[hadoop3.x]HDFS存储类型和存储策略概述
Posted manor的大数据奋斗之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[hadoop3.x]HDFS存储类型和存储策略概述相关的知识,希望对你有一定的参考价值。
前言
目前博客Hadoop文章大都停留在Hadoop2.x阶段,本系列将依据黑马程序员大数据Hadoop3.x全套教程,对2.x没有的新特性进行补充更新,一键三连加关注,下次不迷路!
历史文章
[hadoop3.x系列]HDFS REST HTTP API的使用(一)WebHDFS
[hadoop3.x系列]HDFS REST HTTP API的使用(二)HttpFS
[hadoop3.x系列]Hadoop常用文件存储格式及BigData File Viewer工具的使用(三)
✨[hadoop3.x]新一代的存储格式Apache Arrow(四)
🍑 HDFS存储类型和存储策略
🐒 介绍
l Archive存储(档案存储)是一种将增长的存储容量与计算容量解耦的解决方案
l 可以将一些需要存储、但计算需求很少的数据放在低成本的存储节点中,这些节点用于集群中冷数据的存储
l 根据策略,热数据可以转移到冷节点存储。在冷区域中加入更多的节点可以使存储与集群中的计算容量无关
l 异构存储和归档存储提供的框架将HDFS体系结构概括为包括其他类型的存储介质,包括:SSD和内存。用户可以选择将数据存储在SSD或内存中以获得更好的性能。
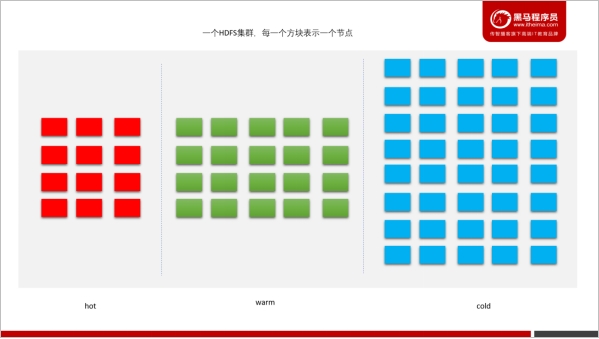
🍑 存储类型和存储策略
🐒 多种多样的存储类型
大家考虑一个问题:我们可以将数据保存在什么样的存储类型中呢?

- 硬盘
SSD
SATA
-
内存
-
NAS
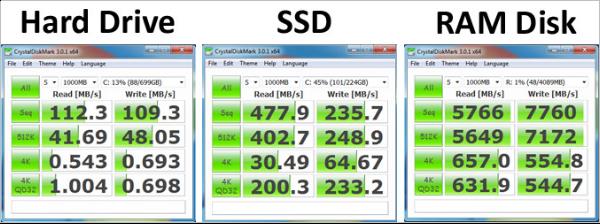
🐒 速率对比
RAM比SSD快几个数量级。普通的磁盘大致的速度为30-150MB,比较快的SSD可以实现500MB /秒的实际写入速度。 RAM的理论上最大速度可以达到SSD实际性能的30倍。
以下是一个实际对比图:
🐒 存储类型
之前在hdfs-site.xml中配置,是将数据保存在Linux中的本地磁盘。
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/server/hadoop-3.1.4/data/datanode</value> <description>
DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
以上配置跟下面的配置是一样的:
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]:/export/server/hadoop-3.1.4/data/datanode</value> <description>
DataNode存储名称空间和事务日志的本地文件系统上的路径</description></property>
在HDFS中,可以给不同的存储介质分配不同的存储类型:
l DISK:默认的存储类型,磁盘存储
l ARCHIVE:具有存储密度高(PB级),但计算能力小的特点,可用于支持档案存储。
l SSD:固态硬盘
l RAM_DISK:DataNode中的内存空间
🐒 存储策略介绍
HDFS中提供热、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence等存储策略。为了根据不同的存储策略将文件存储在不同的存储类型中,引入了一种新的存储策略概念。HDFS支持以下存储策略:
热(hot)
l 用于大量存储和计算
l 当数据经常被使用,将保留在此策略中
l 当block是hot时,所有副本都存储在磁盘中。
冷(cold)
l 仅仅用于存储,只有非常有限的一部分数据用于计算
l 不再使用的数据或需要存档的数据将从热存储转移到冷存储中
l 当block是cold时,所有副本都存储在Archive中
温(warm)
l 部分热,部分冷
l 当一个块是warm时,它的一些副本存储在磁盘中,其余的副本存储在Archive中
全SSD
将所有副本存储在SSD中
单SSD
在SSD中存储一个副本,其余的副本存储在磁盘中。
懒持久
用于编写内存中只有一个副本的块。副本首先写在RAM_Disk中,然后惰性地保存在磁盘中。
🐒 HDFS中的存储策略
HDFS存储策略由以下字段组成:
策略ID(Policy ID)
策略名称(Policy Name)
块放置的存储类型列表(Block Placement)
用于创建文件的后备存储类型列表(Fallback storages for creation)
用于副本的后备存储类型列表(Fallback storages for replication)
当有足够的空间时,块副本将根据#3中指定的存储类型列表存储。当列表#3中的某些存储类型耗尽时,将分别使用#4和#5中指定的后备存储类型列表来替换空间外存储类型,以便进行文件创建和副本。
以下是一个典型的存储策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | ARCHIVE | |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | ||
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事项:
Lazy_Persistence策略仅对单个副本块有用。对于具有多个副本的块,所有副本都将被写入磁盘,因为只将一个副本写入RAM_Disk并不能提高总体性能。
对于带条带的擦除编码文件,合适的存储策略是ALL_SSD、HOST、CORD。因此,如果用户为EC文件设置除上述之外的策略,在创建或移动块时不会遵循该策略。
🐒 存储策略方案
l 创建文件或目录时,其存储策略为未指定状态。可以使用:
storagepolicies -setStoragePolicy
命令指定
l 文件或目录的有效存储策略由以下规则解析:
如果使用存储策略指定了文件或目录,则返回该文件或目录。
对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略
l 可以使用storagepolicies –getStoragePolicy命令获取有效的存储策略
🐒 配置
l dfs.storage.policy.enabled
启用/禁用存储策略功能。默认值是true
l dfs.datanode.data.dir
l 在每个数据节点上,应当用逗号分隔的存储位置标记它们的存储类型。这允许存储策略根据策
略将块放置在不同的存储类型上。
磁盘上的DataNode存储位置/grid/dn/disk 0应该配置为[DISK]file:///grid/dn/disk0
SSD上的DataNode存储位置/grid/dn/ssd 0应该配置为 [SSD]file:///grid/dn/ssd0> 存档上的DataNode存储位置/grid/dn/Archive 0应该配置为 [ARCHIVE]file:///grid/dn/archive0
将RAM_磁盘上的DataNode存储位置/grid/dn/ram0配置为[RAM_DISK]file:///grid/dn/ram0
如果DataNode存储位置没有显式标记存储类型,它的默认存储类型将是磁盘。
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 manor 原创,首发于 CSDN博客🙉
📢Hadoop系列文章会每天更新!✨
以上是关于[hadoop3.x]HDFS存储类型和存储策略概述的主要内容,如果未能解决你的问题,请参考以下文章
[hadoop3.x]HDFS存储策略和冷热温三阶段数据存储概述