[基于Pytorch的MNIST识别04]模型调试
Posted AIplusX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[基于Pytorch的MNIST识别04]模型调试相关的知识,希望对你有一定的参考价值。
知识点
1:nn.MSELoss(x,y) 均方根值函数
如果输入的x和y参数的维度不同,维度低的tensor会进行扩张填充,扩充形式如下图所示:
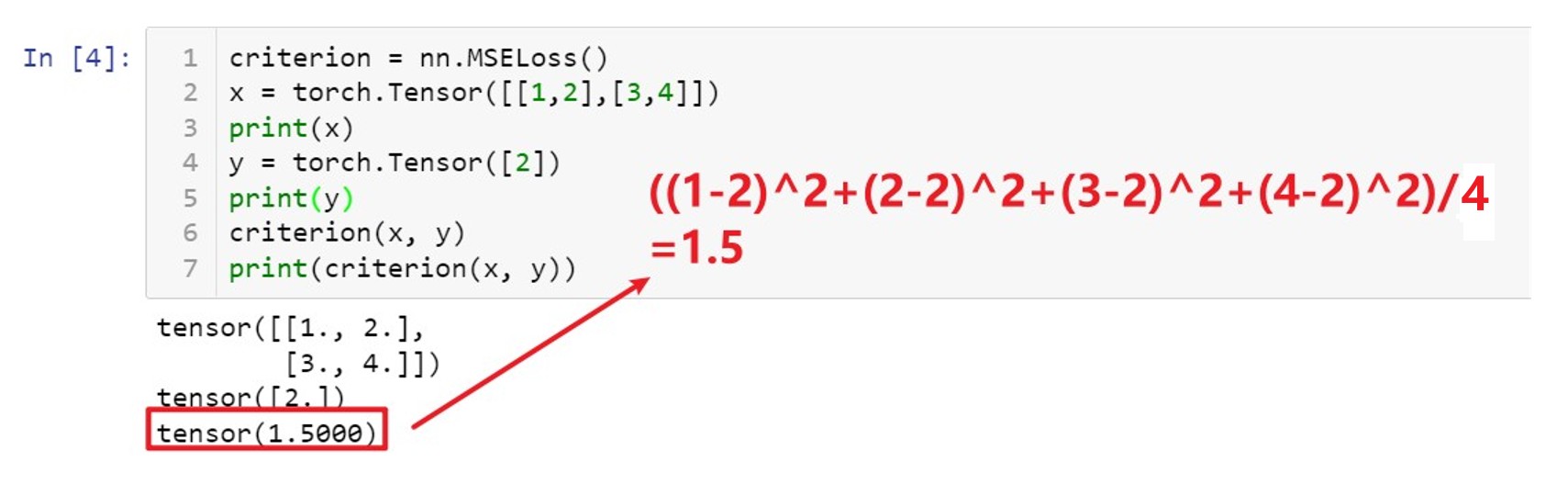
因此之后在训练模型的时候要保持输入变量参数一致,养成良好的编程习惯。
2:这里对昨天一个函数的纠正:
torch.max()用法:
parameter,index = torch.max(data,0), 返回列最大值以及对应索引,索引在后,数值在前
parameter,index = troch.max(data,1), 返回行最大值以及对应索引,索引在后,数值在前
这是我的失误,我也是在网上搜索之后但没有实践就拿来用了,所以搞错了,今天我重新实践了一下,结果如下图所示:
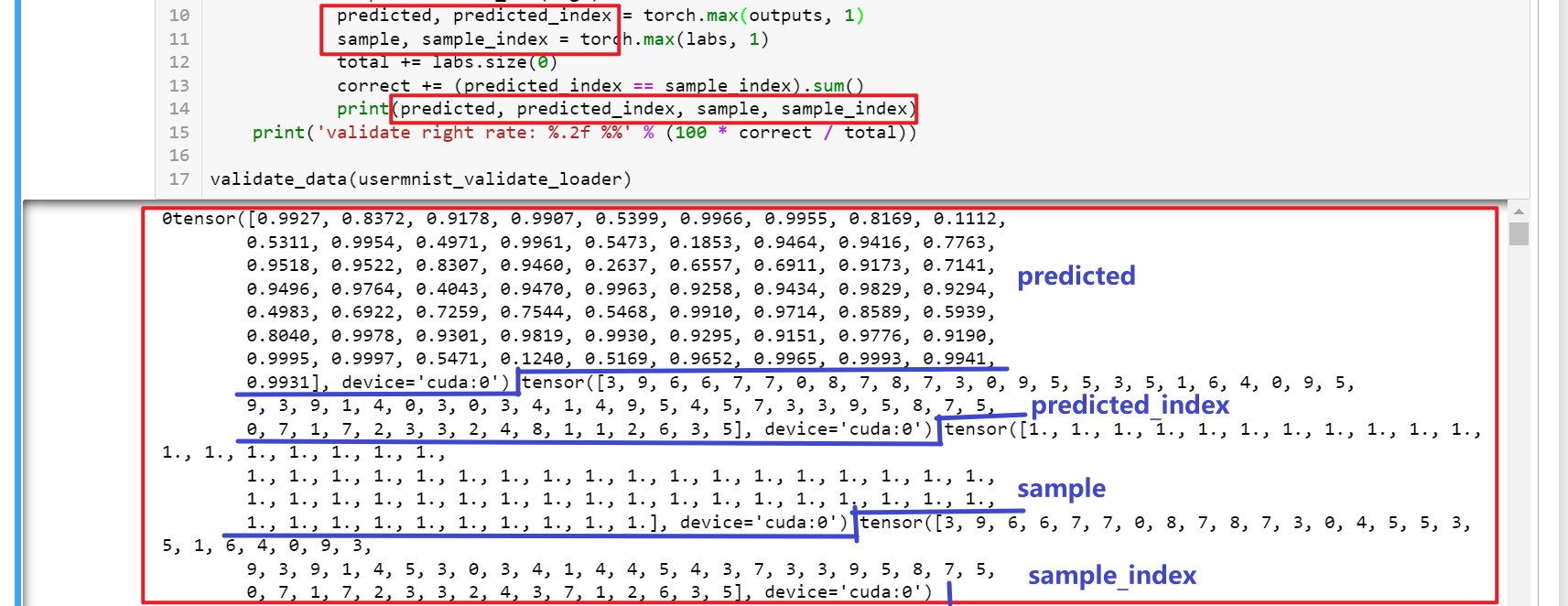
可以看到我对函数的输出分别进行了打印,可以看到是先输出数据,再输出对应索引的。
训练模型
今天我把模型跑通了,我先用batch_size=100的参数进行了训练,并且用验证集进行了验证,验证函数如下图所示:
def validate_data(usermnist_validate_loader):
with torch.no_grad():
total = float(0)
correct = float(0)
for i, (imgs, labs) in enumerate(usermnist_validate_loader):
sys.stdout.write('\\r'+str(i)+str())
imgs = imgs.to(device)
labs = labs.to(device)
outputs = mnist_net(imgs)
predicted, predicted_index = torch.max(outputs, 1)
sample, sample_index = torch.max(labs, 1)
total += labs.size(0)
correct += (predicted_index == sample_index).sum()
# print(predicted, predicted_index, sample, sample_index)
print('validate right rate: %.2f %%' % (100 * correct / total))
validate_data(usermnist_validate_loader)
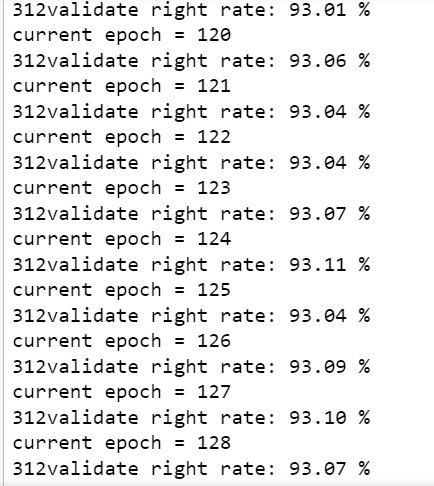
在训练了100个epoch之后达到了89.91%的正确率,但是在之后的训练中正确率上升的十分缓慢,说明训练的效率十分低下,因此我把batch_size换成了32,在小batch_size的情况下,正确率的输出可能会震荡,但是总体还是呈下降趋势的,具体结果如下图所示:
源码:
# coding: utf-8
# In[1]:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import torchvision.transforms as transforms
import struct
import matplotlib.pyplot as plt
import sys
import warnings
from torch.utils.data import Dataset,DataLoader
#print beta
print(torch.__version__)
torch.set_default_tensor_type(torch.DoubleTensor)
# In[65]:
user_train_imgs_path = './dataset/train-images.idx3-ubyte'# 6w
user_train_labels_path = './dataset/train-labels.idx1-ubyte'
user_validate_imgs_path = './dataset/t10k-images.idx3-ubyte'# 1w
user_validate_labels_path = './dataset/t10k-labels.idx1-ubyte'
#hyperparameters
input_size = 784 #28*28
hidden_size = 16
user_batch_size = 32
out_put_size = 10 #0~9
# In[13]:
class UserMNIST(Dataset):
def __init__(self, imgs_path, labels_path, root='', train=True):
super(UserMNIST, self).__init__()
self.train = train #type of datasets
