12-flink-1.10.1-Flink中的时间语义和watermark
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了12-flink-1.10.1-Flink中的时间语义和watermark相关的知识,希望对你有一定的参考价值。
1 Fink 中的时间语义
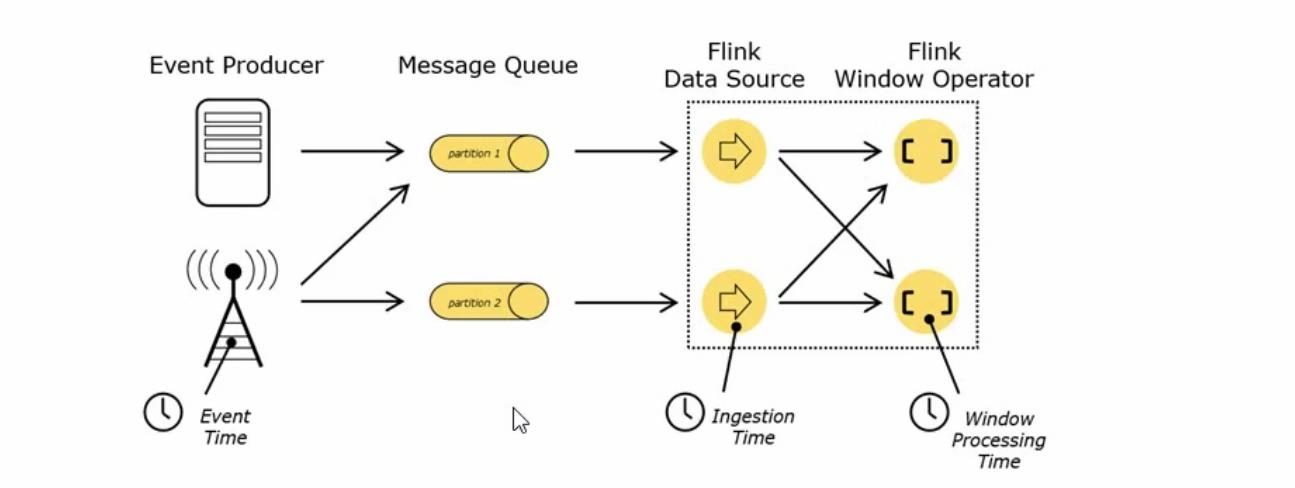
Event Time :事件产生的时候的时间,比如日志访问日志产生的时间
Ingestion Time: 数据进入flink的时间
Processing Time:执行操作算子的本地系统时间,与机器无关
1.1 哪种时间语义更重要
不同的时间语义有不同的应用场景
我们往往更关心事件的时间(Event Time)
用星球大战电影拍摄举例说明
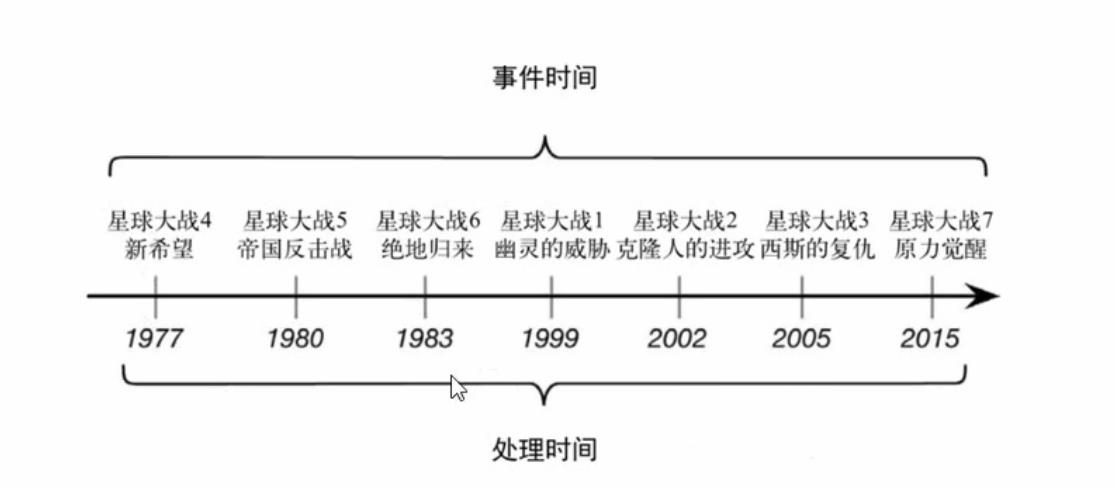
比如上面的星球大战系列电影,如果我们想统计的的是事件发生的先后顺序呢那就要关注电影情节里故事发生的时间(Event Time)。如果我们想统计的是每部电影观后体验和口碑的话就要关注电影上映的时间(Processing Time)
用计算机业内应用举例说明
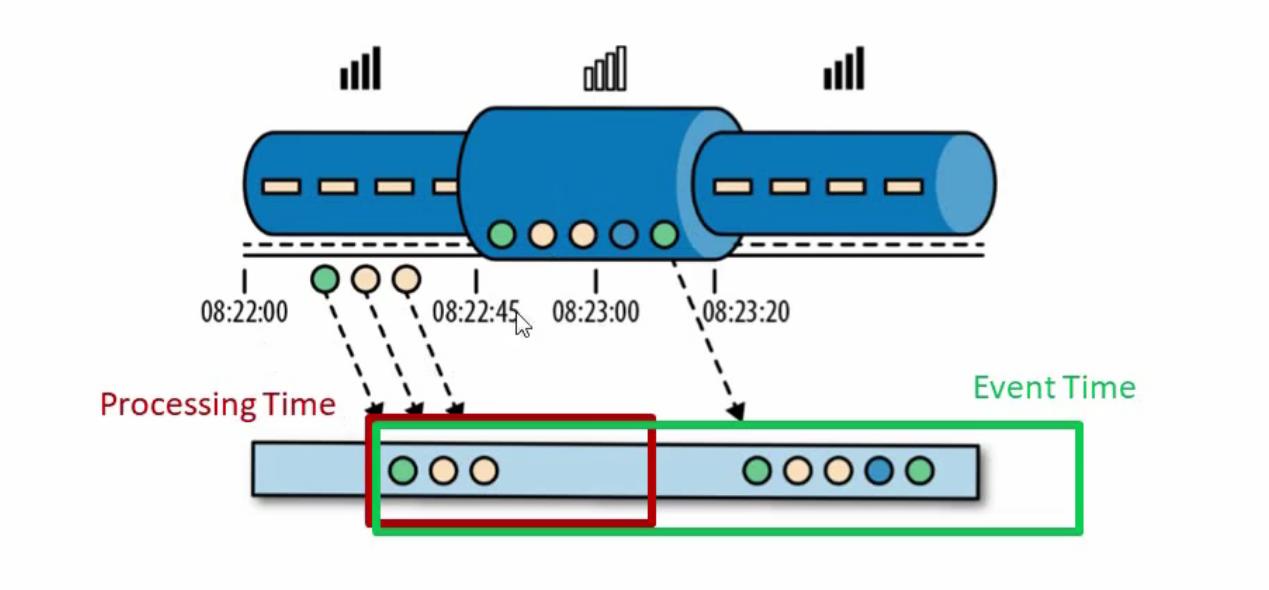
假如上图显示的是消消乐游戏,规则是如果1分钟内连续通关8关会给一定的奖励。因为消消乐可以不联网离线完,但是发放奖励是需要联网的。如上图描述的过程是,我在玩08:22:45分之前有网络的情况下已经连续通关3关了,但是08:22:45分之后突然没有网络了(比如进入地铁等等)没有网络的这段时间08:22:45~08:23:20之间又连续通关5关,加上之前的三关一共连续通关8关了,那么08:23:20以后能不能给发送奖励呢?
