爬虫 + 自动化利器 selenium 之自学成才篇
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫 + 自动化利器 selenium 之自学成才篇相关的知识,希望对你有一定的参考价值。
❤ 系列内容 ❤
爬虫+自动化利器 selenium 之自学成才篇(一)
主要内容:selenium 简介、selenium 安装、安装浏览器驱动、8 种方式定位页面元素、浏览器控制、鼠标控制、键盘控制
爬虫+自动化利器 selenium 之自学成才篇(二)
主要内容:三种等待方式(显式等待、隐式等待、强制等待)、一组元素的定位方式、切换操作(窗口切换、表单切换)、弹窗处理等。
爬虫+自动化利器 selenium 之自学成才篇(三)(待更新)
主要内容:文件上传 & 下载、cookie 操作、调用 javascript(滑动滚动条)、关闭操作、页面截图等。

设置元素等待
很多页面都使用 ajax 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。webdriver 中的等待分为 显式等待 和 隐式等待。
显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(TimeoutException)。显示等待需要使用 WebDriverWait,同时配合 until 或 not until 。下面详细讲解一下。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
driver:浏览器驱动timeout:超时时间,单位秒poll_frequency:每次检测的间隔时间,默认为0.5秒ignored_exceptions:指定忽略的异常,如果在调用until或until_not的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有NoSuchElementException。
until(method, message=’ ‘)
until_not(method, message=’ ')
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。until_not正好相反,当元素消失或指定条件不成立,则继续执行后续代码message: 如果超时,抛出TimeoutException,并显示message中的内容
method 中的预期条件判断方法是由 expected_conditions 提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, 'kw')
element = driver.find_element_by_id('kw')
| 方法 | 描述 |
|---|---|
| title_is(‘百度一下’) | 判断当前页面的 title 是否等于预期 |
| title_contains(‘百度’) | 判断当前页面的 title 是否包含预期字符串 |
| presence_of_element_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility_of_element_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text_to_be_present_in_element(locator , ‘百度’) | 判断元素中的 text 是否包含了预期的字符串 |
| text_to_be_present_in_element_value(locator , ‘某值’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame_to_be_available_and_switch_to_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility_of_element_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element_to_be_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness_of(element) | 等待元素从 dom 树中移除 |
| element_to_be_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element_selection_state_to_be(element, True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element_located_selection_state_to_be(locator, True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert_is_present() | 判断页面上是否存在 alert |
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, 'kw')),
message='超时啦!')

隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 NoSuchElementException 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 implicitly_wait() 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 id 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id('kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')

代码运行到 driver.find_element_by_id('kw') 这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
强制等待
使用 time.sleep() 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/qq_43965708')
start = time()
sleep(5)
try:
driver.find_element_by_id('kw')
except Exception as e:
print(e)
print(f'耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将 element 改为 elements 即可,它的使用场景一般是为了批量操作元素。
find_elements_by_id()find_elements_by_name()find_elements_by_class_name()find_elements_by_tag_name()find_elements_by_xpath()find_elements_by_css_selector()find_elements_by_link_text()find_elements_by_partial_link_text()
这里以 CSDN 首页的一个 博客专家栏 为例。
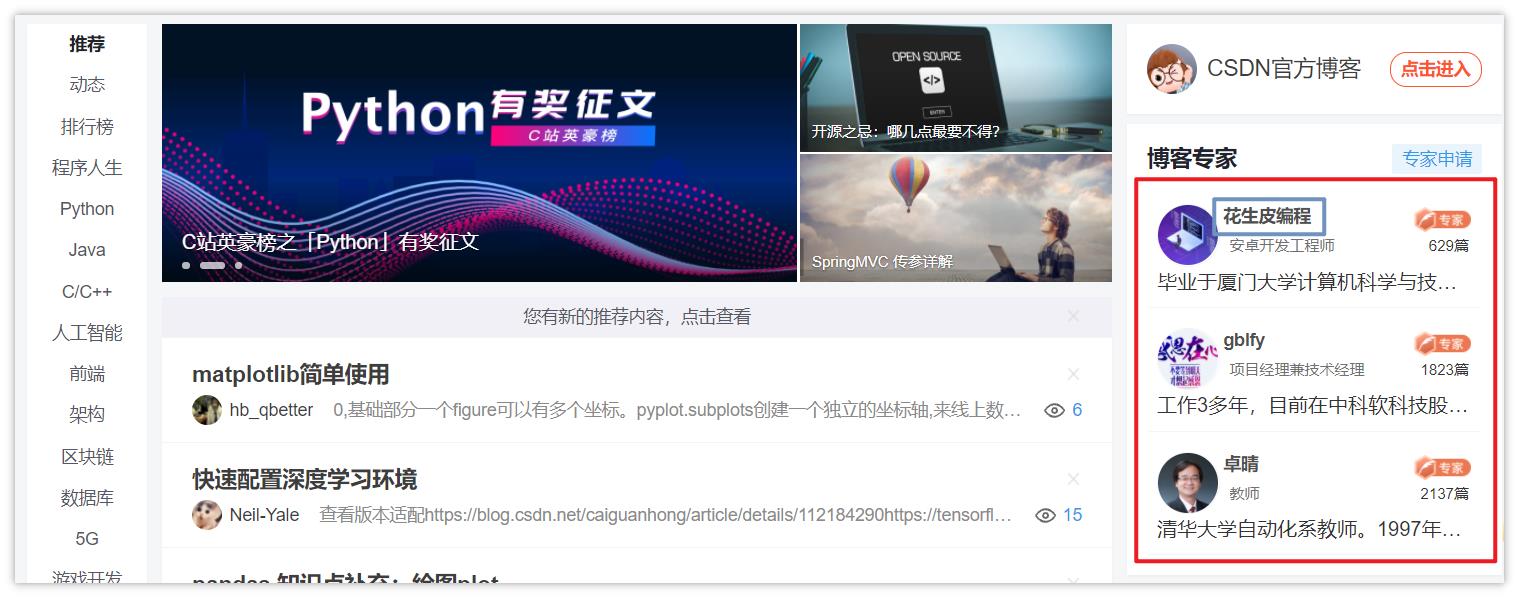
下面使用 find_elements_by_xpath 来定位三位专家的名称。

