HiveQL数据查询进阶
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveQL数据查询进阶相关的知识,希望对你有一定的参考价值。
HiveQL数据查询进阶
Hive内置函数
Hive内置函数就是Hive数据仓库工具已经帮助开发者实现好的可以拿来即用的函数,就好像传统的关系型数据库为开发者提供的丰富的函数,如sum、count、sqrt等。Hive提供的这些内置函数与关系型数据库所提供的函数在形式和功能上都是一样的。
首先,我们来浏览一下Hive都提供了哪些内置函数,
show functions;

Hive内置函数可以分为:数学函数、字符函数、收集函数、转换函数、日期函数、条件函数、聚合函数以及表生成函数。
数学函数
四则运算+-*/略。
round
四舍五入的应用
select round(88.947,2),round(77.912,1),round(55.667,2);

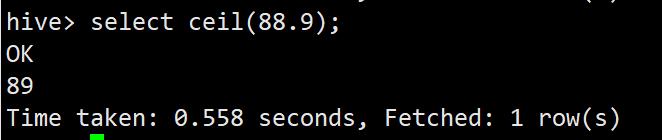
ceil
向上取整函数
select ceil(88.9);
floor
向下取整
select floor(88.9);

pow
取平方函数
select pow(3,2);

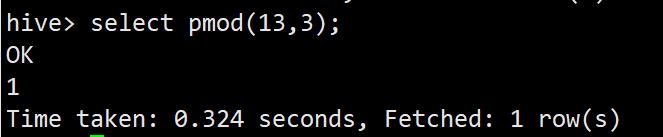
pmod
取模函数
select pmod(13,3);
字符函数
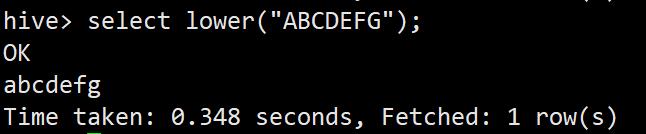
lower转小写函数
select lower("ABCDEFG");
upper转大写函数
select upper("abcdefg");

length字符串长度函数
select length("hadoop");

concat字符串
生成hadoop和spark的合并
select concat("hadoop","&spark");

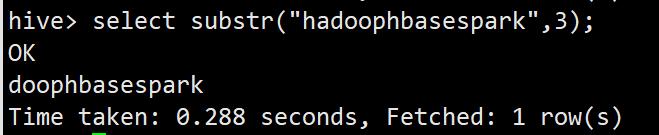
substar求子串函数
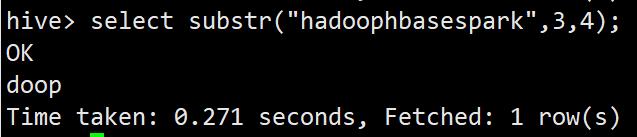
select substr("hadoophbasespark",3);
select substr("hadoophbasespark",3,4);
trim去前后空格函数
select trim(" hadoop ");