如果按照服务器处理时间(相当于flink processing time)1分钟内没有收到联通8关的信息,不能发送奖励,如果按照事件也就是通关事件事件(相当于flink event time)来算实际上满足奖励发放机制,可以发放奖励,从用户体验的角度来看,是要考虑使用event time事件来处理奖励方法的。

2 设置Event Time

我们可以直接在代码中,对执行环境调用setStreamTimeCharacteristic方法,设置流的市价特性
具体时间,还需要从数据中提取时间戳(timestamp)
/**创建flink流式处理环境*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//为从此环境创建的所有流设置时间特性
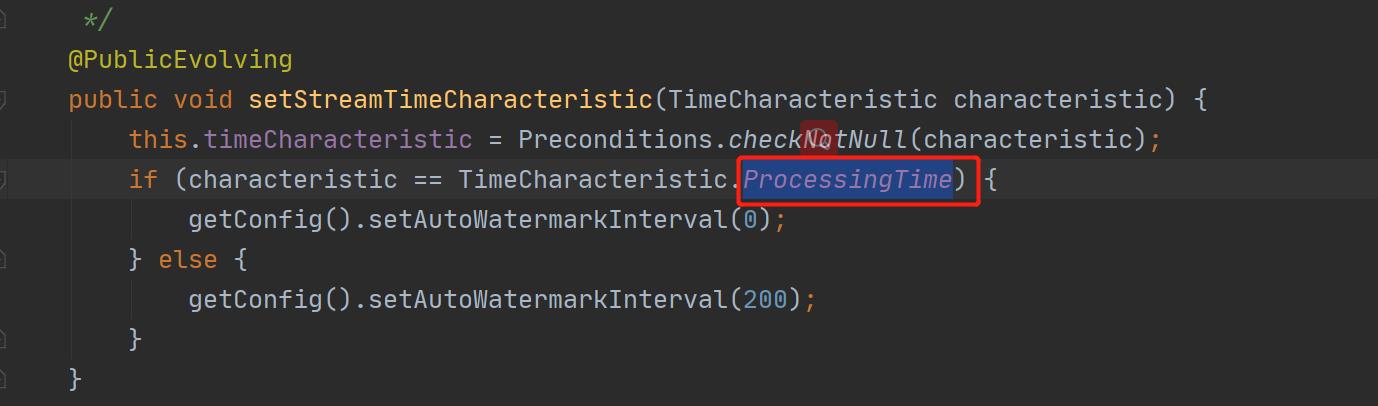
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)注意:如果我们没有指定时间语义,那么创建好的flink执行环境默认选择的是processing time ,下面的源码可以看到确实是这样的。
3 水位线(Watermark)
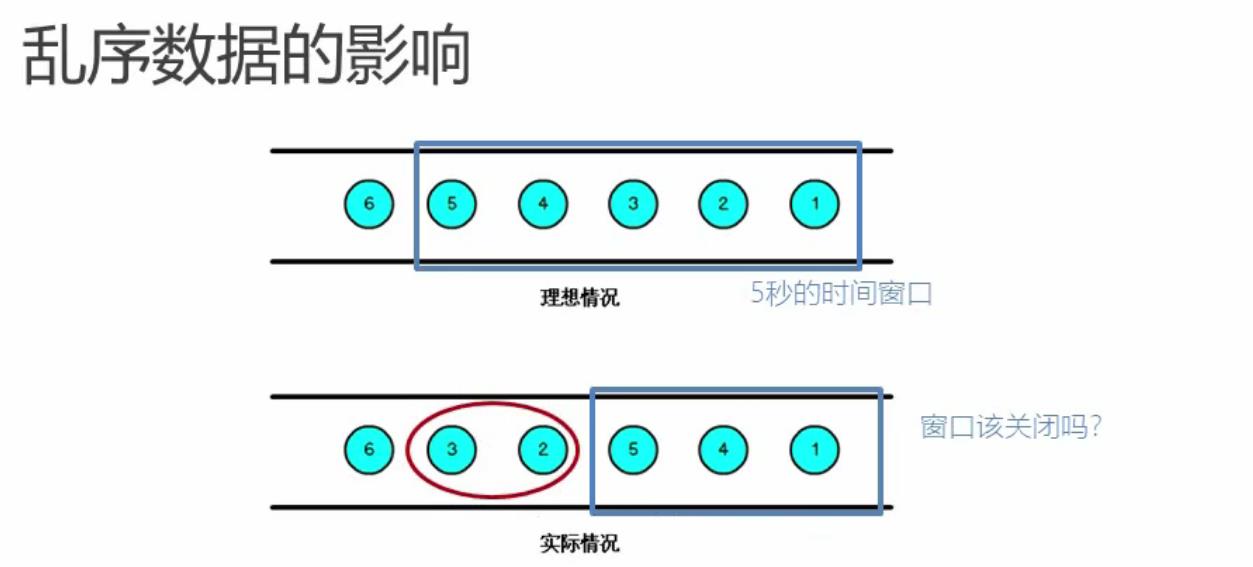

当flink以event time 模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子
由于网络,分布式等原因,会导致乱序数据的产生
乱序数据会让窗口计算不准确
3.1 水位线概念
怎样避免乱序数据带来的计算不正确?
