✨三万字制作,关于C语言,你必须知道的这些知识点(高阶篇)✨
Posted /少司命
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了✨三万字制作,关于C语言,你必须知道的这些知识点(高阶篇)✨相关的知识,希望对你有一定的参考价值。

目录
一,写在前面
说实话,我上一篇写的基础篇能上全站热搜榜一,真的是诚惶诚恐,觉得自己配不上这个榜一,分享内容其实没那么好,得到C站的朋友的认可,有点小开心,这会更加督促我提升自己的水平,提升自己博客的质量,对的起大家的认可。学习本篇之前可以学习我上一篇的博客,有利于本篇更好的理解和学习。点击标题即可跳转到相应博文哟。
上一篇讲的是基础,这篇讲的是高阶版,需要多练习多揣摩,本篇文章是之前学习C语言的总结,制作主要是我复习用的,既然是知识,当然分享是很重要的,还是那句老话,如果你认为这篇博客写的不错的话,求评论,求收藏,求点赞,您的三连是我最大的制作动力,本文大约三万字,没有时间看完可以收藏抽时间看,部分内容我以链接形式展示,废话不多说,让我们学起来吧!!!
二,数据的存储
1,数据类型介绍
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长的整形
float //单精度浮点数
double //双精度浮点数类型的意义:
使用这个类型开辟内存空间的大小(大小决定了使用范围)。
如何看待内存空间的视角。
2,类型的基本归类
整形家族
char
unsigned char
signed char
short
unsigned short[int]
signed short[int]
int
unsigned int
signed int
long
unsigned long[int]
signed long[int]浮点数家族
float
double构造类型
数组类型
结构体类型 struct
枚举类型 enum
联合类型 unionint main()
{
unsigned char a = 200;
unsigned char b = 100;
unsigned char c = 0;
c = a + b;
printf("%d %d", a + b, c);
return 0;
}程序的执行结果为( )
A.300 300
B.44 44
C.300 44
D.44 300
说明:printf在传入参数的时候如果是整形会默认传入四字节,所以a+b的结果是用一个四字节的整数接收的,不会越界。而c已经在c = a + b这一步中丢弃了最高位的1,所以只能是300-256得到的44了。
※由于printf是可变参数的函数,所以后面参数的类型是未知的,所以甭管你传入的是什么类型,printf只会根据类型的不同将用两种不同的长度存储。其中8字节的只有long long、float和double(注意float会处理成double再传入),其他类型都是4字节。所以虽然a + b的类型是char,实际接收时还是用一个四字节整数接收的。另外,读取时,%lld、%llx等整型方式和%f、%lf等浮点型方式读8字节,其他读4字节。
3,整形在内存中的存储
原码、反码、补码
原码
直接将二进制按照正负数的形式翻译成二进制就可以。
反码
将原码的符号位不变,其他位依次按位取反就可以得到了。
补码
反码+1就得到补码。
想了解原反补码的计算和进制的可以看看我之前的博客,二进制的讲解
原码、反码、补码说法错误的是( )
A.一个数的原码是这个数直接转换成二进制
B.反码是原码的二进制符号位不变,其他位按位取反
C.补码是反码的二进制加1
D.原码、反码、补码的最高位是0表示负数,最高位是1表示正数
ABC正确,D关于符号位的描述说反了
数据在内存的储存
#include<stdio.h>
int main()
{
int a = 1;
int b = -2;
return 0;
}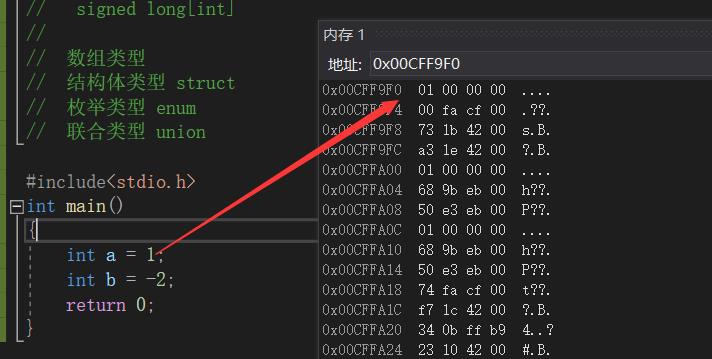
数据在内存中存储中有大小端之分
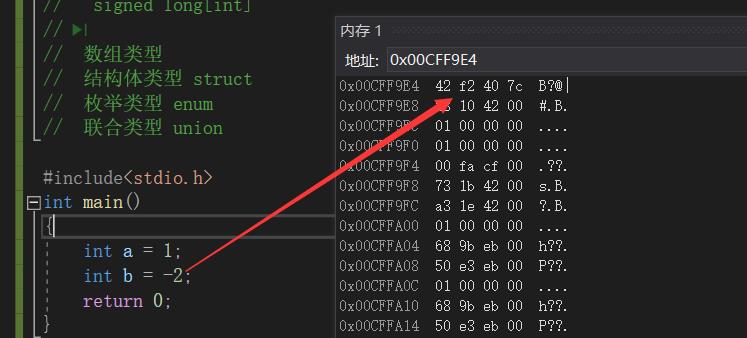
正数的原、反、补码都相同。
对于整形来说:数据存放内存中其实存放的是补码。
大小端介绍
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
为什么有大端和小端
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一 个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具 体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字 节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。 例如一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小 端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小 端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
unsigned int a = 0x1234;
unsigned char b = *(unsigned char*)&a;在32位大端模式处理器上变量b等于( )
大端序中,低地址到高地址的四字节十六进制排列分别为00 00 12 34,其中第一个字节的内容为00,故选A
关于大小端字节序的描述正确的是( )
A.大小端字节序指的是数据在电脑上存储的二进制位顺序
B.大小端字节序指的是数据在电脑上存储的字节顺序
C.大端字节序是把数据的高字节内容存放到高地址,低字节内容存放在低地址处
D.小端字节序是把数据的高字节内容存放到低地址,低字节内容存放在高地址处
小端字节序: 低位放在低地址
大端字节序:高位放在低地址
下面代码的结果是( )
int main()
{
char a[1000] = { 0 };
int i = 0;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}a是字符型数组,strlen找的是第一次出现尾零(即值为0)的位置。考虑到a[i]其实是字符型,如果要为0,则需要-1-i的低八位要是全0,也就是问题简化成了“寻找当-1-i的结果第一次出现低八位全部为0的情况时,i的值”(因为字符数组下标为i时第一次出现了尾零,则字符串长度就是i)。只看低八位的话,此时-1相当于255,所以i==255的时候,-1-i(255-255)的低八位全部都是0,也就是当i为255的时候,a[i]第一次为0,所以a[i]的长度就是255了
4,浮点型在内存中的存储
常见的浮点数:
3.14159 1E10 浮点数家族包括: float、double、long double 类型。 浮点数表示的范围:float.h中定义
举个例子
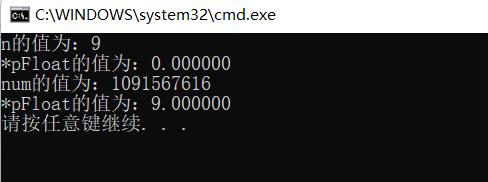
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\\n", n);
printf("*pFloat的值为:%f\\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\\n", n);
