架构之美-软件实现分析之道
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构之美-软件实现分析之道相关的知识,希望对你有一定的参考价值。
在一个系统中,模型和接口是相对稳定的部分。
但同样的模型和接口,若采用不同实现,稳定性、可扩展性和性能等诸多方面相差极大。只有熟悉实现,才有改代码写新需求的基础。
“看实现”的确是个大难题,因有无数细节怪在等你。所以,团队的新人都需要几个月试用期去熟悉代码细节。
你不可能记住项目所有细节,但这不妨碍你工作。但若你心中没有一份关于项目实现的地图,你就一定会迷失。
新人一般用几个月熟悉代码,就是在通过代码一点点展开地图,但是,这不仅极其浪费时间,也很难形成整体认知。
推荐你应该直接把地图展开。怎么展开?
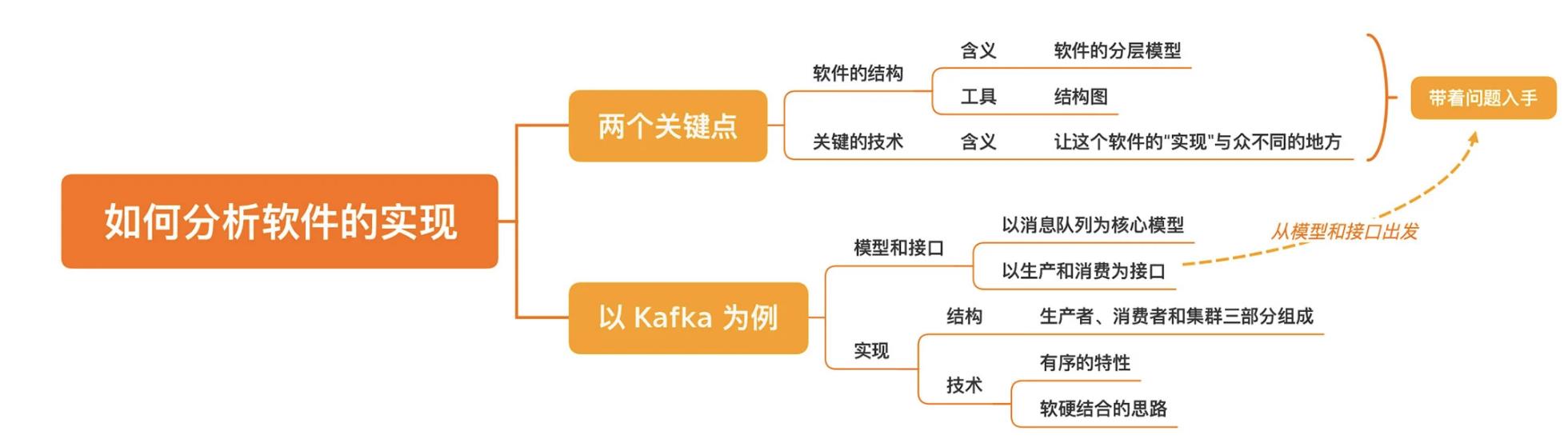
要找到两个关键点:软件的结构和关键的技术。
以Kafka为例,了解一个软件设计三步走:“模型、接口、实现”。
先看Kafka的模型和接口。
MQ的模型与接口
Kafka自我介绍是个分布式流平台,这是它现在的发展方向,但更多人觉得它是个MQ。
MQ是Kafka这个软件的核心模型,而流平台显然是这个核心模型存在之后的扩展。所以,要先把焦点放在Kafka的核心模型——MQ。
MQ(Messaging Queue)是一种进程间通信方式,发消息的一方(即生产者)将消息发给MQ,收消息的一方(即消费者)将队列中的消息取出并处理。
看模型,MQ是很简单的,不就是生产者发消息,消费者消费消息,还有个topic,区分发给不同目标的消息。
基本接口也很简单:
生产者发消息:

消费者收消息:

看完模型和接口,你会感觉MQ本身并不难。
但MQ实现有很多,Kafka只是其中一种,为什么会有这么多不同MQ实现呢?因为每个MQ实现有所侧重,有其适用场景。
MQ还提供一定的消息存储能力。当
Pro发消息速度>Con处理消息速度
MQ可起到缓冲作用。所以MQ还能“削峰填谷”:在消息量特别大时,先把消息收下来,慢慢处理,以减小系统压力。
Kafka之所以突出于一大堆MQ实现,关键在于它针对消息写入做优化,它的生产者写入特快,即吞吐力特强。
显然,接口和模型不足以将Kafka与其他MQ实现区分。所以,必须开始了解它的实现。
看软件实现时的关键:
- 软件的结构
- 关键的技术
模型是个抽象概念,被抽象的对象可以是某个聚合实体(订单中心中的订单),也可以是某个流程或功能(Java内存模型中的主存与缓存同步的规则)。
分层对模型来说是实现层面的东西,是一种水平方向的拆分,是一个实现上的规范;
模型的细粒度拆分(父模型、子模型),应该是一种垂直维度的拆分,子模型的功能要高内聚,其复杂性不该发散到外部。
软件结构
软件结构也是软件模型,只不过,它不是整体上的模型,而是展开实现细节之后的模型。模型是分层的。
对每个软件,当你从整体去了解它时,它是完整的一块。但当你打开它的时候,就成了多模块组合,这也是“分层”意义。上一层只要使用下一层提供给它的接口。
所以,当打开一个层次,了解其实现时,先从大处着手。最好找到一张结构图,准确了解它的结构。
如果你能够找到这样一张图,你还是很幸运的。因为在真实的项目中,你可能会碰到各种可能性:
- 结构图混乱:你找到一张图,上面包含了各种内容。比如,有的是模块设计,有的是具体实现,更有甚者,还包括了一些流程
- 结构图复杂:一个比较成熟的项目,图上画了太多的内容。确实,随着项目的发展,软件解决的问题越来越多,它必然包含了更多的模块。但对于初次接触这个项目的我们而言,它就过于复杂了
- 无结构图
想办法画一张
先了解模型和接口,因为它们永远是你的主线。
假设:现在你有了一张结构图,你打算做什么?