遇到一个时间戳达到了窗口关闭的时间,不应该立刻出发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口
watermark 是一种衡量event time进展的机制,可以设定延迟出发
watermark是用于处理乱序事件的,而正确处理乱序事件,通常用watermark机制结合window来实现。
数据量中的watermark用于表示timestamp小于watermark的数据都已经到达了,因此,window的执行也是由watermark触发的,
watermark 用来让程序自己平衡延迟和结果正确性
3.2 watermark原理和特点
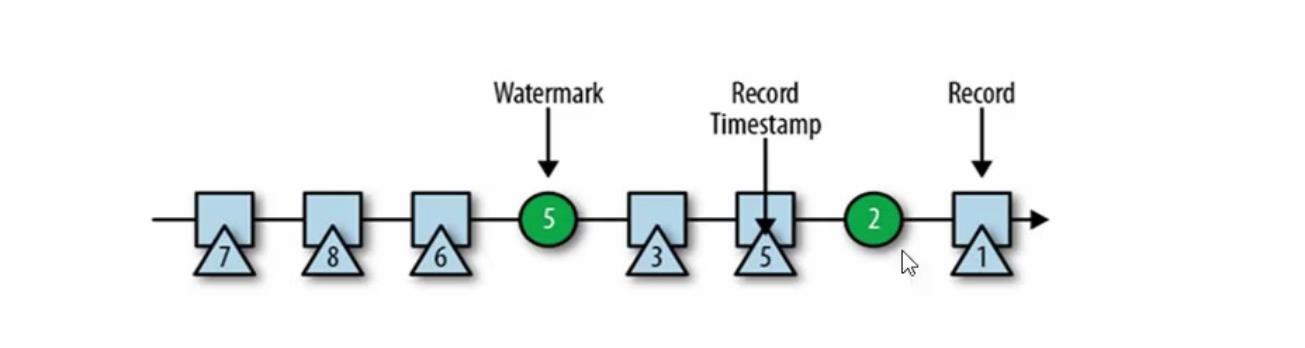
watermark 是一条特殊的数据记录
watermark 必须是单调递增的,以保证任务事件的时间时钟在向前推进,而不是在后退
watermark 与数据的时间戳相关
那么如何保证watermark必须是单调递增呢?与数据的时间戳又有什么关系呢?
watermark时间会和延迟时间一起使用,根据数据的时间戳中最大的时间戳进行一定时间延迟得到的时间就是watermark时间戳。这样就能保证watermark时间是单调递增的。
乱序数据的影响
当flink以event time模式处理数据流时,它会根据数据的时间戳来处理基于时间的算子,由于网络,分布式等原因,会导致乱序数据的产生。
watermark时间产生和窗口关闭过程
(1)根据数据乱序的程度设置延迟时间,
如上面的图片所示数据上面的数字代表第几秒,比如①代表第一秒,④代表第四秒,从①④⑤②③⑥的到达顺序可知实际情况的数据到达可知⑤之前数据都是按时间先后顺序到达的,但是⑤后面来了个②而且在之后的数据中乱序时间差最大的是⑤-②=3秒。那么我们就设置延迟时间是3秒,这样我们认为延迟三秒后所有晚到的时间都能到达flink。
公式:watermark时间搓 = 数据携带的最大时间戳 - 延迟时间
(2)设置时间窗口是5秒钟
那么就有[0,5)秒一个窗口,[5,10)秒一个窗口,以此类推左闭右开的时间窗口的桶
(3)下面演示watermark时间和窗口关闭过程
过程是从左往右的顺序数据到达到的,圆圈代表要处理的业务数据,三角形代表watermark时间戳
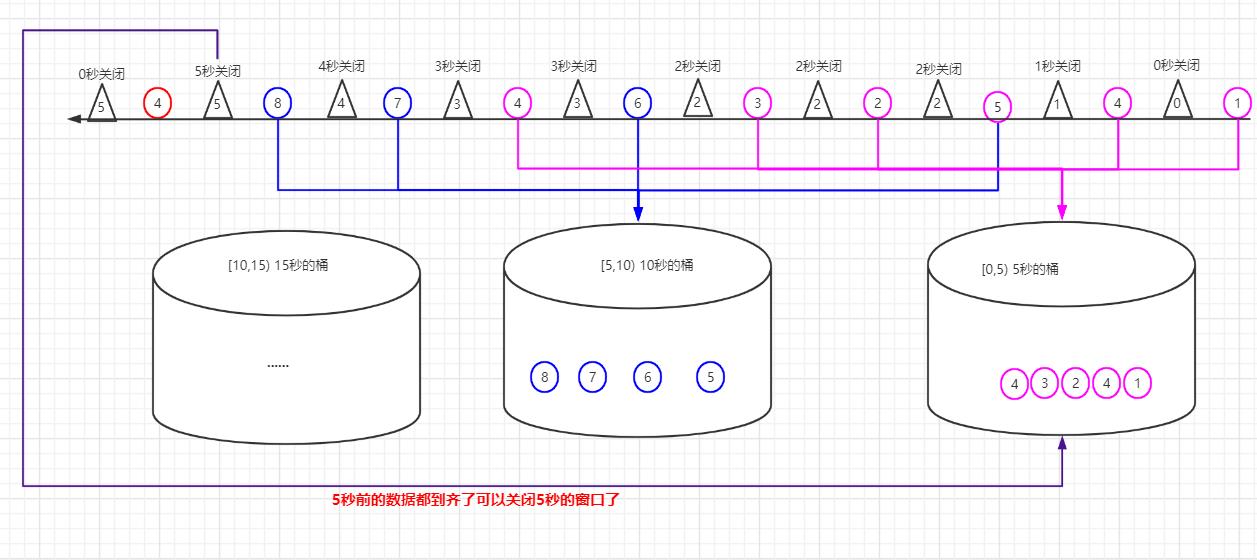
- ①秒的数据到达后,时间属于[0,5),进入5秒的桶,此时最大时间是1秒,根据(1)中公式:watermark时间搓=①-3 = -2秒,因为watermark时间搓是大于等于0的,所以生成0秒时间戳的watermark数据,说明此时延迟3秒后,0秒之前数据都到齐了,0秒的桶可以关闭了,发现没有0秒的桶,无需处理。
- ④秒的数据到达后,时间属于[0,5),进入5秒的桶,此时最大时间是4秒,根据(1)中公式:watermark时间搓=④-3=1秒,所以生成1秒时间戳的watermark数据,说明此时延迟3秒后,1秒之前数据都到齐了,1秒的桶可以关闭了,发现没有1秒的桶,无需处理。
- ⑤秒的数据到达后,时间属于[5,10),进入10秒的桶,此时最大时间是5秒,根据(1)中公式:watermark时间搓=⑤-3=2秒,所以生成2秒时间戳的watermark数据,说明此时延迟3秒后,2秒之前数据都到齐了,2秒的桶可以关闭了,发现没有2秒的桶,无需处理。
- ②秒的数据到达后,时间属于[0,5),进入5秒的桶,此时最大时间是5秒,根据(1)中公式:watermark时间搓=⑤-3=2秒,所以生成2秒时间戳的watermark数据,说明此时延迟3秒后,2秒之前数据都到齐了,2秒的桶可以关闭了,发现没有2秒的桶,无需处理。
- ③秒的数据到达后,时间属于[0,5),进入5秒的桶,此时最大时间是5秒,根据(1)中公式:watermark时间搓=⑤-3=2秒,所以生成2秒时间戳的watermark数据,说明此时延迟3秒后,2秒之前数据都到齐了,2秒的桶可以关闭了,发现没有2秒的桶,无需处理。
- ⑥秒的数据到达后,时间属于[5,10),进入10秒的桶,此时最大时间是6秒,根据(1)中公式:watermark时间搓=⑥-3=3秒,所以生成3秒时间戳的watermark数据,说明此时延迟3秒后,3秒之前数据都到齐了,3秒的桶可以关闭了,发现没有3秒的桶,无需处理。
