服务高可用利器——限流算法介绍与示例
Posted 恋喵大鲤鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务高可用利器——限流算法介绍与示例相关的知识,希望对你有一定的参考价值。

0.前言
后台服务在面临高并发挑战时,为了保障服务的高可用,业界已经有较为成熟的经验和方法,往往需要采取如下几种措施:

- 负载均衡
将请求均衡地分发到各个服务节点,避免节点出现过载或饥饿的现象。常用的负载均衡算法有轮询法(Round Robin)、随机法(Random)、加权随机法(Weight Random)、最小连接法(Least Connections)、源地址哈希法(Hash)等。
- 分流
不同流量,分而治之,避免相互不影响。如主次分离、读写分离、动静分离等。
- 限 流
过载保护,流控防雪崩。常见算法有计数器算法、滑动窗口算法、漏桶算法和令牌桶算法等,下面会详细讲到。
- 降 级
非核心链路让步,优先保障核心链路。如非核心操作允许失败走兜底,避免影响核心链路。
- 容 灾
应付各种不可抗拒的自然灾难和人为错误;常见做法是存储冗余,服务多地部署等;
- 监 控
实时检测系统关键指标,及时发现问题。
1.计数器
1.1 简介
计数器算法是使用计数器在周期内累加访问次数,当达到设定的限流值时,触发限流策略。下一个周期开始时,进行清零,重新计数。
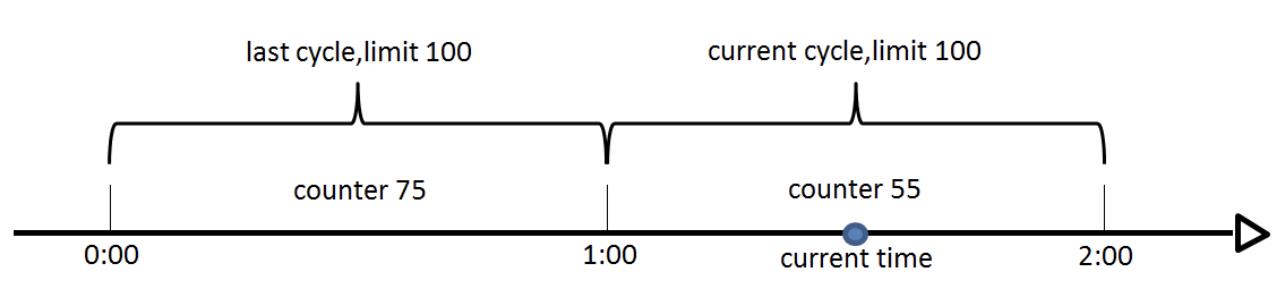
假设 1min 内服务器的负载能力为 100,因此一个周期的访问量限制在 100,然而在第一个周期的最后5秒和下一个周期的开始5秒时间段内,分别涌入 100 的访问量,虽然没有超过每个周期的限制量,但是整体上10s 内已达到 200 的访问量,已远远超过服务器的负载能力。由此可见,计数器算法限流对于周期比较长的限流,存在很大的弊端,这就是该算法的临界值问题。
特点: 实现简单,但存在临界值问题,限流不均匀。
1.2 示例
此算法在单机还是分布式环境下实现都非常简单,如分布式环境下使用 Redis + Lua 原子自增性和线程安全即可轻松实现。Redis 的 TTL(Time to Live) 特性完美的满足了计数器过期这一要求,将时间窗口设置为 Key 的有效时间,然后将 key 的值每次请求+1即可。
Redis + Lua 分布式伪代码实现思路:
// 1.判断是否存在该key
if(EXIST(key)){
// 1.1 自增后判断是否大于最大值,并返回结果
if(INCR(key) > maxPermit){
return false;
}
return true;
}
// 2.不存在 key 则设置 key 初始值为 1,失效时间为 1 秒
SET(key, 1);
EXPIRE(key, 1);
下面是一段可用的 Lua 脚本示例:
local ret = redis.call("exists", KEYS[1])
if ret == 1 then
return redis.call("incr", KEYS[1])
else
local ret = redis.call("set", KEYS[1], 1, "EX", ARGV[1])