printf("*pFloat的值为:%f\\n", *pFloat);
return 0;
}
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说: 十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。 那么,按照上面V的格式,可以得出s=0, M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,s=1,M=1.01,E=2。
IEEE 754对有效数字M和指数E,还有一些特别规定。
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前 加上第一位的1。 比如: 0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位, 则为1.0*2^(-1),其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位 00000000000000000000000,则其二进制表示形式为:
0 01111110 00000000000000000000000E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值, 有效数字M不再加上第一位的1,而是还原为 0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
解释前面的题目:
下面,让我们回到一开始的问题:为什么 0x00000009 还原成浮点数,就成了 0.000000 ? 首先,将 0x00000009 拆 分,得到第一位符号位s=0,后面8位的指数 E=00000000 ,最后23位的有效数字M=000 0000 0000 0000 0000 1001。
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成: V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146) 显然,V是一个很小的接近于0的正数,所以用十进制小 数表示就是0.000000。
再看例题的第二部分。 请问浮点数9.0,如何用二进制表示?还原成十进制又是多少? 首先,浮点数9.0等于二进制 的1001.0,即1.001×2^3。
9.0 -> 1001.0 ->(-1) ^ 01.0012 ^ 3->s = 0, M = 1.001, E = 3 + 127 = 130那么,第一位的符号位s=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130,即 10000010。 所以,写成二进制形式,应该是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000这个32位的二进制数,还原成十进制,正是 1091567616 。
三,指针的进阶
1,字符指针
一般使用
int main()
{
char ch = 'w';
char* pc = &ch;
*pc = 'w';
return 0;
}
高阶使用
int main()
{
char* pstr = "hello bit.";
printf("%s\\n", pstr);
return 0;
}
下面练习一道题
#include <stdio.h>
int main()
{
char str1[] = "hello word.";
char str2[] = "hello word.";
char* str3 = "hello word.";
char* str4 = "hello word.";
if (str1 == str2)
printf("str1 and str2 are same\\n");
else
printf("str1 and str2 are not same\\n");
if (str3 == str4)
printf("str3 and str4 are same\\n");
else
printf("str3 and str4 are not same\\n");
return 0;
}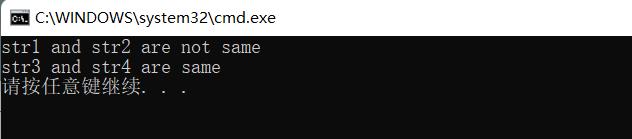
这里str3和str4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区域, 当几个指针。指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始 化不同的数组的时候就会开辟出不同的内存块。所以str1和str2不同,str3和str4不同。
下面关于"指针"的描述不正确的是:( )
A.当使用free释放掉一个指针内容后,指针变量的值被置为NULL
B.32位系统下任何类型指针的长度都是4个字节
C.指针的数据类型声明的是指针实际指向内容的数据类型
D.野指针是指向未分配或者已经释放的内存地址
Afree不会更改指针的指向。
B选项强调了32位系统,所以没问题。
CD选项是定义本身。
所以排除法也可以确定是A
关于下面代码描述正确的是:( )
char* p = "hello word";A.把字符串hello bit存放在p变量中
B.把字符串hello bit的第一个字符存放在p变量中
C.把字符串hello bit的第一个字符的地址存放在p变量中
D.*p等价于hello bit
双引号引起来的这一段是一个常量字符串,本质是一个常量字符数组类型,赋给一个指针,相当于把一个数组的首地址赋给指针,即第一个元素h的地址。
只有选项C提到了第一个字符的地址,故选C
2,指针数组
定义
指针数组:能够指向数组的指针。
int* p1[10];
int(*p2)[10];
//p1, p2分别是什么?
int (*p)[10];
//解释:p先和*结合,说明p是一个指针变量,然后指着指向的是一个大小为10个整型的数组。所以p是一个
指针,指向一个数组,叫数组指针。
//这里要注意:[]的优先级要高于*号的,所以必须加上()来保证p先和*结合。&数组名VS数组名
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
printf("%p\\n", arr);
printf("%p\\n", &arr);
return 0;

可见数组名和&数组名打印的地址是一样的。
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
printf("arr = %p\\n", arr);
printf("&arr= %p\\n", &arr);
printf("arr+1 = %p\\n", arr + 1);
printf("&arr+1= %p\\n", &arr + 1);
return 0;
}
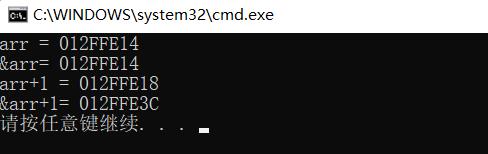
根据上面的代码我们发现,其实&arr和arr,虽然值是一样的,但是意义应该不一样的。 实际上: &arr 表示的是数组的地址,而不是数组首元素的地址。(细细体会一下) 数组的地址+1,跳过整个数组的大小,所以 &arr+1 相对于 &arr 的差值是40.