get_json_object用于处理json格式数据的函数
创建准备存放json格式数据的表weixin,并向其中写入json格式的数据,然后应用get_json_object函数来处理表weixin中的json格式的数据。
use sogou;
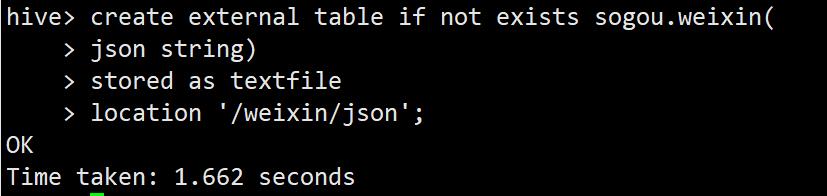
create external table if not exists sogou.weixin(
json string)
stored as textfile
location '/weixin/json';
构造json格式的数据文件weixin.txt,并在文件中写入
vi weixin.txt
[{"name":"zhangsan","age":23,"address":"GanSu"}]
[{"name":"zhangsan2","age":21,"address":"shangdong"}]
[{"name":"zhangsan3","age":22,"address":"beijing"}]
向Hive的表sogou.weixin中加载json格式的数据:
hdfs dfs -put ~/weixin.txt /weixin/json
select * from sogou.weixin;
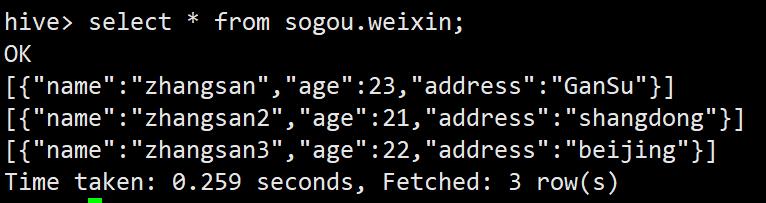
如上所示,表weixin中的数据都是json格式的字符串,使用get_json_object函数就可以轻松处理该json数据格式。
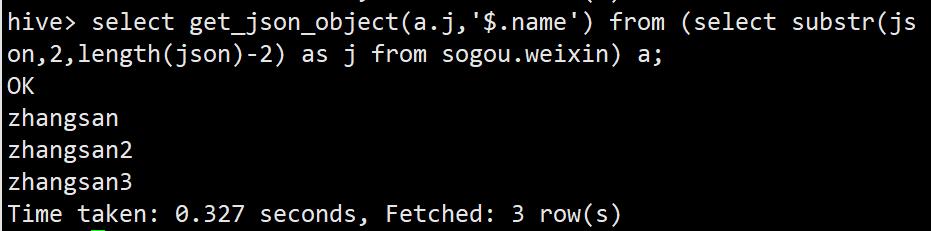
select get_json_object(a.j,'$.name') from (select substr(json,2,length(json)-2) as j from sogou.weixin) a;
转换函数
类型转换函数cast
select cast(99 as double);

select cast("2020-1-30" as date);

日期函数
使用year、month和day分别获取年份、月份、日的函数
select year("2019-9-16 14:36:40"),month("2019-9-16 14:36:40"),day("2019-9-16 14:36:40");

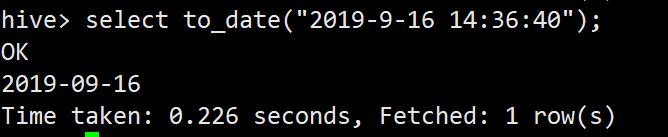
to_date返回日期时间字段中的日期部分
select to_date("2019-9-16 14:36:40");
聚合函数
count返回行数
求员工表中员工的总人数
select count(*) from emp;

sum组内某列求和函数
select job,sum(sal) from emp group by job;

min:组内某列最小值
select job,min(sal)from emp group by job;

