6.携程架构实践 --- 数据库
Posted enlyhua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6.携程架构实践 --- 数据库相关的知识,希望对你有一定的参考价值。
第6 章 数据库
6.1 上传发布
数据库的上传发布,简而言之,就是DDL操作的过程,主要包括表的创建,表结构的调整,索引的调整等。
6.1.1 表结构设计规范
1.创建表的存储引擎必须是InnoDB:不能选择其他引擎
2.每张表必须有主键且不能使用联合主键:每行数据都能被唯一区分
3.默认使用utf8mb4字符集:uft8mb4字符集支持emoji表情符
4.每张表必须有modifytime字段:该字段定义为 " `modifytime` timestamp(3) not null default current_timestamp(3) on update current_timestamp(3) comment '更新时间' ",并强制对该字段创建索引
5.推荐使用 createtime字段:默认值设置为 current_timestamp,该字段用于记录行创建时间
6.不允许使用外键:表之间的关联关系通过应用层进行保证
7.自增字段必须是主键或唯一索引:避免复杂表结构
8.所有声明为 not null 的字段必须显式指定默认值
9.使用 text 字段必须审批:text 字段对mysql主从复制,网络带宽,数据库性能影响都比较大,是数据库不稳定因素之一
10.禁止使用视图,触发器和存储过程:应用逻辑应当放在应用上
11.表和字段必须添加备注说明,以利于被数字字典采集和展现
6.1.2 数据库表结构的发布
数据库则是在发布的时候风险最高。分为两种,一种是新增;一种是修改。
数据库表结构字段的发布有几种方法:
1.原生语法。风险比较高,发布期间服务器负载容易上升;
2.使用开源的 pt-osc 工具。其原理是对要变更的表设置触发器,收集语句的变化,保证临时表和变更表的数据一致性。触发器对服务器性能影响比较
大,尤其对于热表,所以也不是最佳选择。
3.使用 gh-ost 工具来实现表结构字段的发布。其原理是通过 binlog 来复制数据,并应有到临时表上,然后进行交换表名操作。
gh-ost 发布对服务器性能影响远远小于前面两种方案,使用这个工具主要有两个限制:
1.数据库的主从复制必须是行模式;
2.需要特别注意剩余空间问题和主从复制延迟问题。
6.1.3 SQL Server 的特殊之处
6.2 监控告警
6.2.1 数据库大盘监控
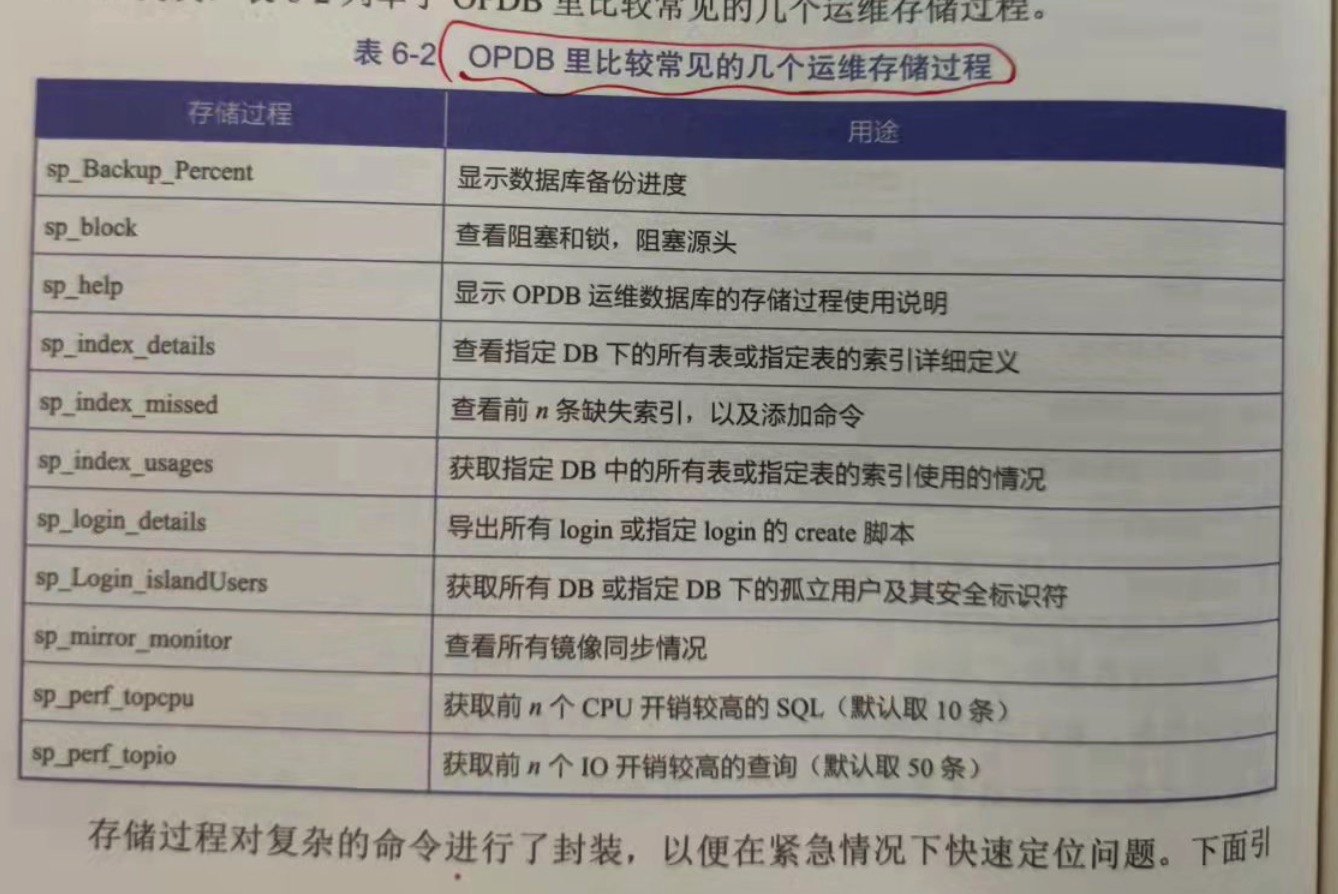
6.2.2 运维数据库OPDB
数据库运维,一旦出现紧急故障,就需要一个速查手册,用于快速定位问题。OPDB就是为此创建,我们在每台数据库服务器上都部署了这个运维数据库,并
通过里面的表记录运维监控数据,通过存储过程记录速查命令。
6.2.3 语句监控
进行全量语句监控。
6.3 数据库高可用
我们推荐数据库三副本,一主一从一异地容灾。
6.3.1 SQL Server 高可用
6.3.2 MySQL 高可用
1.采用传统的MHA管理方式
本质上,MHA是一个管理mysql主从复制架构的工具集。应用可以通过vip进行访问,vip地址挂在在主节点上。MHA管理节点每个10s探测并连接主机,