下面哪个是数组指针( )
A.int** arr[10]
B.int (*arr[10])
C.char *(*arr)[10]
D.char(*)arr[10]
A是二级指针数组,B是指针数组,C是char *数组的指针,D是char *的数组。只有C是数组指针。
tip:根据优先级看只有C选项优先跟*结合,其他都不是指针,所以直接选C。
下面哪个代码是错误的?( )
#include <stdio.h> int main() { int* p = NULL; int arr[10] = { 0 }; return 0; }A.p = arr;
B.int (*ptr)[10] = &arr;
C.p = &arr[0];
D.p = &arr;
就数据类型来看,A左右两边都是int *,B左右两边都是 int (*)[10],C左右两边都是int *,D左边是 int *,右边是 int (*)[10],故选D。
下面代码关于数组名描述不正确的是( )
int main() { int arr[10] = {0}; return 0; }A.数组名arr和&arr是一样的
B.sizeof(arr),arr表示整个数组
C.&arr,arr表示整个数组
D.除了sizeof(arr)和&arr中的数组名,其他地方出现的数组名arr,都是数组首元素的地址
A选项错误明显。arr的类型是int [10],而&arr的类型是int (*)[10],根本不是一个类型,不可能是一样的。而在 sizeof(arr)和&arr中,arr都是看成整体的,而一般它代表一个数组的首地址。
3,数组指针的使用
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,0 };
int(*p)[10] = &arr;//把数组arr的地址赋值给数组指针变量p
//但是我们一般很少这样写代码
return 0;
}一个数组指针的使用
#include <stdio.h>
void print_arr1(int arr[3][5], int row, int col)
{
int i, j;
for (i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
printf("%d ", arr[i][j]);
}
printf("\\n");
}
}
void print_arr2(int(*arr)[5], int row, int col)
{
int i, j;
for (i = 0; i < row; i++)
{
for (j = 0; j < col; j++)
{
printf("%d ", arr[i][j]);
}
printf("\\n");
}
}
int main()
{
int arr[3][5] = { 1,2,3,4,5,6,7,8,9,10 };
print_arr1(arr, 3, 5);
//数组名arr,表示首元素的地址
//但是二维数组的首元素是二维数组的第一行
//所以这里传递的arr,其实相当于第一行的地址,是一维数组的地址
//可以数组指针来接收
print_arr2(arr, 3, 5);
return 0;
}

4,函数指针
#include <stdio.h>
void test()
{
printf("hehe\\n");
}
int main()
{
printf("%p\\n", test);
printf("%p\\n", &test);
return 0;
}

pfun1可以存放。pfun1先和*结合,说明pfun1是指针,指针指向的是一个函数,指向的函数无 参数,返回值类型为void。
5,函数指针数组
要把函数的地址存到一个数组中,那这个数组就叫函数指针数组,那函数指针的数组如何定义呢?
int (*parr1[10]])();
int* parr2[10]();
int (*)() parr3[10];parr1 parr1 先和 [] 结合,说明parr1是数组,数组的内容是什么呢? 是 int (*)() 类型的 函数指针
下面哪个是函数指针?( )
A.int* fun(int a, int b);
B.int(*)fun(int a, int b);
C.int (*fun)(int a, int b);
D.(int *)fun(int a, int n);
ABD没有区别,加的括号没有影响任何优先级,都是返回值为int *的函数,故选C。
定义一个函数指针,指向的函数有两个int形参并且返回一个函数指针,返回的指针指向一个有一个int形参且返回int的函数?下面哪个是正确的?( )
A.int (*(*F)(int, int))(int)
B.int (*F)(int, int)
C.int (*(*F)(int, int))
D.*(*F)(int, int)(int)
D类型不完整先排除,然后看返回值,B的返回值是int,C的返回值是int *,故选A。判断返回值类型只需要删掉函数名/函数指针和参数列表再看就行了。int (*(*F)(int, int))(int)删掉(*F)(int, int)后剩下int (*)(int),符合题意
在游戏设计中,经常会根据不同的游戏状态调用不同的函数,我们可以通过函数指针来实现这一功能,下面哪个是:一个参数为int *,返回值为int的函数指针( )
A.int (*fun)(int)
B.int (*fun)(int *)
C.int* fun(int *)
D.int* (*fun)(int *)
首先C压根就不是函数指针,先排除,然后D返回值不是int,排除,A的参数不是int *,排除,剩下B了。