self.train_nums = int(6e4)
self.test_ratio = int(9e-1)
self.validate_nums = int(1e4)
# print(self.train_nums)#The scientific counting method is float,which should be changed by user
#load files path
self.imgs_folder_path = imgs_path
self.labels_folder_path = labels_path
if self.train :
self.img_nums = self.train_nums
else:
self.img_nums = self.validate_nums
#load dataset
with open(self.imgs_folder_path, 'rb') as _imgs:
self._train_images = _imgs.read()
with open(self.labels_folder_path, 'rb') as _labs:
self._train_labels = _labs.read()
def __getitem__(self, index):
image = self.getImages(self._train_images, index)
label = torch.zeros(out_put_size)
temp = self.getLabels(self._train_labels, index)
label[temp] = 1
return image,label
def __len__(self):
return self.img_nums
def getImages(self, image, index):
img_size_bit = struct.calcsize('>784B')
start_index = struct.calcsize('>IIII') + index * img_size_bit
temp = struct.unpack_from('>784B', image, start_index)
img = self.normalization(np.array(temp, dtype=float))
return img
def getLabels(self, label, index):
lab_size_bit = struct.calcsize('>1B')
start_index = struct.calcsize('>II') + index * lab_size_bit
lab = struct.unpack_from('>1B', label, start_index)
# lab = torch.Tensor(lab)
return lab
def normalization(self, x):
max = float(255)
min = float(0)
for i in range(0, 784):
x[i] = (x[i] - min) / (max - min)
return x
# In[67]:
usermnist_train = UserMNIST(user_train_imgs_path, user_train_labels_path, train=True)#how to one data,return numpy(user define) type
usermnist_train_loader = DataLoader(dataset=usermnist_train, batch_size=user_batch_size, shuffle=True)#do somethings to get all data,return tensor type
usermnist_validate = UserMNIST(user_validate_imgs_path, user_validate_labels_path, train=False)#how to one data,return numpy(user define) type
usermnist_validate_loader = DataLoader(dataset=usermnist_validate, batch_size=user_batch_size, shuffle=True)#do somethings to get all data,return tensor type
# In[50]:
img, lab = usermnist_train.__getitem__(6) # get the 34th sample
print(type(img))
print(type(lab))
# plt.imshow(img)
# plt.show()
# In[51]:
dataiter = iter(usermnist_train_loader)
images,labels = dataiter.next()
# print(images.shape, labels)
print(images.size(), labels.size(), labels.size(1))
