Flink流式计算从入门到实战 三
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink流式计算从入门到实战 三相关的知识,希望对你有一定的参考价值。
文章目录
Flink流式计算实战专题三
Flink流式计算API
==楼兰 Flink的计算功能非常强大,提供的应用API也非常丰富。整体上来说,可以分为DataStream API,DataSet API 和 Table与SQL API三大部分。
其中DataStream API是Flink中主要进行流计算的模块。 DateSet API是Flink中主要进行批量计算的模块。而Table API和SQL主要是对Flink数据集提供类似于关系型数据的数据查询过滤等功能。
在这三个部分中,DateStream API是Flink最为重要的部分。之前介绍过,Flink是以流的方式来进行流批统一的,所以这一部分API基本上包含了Flink的所有精华。
DataSet API处理批量数据,但是批量数据在Flink中是被当做有界流来处理的,DataSet API中的大部分基础概念和功能也都是包含在Flink的DataStream API中的。
而Table API和SQL 是Flink主要针对Java和Scala语言,提供的一套查询API。可以用来对Flink的流式数据进行一些类似于关系型数据的查询过滤功能。而根据官方的介绍,这一部分功能还处在活跃开发阶段,目前版本还没有完全实现全部的特性。
所以,后续的应用开发学习过程中,也需要以DataStream API为主。而对于DataSet API和Table API & SQL,相对来说没有这么重要。
另外,在学习Flink编程API之前,要特别强调一点就是Flink的版本。Flink目前处在非常活跃的开发阶段,不同版本之间的API变动非常大。所有后续的课程内容都以Flink1.12版本为准。
四、Flink DataStream API
1、Flink程序的基础运行模型
要理解DataStream API首先需要理解什么是DataStream。DataStream在Flink 的应用程序中被认为是一个不可更改的数据集,这个数据集可以是无界的,也可以是有界的,Flink对他们的处理方式是一致的,这也就是所谓的流批统一。一个DataStream和java中基础的集合是很像的,他们都是可以迭代处理的,只不过DataStream中的数据在创建了之后就不能再进行增删改的操作了。
在上一章节,其实我们已经接触到了一个简单的Flink程序。 一个Flink程序的基础运行模型是这样的:

这个模型看起来很简单对吧。其实大数据场景下的流式计算确实是很复杂的,但是经过Flink封装后,确实就简单很多了。大致来说,一个Flink的客户端应用主要分为五个阶段:
- 获取一个执行环境 Environment
- 通过Source,定义数据的来源
- 对数据定义一系列的操作,Transformations
- 通过Sink,定义程序处理的结果要输出到哪里
- 最后,提交并启动任务
在之前的演示过程中,我们也接触了一个简单的Flink应用,你可以和这几个步骤对应起来。未来更为复杂的Flink应用也是按照这几个步骤来组织的。
2、Environment 运行环境
StreamExecutionEnvironment是所有Flink中流式计算程序的基础。创建环境的方式有三种。
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment()
StreamExecutionEnvironment.createLocalEnvironment()
StreamExecutionEnvironment.createRemoteEnvironment(String host, int port, String... jarFiles)
通常情况下,你只需要使用getExecutionEnvironment()这一种方式就可以了。这个API会根据运行环境创建正确的StreamExecutionEnvironment对象。这样就不需要区分应用是在IDEA本地执行或者是在某一个Flink Cluster上执行。
然后,创建出来的StreamExecutionEnvironment对象,可以设置应用整体的并行度。StreamExecutionEnvironment.setParallelism。关于并行度已经在上一章节中详细做了分析,这里需要注意,并行度是贯穿整个应用的资源主线。
在StreamExecutionEnvironment对象中,还可以通过setRuntimeMode方法设置一个运行模式。可以设定一个RuntimeExecutionMode枚举类型。该类型有三个可选的枚举值
- STREAMING:流式模式。这种模式下,所有的task都会在应用执行时完成部署,后续所有的任务都会连续不断的执行。
- BATCH: 批量模式。这是Flink早期进行批处理的方式,这种模式下,所有的任务都会周期性的部署,shuffle的过程也会造成阻塞。相当于是拿一批数据处理完了之后,再接收并处理下一批任务。
- AUTOMATIC:自动模式。Flink将会根据数据集类型自动选择处理模式。有界流下选择BATCH模式,无界流下选择STREAMING模式。
BATCH模式能够稍许提升应用的吞吐量,对于有界流,能提高执行效率。但是对于无界流就不适用了。而对于Flink,默认的STREAMING模式在有界流和无界流场景下都是适用的。
另外,这个执行模式并不建议在代码中设置,最好是在flink-conf.yaml文件中通过execution.runtime-mode属性进行整体设置,或者是在使用flink脚本提交任务时指定。这样能让应用更加灵活。例如:
bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
这两种运行模式影响到的功能还是挺多的,通常情况下,不建议做特殊的指定。
3、Source
Source和表示Flink应用程序的数据输入。Flink中提供了非常丰富的Source实现,目前主流的数据源都可以对接。
3.1 基于File的数据源
1 readTextFile(path)
一行行读取文件中的内容,并将结果以String的形式返回。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final DataStreamSource<String> stream = env.readTextFile("D://test.txt");