声明一个指向含有10个元素的数组的指针,其中每个元素是一个函数指针,该函数的返回值是int,参数是int*,正确的是( )
A.(int *p[10])(int*)
B.int [10]*p(int *)
C.int (*(*p)[10])(int *)
D.int ((int *)[10])*p
A选项,第一个括号里是一个完整定义,第二个括号里是个类型,四不像。BD选项,[]只能在标识符右边,双双排除。只有C是能编过的。
6,回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一 个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该 函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或 条件进行响应。
#include <stdio.h>
//qosrt函数的使用者得实现一个比较函数
int int_cmp(const void* p1, const void* p2)
{
return (*(int*)p1 - *(int*)p2);
}
int main()
{
int arr[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };
int i = 0;
qsort(arr, sizeof(arr) / sizeof(arr[0]), sizeof(int), int_cmp);
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
printf("\\n");
return 0;
}
7,指针和数组笔试题
一维数组
int main()
{
int a[] = { 1,2,3,4 };
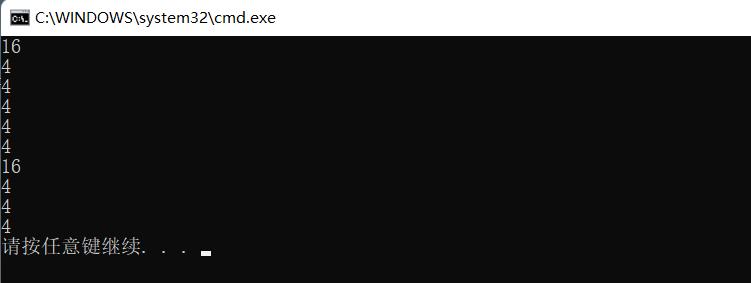
printf("%d\\n", sizeof(a));
//数组名a单独放在sizeof内部,数组名表示整个数组,计算的是整个数组的大小
printf("%d\\n", sizeof(a + 0));
//a表示首元素的地址,a+0还是首元素的地址,地址的大小是4/8字节
printf("%d\\n", sizeof(*a));
//a表示首元素的地址,*a 就是首元素 ==> a[0] ,大小就是4
//*a == *(a+0) == a[0]
printf("%d\\n", sizeof(a + 1));
//a表示首元素的地址,a+1是第二个元素的地址,大小就是4/8
printf("%d\\n", sizeof(a[1]));
//a[1] 就是第二个元素 - 4
printf("%d\\n", sizeof(&a));
//&a - 数组的地址 - 4/8 - int(*)[4]
printf("%d\\n", sizeof(*&a));
//*&a - &a是数组的地址,对数组的地址解引用拿到的是数组,所以大小时候16
//相当于printf("%d\\n", sizeof(a));//16
printf("%d\\n", sizeof(&a + 1));
//4/8 &a是数组的地址,&a+1 是数组的地址+1,跳过整个数组,虽然跳过了数组,
//还是地址 4/8
printf("%d\\n", sizeof(&a[0]));
//4/8
printf("%d\\n", sizeof(&a[0] + 1));
//第二个元素的地址 4/8
return 0;
}
字符数组
char arr[] = { 'a','b','c','d','e','f' };
//arr中是没有放\\0的,而strlen()求长度是找到\\0才停止
printf("%d\\n", strlen(arr));
//从arr位置(首元素地址)向后求长度,随机值
printf("%d\\n", strlen(arr + 0));
//从arr位置(首元素地址)向后求长度,随机值
printf("%d\\n", strlen(*arr));
//arr是首元素地址,*arr是字符‘a’-ascii-97,strlen把字符a对应的ascii码值97作为地址向后计数,非法访问!err
printf("%d\\n", strlen(arr[1]));
//strlen把字符b对应的ascii码值98作为地址向后计数,非法访问!err
printf("%d\\n", strlen(&arr));//&arr和arr地址值相同,都是首元素地址,但是意义不一样
//&arr传给strlen
printf("%d\\n", strlen(&arr + 1));//跳过整个数组后,向后计数,随机值-6
//内存空间连续,同时找到\\0停止,但是strlen(arr)和strlen(&arr)得到的随机值比第二个多6个字符abcdef
printf("%d\\n", strlen(&arr[0] + 1));//从字符b位置向后计数,随机数-1int main()
{
char arr[] = { 'a','b','c','d','e','f' };
//&arr的类型:数组指针: char(*)[6]
printf("%d\\n", sizeof(arr));
//数组名单独放在sizeof内部,计算的是整个数组的大小,元素个数为6个(不含\\0),类型为char 所以大小为6
printf("%d\\n", sizeof(arr + 0));