max:组内某列最大值
select job,max(sal) from emp group by job;
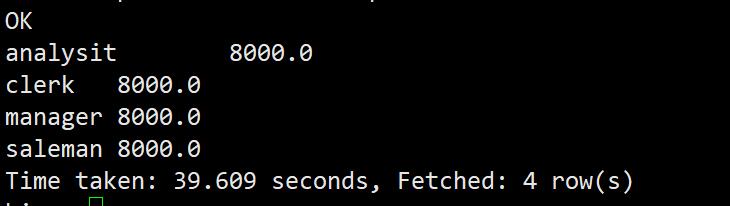
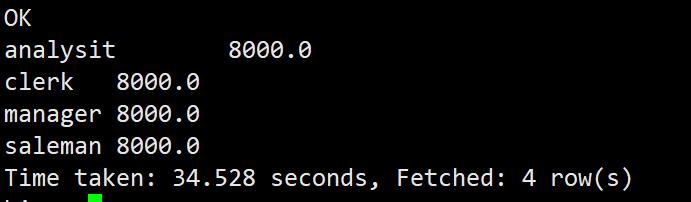
avg:组内某列平均值
select job,avg(sal) from emp group by job;
Hive构建搜索引擎日志数据分析系统
Hive计数的出现成功地将传统地SQL语句移植到大数据平台,使得开发者可以继续沿用传统地SQL数据分析方法而不必去学习额外的分析语言,这使得开发人员学习运用Hive的成本大大降低,因此Hive技术得到了快速的发展与推广。另外,Hive的开发效率比MapReduce高了许多。有了Hive技术,开发人员很少再去写MapReduce程序,仅用一条SQL语句就可以实现复杂的数据分析任务了。当然,Hive负责将SQL语句解析为MapReduce的Job任务在集群上运行。
数据预处理(Linux环境)
引擎搜索日志的数据格式为:访问时间\\t用户 ID\\t[查询词]\\t该URL在URL在返回结果中的排名\\t用户点击的顺序号\\t用户点击的URL地址。其中,用户ID是根据用户使用浏览器访问搜索引擎时的cookie信息自动赋值的,也就是使用同一浏览器输入的多次不同查询所产生的多条搜索记录,对应同一个用户ID信息。
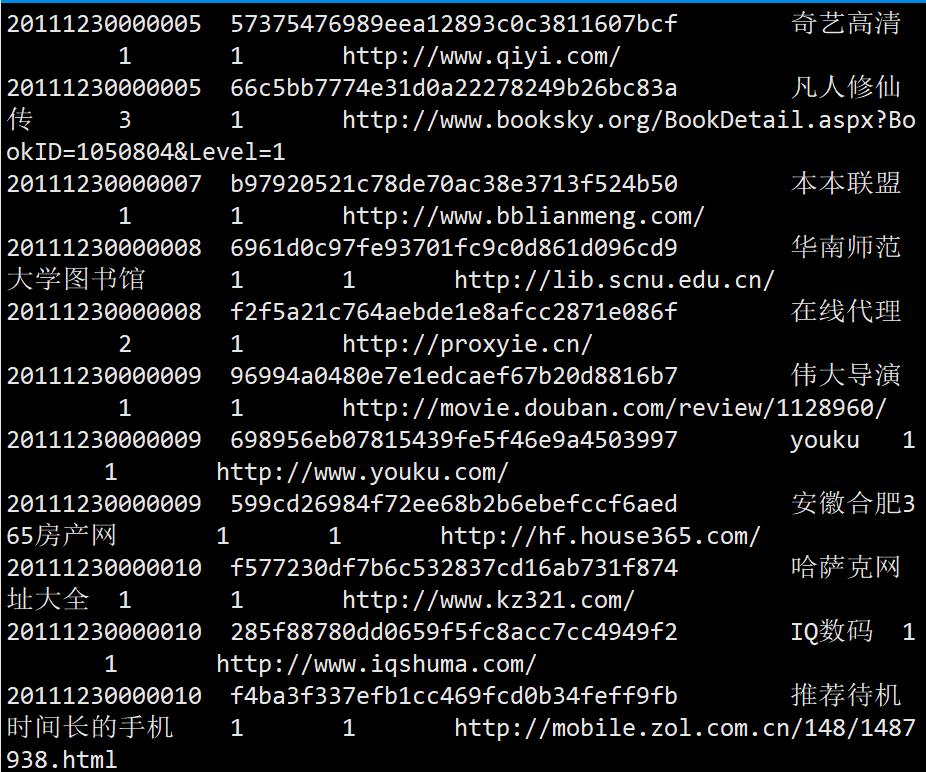
查看数据
进入实验数据文件夹用less命令查看
less sogou.500w.utf8
wc -l sogou.500w.utf8

数据扩展
将用户访问时间字段拆分并拼接,在原始数据每行后面添加年、月、日、小时字段,用以扩充原始数据,为后面创建分区表做好数据准备工作。为此,我们需要编写一个Linux的shell脚本程序来完成数据的拓展任务。
#!/bin/bash
infile=$1
outfile=$2
awk -F '\\t' '{print $0"\\t"substr($1,1,4)"\\t"substr($1,5,2)"\\t"substr($1,7,2)"\\t"substr($1,9,2)}' $infile > $outfile
bash sogou-log-extend.sh /home/hadoop/sogou.500w.utf8 /home/hadoop/sogou.500w.utf8.ext
less sogou.500w.utf8.ext

数据加载
将数据加载到HDFS
hdfs dfs -mkdir -p /sogou/20111230;
hdfs dfs -put /home/hadoop/sogou.500w.utf8 /sogou/20111230;

hdfs dfs -mkdir -p /sogou_ext/20111230;
hdfs dfs -put /home/hadoop/sogou.500w.utf8.ext /sogou_ext/20111230;

