学习笔记Spark—— Spark集群的安装配置
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Spark—— Spark集群的安装配置相关的知识,希望对你有一定的参考价值。
一、我的软件环境

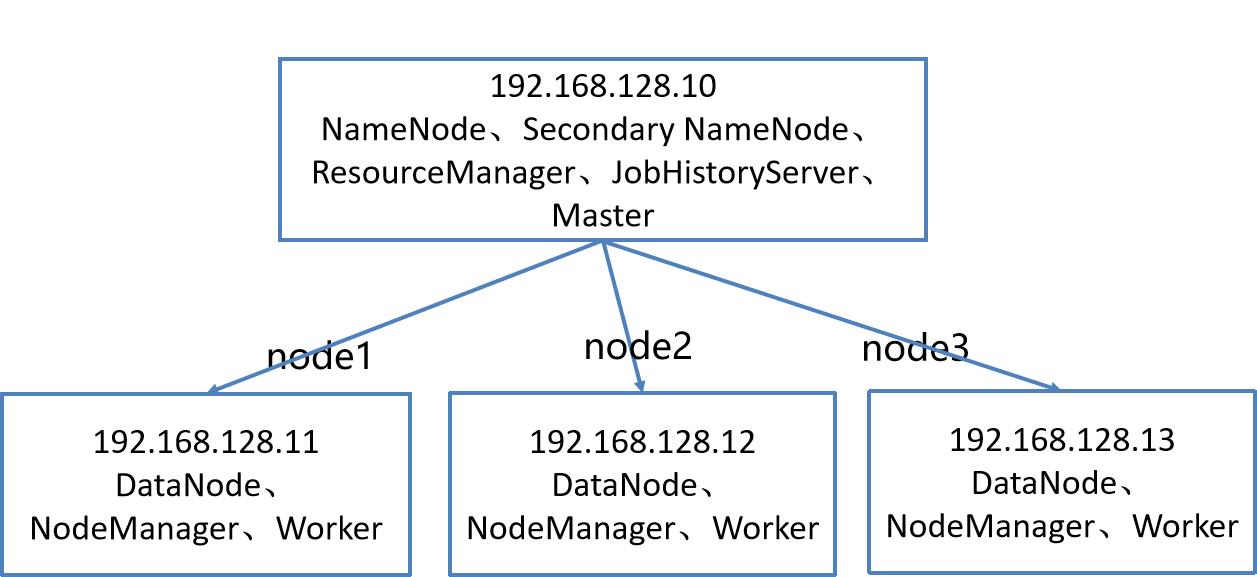
二、Spark集群拓扑
2.1、集群规模
192.168.128.10 master 1.5G ~2G内存、20G硬盘、NAT、1~2核 ;
192.168.128.11 node1 1G内存、20G硬盘、NAT、1核
192.168.128.12 node2 1G内存、20G硬盘、NAT、1核
192.168.128.13 node3 1G内存、20G硬盘、NAT、1核
2.2、Spark的安装模式
1、本地模式
在一个节点上安装Spark,利用本地线程运行程序,非分布式环境
2、伪分布式
Spark单机伪分布式是在一台机器上既有Master,又有Worker进程
3、完全分布式
全分布模式用于生产,至少需要3~4台机器,其中一台为为主节点,部署Master,其他节点部署Worker
4、HA高可用模式
在完全分布式基础上利用Zookeeper实现Master主从备份
三、Spark安装配置
3.1、Spark配置文件
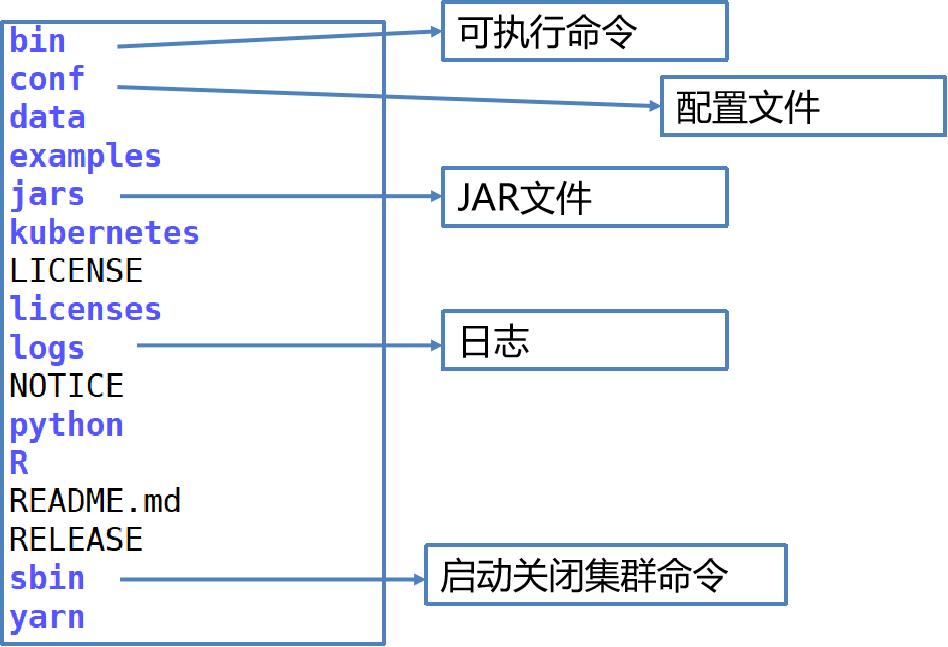
Data: spark mllib里面用到的数据;
Ec2: 部署在亚马逊云平台上的脚本
Examples:示例代码;
Python:python接口;
R:R接口
3.1.1、配置文件解读

Template是一个模板
HADOOP_CONF_DIR :Hadoop配置文件所在的路径,Spark需要找到Hadoop里面相关的东西,比如hdfs相关的地址,比如我们可能要上传数据或者日志需要存在这上面
SPARK_WORKER_INSTANCES :设置每个节点的worker进程
SPARK_WORKER_MEMORY :设置节点能给予executors的所有内存
SPARK_WORKER_CORES :设置这台机器所用的核数
SPARK_EXECUTOR_CORES :executor使用的核数
SPARK_EXECUTOR_MEMORY :每个executor的内存