//此处的arr代表的是首元素地址,arr+0仍是首元素地址char*,地址(指针)大小是4/8
printf("%d\\n", sizeof(*arr));
//此处的arr代表的是首元素地址,*arr即为数组首元素,即为字符‘a’ 大小为1
printf("%d\\n", sizeof(arr[1]));
//arr[1]->字符‘b’,大小为1
printf("%d\\n", sizeof(&arr));
//取出整个数组的地址,还是地址,地址的大小就是4/8
printf("%d\\n", sizeof(&arr + 1));
//取出数组arr的地址+1,跳过一个数组,还是地址,地址的大小为:4/8
printf("%d\\n", sizeof(&arr[0] + 1));//数组第二个元素的地址,4/8
return 0;
}
int main()
{
char arr[] = "abcdef";
//此时数组arr中存放了\\0 strlen求长度,遇到\\0即停止计数
printf("%d\\n", strlen(arr));
//从arr位置开始向后计数,遇到\\0即停,长度为6
printf("%d\\n", strlen(arr + 0));
///从arr位置开始向后计数,遇到\\0即停,长度为6
printf("%d\\n", strlen(*arr));//arr是首元素地址,*arr是字符‘a’
// 对应ascii值为97,strlen把字符a对应的ascii码值97作为地址向后计数,err
printf("%d\\n", strlen(arr[1]));///arr[1]:‘b’对应ascii值为98,
//strlen把字符b对应的ascii码值98作为地址向后计数,非法访问!err
printf("%d\\n", strlen(&arr));
//&arr和arr地址值相同,都是首元素地址,但是意义不一样
//&arr传给strlen &arr类型:数组指针 char(*p)[6] 而strlen接收的类型为char*,不兼容,但是问题不大
//从数组首元素位置向后计数,值为 6
printf("%d\\n", strlen(&arr + 1));
//跳过整个数组后,向后计数,未知值
printf("%d\\n", strlen(&arr[0] + 1));
//从b未知向后计数,长度为5
return 0;
}
int main()
{
char arr[] = "abcdef";
//此时的arr数组里面是放了\\0的
printf("%d\\n", sizeof(arr));
//数组名单独放在sizeof内部,计算的是整个数组的大小,\\0也算进去,大小为7
printf("%d\\n", sizeof(arr + 0));
//此时的数组名是首元素地址,地址(指针)大小:4/8
printf("%d\\n", sizeof(*arr));
//此时的数组名是首元素地址,*arr即为首元素,字符a->char类型,大小为1
printf("%d\\n", sizeof(arr[1]));
//arr[1]:字符'b',大小为1
printf("%d\\n", sizeof(&arr));
//取出数组的地址,还是地址,大小为4/8
printf("%d\\n", sizeof(&arr + 1));
//取出数组的地址+1,跳过整个数组,还是地址:4/8
printf("%d\\n", sizeof(&arr[0] + 1));
//取出第一个元素的地址+1,跳过一个元素,即为第二个元素的地址,4/8
return 0;
}
#include<stdio.h>
int main()
{
//&p[0]==>相当于&*(p+0)-->相当于sizeof(p),p存中存放的是字符a的地址,+1,即为字符b的地址,从字符b位置向后访问, 长度为5
// p[0] :字符a
//&p[0]:字符a的地址
//&p[0] +1:字符b的地址
const char* p = "abcdef";
//p存放的是字符a的地址,
//p+1:字符b的地址
printf("%d\\n", strlen(p));
//p存放的是字符a的地址,即从字符a的地址向后计数,长度为6
printf("%d\\n", strlen(p + 1));
//从字符b的地址向后计数,长度为5
//printf("%d\\n", strlen(*p));
//*p ->字符‘a’ 即以字符a的ascii码值97为地址向后计数,非法访问,err
//printf("%d\\n", strlen(p[0]));
//p[0] ->字符‘a’ 即以字符a的ascii码值97为地址向后计数,非法访问,err
printf("%d\\n", strlen(&p));
//&p取出的是p变量的地址,即以p变量的地址(16进制)向后计数, 随机值
printf("%d\\n", strlen(&p + 1));//&p取出的是p变量的地址,&p+1,跳过p变量,即从p变量之后的位置向后访问 随机值
printf("%d\\n", strlen(&p[0] + 1));
//&p[0]==>相当于&*(p+0)-->相当于sizeof(p),p存中存放的是字符a的地址,+1,即为字符b的地址,从字符b位置向后访问, 长度为5
return 0;
}int main()
{
//因为指针指向的是常量字符串,不可以被修改
//所以可以用const修饰
//char* p = "abcdef";
const char* p = "abcdef";
//p存放的是字符a的地址
printf("%d\\n", sizeof(p));