这是专家名称部分的页面代码,不知各位有没有想到如何通过 xpath 定位这一组专家的名称呢?
from selenium import webdriver
# 设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
driver.get('https://blog.csdn.net/')
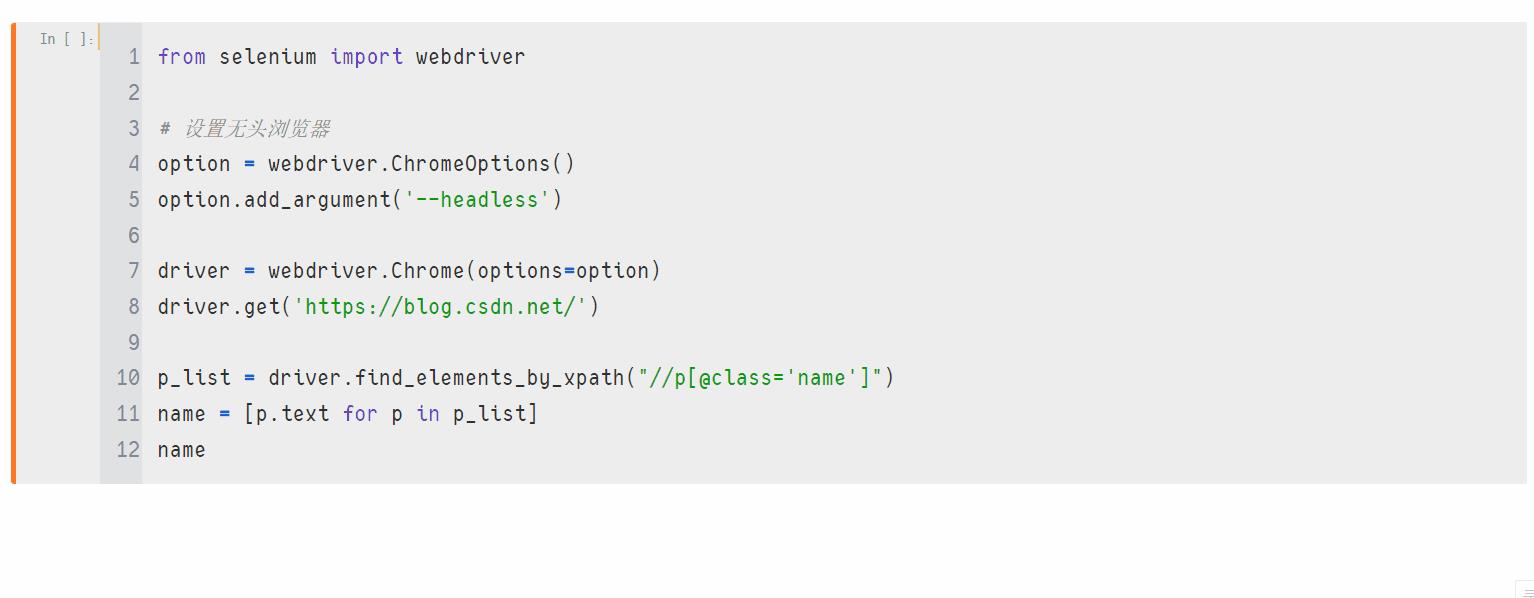
p_list = driver.find_elements_by_xpath("//p[@class='name']")
name = [p.text for p in p_list]
name
切换操作
窗口切换
在 selenium 操作页面的时候,可能会因为点击某个链接而跳转到一个新的页面(打开了一个新标签页),这时候 selenium 实际还是处于上一个页面的,需要我们进行切换才能够定位最新页面上的元素。
窗口切换需要使用 switch_to.windows() 方法。
首先我们先看看下面的代码。
代码流程:先进入 【CSDN首页】,保存当前页面的句柄,然后再点击左侧 【CSDN官方博客】跳转进入新的标签页,再次保存页面的句柄,我们验证一下 selenium 会不会自动定位到新打开的窗口。
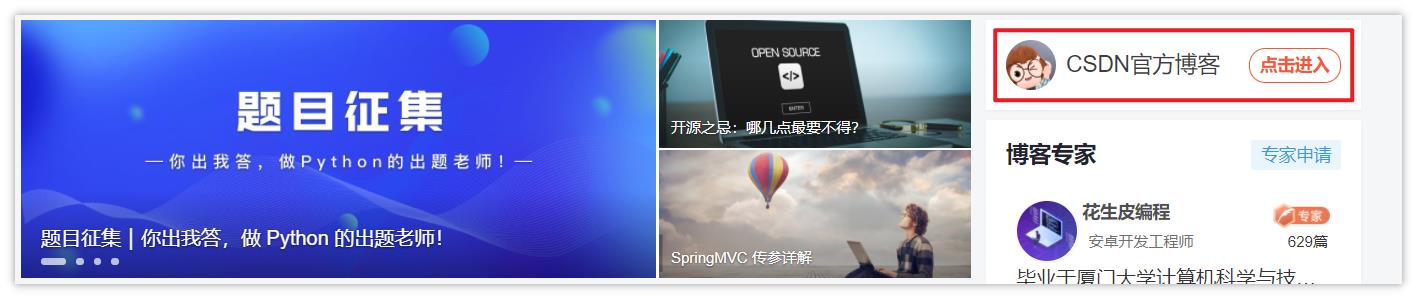
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
# 获取当前所有窗口的句柄
print(driver.window_handles)