- 第二个④秒的数据到达后,时间属于[0,5),进入5秒的桶,此时最大时间是6秒,根据(1)中公式:watermark时间搓=⑥-3=3秒,所以生成3秒时间戳的watermark数据,说明此时延迟3秒后,3秒之前数据都到齐了,3秒的桶可以关闭了,发现没有3秒的桶,无需处理。
- ⑦秒的数据到达后,时间属于[5,10),进入10秒的桶,此时最大时间是7秒,根据(1)中公式:watermark时间搓=⑦-3=4秒,所以生成4秒时间戳的watermark数据,说明此时延迟3秒后,4秒之前数据都到齐了,4秒的桶可以关闭了,发现没有4秒的桶,无需处理。
- ⑧秒的数据到达后,时间属于[5,10),进入10秒的桶,此时最大时间是8秒,根据(1)中公式:watermark时间搓=⑧-3=5秒,所以生成5秒时间戳的watermark数据,说明此时延迟3秒后,5秒之前数据都到齐了,5秒的桶可以关闭了,发现刚好有个[0,5) 5秒的桶,然后进行关闭操作,5秒桶里的数据进行相应的分析聚合等处理操作。
- 第三个④秒的数据又来了,时间属于[0,5),进入5秒的桶,发现5秒的桶已经关闭过了,没有桶可以存放了,因此这个4秒时间戳的数据就丢失了。因为这个乱序是在最大时间戳8秒之后又来了个4秒的数据,时间乱序程度是8-4=4秒>3秒(我们设定的延迟时间)。因此可以看出如果我们把延迟时间设置不合理的话会导致数据丢失。
- 以此类推处理后续源源不断近来的流数据,进行相应的处理
总结:watermark时间和延迟时间使我们可以通过灵活调节延迟时间和watermark的时间戳来控制flink计算的准确性和实时性,从上面的时间推演可知,准确性和延迟时间是正相关的,实时性和延迟时间是逆相关的。
4 watermark的传递,引入和设置
4.1 watermark的传递
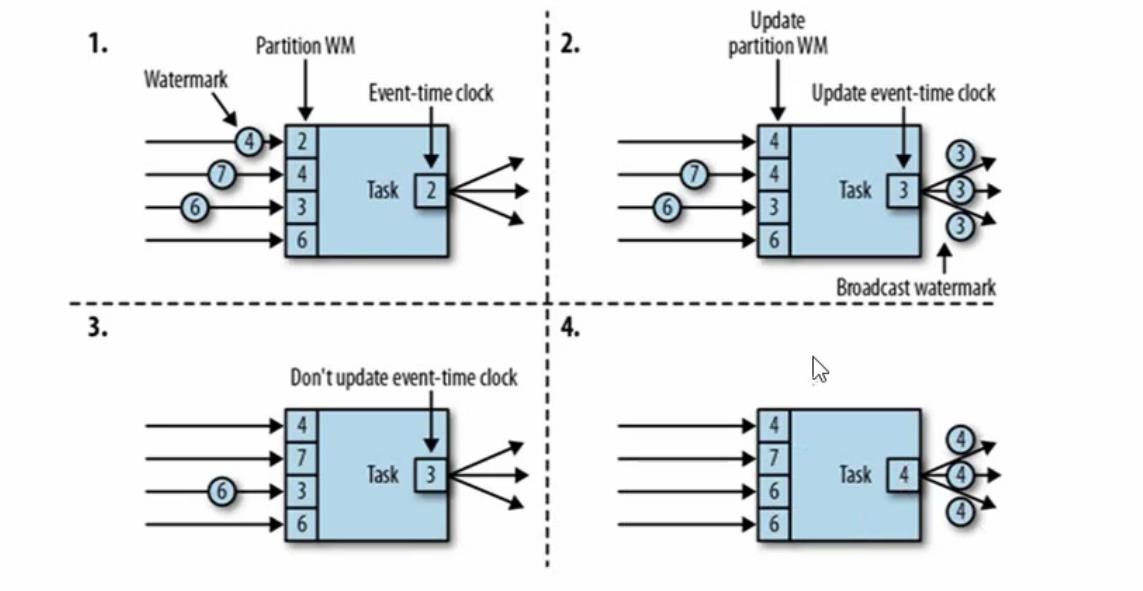
上面我们知道watermark的原理和特点,那么watermark时间戳是怎么在一个一个算子之间传递的呢?如果没有并行处理存在的话很简单一个个传递就行了,但是flink是分布式流处理引擎,所以是有分布式并行处理的情况的。为了解决watermark传递问题,实际上watermark时间的传递是直接广播出去的。比如下图的1中有3个下游并行度因此每个watermark时间戳到达的时候都是同时广播出去3个相同的时间戳到下游任务。那么下游任务又是如何接受上游时间戳的呢?当前时间又是什么呢?其实下游是以时间戳的时钟分区来接受上游传递的时间戳数据的,当前时间就是当前任务重所有时钟分区内最小的时间。
4.2 watermark代码中引入
Event Time的使用一定要指定数据源中的时间戳
调用assignTimestampAndWatermarks 方法,传入一个 BoundedOutOfOrdernessTimesampExtractor ,就可以指定watermark
package com.study.liucf.unbounded.watermark
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author liucf
* @Date 2021/9/25
*/
object LiucfWatermark {
def main(args: Array[String]): Unit = {
/**创建flink流式处理环境*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//为从此环境创建的所有流设置时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// env.setParallelism(2)
/**flink 从外部命令获取参数*/
val paramTool = ParameterTool.fromArgs(args)
val ip = paramTool.get("ip")
val port = paramTool.getInt("port")
/**监听一个流式输入端口*/
// val sockerInput: DataStream[String] = env.socketTextStream("192.168.109.151", 9999)
val sockerInput: DataStream[String] = env.socketTextStream(ip, port)