基于Hive构建日志数据的数据仓库
首先要求Hadoop集群已正常启动,然后打开Hive客户端
基本操作
show databases;
create database if not exists sogou;
use sogou;
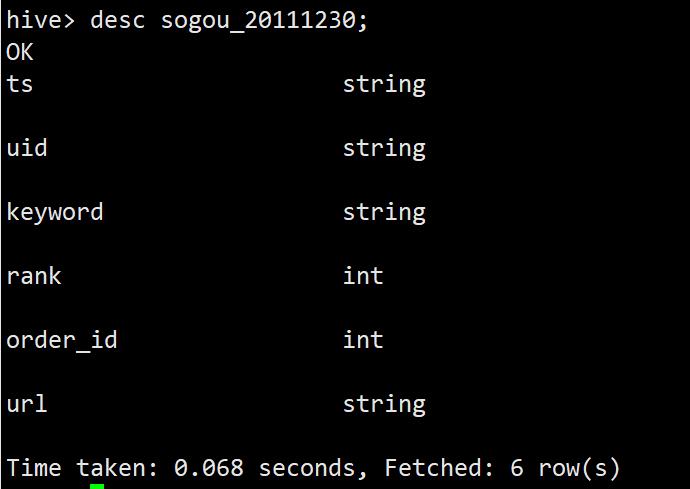
create external table sogou.sogou_20111230(
ts string,
uid string,
keyword string,
rank int,
order_id int,
url string)
comment 'this is the sogou search data of one day'
row format delimited
fields terminated by '\\t'
stored as textfile
location '/sogou/20111230';
创建分区表(按照年、月、天、小时分区)
create external table sogou.sogou_ext_20111230(
ts string,
uid string,
keyword string,
rank int,
order_id int,
url string,
year int,
month int,
day int,
hour int)
comment 'this is the sogou search data of extend'
row format delimited
fields terminated by '\\t'
stored as textfile
location '/sogou_ext/20111230';
然后创建带分区的表
create external table sogou.sogou_partition(
ts string,
uid string,
keyword string,
rank int,
order_id int,
url string)
comment 'this is the sogou search data of partitioned'
partitioned by (year int,month int,day int,hour int)
row format delimited
fields terminated by '\\t'
stored as textfile;

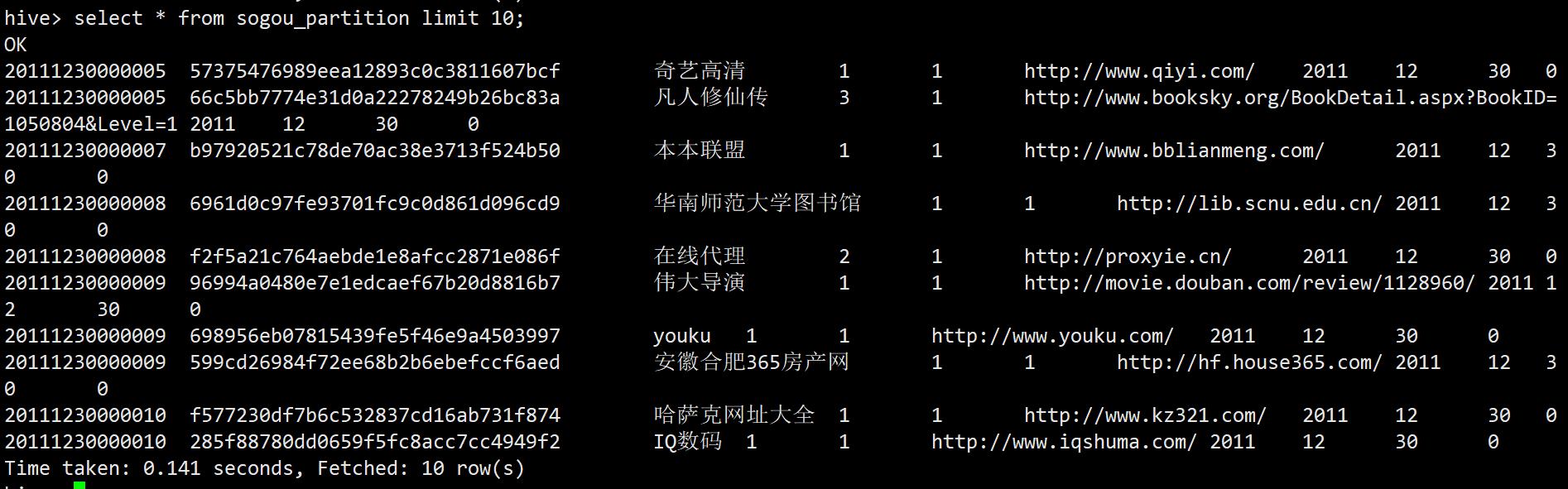
最后向分区表sogou_partition中载入数据:
set hive.exec.dynamic.partition.mode=nonstriot;
insert overwrite table sogou.sogou_partition partition(year,month,day,hour) select * from sogou.sogou_ext_20111230;
查询结构
使用以下命令查询结果
select * from sogou_partition limit 10;
数据分析需求(1):条数统计
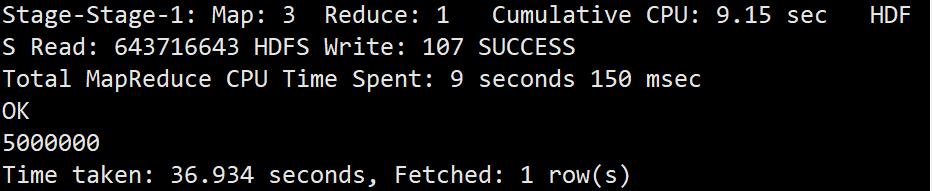
数据总条数统计
select count(*) from sogou.sogou_ext_20111230;