了解它的结构?是,但不够。不仅要知道一个设计的结果,最好还要推断出设计原因。
所以,一种更好的做法:带问题上路。
假设自己就是这个软件设计者,问问自己要怎么做。再去对比别人的设计,你就会发现,自己的想法和别人想法的相同或不同。
让你来设计MQ,你会怎么做?
Kafka网上能搜到各种架构图,看个 最简单的架构图,因为最贴近MQ基础模型:
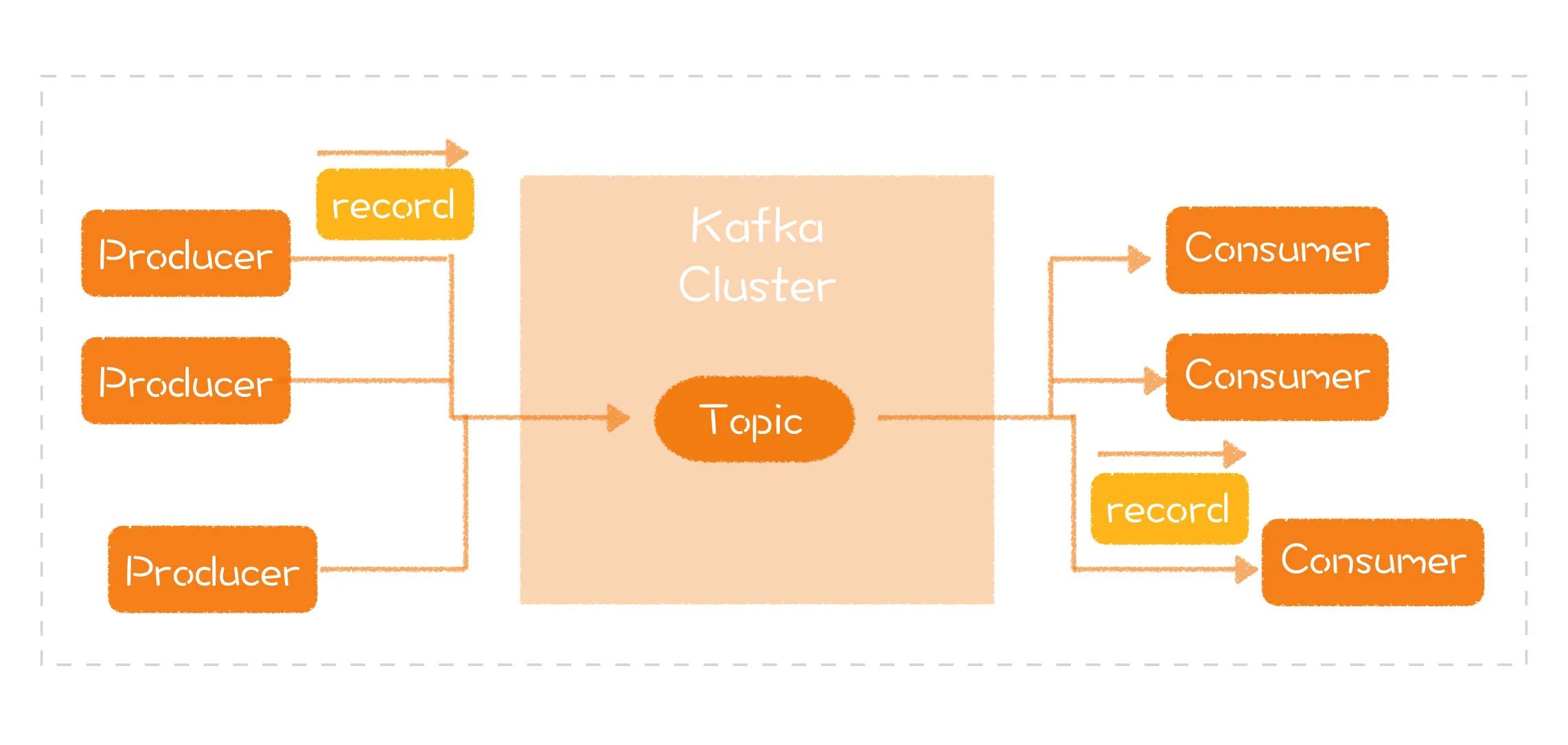
你能看到什么?
