学习笔记Hive—— 查询优化
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Hive—— 查询优化相关的知识,希望对你有一定的参考价值。
一、视图
1.1、Hive的视图
- 视图是基于数据库的基本表进行创建的一种伪表,数据库中储存视图的定义,不存数据项,数据项仍然存在基本表中它可作为一个抽象层,将数据发布给下游用户。
- 目前 Hive 版本支持逻辑视图,不支持物理视图。所以 Hive 的数据仓库目录查找不到视图,但可在 mysql 的元数据库中查找到。
- 视图只能查询,不能进行数据的插入和修改,可以提高数据的安全性。
- 在创建视图时候视图就已经固定,对基表的后续更改(如添加列)将不会反映在视图。
- view定义中若包含了ORDER BY/LIMIT语句,则当查询视图时也进行ORDER BY/LIMIT语句操作,view当中定义的优先级更高。
1.2、引用视图的优点
- 使用视图降低查询复杂度
- 使用视图来限制基于条件过滤的数据
1.3、视图创建和应用
1.3.1、了解顾客需求
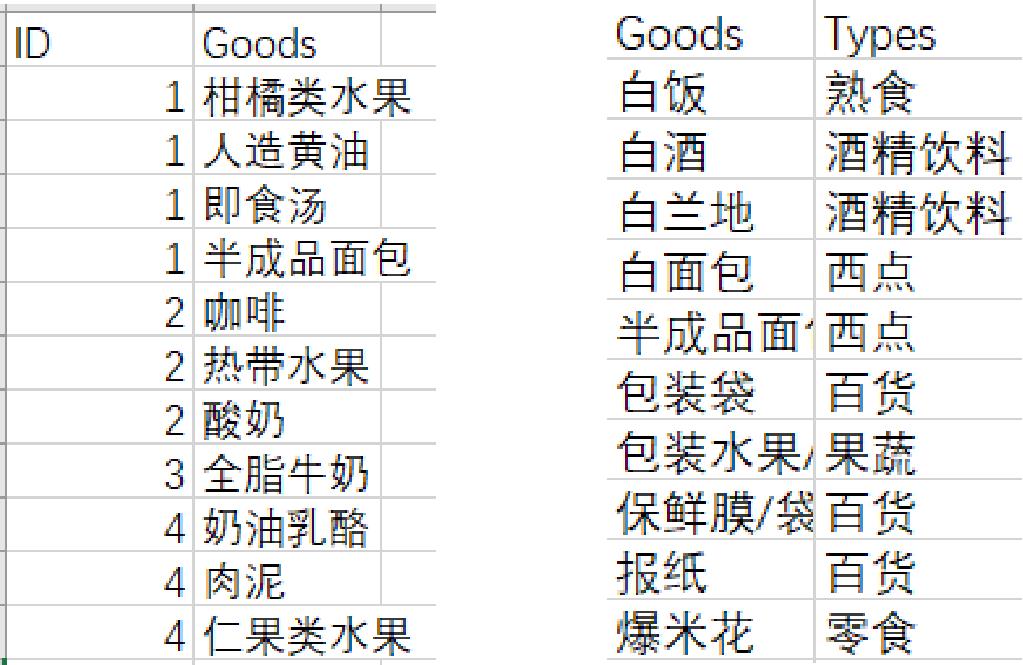
1.3.2、创建视图
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name -- 视图名称
[(column_name [COMMENT column_comment], ...) ] --列名
[COMMENT view_comment] --视图注释
[TBLPROPERTIES (property_name = property_value, ...)] --额外信息
AS SELECT ...;
1.3.3、查看与删除视图
1、查看某个视图
desc view_name;
2、查看某个视图详细信息
desc formatted view_name;
3、删除视图
DROP VIEW [IF EXISTS] [db_name.]view_name;
任务1
将以下嵌套查询中的嵌套子查询变成视图
select t.types,t.goods,t.t_g_count from (select c.types,c.goods,count(1) t_g_count,row_number() over(partition by c.types order by count(1) desc) rank from(select a.*,b.types from goodsorder a left outer join goodstypes b on a.goods=b.goods) c group by c.types,c.goods) t where rank<=10



结果(部分):

二、索引
2.1、Hive的索引
- Hive没有主键概念,但可以建立索引,索引的设计目标是提高表某些列的查询速度。
- 在指定列上建立索引,会产生一张索引表,里面的字段包括:索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。
- 在查询涉及到索引字段时,首先到索引表查找索引列值对应的HDFS文件路径及偏移量,这样就避免了全表扫描。
索引表:

2.2、索引的优点
- 可以避免全表扫描和资源浪费
- 可以加快含有group by的语句的查询速度
2.3、索引创建和应用
2.3.1、创建索引
CREATE INDEX index_name --索引名称
ON TABLE base_table_name (col_name, ...) --建立索引的列
AS index_type --索引类型
[WITH DEFERRED REBUILD] --重建索引
[IDXPROPERTIES (property_name=property_value, ...)] --索引额外属性
[IN TABLE index_table_name] --索引表的名字
[ [ ROW FORMAT ...] STORED AS ...
| STORED BY ... ] --索引表行分隔符 、 存储格式
[LOCATION hdfs_path] --索引表存储位置
[TBLPROPERTIES (...)] --索引表表属性
[COMMENT "index comment"]; --索引注释
2.3.2、自动使用索引
(创建索引之前设置)
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
SET hive.optimize.index.filter=true;
SET hive.optimize.index.filter.compact.minsize=0;
2.3.3、查看和删除索引
1、显示表上所有列的索引
SHOW FORMATTED INDEX ON table_name;
2、删除索引
DROP INDEX [IF EXISTS] index_name ON table_name;
任务2
1、为goodsorders id字段创建索引

2、查询id=10的顾客的订单

3、按照id分组统计每个顾客购买商品数量

三、存储格式
3.1、文件存储格式
- 指Hive表数据存储的格式
- 默认是文本文件格式
- 有行存储和列存储
3.2、存储格式设置
STORED AS (TextFile|RCFile|SequenceFile|ORC|Parquet)
| 存储格式 | 存储方式 | 压缩方式 | 特点 |
|---|---|---|---|
| textFile | 按行存储 | Gzip,Bzip2 | 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高 |
| SequenceFile | 按行存储 | NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩 | 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载 |
| RCFile | 按列存储 | 存储空间小,查询的效率高 ,需要通过text文件转化来加载,加载的速度低。压缩快 快速列存取。读取全量数据的操作 性能可能比sequencefile没有明显的优势 | |
| ORCFile | 按列存储 | zlib(default),snappy | 压缩快,快速列存取 ,效率比rcfile高,是rcfile的改良版本,不支持其他的查询引擎, 比如impala |
| parquet | 按列存储 | Parquet压缩比较低,查询效率较低,不支持update、insert和ACID.但是Parquet支持Impala查询引擎 |
默认是TextFile存储格式
Impala是CloudParquet和ORC有很多相似之处, 但是Parquet更有意成为hadoop上通用的存储格式. 它可以与impala, Spark, Pig等引擎结合使用. 它可以指定每一列的压缩方式, 从而实现更高效的压缩. Parquet旨在设计为支持复杂嵌套数据的存储, 比如json
任务3
数据(person.parquet):
1,Tom,23
2,Kate,24
3,Betty,22
4,Ketty,23
5,Jhon,21
1、创建表person,设置表的数据存储格式为parquet

2、将user.parquet文件存入表中

3、查询数据
以上是关于学习笔记Hive—— 查询优化的主要内容,如果未能解决你的问题,请参考以下文章