非空查询条数
select count(*) from sogou.sogou_ext_20111230 where keyword is not null and keyword != '';
无重复总条数(根据ts、uid、keyword、url)
select count(*) from (select uid,count(*) from sogou.sogou_ext_20111230 group by ts,uid,keyword,url having count(*) = 1 ) t

注:在嵌套查找时,必须给子表命名一个别名。在分组查询时在同一组但非分组列值不同的记录,输出时会引起错误。
独立UID总数的HiveQL脚本
select count(distinct(uid)) from sogou.sogou_ext_20111230;

数据分析需求(2):关键词分析
查询关键词平均长度统计
select avg(a.cnt) from (select size(split(keyword,' s+')) as cnt from sogou.sogou_ext_20111230) a;

注:此处计算时可能进度非常慢,这是可能是因为split函数不支持矢量化,禁用矢量化之后十几秒就可以处理完。
set hive.vectorized.execution.enabled=false;
查询频度排名(将搜索关键词频度最高的前50词列出)
select keyword,count(*) as cnt from sogou.sogou_ext_20111230 group by keyword order by cnt desc limit 50;

数据分析需求(3):UID分析
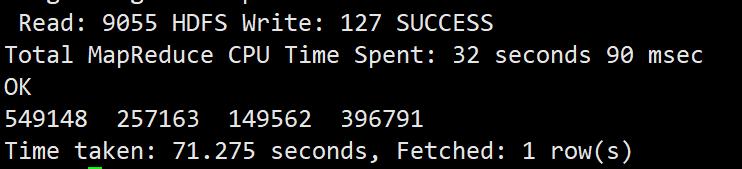
为了统计UID的查询次数分布(查询1次的UID个数…查询n次的UID个数),这里我们列出查询1次、2次、3次和大于3次的UID个数
select sum(if(uids.cnt=1,1,0)),sum(if(uids.cnt=2,1,0)), sum(if(uids.cnt=3,1,0)), sum(if(uids.cnt>3,1,0)) from (select uid, count(*) as cnt from sogou.sogou_ext_20111230 group by uid) uids;
统计UID平均查询次数
select sum(a.cnt)/count(a.uid)from(select uid,count(*)as cnt from sogou.sogou_ext_20111230 group by uid) a;

统计查询次数大于2次的用户占比:
UID总数统计
select count(distinct(uid))from sogou.sogou_ext_20111230;

统计查询次数大于2次的用户总数
select count(a.uid) from (select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid having cnt>2)a;

结果是C=B/A
查询次数大于2次的数据
select b.* from(select uid,count(*) as cnt from sogou.sogou_ext_20111230 group by uid having cnt >2) a join sogou.sogou_ext_20111230 b on a.uid=b.uid limit 50;