if ret.ok == "OK" then
return 1
else
return ret
end
end
2.滑动窗口
2.1 简介
滑动窗口算法是对计数器算法的改进,将时间周期分为 N 个小周期,分别记录每个小周期内访问次数,并且根据时间滑动删除过期的小周期。

如上图,假设时间周期为 1min,将 1min 再分为 2 个小周期,统计每个小周期的访问数量。可以看到,第一个时间周期内访问数量为 75,第二个时间周期内访问数量为 50,超过 50 的访问则被限流掉了。
由此可见,当滑动窗口的格子划分的越多,那么滑动窗口的计数就越平滑,限流的统计就会越精确。
特点: 此算法可以很好地解决固定窗口算法的临界问题。但由于缩短统计周期,增加了空间和时间复杂度。
2.2 示例
滑动窗口算法本质上仍是计数器算法,在计数器算法的基础上,我们将请求数统计周期分割为多个更短的小周期。从当前时间追溯过去最近的多个小周期,获取其累加值来判断是否限流。
Redis + Lua 分布式伪代码如下:
// 1.判断是否存在该小 key
if(EXIST(key)){
// 自增当前短周期计数
INCR(key)
}
// 2.不存在 key 则设置 key 初始值为 1,失效时间为 1 秒
SET(key, 1);
EXPIRE(key, 1);
// 3.判断是否限流
// 获取过去多个短后期计数之和
SUM = GET(key) + GET(key1) + ... + Get(keyn-1)
if(SUM > maxPermit){
return false;
}
return true;
3.漏桶
3.1 简介
漏桶算法是请求到达时放入漏桶(消息队列等),如果当前容量已达到上限(限流值)则丢弃(触发限流策略)。漏桶以固定的速率进行释放请求(业务处理单元处理请求),直到漏桶为空。
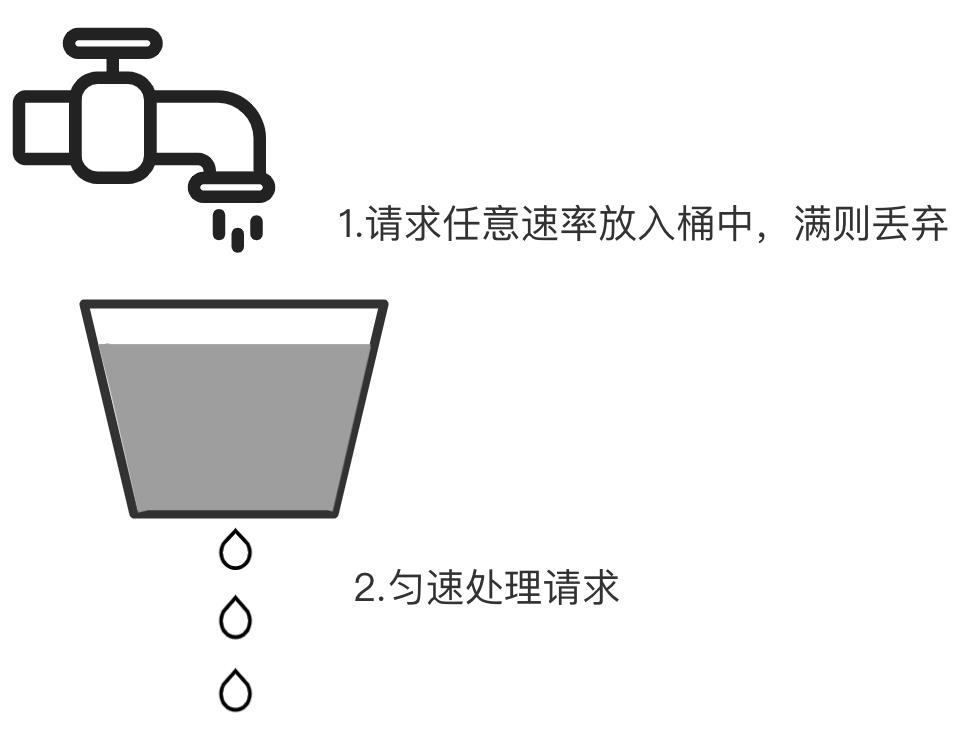
使用场景: 漏桶一般用于保护下游被调,保证流量均匀转发至下游。
特点:限流均匀。
3.2 示例
漏桶一般使用队列实现,比如请求队列就是一种漏桶。
漏桶的容量可以根据请求的超时时间 timeout,处理速率 rate,平均耗时 cost 来定,不然会出现等待超时的情况,一般设为(timeout - cost) * rate 来保证桶内最后一个请求能在超时时间内被处理完。
基于 MQ 分布式伪代码如下:
var capacity; // 桶的容量
var mq // 消息队列
// 获取队列待处理的请求数
var water = GET(mq)
// 判断是否队列已满,满则丢弃
if(water >= capacity) {
return false
}
PUT(mq)
return true
4.令牌桶
4.1 简介
令牌桶算法是程序以 r( r = 时间周期/限流值)的速度向令牌桶中增加令牌,直到令牌桶满。请求到达时向令牌桶请求令牌,如获取到令牌则通过请求,否则触发限流策略。

使用场景: 令牌桶一般用于保护自身,允许一定范围内的突发流量。
特点: 限流均匀,且允许一定范围内的突发流量。
4.2 示例
Redis + Lua 分布式令牌桶伪代码:
var key; // 计数器 Key