/**数据流转换*/
val transRes = sockerInput
.map(d=>{
val arr = d.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
})
// .assignAscendingTimestamps(_.timestamp * 1000L)//升序数据提取时间戳,这样不需要定义watermark时间,直接使用事件事件
// ① 断点生成watermark(来一条数据生成一个),②周期性生成watermark(不跟数据生成,按时间周期生成)
// 稠密的数据适合使用断点生成watermark,稀疏的数据适合周期性生成watermark
// 下面三重保证可以保证数据完全正确
//一,首先先设置一个较小的时间延迟,能吼住大部分数据,
//二,在window操作里使用.allowedLateness(Time.minutes(1))
//三,把延迟数据放到侧输出流里面sideOutputLateData(new OutputTag[(String, Double, Long)]("later"))
.assignTimestampsAndWatermarks(
new timestamps.BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](
Time.seconds(3)) {
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp * 1000
})
/**输出结果,打印到控制台*/
transRes.print()
/**启动流式处理*/
env.execute(" liucf watermark test")
}
}
4.3 自定义watermark

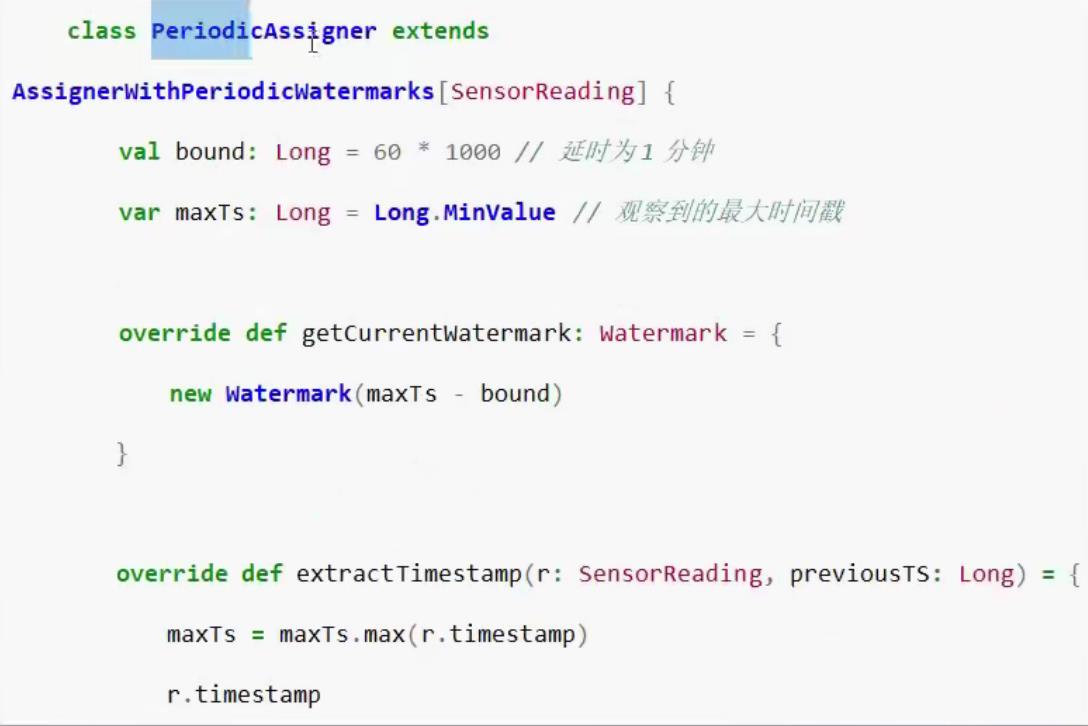

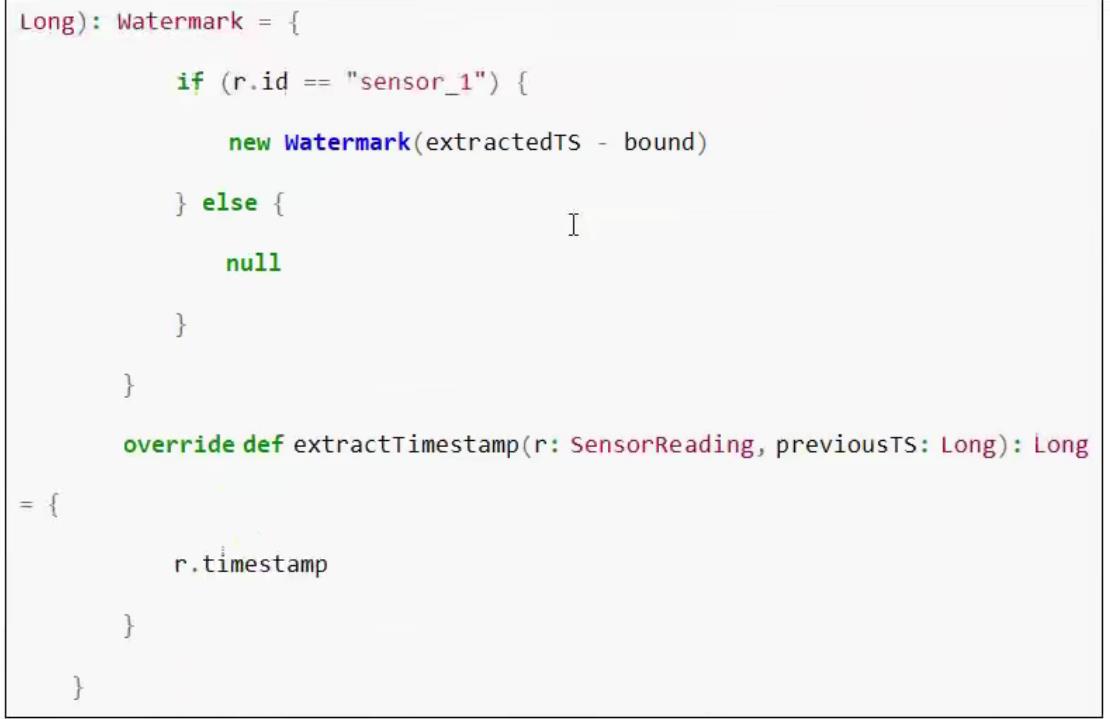
4.4 watermark的实例代码
package com.study.liucf.unbounded.watermark
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author liucf
* @Date 2021/9/25
*/
object LiucfWatermark2 {
def main(args: Array[String]): Unit = {
/**创建flink流式处理环境*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//为从此环境创建的所有流设置时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
/**flink 从外部命令获取参数*/
val paramTool = ParameterTool.fromArgs(args)
val ip = paramTool.get("ip")
val port = paramTool.getInt("port")
/**监听一个流式输入端口*/
// val sockerInput: DataStream[String] = env.socketTextStream("192.168.109.151", 9999)
val sockerInput: DataStream[String] = env.socketTextStream(ip, port)
val laterTag = new OutputTag[(String, Double, Long)]("later")
/**数据流转换*/
val transRes = sockerInput
.map(d=>{
val arr = d.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
})
// .assignAscendingTimestamps(_.timestamp * 1000L)//升序数据提取时间戳,这样不需要定义watermark时间,直接使用事件事件
// ① 断点生成watermark(来一条数据生成一个),②周期性生成watermark(不跟数据生成,按时间周期生成)