Spark_WORKER_CORES :每个WORKER占用多少个核,我们给每个虚拟机配了多少核
SPARK_WORKER_INSTANCES :每个worker节点有多少个实例
比如INSTANCES配了2,有三个节点,那么就有6个WORKER,相当于HADOOP有6个节点
3.1.2、配置文件解读
3.2、配置步骤
1.上传spark-2.4.0-bin-hadoop2.6.tgz到/opt目录,并解压
tar -zxf /opt/spark-2.4.0-bin-hadoop2.6.tgz
2.进入/opt/spark-2.4.0-bin-hadoop2.6/conf
复制slaves.template:
cp slaves.template slaves
vi slaves
修改slaves,先删除其中的localhost,然后添加:
node1
node2
node3
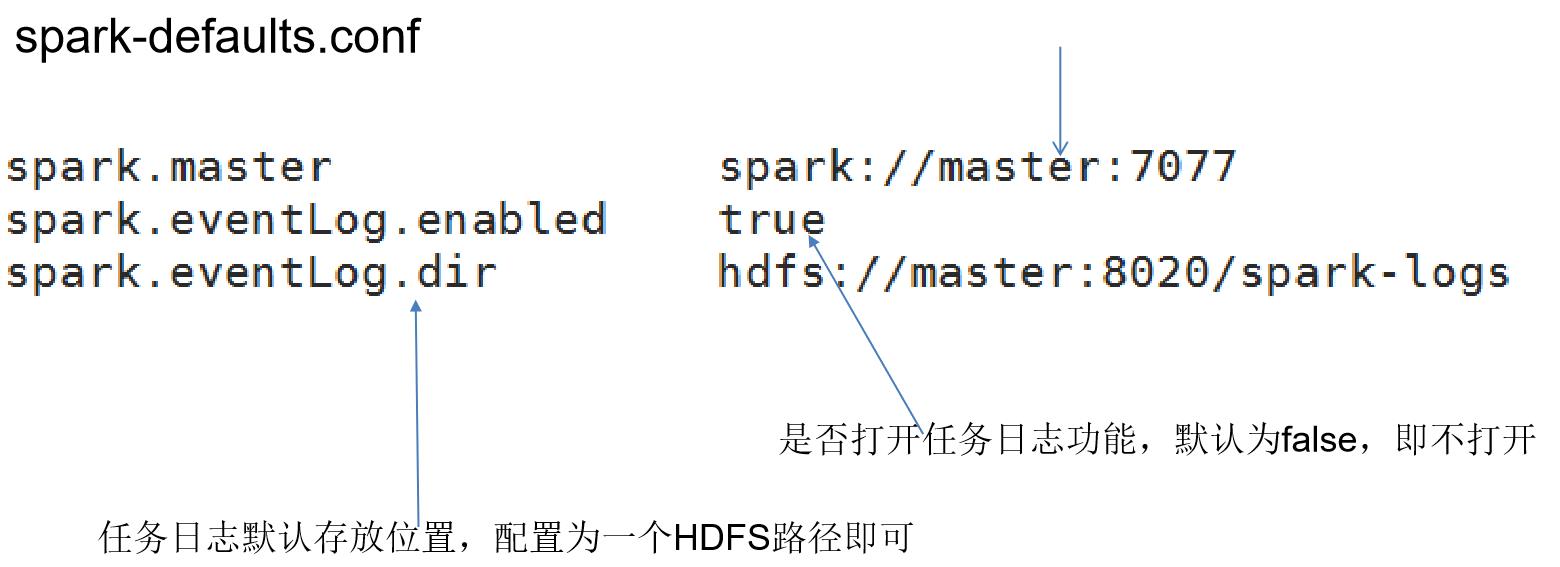
3.修改spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
添加:
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/spark-logs
spark.history.fs.logDirectory hdfs://master:8020/spark-logs
4.修改spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加:
JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
HADOOP_CONF_DIR=/opt/hadoop-3.1.4/etc/hadoop
SPARK_MASTER_IP=master
SPARK_MASTER_PORT=7077
SPARK_WORKER_MEMORY=512m
SPARK_WORKER_CORES=1
SPARK_EXECUTOR_MEMORY=512m
SPARK_EXECUTOR_CORES=1
SPARK_WORKER_INSTANCES=1
5.启动Hadoop集群,在HDFS中新建目录:
hdfs dfs -mkdir /spark-logs