Sqoop应用与开发
在实际开发中我们经常会碰到这样一种需求,即大数据平台处理完的数据需要导入关系型数据库,反之关系型数据库中的数据也需要导入大数据平台,为此大数据平台为我们提供了Sqoop工具来解决这一需求。
Sqoop简介
Sqoop是Apache开源的顶级项目之一,用于在ApacheHadoop和关系型数据库等结构化数据存储之间高效传输大容量数据的工具。也就是说,Sqoop是一款类ETL工具,主要负责将大数据平台处理完的数据导入关系型数据库中,或者将关系型数据库中的数据带入大数据平台。
Sqoop安装部署
安装环境
在安装Sqoop之前确保hadoop正确启动,运行,mysql正常运行。
解压安装
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mv sqoop-1.4.7.bin__hadoop-2.6.0 /usr/local/sqoopmv sqoop-1.4.7.bin__hadoop-2.6.0 /usr/local/sqoop
更改目录权限
chown hadoop:hadoop -R /usr/local/sqoop/
配置Sqoop
1)配置MySQL连接器
Sqoop底层通过JDBC的方式访问MySQL数据库,所以需要把MySQL数据库的驱动程序复制到Sqoop的依赖包,这里可以使用hive的mysql驱动(如果有)
cp /usr/local/hive/lib/mysql-connector-java-5.1.32.jar /usr/local/sqoop/lib/
2)配置环境变量
进入到Sqoop的conf目录下,找到sqoop-env-template.sh文件,重命名为sqoop-env.sh,打开进行环境变量的配置
cp /usr/local/sqoop/conf/sqoop-env-template.sh /usr/local/sqoop/conf/sqoop-env.sh
vi /usr/local/sqoop/conf/sqoop-env.sh
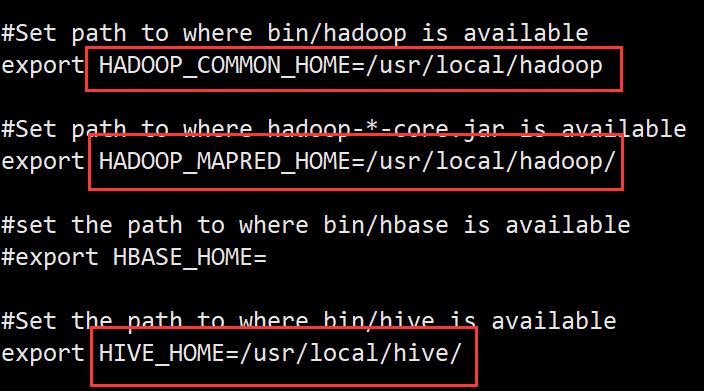
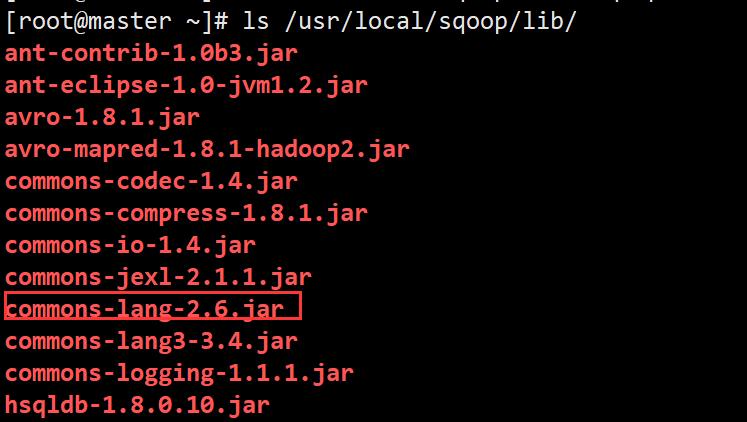
3)将commons-log.jar包放在lib下。
https://mirrors.tuna.tsinghua.edu.cn/apache//commons/lang/binaries/commons-lang-2.6-bin.zip
mv commons-lang-2.6.jar /usr/local/sqoop/lib/
chown hadoop:hadoop /usr/local/sqoop/lib/commons-lang-2.6.jar
Sqoop将Hive表中的数据导入MySQL
实验条件
MySQL正常启动
构建MySQL数据库中的表
1)登录MySQL
登录MySQL的命令
mysql -u root -p
2)创建数据库
create database if not exists test;