// 稠密的数据适合使用断点生成watermark,稀疏的数据适合周期性生成watermark
// 下面三重保证可以保证数据完全正确
//一,首先先设置一个较小的时间延迟,能吼住大部分数据,
//二,在window操作里使用.allowedLateness(Time.minutes(1))
//三,把延迟数据放到侧输出流里面sideOutputLateData(new OutputTag[(String, Double, Long)]("later"))
.assignTimestampsAndWatermarks(
new timestamps.BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](
Time.seconds(3)) {
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp * 1000L
})
//timestamp - (timestamp - offset + windowSize) % windowSize
val resultDs = transRes.map(d=>(d.id,d.temperature,d.timestamp))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.allowedLateness(Time.minutes(1))
.sideOutputLateData(laterTag)
.reduce((curRes,newData)=>(curRes._1,curRes._2.min(newData._2),newData._3))
//
resultDs.getSideOutput(laterTag).print("later")
/**输出结果,打印到控制台*/
resultDs.print("result")
/**启动流式处理*/
env.execute(" liucf watermark test")
}
}
4.5 运行实例测试
①启动nc
nc -l 9999② 启动 LiucfWatermark2
4.5.1 测试第一个关闭的窗口
sensor_1,1633444609,56.6
sensor_2,1633444610,30.9
sensor_3,1633444611,36.3
sensor_4,1633444612,36.4
sensor_5,1633444613,36.5
sensor_1,1633444614,36.9
sensor_1,1633444615,35.5
sensor_1,1633444616,38.1
sensor_1,1633444617,38.2
sensor_1,1633444618,38.3
sensor_1,1633444619,38.4
sensor_1,1633444620,38.5
sensor_1,1633444621,38.6
sensor_1,1633444622,38.7
sensor_1,1633444623,38.8
sensor_1,1633444924,38.9
sensor_1,1633444925,38.1因为我们不知道关闭第一个窗口是在多少秒的数据输入的时候才触发,所以我在第一条温度数据sensor_1,1633444609,56.6输入后,继续输入每隔一秒的温度数据看看到底多少秒会触发第一个15秒的窗口关闭。经过测试发现末尾第23秒(即sensor_1,1633444623,38.8)输入后触发了第一个窗口关闭,有结果打印出来
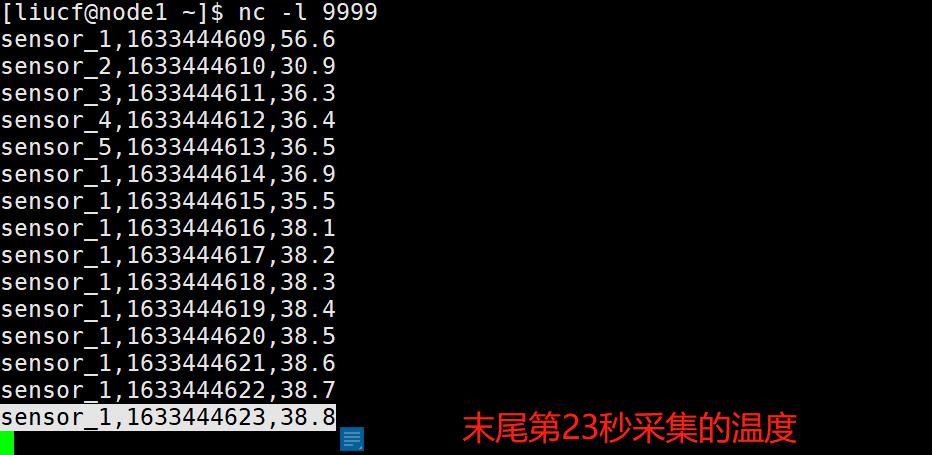
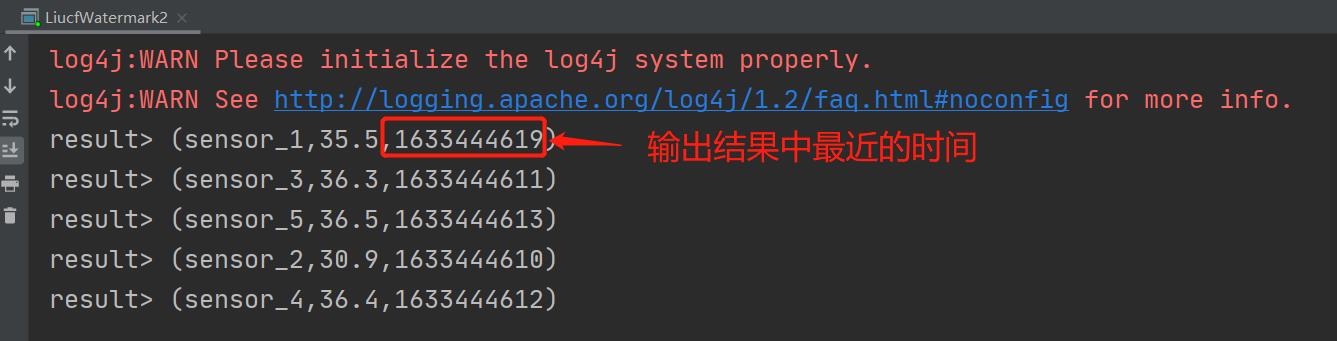
从输出结果可以看出最近的时间是1633444619那么又是1633444623秒温度输入的时候触发的,因为延迟3秒触发所以此时的watermark时间戳是1633444623-3=1633444620,因此也验证了窗口时间右边不包含1633444620本人是开区间,加上窗口是15秒的窗口那么开始时间就是1633444623-15-3=1633444605,所以1633444623输入后实际上关闭的窗口是[1633444605,1633444620)这个窗口。
那么问题来了,为什么开始时间是1633444605而不是 1633444606,1633444607等等呢?
