Python爬虫实战❤️ 从零开始分析页面,抓取数据——爬取豆瓣电影任意页数 看不懂你来找我!❤️
Posted 是Dream呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战❤️ 从零开始分析页面,抓取数据——爬取豆瓣电影任意页数 看不懂你来找我!❤️相关的知识,希望对你有一定的参考价值。

📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一个有趣的Python博主,小白一枚,多多关照😜😜😜
🏅🏅🏅CSDN Python领域新星创作者,大二在读,欢迎大家找我合作学习
💕入门须知:这片乐园从不缺乏天才,努力才是你的最终入场券!🚀🚀🚀
💓最后,愿我们都能在看不到的地方闪闪发光,一起加油进步🍺🍺🍺
🍉🍉🍉“一万次悲伤,依然会有Dream,我一直在最温暖的地方等你”,唱的就是我!哈哈哈~🌈🌈🌈
🌟🌟🌟✨✨✨
前言:
接下来带着大家用Python爬虫实现豆瓣电影的爬取,从零开始,跟上节奏,看不懂你来找我~
Python爬虫实战❤️爬取豆瓣电影任意页数:
一、urllib_ajax的get方法 单页抓取
1.页面分析
要爬取豆瓣电影,我们第一步当然是先百度:豆瓣电影,进入官网,昂昂Duang~
我们打开相应的豆瓣电影页面:豆瓣电影动作片排行榜

然后单击鼠标右键,在界面下方找到检查,单击进去:

然后在其中找到network,点击并顺势进行网页刷新获取新的数据:

进行分析其中的数据:首先排除js和png、jpg文件,在此基础上,我们发现了这个文件:

点开发现,确实是我们所需要的数据:
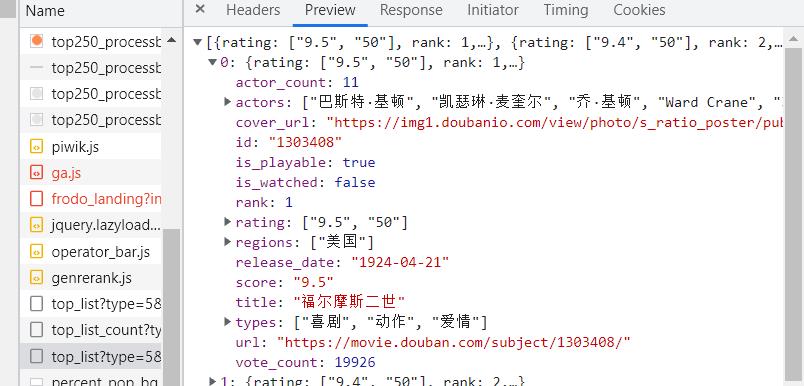
进而我们在headers中找到它的url:

2.抓取步骤
(1) url和headers选取
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
(2)请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
(3)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
(4)数据下载到本地
open方法默认情况下使用的是gbk的编码,如果我们想要保存汉字,那么使用
open方法中制定编码格式为utf-8 ,encoding=utf-8
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
完全等价:
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
3.具体代码
# -*-coding:utf-8 -*-
# @Author:到点了,心疼徐哥哥
# 奥利给干!!!
# get请求,获取第一页数据,并保存起来
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
# (1)请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# (3)数据下载到本地
# open方法默认情况下使用的是gbk的编码,如果我们想要保存汉字,那么使用
# open方法中制定编码格式为utf-8
# encoding=utf-8
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# 完全等价
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
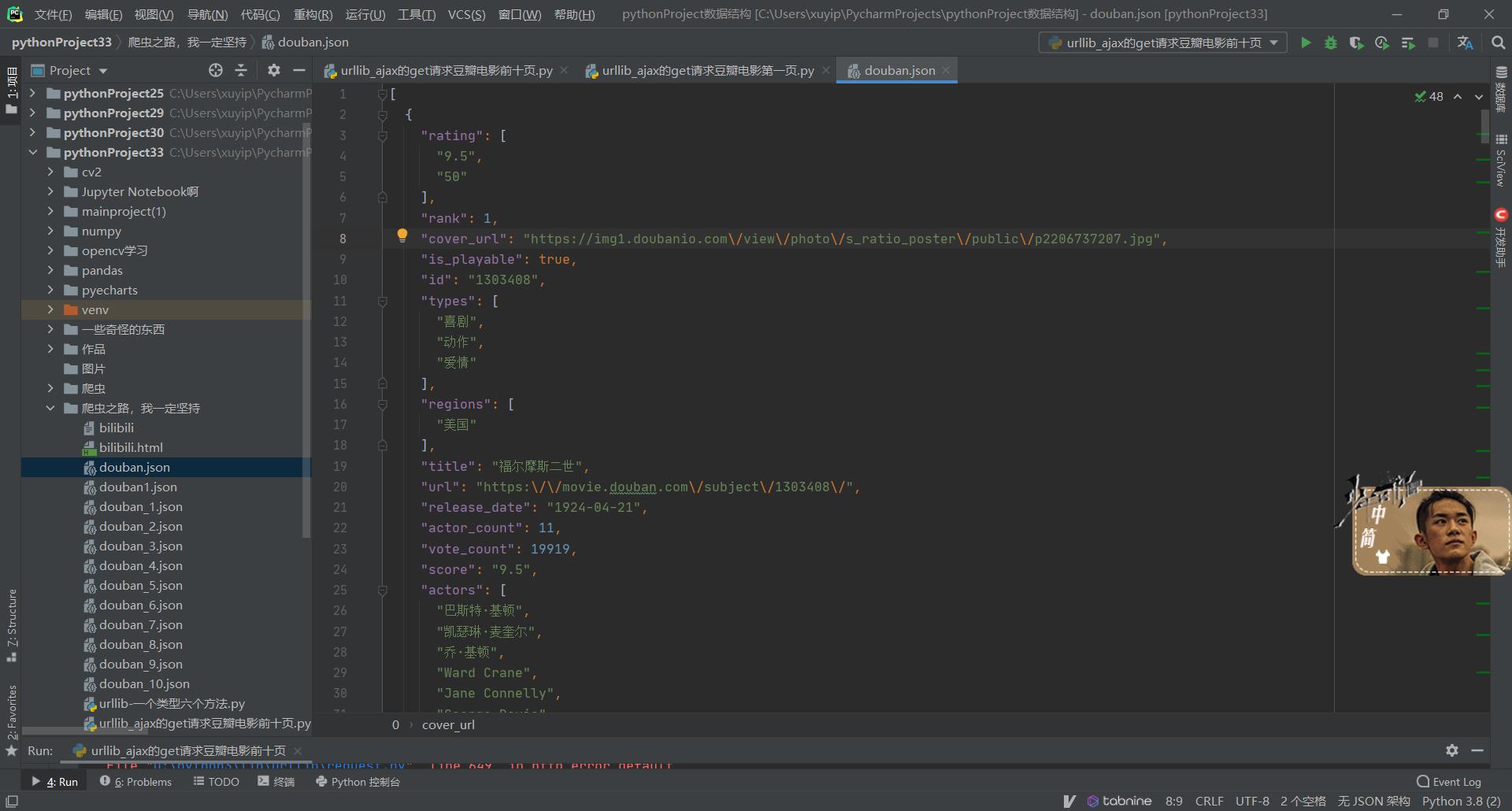
4.结果展示
保存为json数据,你会发现此时你的数据是一行的,显得十分难看,只需要按住 ctrl + alt +l 就可以将数据变为规范的一行行数据。不过此键会和电脑QQ锁定键重合,所以说一般进行此操作先把QQ退掉,或者有能力的同学可以更改键位选择,将其换位其他键位的组合。
二、urllib_ajax的get方法 爬取任意页数爬取
1.页面分析
在此页面中,用鼠标逐渐向下滑动,你会发现会新增加一些近乎一样的页面数据,其实每次页面显示二十部电影,当你继续往下滑动时,又会出现二十部电影,我们分别将其对应的url取下来单独进行分析:
 第一页:
第一页:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
第二页:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
第三页:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
可以发现:每次的start都不同
设page为n,则:start=(n-1)*20
2.抓取步骤
(1)请求对象的定制
resquest = urllib.request.Request(url=url,headers=headers)
(2)url拼接
应用urllib.parse进行拼接:
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
(3)设置入口
if __name__=='__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页面'))
for page in range(start_page,end_page+1):
- 获取请求
- 响应请求
- 保存数据
request = create_request(page)
# 获取响应的数据
content = get_content(request)
down_load(page,content)
(4) create_request(page)函数
def create_request(page):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
resquest = urllib.request.Request(url=url,headers=headers)
return resquest
(5) get_content(request)函数
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
(6) down_load(page,content)函数
def down_load(page,content):
# with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
# fp.write(content)
fp = open('douban_'+str(page)+'.json','w',encoding='utf-8')
fp.write(content)
3.具体代码
# -*-coding:utf-8 -*-
# @Author:到点了,心疼徐哥哥
# 奥利给干!!!
import urllib.request
import urllib.parse
def create_request(page):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
resquest = urllib.request.Request(url=url,headers=headers)
return resquest
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
# with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
# fp.write(content)
fp = open('douban_'+str(page)+'.json','w',encoding='utf-8')
fp.write(content)
if __name__=='__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页面'))
for page in range(start_page,end_page+1):
request = create_request(page)
# 获取响应的数据
content = get_content(request)
down_load(page,content)
4.结果展示

将其转化为更规范的形式:ctrl+alt+l
三、最后充电⚡⚡⚡
当经过一系列操作之后,你已经爬取到了豆瓣电影的数据,当你满心欢喜的回去重新进一次豆瓣电影官网时,却突然发现进不去了,需要你先登录!
豆瓣:你礼貌吗,休想白嫖!
哈哈哈,你已经被豆瓣拉入黑名单了哟~人家的防范意识还是很高的!

毕竟一朝被爬取,次次防爬虫!
好哒,那我们拜了个拜,下期再见!
往期文章推荐:
还看不懂Python OpenCV?不,我不允许!隔壁大爷都说看得懂!❤️环境配置+问题分析+视频图像入门❤️万字只为你~
Python OpenCV实战画图——这次一定能行!爆肝万字,建议点赞收藏~❤️❤️❤️
❤️大家中秋节快乐❤️接下来请欣赏Python Opencv实战之图像阈值和模糊处理,万字实战,收藏起来吧~
Python爬虫❤️ Urllib用法合集——⚡一键轻松入门爬虫⚡
🌲🌲🌲 好啦,这就是今天要分享给大家的全部内容了
❤️❤️❤️如果你喜欢的话,就不要吝惜你的一键三连了~


以上是关于Python爬虫实战❤️ 从零开始分析页面,抓取数据——爬取豆瓣电影任意页数 看不懂你来找我!❤️的主要内容,如果未能解决你的问题,请参考以下文章