//p是指针,指向字符a,大小为4/8
printf("%d\\n", sizeof(p + 1));
//p+1,指向的是字符b,指针,大小为4/8
printf("%d\\n", sizeof(*p));
//p存放的是字符a的地址,*p:即为字符a,大小为1
printf("%d\\n", sizeof(p[0]));
//p[0]->字符a ,大小为1
printf("%d\\n", sizeof(&p));
//取出p变量的地址,仍是地址,大小为4/8
printf("%d\\n", sizeof(&p + 1));
//取出p变量的地址+1,跳过p变量,但仍是地址,大小为4/8
printf("%d\\n", sizeof(&p[0] + 1));
//&p[0]相当于&*(p+0),&和*抵消,&p[0]:字符a的地址,+1:字符b的地址,大小为4/8
return 0;
}

int main()
{
int a[3][4] = { 0 };
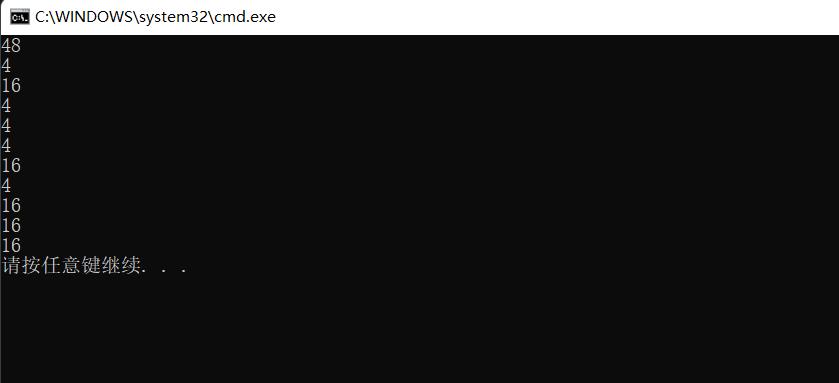
printf("%d\\n", sizeof(a));
//数组名单独放在sizeof内部,计算的是整个数组的大小,
//数组元素为12个,每一个元素大小为4个字节,12*4=48
printf("%d\\n", sizeof(a[0][0]));
//计算的是数组第有一行第一个元素的大小,int类型,大小为4
printf("%d\\n", sizeof(a[0]));
//a[0]==>*(a+0)==>数组名是首元素地址,即为第一行的地址,解引用第一行的地址,
// 就是第一行,所以计算的是第一行元素的大小 4*4=16
//a[0] : 二维数组的第一行
printf("%d\\n", sizeof(a[0] + 1));
//a[0]:第一行的数组名,代表第一行第一个元素的地址,a[0]+1::跳过一个元素,
// 即为第一行第二个元素地址,大小为4/8
//注意:a[0] + 1 :不是第二行,a[0]是第一行的数组名,首元素地址,
//即为第一行第一个元素地址,a[0]+1:跳过一个元素 a+1:a为数组名,首元素地址,第一行的地址,a+1,跳过一行,二维数组第二行
printf("%d\\n", sizeof(*(a[0] + 1)));
//由上可得:a[0]+1:第一行第二个元素地址, *(a[0]+1):即为第一行第二个元素 int类型 大小为4
printf("%d\\n", sizeof(a + 1));
//a为二维数组的数组名->首元素地址,e二维数组第一行的地址,+1,跳过一行,即为第二行的地址->地址,大小为4/8
printf("%d\\n", sizeof(*(a + 1)));
//由上,a+1是第二行的地址,*(a+1)即为第二行,大小为4*4 = 16
printf("%d\\n", sizeof(&a[0] + 1));
//a[0]是第一行的数组名,&a[0]就是第一行的地址,
//(相当于是,数组名和取地址数组名的关系,二二者地址值相同,但是含义不同),&a[0]+1:跳过第一行,即为第二行地址,地址:4/8
printf("%d\\n", sizeof(*(&a[0] + 1)));
//由上:(&a[0]+1):第二行地址,解引用就是第二行,大小为4*4 = 16
printf("%d\\n", sizeof(*a));
//二维数组数组名是首元素地址,即为第一行的地址,解引用就是第一行, 大小为4* 4 = 16
printf("%d\\n", sizeof(a[3]));
//a[3]假设存在,就是第四行的数组名,sizeof(a[3])相当于数组名单独放在sizeof内部,计算的是第四行的大小, 4*4 = 16
//sizeof内部的表达式不参与运算,即不会真的去访问a[3]的空间,所以不出错,它只看一下第四行的类型,并没有真正去访问第四行的内容,
return 0;
}
下面程序的结果是:( )
int main()
{
int aa[2][5] = {10,9,8,7,6,5,4,3,2,1};
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}&aa的类型是int (*)[2][5],加一操作会导致跳转一个int [2][5]的长度,直接跑到刚好越界的位置。减一以后回到最后一个位置1处。*(aa + 1)相当于aa[1],也就是第二行的首地址,自然是5的位置。减一以后由于多维数组空间的连续性,会回到上一行末尾的6处
下面程序的结果是:( )
int main() { int a[5] = {5, 4, 3, 2, 1}; int *ptr = (int *)(&a + 1); printf( "%d,%d", *(a + 1), *(ptr - 1)); return 0; }*(a + 1)等同于a[1],第一个是4,a的类型是int [5],&a的类型就是int(*)[5],是个数组指针。所以给int(*)[5]类型加一,相当于加了一个int [5]的长度。也就是这个指针直接跳过了a全部的元素,直接指在了刚好越界的位置上,然后转换成了int *后再减一,相当于从那个位置向前走了一个int,从刚好越觉得位置回到了1的地址处,所以第二个是1
四,字符函数和字符串函数
本节我之前的博客有详解,感兴趣的可以去考古
1,strlen
size_t strlen ( const char * str );
字符串已经 '\\0' 作为结束标志,strlen函数返回的是在字符串中 '\\0' 前面出现的字符个数(不包含 '\\0' )。