- Kafka的生产者一端将消息发给Kafka集群
- 消费者一端将消息取出来进行处理
这样的结构和你想的是不是一样?
进一步设计,会干啥?
- 生产者端封装出一个 SDK,负责消息的发送
- 消费者端封装出一个 SDK,负责消息的接收
- 设计一个集群系统,作为生产者和消费者之间的连接
可以问自己更多的问题:
生产端如果出现网络抖动,消息没有成功发送,怎么重试?
消费端处理完的消息,如何保证集群不重复发送?
为什么要设计一个集群呢?要防止出现单点的故障,而一旦有了集群,就会牵扯到下一个问题,集群内的节点如何保证消息的同步呢?
消息在集群里是怎么存储的?
生产端也好,消费端也罢,如果一个节点彻底掉线,集群该怎么处理呢?
……
有了更多问题,你就会在代码里更深入探索。你可根据需要,打开对应模块,进一步了解实现:
比如消息重发问题,可看生产端是如何解决的。当问题细化到具体实现时,就可以打开源码,去寻找答案。
结构上,Kafka不是一个特复杂系统。所以,若你的项目更复杂,层次更多,推荐把各层次逐一展开,先把整体结构放在心中,再做细节探索。
核心技术
就是能够让这个软件的“实现”与众不同的地方。
了解关键技术可保证我们对代码的调整不会使项目出现明显劣化。
大多数项目都愿意把自己的关键技术讲出来,所以,找到这些信息不难。
Kafka
对写入做了专门优化,使其整体吞吐能力很强。
咋做到的?
MQ实现消息存储的方式通常是把它写入磁盘,而Kafka不同之处在于,它利用磁盘顺序读写特性。
普通机械硬盘:
- 随机写,需按机械硬盘方式寻址,然后磁头做机械运动,写入很慢
- 顺序写,会大幅减少磁头运动
可以这样实现,也是充分利用MQ本身特性:有序,技术实现与需求完美结合的产物。还可进一步优化:利用内存映射文件减少用户空间到内核空间复制的开销。
若站在了解实现的角度,你会觉得这都很自然。
但要想从设计角度学到更多,还是应带着问题上路,多问自己,为什么其它MQ不这么做?
这的确值得深思。Kafka这个实现到底是哪里不容易想到呢?
软硬结合。
其它MQ实现也会把消息写入文件,但文件对于它们只是个通用接口。开发者并没有想过利用硬件的特性做开发。而Kafka开发者突破此限制,把硬件特性利用起来,取得更好结果。