stream.print();
env.execute();
print打印出来的结果中每一行前面的数字表示这一行是哪个线程打印出来的。
2 readFile((FileInputFormat inputFormat, String filePath))
DataStreamSource<String> stream = env.readFile(new TextInputFormat(new Path("D://test.txt")), "D://test.txt");
TextInputFormat是一个接口,OUT泛型代表返回的数据类型。TextInputFormat的返回类型是String。PojoCsvInputFormat就可以指定从CSV文件中读取出一个POJO类型的对象。
示例代码:com.roy.flink.streaming.FileRead 从文件读数据,输出到文件。
3.2 基于Socket的数据源
这个我们之前已经演示过。对接一个Socket通道,读取数据
DataStreamSource<String> stream = env.socketTextStream("localhost", 11111);
stream.print();
env.execute("stream word count");
3.3 基于集合的数据源
1、fromCollection 从集合获取数据
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
final DataStreamSource<Integer> stream = env.fromCollection(list);
stream.print();
env.execute("stream");
2、fromElements 从指定的元素集合中获取数据
final DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5);
3.4 从Kafka读取数据
在通常情况下,流式数据最大的数据来源还是kafka。而Flink已经提供了针对kafka的Source。引入kafka的连接器,需要引入maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.12.3</version>
</dependency>
然后使用FlinkKafkaConsumer创建一个Source
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop01:9092,hadoop02:9092,hadoop03:9092");
properties.setProperty("group.id", "test");
final FlinkKafkaConsumer<String> mysource = new FlinkKafkaConsumer<>("flinktopic", new SimpleStringSchema(), properties);
// mysource.setStartFromLatest();
// mysource.setStartFromTimestamp();
DataStream<String> stream = env
.addSource(mysource);
stream.print();
env.execute("KafkaConsumer");
这样就可以接收到kafka中的消息了
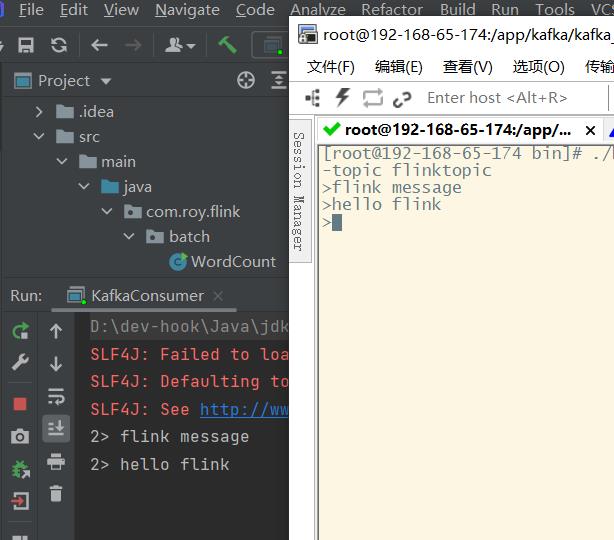
另外,Flink非常多常用组件的Connector。例如Hadoop,HBase,ES,JDBC等。 具体参见官方网站的Connectors模块。
地址:https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/kafka.html
补充一个组件RocketMQ。 Flink官方并没有提供RocketMQ的Connector。但是RocketMQ社区只做了一个Flink的Connector,参见Git仓库:https://github.com/apache/rocketmq-externals
3.5 自定义Source
用户程序也可以基于Flink提供的SourceFunction,配置自定义的Source数据源。例如下面的示例,可以每一秒钟随机生成一个订单对象。
public class UDFSource {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Order> orderDataStreamSource = env.addSource(new MyOrderSource());
orderDataStreamSource.print();
env.execute("UDFOrderSOurce");
}
public static class MyOrderSource implements SourceFunction<Order> {
private boolean running = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
final Random random = new Random();
while(running){
Order order = new Order();
order.setId("order_"+System.currentTimeMillis()%700);
order.setPrice(random.nextDouble()*100);
order.setOrderType("UDFOrder");
order.setTimestamp(System.currentTimeMillis());
//发送对象
ctx.collect(order);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running=false;
}
}
}
注 1、流式计算的数据源需要源源不断产生数据,所以run方法通常都是一个无限循环。这时Flink强调要通过cancel方法主动停止run方法中的循环。
2、Flink还提供了另外一个RichSourceFunction接口来定义Source。这个接口提供了Source的生命周期管理。关于生命周期,在这个示例中看不出差别,在后面的章节会进行讲解。
4、Sink