参数指向的字符串必须要以 '\\0' 结束。
注意函数的返回值为size_t,是无符号的( 易错 )
2,strcpy
char* strcpy(char * destination, const char * source );源字符串必须以 '\\0' 结束。
会将源字符串中的 '\\0' 拷贝到目标空间。
目标空间必须足够大,以确保能存放源字符串。
目标空间必须可变。
3,strcat
char * strcat ( char * destination, const char * source );源字符串必须以 '\\0' 结束。
目标空间必须有足够的大,能容纳下源字符串的内容。
目标空间必须可修改。
4,strcmp
char * strcmp ( const char * str1, const char * str2)第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
5,strstr
char * strstr ( const char *, const char * );
6,memcpy
void * memcpy ( void * destination, const void * source, size_t num );函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
这个函数在遇到 '\\0' 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的。
7,memmove
void * memmove ( void * destination, const void * source, size_t num );和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
如果源空间和目标空间出现重叠,就得使用memmove处理。
8,模拟实现上述内存函数与字符串函数
memmove实现重叠拷贝和不重叠拷贝
void* my_memmove(void* dest, const void* src, size_t count)//无符号整型
{
//前到后
assert(dest && src);
void* ret = dest;
if (dest < src)
{
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
//后到前
else
{
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
}
return ret;
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
my_memmove(arr + 2, arr, 16);
//my_memmove(arr, arr + 2, 16);
return 0;
}my_memcpy(void* dest, const void* src, size_t count)
{
void* set = dest;
assert(dest && src);
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return set;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7 };
int arr2[20] = { 0 };
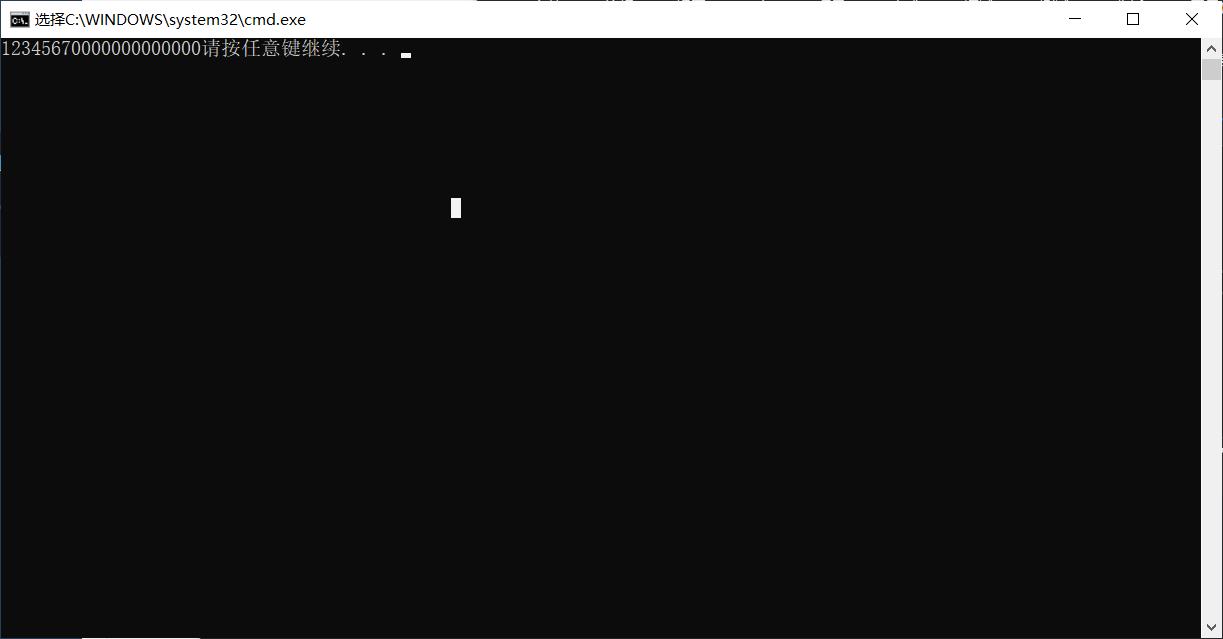
my_memcpy(arr2, arr1, 40);//拷贝的是整型数据
int i = 0;
for (i = 0; i < 20; i++)
{
printf("%d", arr2[i]);
}
return 0;
}
char* my_strstr(const char*str1, const char* str2)
{
assert(str1 && str2);
char* s1;
char* s2;
char* cp = str1;
if (*str2 == '\\0')
return str1;
while (*cp)
{
s1 = cp;
s2 = str2;
//while (*s1!='\\0' && *s2 != '\\0' && *s1 == *s2)
while (*s1 && *s2 && *s1 == *s2)
{
s1++;
s2++;
}
if (*s2 == '\\0')
{
return cp;
}
cp++;
}
//找不到
return NULL;
}
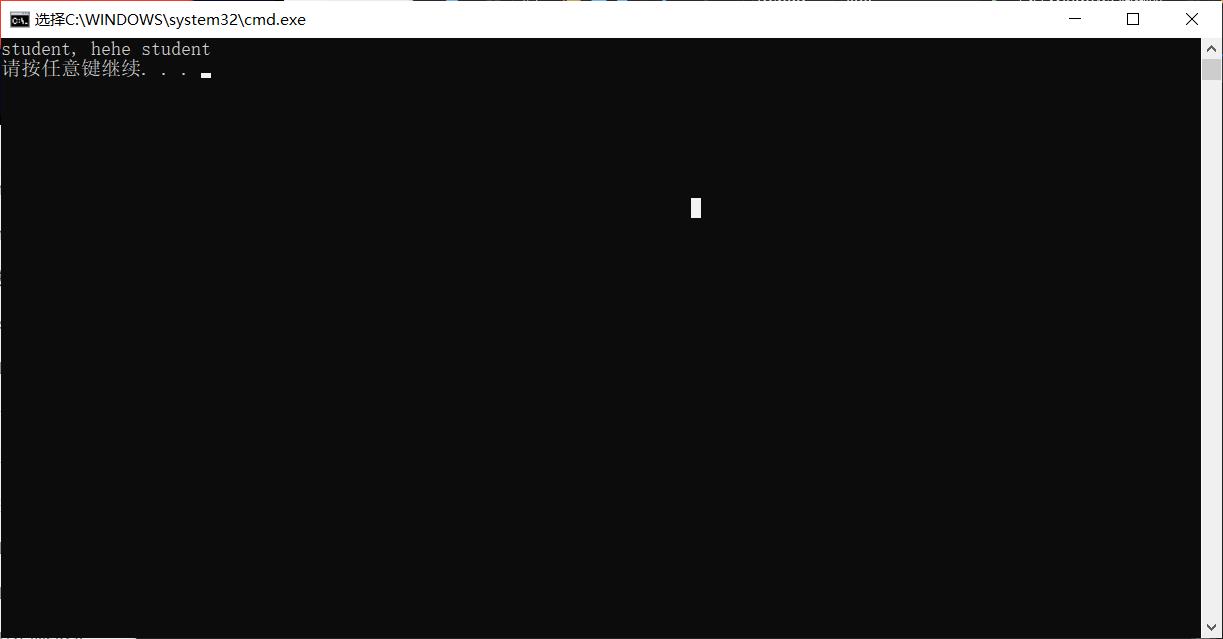
int main()
{
char arr1[] = "i am good student, hehe student";
char arr2[] = "student";
//查找arr1中arr2第一次出现的位置
char *ret = my_strstr(arr1, arr2);
if (ret == NULL)
{
printf("找不到\\n");
}
else
{
printf("%s\\n", ret);
}
return 0;
}
#include<string.h>
#include<stdio.h>
#include<assert.h>
my_strcat(char* dest, const char* src)
{
assert(dest && src);