如果3次连不上,则判定主机故障,触发切换。在发生切换时,MHA结合半同步复制,补全未同步的日志,这种切换可以保证数据完整。
传统的MHA架构比较成熟,使用广泛,但存在风险。如果由于交换机故障,MHA管理节点连接不上主机,但主机本身运行正常,MHA管理工具无法判断是网络
故障还是服务器故障,就会进行切换,并且把vip挂在到slave节点,但MHA管理节点连不上旧主机,无法删除vip。此时两个节点都有vip存在,就会发生数据
双写,也就是"脑裂"。这种情况很少发生,一旦发生,就难以处理,起因就在于vip。解决的方法是把vip删除,使用物理ip进行直连。这就需要数据库访问DAL
模块和统一配置中心。
2.使用IP直连
初始的时候,应用程序使用物理ip1访问数据库。MHA管理节点探测到主节点发生了故障,预备切换到ip2,并将ip地址变更通知配置中心。统一配置中心
在收到这个变化后,会把这个变化推送到应用服务器的数据库访问中间件DAL。DAL会重置对数据库的连接,使用新的ip地址。
极端情况下,还是存在风险。如果机房整体发生故障,MHA管理节点和主机/从机同时无法运行,MHA就无法自动切换到DR节点。
3.引入多MHA管理节点
应用物理ip1访问数据库。每一个数据库实例由5个MHA管理节点同时监听。这5个MHA分布在3个机房。一旦某个mha管理节点探测到主机发生了异常,则
标记为 SDOWN。但一个mha节点无法决定主机是否真的发生了故障,该mha需要发起协商流程,和其他mha一同判断,如果多数mha认为发生了故障,则标记为
ODOWN,也就是确定主机真的发生了故障。mha会检测并决定可以成为备选主节点的节点,并由5个mha再次协商,推选一个管理节点,用来向统一配置中心汇报
ip地址变化。如果机房发生故障,并且另一个ip2不可用,则可选择主节点为ip3。统一配置中心会把这个变化推送到DAL组件,并重置连接,使用新的ip地址。
5节点mha管理是稳定的。其中一个管理节点处于第三机房,能抵御单机房故障。mha管理节点的协商比较复杂,我们可以借助redis的哨兵管理机制,在
redis哨兵管理机制上进行改造,适配对mysql的监控。
6.3.3 Redis 高可用架构
redis 由哨兵来监控redis实例的运行状态。我们启用了5个哨兵来同时监听,哨兵的主要功能为:
1.监控所有实例是否正常运行;
2.当slave故障时,通过消息通知机制把该slave拉出,并将其设置为不可用,同时把master设置为可读,可写;
3.当master发生故障时,通过自动拉票机制从slave节点选出master,实现redis自动切换。
哨兵实际上是运行在特殊模式下的redis服务,可以通过启动命令参数中添加 sentinel 选项,来表示该redis服务是哨兵。每一个哨兵会向其他哨兵,
即master或者slave定时发送消息,以确认对方是否正常运行,如果发现对方在指定时间内未响应,则暂时认为对方主观挂机(subjective down,sdown),
如果哨兵集群中多数哨兵都报告某个master没有反应,系统就会认为该master客观挂机(objective down,odown)。

















































以上是关于6.携程架构实践 --- 数据库的主要内容,如果未能解决你的问题,请参考以下文章