于20w之后,会出现明显的延迟,开启多级归并后,QPS达到35w时,延迟时间仍然保持在1s以内
流水线&并行
全局Binlog数据流生产线,采用了类似SEDA(Staged Event-Driven Architecture)的架构,共划分为6个Stage,相邻的Stage之间以及Stage内部组件之间,通过队列进行串联,每个Stage内部通过异步或多线程并行技术对数据处理进行加速。
Extract Stage Extract Stage用于完成一级排序,涉及binlog解析、数据整形、元数据维护、ddl处理等,每个DN对应一个处理线程,单个DN最大可支持的EPS吞吐为25w/s,采用的性能优化手段主要在内存管理和缓存管理层面,见下文的内存使用优化章节。
Merge Stage Merge Stage用于完成全局排序,保证全局Binlog中数据操作的线性一致,采用的性能优化手段主要是多级归并,上文已经有详细描述,此处不再赘述。
Collect Stage Collect Stage用于实现事务的合并,将分布式事务的分散到各个DN的binlog数据进行排序和合并,采用的性能优化手段主要有: 通过RingBuffer,进行并行处理,大大提升合并速度 支持“预序列化”,某个事务合并完成之后,如果事务大小小于设定阈值(如果太大,预序列化可能会占用大量内存),会直接构建Transmit Message并序列化,为Transmit Stage减轻压力(Transmit Stage序列化操作是单线程处理)
Transmit Stage Transmit Stage用于实现Task和Dumper之间的网络传输,使用Grpc构建Data Stream,采用的性能优化手段主要有: Batch模式,多个事务的event封装为一个数据包,提升吞吐率 Single模式,自动检测大事务,单个事务独立封装数据包,避免内存溢出 异步处理,耗时的序列化和反序列化操作放到独立线程 动态反压控制,避免内存溢出
Write Stage Write Stage处于数据流的末端,用来构建终态的全局Binlog文件,主要采用了3种优化手段: 并行构建 使用RingBuffer构建缓冲区,将构建binlog event的操作(创建event、更新event内容、计算CRC32校验值等)并行化处理,解决单线程瓶颈。 直接内存 采用直接内存进行IO操作,减小用户态和内核态上下文切换 * Write Cache 引入写缓存,并保证缓存大小为page页的整数倍,降低IO频率和提升page命中率
Backup Stage Backup Stage用于实现全局Binlog文件的备份,支持Dumper之间的主备复制,和到中心化存储(如OSS)的冷备份,主要的性能优化手段是多线程上传和下载。
内存使用优化
全局Binlog系统是一个数据密集型的系统,对内存资源的管理是一个核心关键问题,下面介绍全局Binlog在内存优化层面的优化手段。
事务数据持久化 排序是全局Binlog系统最核心的功能,在对数据进行处理时,需要将某个事务的binlog数据全部接收完之后,才能进行排序操作,当遇到大事务或者超长事务空洞时,如果没有数据的持久化机制,很容易把内存撑爆,导致full gc或内存溢出,影响链路的正常运行。对此系统设计了支持内存和磁盘混合存储的Hybrid KV Store,用来解决内存不足的问题,数据链路的几个核心Stage深度依赖该Store,如下所示
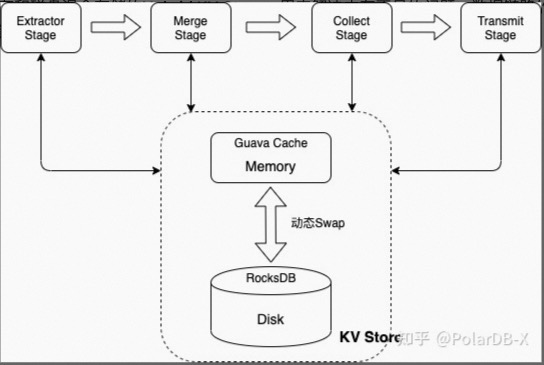
KV Store的主要特点有: 支持大事务swap到磁盘,动态监测事务大小,超过指定阈值后,该事务数据swap到磁盘 支持大事件swap到磁盘,遇到超过指定阈值的binlog event,直接保存到磁盘 支持动态监测内存使用率,超过指定阈值后,自动将存量数据和新增数据swap到磁盘 全磁盘存储相比纯内存存储,性能大概有20%的降低
元数据持久化 元数据是全局Binlog系统的核心命脉,在库表非常多的情况下,元数据会消耗大量内存,可以多达10几GB,影响数据链路的正常运行。举例来说,48w张数据表占用了接近8G的内存,如下所示:
系统提供了针对元数据的持久化机制,开启持久化能力之后,元数据会被序列化并保存至RocksDB,并支持在内存和磁盘之间的动态Swap,涉及元数据持久化的参数为: meta.persist.basePath : 配置元数据持久化目录 meta.persist.schemaObject.switch : 是否开启元数据持久化
接上面例子,当开启元数据持久化之后,内存占用大幅降低到只有240M,如下所示:
优化内存分配 虽然KV Store提供了swap机制,保证了内存不够用时数据可以转储到磁盘,但毕竟会对性能造成影响,最优的策略还是尽量减少内存的占用,系统提供的主要优化手段有: 不同stage对内存的要求不一样,合理控制队列缓冲区的大小,规避不必要的数据堆积 规避不必要的数据复制,如针对ByteString的使用 ByteString.copyFrom方法可以替换为UnsafeByteOperations.unsafeWrap方法,免去字节数组copy操作 ByteString.toByteArray方法可以替换为DirectByteOutput.unsafeFetch方法,免去字节数组copy操作
总结
本篇从技术原理的角度,对全局Binlog的一些核心的性能优化手段做了简要的介绍,通过SEDA流水线架构实现了异步和并行处理,通过多级归并解决了集群规模扩张时的性能衰减问题,通过一系列的内存优化手段保证了数据链路的高效运行,这些优化措施,保证了全局Binlog在TPCC 150w tpmC的压力下,延迟仍可以控制在1s以内(参见:性能白皮书)
当然,全局Binlog在架构上也有天然的劣势,其在应对超大规模集群时存在单点瓶颈,PolarDB-X的多流Binlog通过牺牲事务的完整性解决了单点问题,在应对超大规模集群时,能够保证性能的线性提升,敬请关注我们的系列文章。
本文为阿里云原创内容,未经允许不得转载。
以上是关于PolarDB-X 全局 Binlog 解读之性能篇(下)的主要内容,如果未能解决你的问题,请参考以下文章