通过代码追踪我们会发现其中的原因:①
.timeWindow(Time.seconds(15)) -->> ②
new WindowedStream(javaStream.timeWindow(size)) -->> ③
return window(TumblingEventTimeWindows.of(size)); -->> ④
long start = TimeWindow.getWindowStartWithOffset(timestamp, offset, size);-->> ⑤
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}
可见 start timestamp = timestamp - (timestamp - offset + windowSize) % windowSize
把上面的时间戳带进去:1633444609 -(1633444609 - 0 + 15 ) % 15 = 1633444605
所以第一个关闭的窗口确定为:[1633444605,1633444620)
4.5.2 推导出第二个窗口关闭
由上面第一个关闭的窗口是[1633444605,1633444620)那么下一个要被关闭的窗口将是[1633444620,1633444635) 因为有3秒的延迟所以应该是1633444635+3=1633444638秒的时间戳的数据输入的时候被触发
下面进行验证
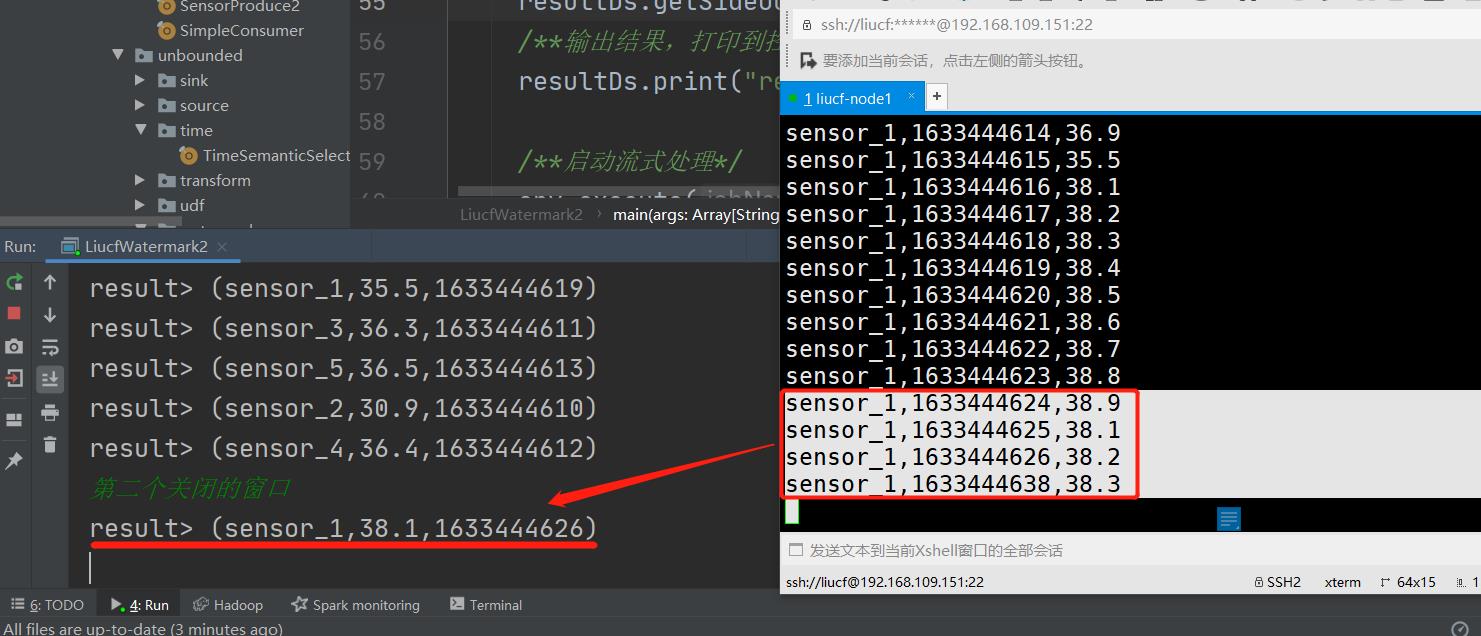
测试发现输入
sensor_1,1633444624,38.9
sensor_1,1633444625,38.1
sensor_1,1633444626,38.2
sensor_1,1633444638,38.3输入到sensor_1,1633444638,38.3关闭了第二个窗口,有结果打印。
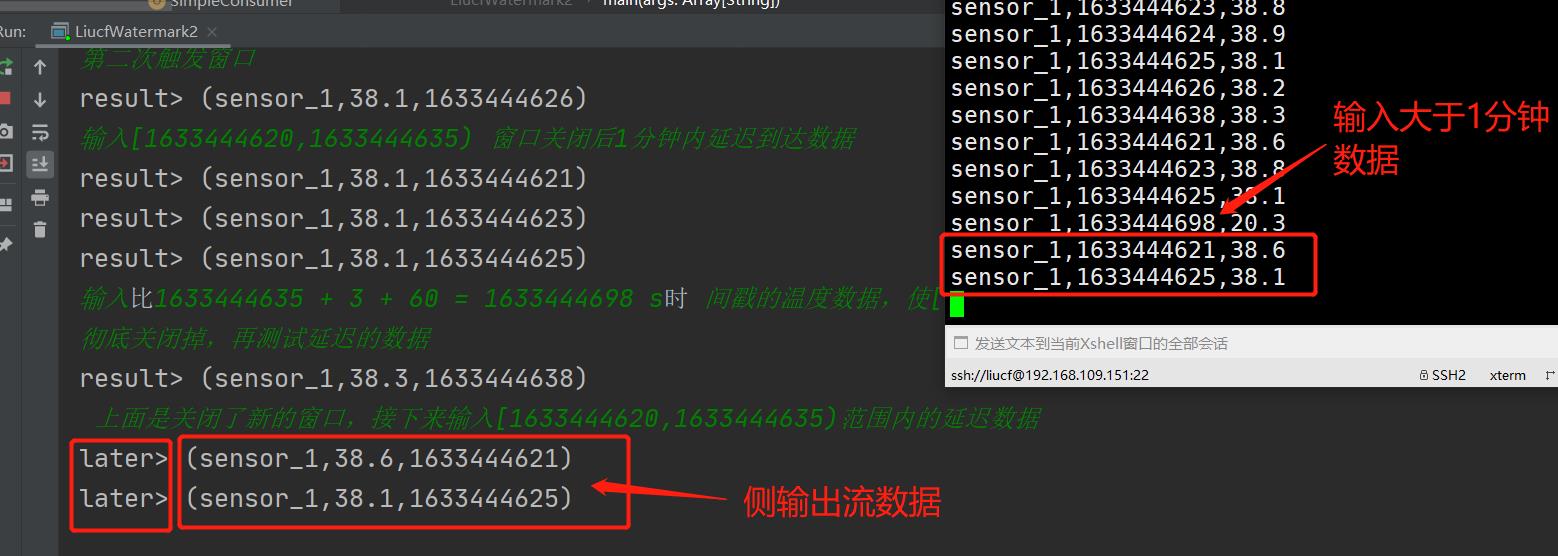
4.5.3 测试允许1分钟内迟到数据
因为代码里有下面这段代码
.allowedLateness(Time.minutes(1))
意思是允许窗口触发关闭后,1分钟内有延迟的数据进入还能被处理,说明当上面的sensor_1,1633444638,38.3输入后触发了窗口关闭但是不是立马测地关闭掉了。
那么sensor_1,1633444638,38.3输入后触发了窗口[1633444620,1633444635)关闭,这个时候1分钟内迟到的数据就应该是时间戳在[1633444620,1633444635)范围内的温度数据
比如下面这几条
sensor_1,1633444621,38.6
sensor_1,1633444623,38.8
sensor_1,1633444625,38.1
可见没输入一条就会打印一次计算的结果
因此可以看到这个时候和窗口关闭前的区别在于,关闭前不会输入一条数据就计算一次结果然后输出,说明关闭前是把数据先聚集到一起放到同一个桶内等到被watermark时间触发后在计算输出,如果是关闭后1分钟内延迟的数据会在每条输入后立马参与计算和输出。
注意:因为我选择的是事件事件,这里迟到1分钟内的数据是指输入的数据中最大时间戳减去3秒钟延迟再减去60秒大于被关闭的窗口上限的数据,是以flink接受到的最大数据事件时间戳时间为参照的。
4.5.4 测试兜底策略侧输出流
也就是当flink接收到的数据的watermark时间戳大于1分钟后被触发关闭的时间窗口会彻底关闭再次晚到的数据就不会被放到对应的时间窗口的桶里。这个时候我们可以使用侧输出流进行特殊处理,如果不处理这部分晚到的数据就会丢了。
摘录4.4 部分代码
定义侧输出流,并命名