var burst; // 桶的容量,同一时刻最大请求限制
var r; // 令牌产生速度
var interval; // 每次向桶里添加令牌的时间间隔(避免每次判断都去生产 token)
var lastTimeKey = key + "last"; // 上一次生产 token 时间
// 1 判断是否存在桶对应的 Key
if(EXIST(key)) {
var value = GET(key);
var diffTime = now() - lastTimeKey;
// 1.1 判断是否超出时间间隔
if(diffTime > interval) {
// 根据时间间隔,计算出应该向桶里添加令牌的个数
var value = MIN(burst, value + r * diffTime)
// 设置 key 的值及操作时间
SET(key, value);
SET(lastTimeKey,now());
}
// 1.2 判断桶里是否有 token,无则限制
if(value <= 0){
reurn false;
}
// token 数减 1
DECR(key);
reture true;
}
// 2.不存在 key 则设初始值为 maxPermit - 1
SET(key, maxPermit -1);
SET(lastTimeKey, now());
return true
上面的实现仅提供一种思路,大家也可以参考 Golang 官方限流组件 time/rate 的实现思路,它基于令牌桶算法,但是比较遗憾的是在单节点下的限流。
5.小结
四种限流算法中最常用的是令牌桶,当然也要结合具体业务场景,没有最好的算法,只有最合适的算法。
各个算法比较入下:
| 算法 | 确定参数 | 空间复杂度 | 时间复杂度 | 平滑限流 | 分布式环境下实现难度 | 缺点 |
|---|---|---|---|---|---|---|
| 计数器 | 计数周期T、周期内最大访问数N | O(1)(记录周期内访问次数) | O(1) | 否 | 低 | 存在临界值问题 |
| 滑动窗口 | 计数周期数n、计数周期T、周期内最大访问数N | O(n)(n个计数周期) | O(n) | 滑动窗口划分越细,限流越平滑 | 中 | 空间&时间复杂度较高 |
| 漏桶 | 漏桶容量N、漏桶流出速度r | O(N)(记录桶内请求) | O(1) | 是 | 高 | 无 |
| 令牌桶 | 令牌桶容量N、令牌产生速度r | O(1)(记录桶内令牌数) | O(1) | 是 | 高 | 无 |
关于漏桶与令牌桶的区别,很多文章作者自己没搞清楚就在那乱写,混淆视听,误人子弟。推荐参考这篇文章,基本说清了二者的区别:漏桶算法和令牌桶算法,区别到底在哪里?
二者区别: 漏桶的本质是总量控制,令牌桶的本质是速率控制。至于这个控制,既可以用来保护自己,也可以用来保护别人。
参考文献
CSDN.【架构】高可用高并发系统设计原则
CSDN.常用4种限流算法介绍及比较
限流方案常用算法讲解 - callbin - 博客园
限流算法的实现(redis + lua)
漏桶算法和令牌桶算法,区别到底在哪里?
以上是关于服务高可用利器——限流算法介绍与示例的主要内容,如果未能解决你的问题,请参考以下文章