LMAX Disruptor
最强劲的线程通信库。经典代码片段:
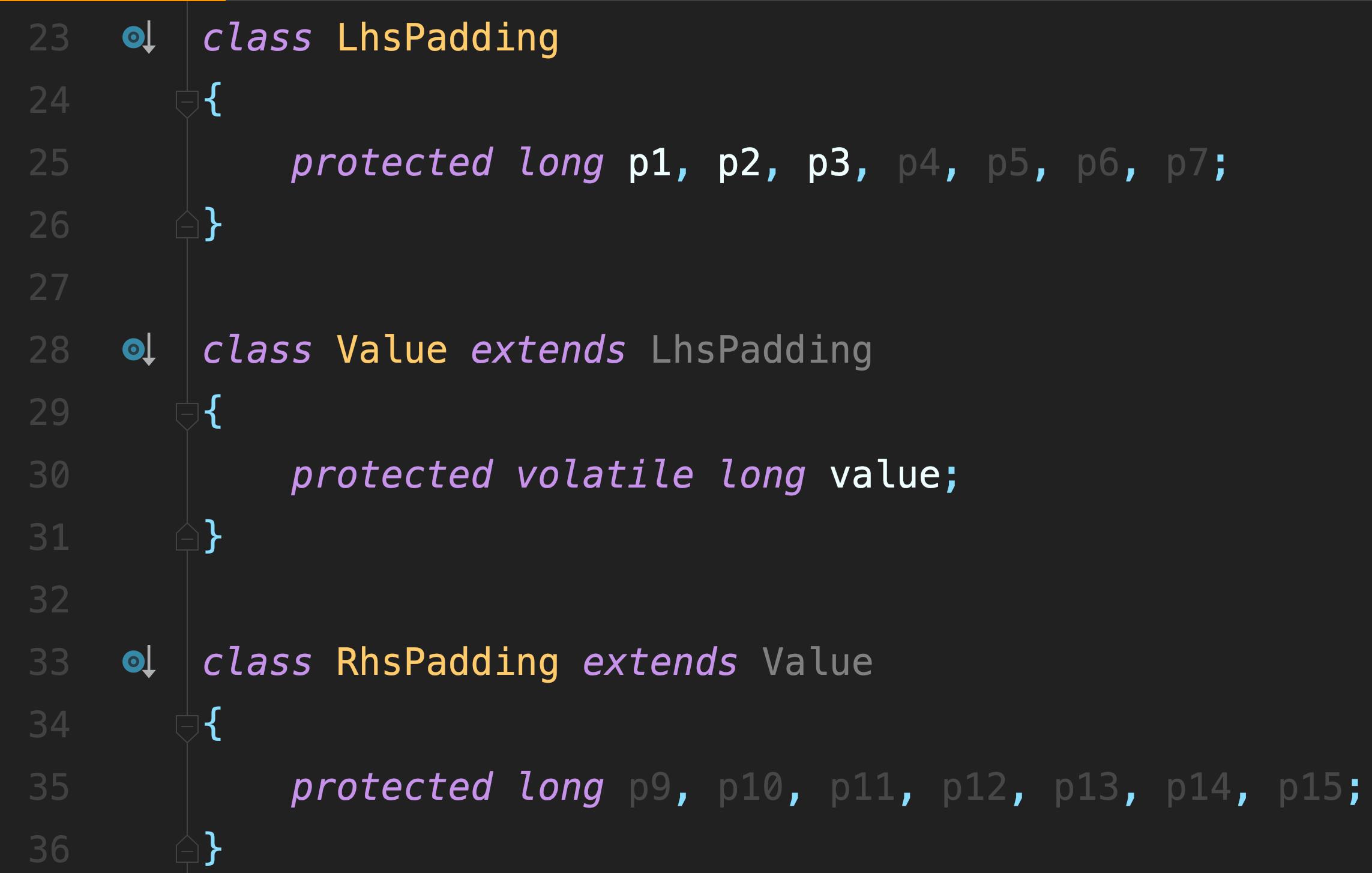
要理解这段代码,必须理解CPU缓存行,这也是软硬结合的设计。
Disruptor缓存行填充中的填充字段。Disruptor中的一个元素是个volatile long类型,占用8字节。
一但一个元素被修改,则与其在同一缓存行的所有元素的缓存都会失效。这就导致变更索引位1的元素,会导致索引位0的元素缓存也失效(操作时需重新从主内存加载)。
所以,Disruptor做了一个缓存行填充的优化,在目标元素的前后都加7个类型字段,两边都占据掉56个字节。故而保证每个元素都独占缓存行。是一种用空间换时间的思想。
总结
理解一个实现,是以对模型和接口的理解为前提。
如果想了解一个系统的实现,应从软件结构和关键技术两个方面着手。无论是软件结构,还是关键技术,我们都需要带着自己的问题入手,而问题的出发点就是我们对模型和接口的理解。
了解软件的结构,其实,就是把分层的模型展开,看下一层模型:
- 要知道这个层次给你提供了怎样的模型
- 要带着自己的问题去了解这些模型为什么要这么设计
Kafka的实现主要是针对机械硬盘做的优化,现在的SSD硬盘越来越多,成本越来越低,这个立意的出发点已经不像以前那样稳固了。
软件的结构和核心技术应该分开,kafka之所以是:
- MQ,看的是对MQ这个模型结构的实现
就没必看存储的实现,应该看路由信息管理、消息生产、消息消费等核心实现及其旁支功能的选择(限制消息大小、故障节点延后、延迟消费) - kafka,看的是其消息存储核心技术实现
如果想知道kafka为什么在 MQ如此突出,那就得了解其核心技术实现,即这里的软硬结合的存储设计。
理解实现,带着自己的问题,了解软件的结构和关键的技术。
以上是关于架构之美-软件实现分析之道的主要内容,如果未能解决你的问题,请参考以下文章
架构之美(软件架构的艺术) PDF扫描版[22MB] 完整版下载
架构之美(软件架构的艺术) PDF扫描版[22MB] 完整版下载