Sink是Flink中的输出组件,负责将DataStream中的数据输出到文件、Socket、外部系统等。
4.1 输出到到控制台
DataStream可以通过print()和printToErr()将结果输出到标准控制台。在Flink中可以在TaskManager的控制台中查看。
4.2 输出到文件
对于DataStream,有两个方法writeAsText和writeAsCsv,可以直接将结果输出到文本文件中。但是在当前版本下,这两个方法已经被标记为过时。当前推荐使用StreamingFileSink。例如:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
final StreamingFileSink<String> streamingfileSink = StreamingFileSink
.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<String>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.addSink(streamingfileSink);
env.execute();
流式计算场景下的文件输出,不能直接往一个文件里不停的写。StreamingFileSink提供了流式数据的分区读写以及滚动更新功能。Flink另外提供了多种文件格式的Sink类型。具体参见https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/streamfile_sink.html
然后,针对流批统一场景,Flink还另外提供了一个StreamingFileSink的升级版实现,FileSink。使用FileSink需要增加一个maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.12.5</version>
</dependency>
这样就可以使用FileSink进行流批统一的文件输出了。、
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
final FileSink<String> fileSink = FileSink
.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<String>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.sinkTo(fileSink);
env.execute();
通常情况下,流式数据很少会要求输出到文件当中,更多的场景还是会直接输出到其他下游组件当中,例如kafka、es等。
4.3 输出到Socket
例如我们可以将之前从Socket读到的wordcount结果输出回Socket
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
final int port = parameterTool.getInt("port");
final DataStreamSource<String> inputDataStream = environment.socketTextStream(host, port);
final DataStream<Tuple2<String, Integer>> wordcounts = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
final String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
.setParallelism(2)
.keyBy(value -> value.f0)
.sum(1)
.setParallelism(3);
wordcounts.print();
wordcounts.writeToSocket(host,port,new SerializationSchema<Tuple2<String, Integer>>(){
@Override
public byte[] serialize(Tuple2<String, Integer> element) {
return (element.f0+"-"+element.f1).getBytes(StandardCharsets.UTF_8);
}
});
environment.execute("stream word count");
}
这样,在socket的服务端就能收到响应信息。
4.4 输出到kafka
Flink提供的这个kafka的connector模块,即提供了FlinkKafkaConsumer作为Source消费消息,也提供了FlinkKafkaProducer作为Sink生产消息。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<String>(
"my-topic", // 目标 topic
new SimpleStringSchema() // 序列化 schema
properties, // producer 配置
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // 容错
stream.addSink(myProducer);
env.execute("kafka sink")
详细情况还是可以参看官方文档说明。
参考示例 com.roy.flink.sink.KafkaSinkDemo 从一个topic接收数据,处理完成后,转发到另一个Topic,这是一个典型的流式计算场景。
4.5 自定义Sink
与Source类似,应用程序同样可以通过不带生命周期的SinkFunction以及带生命周期的RickSinkFunction来定义自己的Sink实现。例如下面的示例中就扩展出了一个把消息存入mysql的示例。
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Order> source = env.addSource(new UDFSource.MyOrderSource());
source.addSink(new MyJDBCSink());
env.execute("UDFJDBCSinkDemo");
}
public 以上是关于Flink流式计算从入门到实战 三的主要内容,如果未能解决你的问题,请参考以下文章