可以看到第一个列表 handle 是相同的,说明 selenium 实际操作的还是 CSDN首页 ,并未切换到新页面。
下面使用 switch_to.windows() 进行切换。
from selenium import webdriver
handles = []
driver = webdriver.Chrome()
driver.get('https://blog.csdn.net/')
# 设置隐式等待
driver.implicitly_wait(3)
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
# 点击 python,进入分类页面
driver.find_element_by_xpath('//*[@id="mainContent"]/aside/div[1]/div').click()
# 切换窗口
driver.switch_to.window(driver.window_handles[-1])
# 获取当前窗口的句柄
handles.append(driver.current_window_handle)
print(handles)
print(driver.window_handles)

上面代码在点击跳转后,使用 switch_to 切换窗口,window_handles 返回的 handle 列表是按照页面出现时间进行排序的,最新打开的页面肯定是最后一个,这样用 driver.window_handles[-1] + switch_to 即可跳转到最新打开的页面了。
那如果打开的窗口有多个,如何跳转到之前打开的窗口,如果确实有这个需求,那么打开窗口是就需要记录每一个窗口的 key(别名) 与 value(handle),保存到字典中,后续根据 key 来取 handle 。
表单切换
很多页面也会用带 frame/iframe 表单嵌套,对于这种内嵌的页面 selenium 是无法直接定位的,需要使用 switch_to.frame() 方法将当前操作的对象切换成 frame/iframe 内嵌的页面。
switch_to.frame() 默认可以用的 id 或 name 属性直接定位,但如果 iframe 没有 id 或 name ,这时就需要使用 xpath 进行定位。下面先写一个包含 iframe 的页面做测试用。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div p {
color: #red;
animation: change 2s infinite;
}
@keyframes change {
from {
color: red;
}
to {
color: blue;
}
}
</style>
</head>
<body>
<div>
<p>公众号:Python新视野</p>
<p>CSDN:Dream丶Killer</p>
<p>微信:python-sun</p>
</div>
<iframe src="https://blog.csdn.net/qq_43965708" width="400" height="200"></iframe>
<!-- <iframe id="CSDN_info" name="Dream丶Killer" src="https://blog.csdn.net/qq_43965708" width="400" height="200"></iframe> -->
</body>
</html>
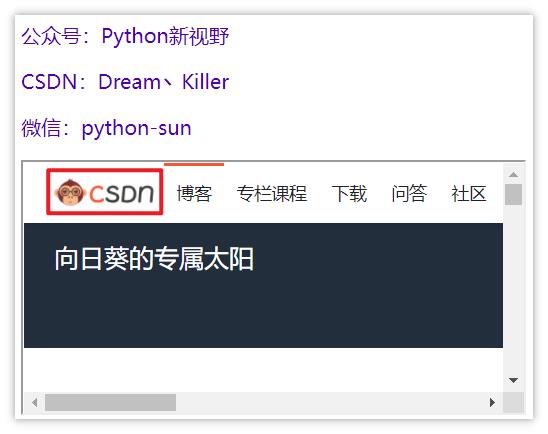
现在我们定位红框中的 CSDN 按钮,可以跳转到 CSDN 首页。
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
# 读取本地html文件
driver.get('file:///' + str(Path(Path.cwd(), 'iframe测试.html')))
# 1.通过id定位
driver.switch_to.frame('CSDN_info')
# 2.通过name定位
# driver.switch_to.frame('Dream丶Killer')
# 通过xpath定位
# 3.iframe_label = driver.find_element_by_xpath('/html/body/iframe')
# driver.switch_to.frame(iframe_label)
driver.find_element_by_xpath('//*[@id="csdn-toolbar"]/div/div/div[1]/div/a/img').click()
这里列举了三种定位方式,都可以定位 iframe 。

