大数据Spark MLlib机器学习
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark MLlib机器学习相关的知识,希望对你有一定的参考价值。
目录
1 什么是Spark MLlib?
MLlib是Spark的机器学习(ML)库。旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
MLlib目前分为两个代码包:
- spark.mllib 包含基于RDD的原始算法API。
- spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习管道。
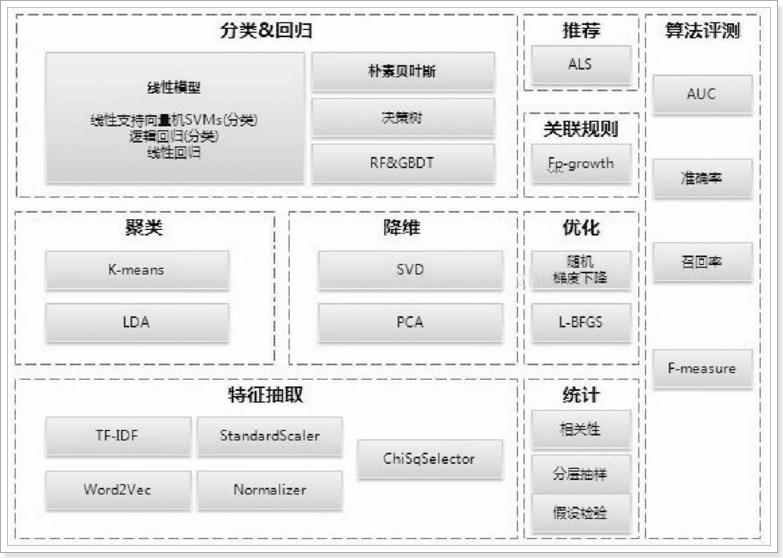
MLlib支持的算法库如下:
2 支持的数据类型
MLlib支持的数据类型是比较丰富的,从最基本的Spark数据集RDD到部署在集群中向量和矩阵,并且还支持部署在本地计算机中的本地化格式。

2.1 本地向量集
MLlib使用的本地化存储类型是向量,这里的向量主要由两类构成:稀疏型数据集(sparse)和密集型数据集(dense)。
导入MLlib的依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>2.4.3</version>
</dependency>
密集向量由double类型的数组支持,而稀疏向量则由两个平行数组支持。
example:
向量(5.2,0.0,5.5)
密集向量表示:[5.2,0.0,5.5]
稀疏向量表示:(3,[0,2],[5.2,5.5]) # 3是向量(5.2,0.0,5.5)的长度,除去0值外,其他两个值的索引和值分别构成了数组[0,2]和数组[5.2,5.5]。
2.1.1、密集型数据集
package cn.itcast.spark;
import org.apache.spark.mllib.linalg.Vector;
import org.apache.spark.mllib.linalg.Vectors;
import org.junit.Test;
public class SparkMLlib {
@Test
public void testDense(){
Vector vd = Vectors.dense(9, 5, 2, 7); //定义密集型向量
double v = vd.apply(2); //获取下标为2的值
System.out.println(v); //2
}
}
2.1.2 稀疏型数据集
@Test
public void testSparse() {
int[] indexes = new int[]{0, 1, 2, 5};
double[] values = new double[]{9, 5, 2, 7};
Vector vd = Vectors.sparse(6, indexes, values); //定义稀疏型向量
double v = vd.apply(2); //获取下标为2的值
double v2 = vd.apply(4); //获取下标为4的值
double v3 = vd.apply(5); //获取下标为5的值
System.out.println(v); //2
System.out.println(v2); //0
System.out.println(v3); //7
}
2.2 向量标签
向量标签用于MLLIB中机器学习算法做标记。在分类问题中,可以将不同的数据集分成若干份,以整数型0、1、2进行标记。例如:垃圾邮件标记为1,非垃圾邮件标记为0。
@Test
public void testLabeledPoint(){
Vector vd = Vectors.dense(9, 5, 2, 7); //定义密集型向量
LabeledPoint lp = new LabeledPoint(1, vd); //定义标签向量
System.out.println(lp.features());
System.out.println(lp.label());
System.out.println(lp);
System.out.println("------------");
int[] indexes = new int[]{0, 1, 2, 3};
double[] values = new double[]{9, 5, 2, 7};
Vector vd2 = Vectors.sparse(4, indexes, values); //定义稀疏型向量
LabeledPoint lp2 = new LabeledPoint(2, vd2);
System.out.println(lp2.features());
System.out.println(lp2.label());
System.out.println(lp2);
}
2.3 本地矩阵
大数据运算中,为了更好地提升计算效率,可以更多地使用矩阵运算进行数据处理。部署在单机中的本地矩阵就是一个很好的存储方法。举一个简单的例子,例如一个数组Array(1,2,3,4,5,6),将其分为2行3列的:
@Test
public void testMatrix() {
double[] values = new double[]{1, 2, 3, 4, 5, 6};
Matrix mx = Matrices.dense(2, 3, values);
System.out.println(mx);
}
运行结果:
1.0 3.0 5.0
2.0 4.0 6.0
2.4 分布式矩阵