print(type(images), type(labels))
# print(dataiter.batch_size)
# In[20]:
#set up NeuralNet
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, out_put_size):
super(NeuralNet, self).__init__()
#recode hyperparameters
self.input_size = input_size
self.hidden_size = hidden_size
self.out_put_size = out_put_size
# 2 hidden_layers
self.gap0 = nn.Linear(input_size, hidden_size)
self.gap1 = nn.Linear(hidden_size, hidden_size)
self.gap2 = nn.Linear(hidden_size, out_put_size)
def forward(self, x):
out = self.gap0(x)
out = torch.relu(out)
out = self.gap1(out)
out = torch.relu(out)
out = self.gap2(out)
out = torch.sigmoid(out)
return out
learning_rate = 1e-2
mnist_net = NeuralNet(input_size, hidden_size, out_put_size)
optimizer = torch.optim.SGD(mnist_net.parameters(), lr=learning_rate)
print(mnist_net)
# In[21]:
for name,parameters in mnist_net.named_parameters():
print(name,':',parameters.size())
# print(parameters)
# In[22]:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
mnist_net.to(device)
print(next(mnist_net.parameters()).device)
# In[53]:
def validate_data(usermnist_validate_loader):
with torch.no_grad():
total = float(0)
correct = float(0)
for i, (imgs, labs) in enumerate(usermnist_validate_loader):
sys.stdout.write('\\r'+str(i)+str())
imgs = imgs.to(device)
labs = labs.to(device)
outputs = mnist_net(imgs)
predicted, predicted_index = torch.max(outputs, 1)
sample, sample_index = torch.max(labs, 1)
total += labs.size(0)
correct += (predicted_index == sample_index).sum()
# print(predicted, predicted_index, sample, sample_index)
print('validate right rate: %.2f %%' % (100 * correct / total))
validate_data(usermnist_validate_loader)
# In[63]:
criterion = nn.MSELoss()
# In[ ]:
epoches = 200
for epoch in range(epoches):
print('current epoch = %d' % epoch)
validate_data(usermnist_validate_loader)
for i, (images, labels) in enumerate(usermnist_train_loader):
images = images.to(device)#move to gpu
labels = labels.to(device)
optimizer.zero_grad()
outputs = mnist_net(images)
with warnings.catch_warnings():#ignore some warnings
warnings.simplefilter("ignore")
loss = criterion(outputs, labels) # calculate loss
loss.backward()
optimizer.step()
# In[ ]:
save_path = './'
torch.save(mnist_net, save_path)

以上是关于[基于Pytorch的MNIST识别04]模型调试的主要内容,如果未能解决你的问题,请参考以下文章