弹窗处理
JavaScript 有三种弹窗 alert(确认)、confirm(确认、取消)、prompt(文本框、确认、取消)。
处理方式:先定位(switch_to.alert自动获取当前弹窗),再使用 text、accept、dismiss、send_keys 等方法进行操作
| 方法 | 描述 |
|---|---|
text | 获取弹窗中的文字 |
accept | 接受(确认)弹窗内容 |
dismiss | 解除(取消)弹窗 |
send_keys | 发送文本至警告框 |
这里写一个简单的测试页面,其中包含三个按钮,分别对应三个弹窗。
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<button id="alert">alert</button>
<button id="confirm">confirm</button>
<button id="prompt">prompt</button>
<script type="text/javascript">
const dom1 = document.getElementById("alert")
dom1.addEventListener('click', function(){
alert("alert hello")
})
const dom2 = document.getElementById("confirm")
dom2.addEventListener('click', function(){
confirm("confirm hello")
})
const dom3 = document.getElementById("prompt")
dom3.addEventListener('click', function(){
prompt("prompt hello")
})
</script>
</body>
</html>

下面使用上面的方法进行测试。为了防止弹窗操作过快,每次操作弹窗,都使用 sleep 强制等待一段时间。
from selenium import webdriver
from pathlib import Path
from time import sleep
driver = webdriver.Firefox()
driver.get('file:///' + str(Path(Path.cwd(), '弹窗.html')))
sleep(2)
# 点击alert按钮
driver.find_element_by_xpath('//*[@id="alert"]').click()
sleep(1)
alert = driver.switch_to.alert
# 打印alert弹窗的文本
print(alert.text)
# 确认
alert.accept()
sleep(2)
# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="confirm"]').click()
sleep(1)
confirm = driver.switch_to.alert
print(confirm.text)
# 取消
confirm.dismiss()
sleep(2)
# 点击confirm按钮
driver.find_element_by_xpath('//*[@id="prompt"]').click()
sleep(1)
prompt = driver.switch_to.alert
print(prompt.text)
# 向prompt的输入框中传入文本
prompt.send_keys("Dream丶Killer")
sleep(2)
prompt.accept()
'''输出
alert hello
confirm hello
prompt hello
'''

注:细心地读者应该会发现这次操作的浏览器是
Firefox,为什么不用Chrome呢?原因是测试时发现执行prompt的send_keys时,不能将文本填入输入框。尝试了各种方法并查看源码后确认不是代码的问题,之后通过其他渠道得知原因可能是Chrome的版本与selenium版本的问题,但也没有很方便的解决方案,因此没有继续深究,改用Firefox可成功运行。这里记录一下我的Chrome版本,如果有大佬懂得如何在Chrome上解决这个问题,请在评论区指导一下,提前感谢!
selenium:3.141.0
Chrome:94.0.4606.71

未完待续~
⭐️往期精彩,不容错过⭐️
总结篇
❤️两万字,50个pandas高频操作【图文并茂,值得收藏】❤️
❤️吐血总结《Mysql从入门到入魔》,图文并茂(建议收藏)❤️
工具篇
⭐️Python实用小工具之制作酷炫二维码(有界面、附源码)⭐️
❤️Python实用工具之制作证件照(有界面、附源码)❤️
❤️女朋友桌面文件杂乱无章?气得我用Python给她做了一个文件整理工具❤️
更多有趣的文章及干货,尽在
以上是关于爬虫 + 自动化利器 selenium 之自学成才篇的主要内容,如果未能解决你的问题,请参考以下文章