6.将Spark安装包分发到其他节点
scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node1:/opt/
scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node2:/opt/
scp -r /opt/spark-2.4.0-bin-hadoop2.6/ node3:/opt/
7.在所有节点配置Spark环境变量
(master、node1、node2、node3)
vi /etc/profile
在文件尾加入:
export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
执行source /etc/profile使命令生效
8.启动spark
进入/opt/spark-2.4.0-bin-hadoop2.6/sbin
执行
./start-all.sh
9.查看客户端
http://master:8080
3.3、启动关闭Spark
进入/usr/local/spark-2.4.0-bin-hadoop2.6/
1、启动Spark
sbin/start-all.sh
2、启动日志服务
sbin/start-history-server.sh hdfs://master:8020/spark-logs
3、关闭Spark
sbin/stop-all.sh
sbin/stop-history-server.sh hdfs://master:8020/spark-logs
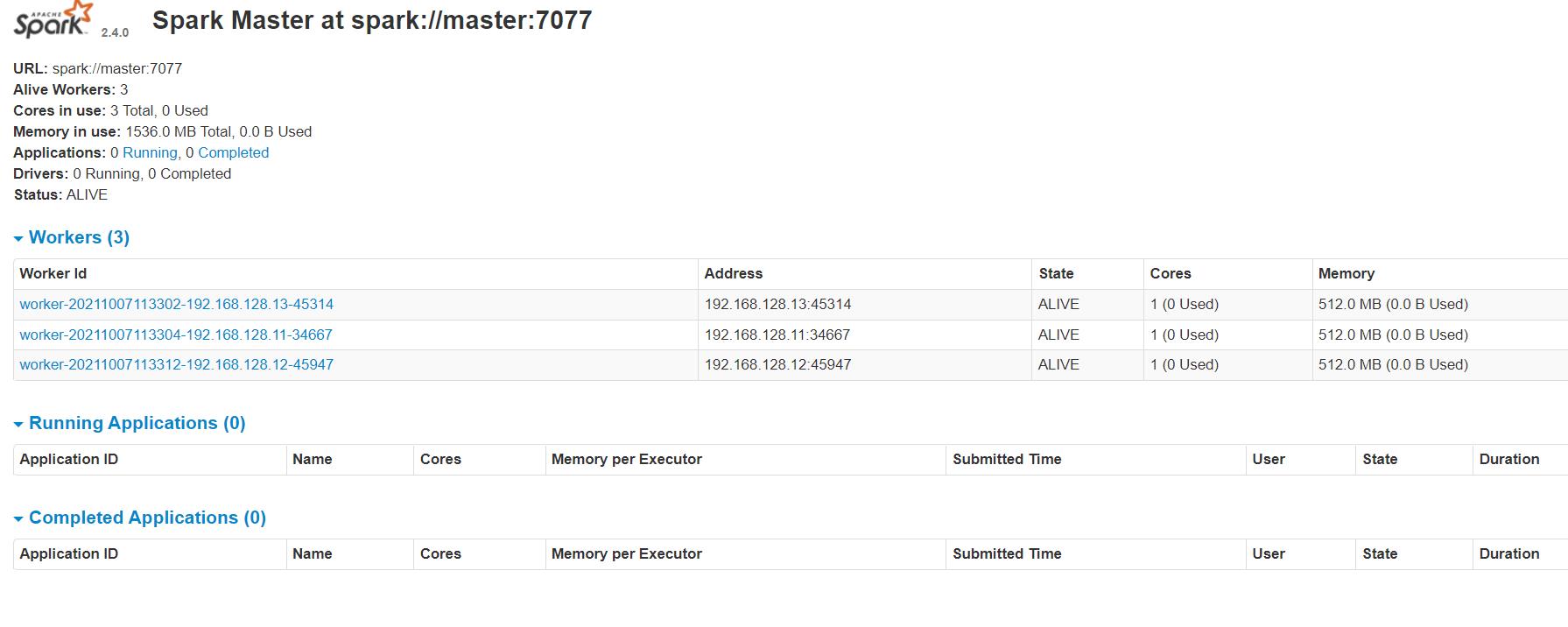
3.5、查看客户端
Spark监控:http://master:8080
四、运行第一个Spark程序
进入Spark命令行交互界面:spark-shell
退出交互界面::q
数据文件 a.txt:
I am a student
上传到hdfs的/user/root目录下
执行:
sc.textFile("/user/root/a.txt").flatMap(x=>x.split(“ “)).map(x=>(x,1)).reduceByKey(_+_)
结果展示:

以上是关于学习笔记Spark—— Spark集群的安装配置的主要内容,如果未能解决你的问题,请参考以下文章