分布式矩阵由长整型行列索引和双精度浮点型值数据组成,分布式存储在一个或多个RDD中,对于巨大的分布式矩阵来说,选择正确的存储格式非常重要,将一个分布式矩阵转化为另外一个不同格式需要混洗(shuffle),其代价很高。在MLlib实现了四类分布式矩阵存储格式,分别是:
- 行矩阵(RowMatrix)
- 行索引矩阵(IndexedRowMatrix)
- 坐标矩阵(CoordinateMatrix)
- 分块矩阵(BlockMatrix)
2.4.1 行矩阵
行矩阵是最基本的一种矩阵类型。行矩阵是以行作为基本方向的矩阵存储格式,列的作用相对较小。可以将其理解为行矩阵是一个巨大的特征向量的集合。每一行就是一个具有相同格式的向量数据,且每一行的向量内容都可以单独取出来进行操作。
a.txt:
1 2 3
4 5 6
@Test
public void testRowMatrix() {
SparkConf sparkConf = new SparkConf()
.setAppName("SparkMLlib")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
JavaRDD<String> rdd1 = jsc.textFile("F:\\\\code\\\\files\\\\a.txt");
JavaRDD<Vector> rdd2 = rdd1.map(v1 -> {
String[] ss = v1.split(" ");
double[] ds = new double[ss.length];
for (int i = 0; i < ss.length; i++) {
ds[i] = Double.valueOf(ss[i]);
}
return Vectors.dense(ds);
});
RowMatrix rmx = new RowMatrix(rdd2.rdd());
System.out.println(rmx.numRows()); //2
System.out.println(rmx.numCols()); //3
}
2.4.2 行索引矩阵
An IndexedRowMatrix类似于a RowMatrix但具有有意义的行索引。它由索引行的RDD支持,因此每行由其索引(long-typed)和本地向量表示。
@Test
public void testIndexedRowMatrix() {
SparkConf sparkConf = new SparkConf()
.setAppName("SparkMLlib")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
JavaRDD<String> rdd1 = jsc.textFile("F:\\\\code\\\\files\\\\a.txt");
JavaRDD<Vector> rdd2 = rdd1.map(v1 -> {
String[] ss = v1.split(" ");
double[] ds = new double[ss.length];
for (int i = 0; i < ss.length; i++) {
ds[i] = Double.valueOf(ss[i]);
}
return Vectors.dense(ds);
});
JavaRDD<IndexedRow> rdd3 = rdd2.map(v1 -> new IndexedRow(v1.size(), v1)); //建立待索引的行
IndexedRowMatrix irmx = new IndexedRowMatrix(rdd3.rdd()); //行索引
JavaRDD<IndexedRow> rdd4 = irmx.rows().toJavaRDD();
List<IndexedRow> collect = rdd4.collect();
collect.forEach(indexedRow -> System.out.println(indexedRow)); //打印行内容
}
2.4.3 坐标矩阵
CoordinateMatrix是由其条目的RDD支持的分布式矩阵。每个条目都是一个元组(i: Long, j: Long, value: Double),其中i是行索引,j是列索引, value是条目值。只有当矩阵的两个维度都很大并且矩阵非常稀疏时,才应该使用它。
@Test
public void testCoordinateMatrix() {
SparkConf sparkConf = new SparkConf()
.setAppName("SparkMLlib")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
JavaRDD<String> rdd1 = jsc.textFile("F:\\\\code\\\\files\\\\a.txt");
JavaRDD<MatrixEntry> rdd2 = rdd1.map(v1 -> {
String[] ss = v1.split(" ");
return new MatrixEntry(Long.valueOf(ss[0]),Long.valueOf(ss[1]),Double.valueOf(ss[2]));
});
CoordinateMatrix matrix = new CoordinateMatrix(rdd2.rdd());
List<MatrixEntry> collect = matrix.entries().toJavaRDD().collect();
for (MatrixEntry matrixEntry : collect) {
System.out.println(matrixEntry);
}
}
2.4.4 分块矩阵