val laterTag = new OutputTag[(String, Double, Long)]("later")
使用侧输出流
.sideOutputLateData(laterTag)
对侧输出流进行处理输出
resultDs.getSideOutput(laterTag).print("later")下面我们进行实际打印测试代码
4.5.5 整体测试输入输出和总结
输入
[liucf@node1 ~]$ nc -l 9999
sensor_1,1633444609,56.6
sensor_2,1633444610,30.9
sensor_3,1633444611,36.3
sensor_4,1633444612,36.4
sensor_5,1633444613,36.5
sensor_1,1633444614,36.9
sensor_1,1633444615,35.5
sensor_1,1633444616,38.1
sensor_1,1633444617,38.2
sensor_1,1633444618,38.3
sensor_1,1633444619,38.4
sensor_1,1633444620,38.5
sensor_1,1633444621,38.6
sensor_1,1633444622,38.7
sensor_1,1633444623,38.8 // 试探性输入结束,第一个窗口关闭被触发
sensor_1,1633444624,38.9
sensor_1,1633444625,38.1
sensor_1,1633444626,38.2
sensor_1,1633444638,38.3 // 第二个窗口关闭触发,被验证
sensor_1,1633444621,38.6
sensor_1,1633444623,38.8
sensor_1,1633444625,38.1 // 第二个窗口关闭后的一分钟内延迟数据
sensor_1,1633444698,20.3 // 输入第二个窗口一分钟后的数据使最大延迟时间戳超过1分钟,彻底关闭
sensor_1,1633444621,38.6
sensor_1,1633444625,38.1 // 输入第二个关闭的窗口,延迟超过1分钟的延迟数据,验证兜底策略
输出
 总结:flink可以通过watermark来灵活调节数据处理的准确性和及时性。对准确性的保证有3层策略
总结:flink可以通过watermark来灵活调节数据处理的准确性和及时性。对准确性的保证有3层策略
第一,watermark延迟时间
.assignTimestampsAndWatermarks(
new timestamps.BoundedOutOfOrdernessTimestampExtractor[LiucfSensorReding](
Time.seconds(3)) {
override def extractTimestamp(element: LiucfSensorReding): Long = element.timestamp * 1000L
})第二,允许处理迟的数据(时间有限)
.allowedLateness(Time.minutes(1))第三,兜底侧输出流
定义侧输出流,并命名
val laterTag = new OutputTag[(String, Double, Long)]("later")
使用侧输出流
.sideOutputLateData(laterTag)
对侧输出流进行处理输出
resultDs.getSideOutput(laterTag).print("later")以上是关于12-flink-1.10.1-Flink中的时间语义和watermark的主要内容,如果未能解决你的问题,请参考以下文章
12-flink-1.10.1-Flink中的时间语义和watermark