// a b c \\0
// d e f \\0
//1,找到目标字符串的末尾\\0
//2,追加字符串直到\\0
//返回类型是char*,stract返回目标空间的起始地址
char* ret = dest;
while (*dest)
{
dest++;
}
//与strcpy追加相等
while (*dest++ = *src++)
{
;
}
return ret;
//返回类型是char*,stract返回目标空间的起始地址
}
int main()
{
//strcpy字符串拷贝\\0是停止的标志
//stract字符串连接
char arr1[20] = "abc";//保证数据可以放进去
char arr2[20] = { 'd','e','f' };//无\\0程序将会出现问题
char arr3[20] = { 'd','e','f' ,'\\0' };//正确书写
my_strcat(arr1, arr3);
printf("%s\\n", arr1);
return 0;
}
int my_strcmp(const char* s1,const char* s2)
{
assert(s1 && s2);
// a b c d e \\0
// a d n \\0
//c与n不相等,比较assic值
// a b c \\0
// a b c \\0
//相等
while (*s1 == *s2)
{
if (*s1 == '\\0')
{
return 0;
}
s1++;
s2++;
}
return *s1 - *s2;//第一个字符串小于第二字符串,返回负数
}
int main()
{
char arr1[] = "asihvw";
char arr2[] = "asns";
//字符串一一比较
//返回值有三种可能性
//发现相等\\0,停下来,结果为0;
//不同比较的是字符串对应的assic码值
int ret = my_strcmp(arr1, arr2);
if (ret == 0)
{
printf("=\\n");
}
else if (ret < 0)
{
printf("<\\n");
}
else
{
printf(">\\n");
}
printf("%d\\n", ret);
return 0;
}
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);
char* ret = dest;
while (*dest++ = *src++)
{
;
}
return ret;
}
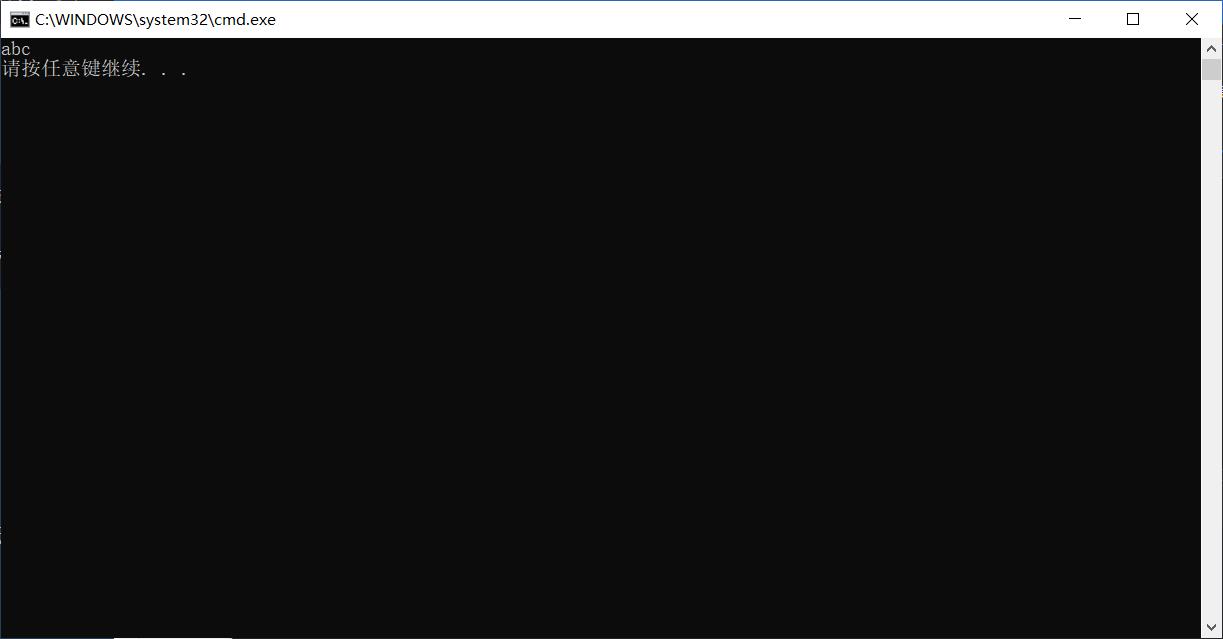
int main()
{
char arr1[] = "xxxxxxxx";
char arr2[] = "abc";
printf("%s\\n", my_strcpy(arr1, arr2));
return 0;
}
int my_strlen(const char* str)
{
int count = 0;
while (*str !='\\0')
{
count++;
str++;
}
return count;
}
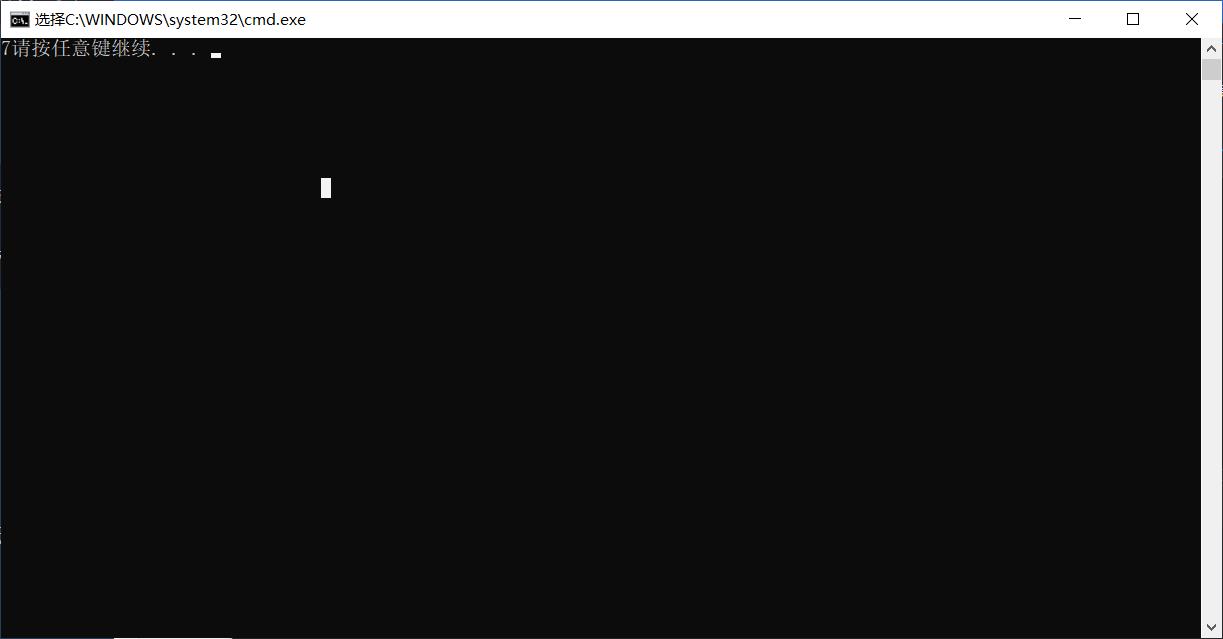
int main()
{
char arr1[] = "sfsgssg";
int ret = my_strlen(arr1);
printf("%d",ret);
return 0;
}
五,自定义类型:结构体,枚举,联合
1,结构体
结构的声明
struct tag
{
member-list;
}variable-list;结构的自引用
struct Node
{
int data;
struct Node* next;
};
结构体变量的定义和初始化
int x, y;
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋初值。
struct Point p3 = { x, y };
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = { "zhangsan", 20 };//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化
struct Node n2 = { 20, {5, 6}, NULL };//结构体嵌套初始h,结构体内存对齐
本节在我前面的博客有详解,建议欢迎各位考古,不了解结构体对齐对下面的题上手困难
结构体的对齐规则
1,结构体的第一个成员永远放在结构体起始位置偏移为0的地址
2,结构体从第二个成员,总是放在一个对齐数的整数倍数
对齐数 = 编译器默认的对齐数和变量自身大小的较小值3,. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4,如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
为什么存在内存对齐
1. 平台原因(移植原因): 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能 在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因: 数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于&#
以上是关于✨三万字制作,关于C语言,你必须知道的这些知识点(高阶篇)✨的主要内容,如果未能解决你的问题,请参考以下文章