BlockMatrix是支持矩阵分块RDD的分布式矩阵,其中矩阵分块由((int,int),matrix)元祖所构成(int,int)是该部分矩阵所处的矩阵的索引位置,Matrix表示该索引位置上的子矩阵
分块矩阵支持矩阵加法和乘法,并设有辅助函数验证用于检查矩阵是否设置正确。
@Test
public void testCoordinateMatrix() {
SparkConf sparkConf = new SparkConf()
.setAppName("SparkMLlib")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
JavaRDD<String> rdd1 = jsc.textFile("F:\\\\code\\\\files\\\\a.txt");
JavaRDD<MatrixEntry> rdd2 = rdd1.map(v1 -> {
String[] ss = v1.split(" ");
return new MatrixEntry(Long.valueOf(ss[0]),Long.valueOf(ss[1]),Double.valueOf(ss[2]));
});
CoordinateMatrix matrix = new CoordinateMatrix(rdd2.rdd());
//转化成块矩阵
BlockMatrix blockMatrix = matrix.toBlockMatrix();
// 对该分块矩阵进行检验,确认该分块是否正确,如果不正确则抛出异常
blockMatrix.validate();
BlockMatrix addBlockMatrix = blockMatrix.add(blockMatrix); // 相加
List<Tuple2<Tuple2<Object, Object>, Matrix>> collect = addBlockMatrix.blocks().toJavaRDD().collect();
for (Tuple2<Tuple2<Object, Object>, Matrix> tuple2MatrixTuple2 : collect) {
System.out.println(tuple2MatrixTuple2);
}
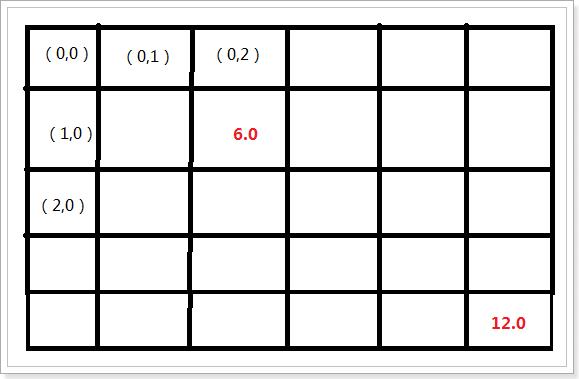
// ((0,0),5 x 6 CSCMatrix
// (1,2) 6.0
// (4,5) 12.0)
}
结果说明:
不论是索引值还是坐标值都是从0开始,所以行数是索引值加1
3 RDD、DataSet、Dataframe区别及转化
RDD(Spark1.0)—>DataFrame(Spark1.3)---->DataSet(Spark1.6)
SparkSql提供了Dataframe和DataSet的数据抽象,DataFrame就是RDD+Schema,可以认为是一张二维表格。它的劣势是在编译器不对表格中的字段进行类型检查。在运行期间检查。DataSet是Spark最新数据抽象,Spark的发展会逐步将DataSet作为主要的数据抽象,弱化RDD和DataFrame。DataSet包含了DataFrame所有的优化机制。除此之外提供了以样例类为Schema模型的强类型。
个人理解:
JavaRDD<String[]> map = source.map(line -> line.split(","));
List<String[]> collect = source.map(line -> line.split(",")).collect();
rdd是一种特殊的分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract,当collect转变为本质的存储类型.map进行以行为单位或者list进行遍历.每行的数据类型为String[].
示例:
package cn.itcast.spark;
import java.io.Serializable;
public class Student implements Serializable {
private Long id;
private String name;
private Integer age;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\\'' +
", age=" + age +
'}';
}
}
users.txt:
1,zhangsan,20
2,lisi,21
3,wangwu,19
4,zhaoliu,18
@Test
public void testDataSet() {
SparkSession sparkSession = SparkSession.builder().appName("SparkMLlib").master("local[*]").getOrCreate();
// 读取文件
JavaRDD<String> source = sparkSession.read().textFile("F:\\\\code\\\\users.txt").toJavaRDD();
JavaRDD<Student> rowRDD = source.map(line -> {
String parts[] = line.split(",");
Student student = new Student();
student.setId(Long.valueOf(parts[0]));
student.setName(parts掌握Spark机器学习库 大数据开发技能更进一步
学习笔记Spark—— Spark MLlib应用—— 机器学习简介Spark MLlib简介