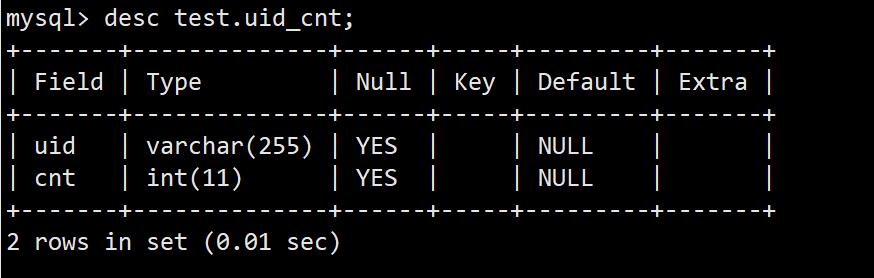
3)创建表
create table test.uid_cnt (uid varchar(255) default null,cnt int(11) default null);
构建Hive数据仓库中的表
1)进入Hive
2)创建Hive中的表sogou.sogou_uid_cnt
create table sogou.sogou_uid_cnt(uid string,cnt int) row format delimited fields terminated by '\\t';
3)向表中写入数据
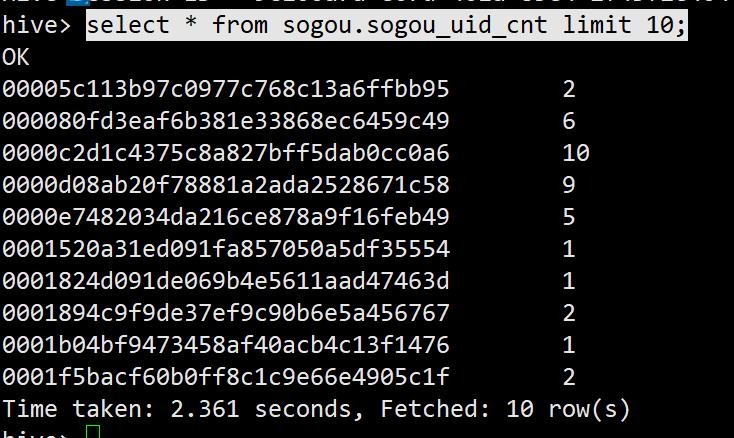
insert into table sogou.sogou_uid_cnt select uid,count(*) from sogou_500w group by uid;
select * from sogou.sogou_uid_cnt limit 10;
使用Sqoop工具将Hive的数据导入MySQL
1)导入命令
/usr/local/sqoop/bin/sqoop export --connect jdbc:mysql://master:3306/test --username root --password 123456 --table uid_cnt --export-dir 'hdfs://master:9000/user/hive/warehouse/sogou.db/sogou_uid_cnt' --fields-terminated-by '\\t'
2)以上命令的解释如下
sqoop export表示数据从Hive复制到MySQL数据库中;–connect jdbc:mysql://master:3306/test表示连接MySQL数据库test;–username root表示连接MySQL数据库的用户名;–password 12345表示连接MySQL数据库的密码;–table uid_cnt表示MySQL中的表即将被导入的表名称;–export-dir '/user/hive/warehouse/sogou.db/uid_cnt’表示Hive中被导出的文件路径;–fields-terminated-by '\\t’表示Hive中被导出的文件字段的分隔符。
3)以上命令成功运行之后会在控制台打印输出如下结果

4)最后,验证结果数据。
登录MySQL数据库,查询库test的表uid_cnt中是已经有了数据,如果有数据说明Sqoop工具将Hive中的数据成功导入了MySQL。
select * from test.uid_cnt limit 10;

select count(*) from test.uid_cnt;

使用Sqoop工具将MySQL中的数据导入Hive表
前面我们成功地将Hive表sogou_uid_cnt中的数据导入MySQL数据库的uid_cnt表,反之,我们再利用Sqoop工具将表uid_cnt中的数据导入表sogou_uid_cnt2中
1)首先,在Hive中创建表sogou_uid_cnt2
create table sogou.sogou_uid_cnt2(uid string,cnt int) row format delimited fields terminated by '\\t';
describe sogou.sogou_uid_cnt2;
2)然后,我们就可以使用Sqoop工具将MySQL中表uid_cnt的数据导入Hive的表sogou_uid_cnt
在导入数据之前,/user/hive/warehouse/sogou.db/sogou_uid_cnt2已经存在,我们将其删除。
hdfs dfs -rmdir /user/hive/warehouse/sogou.db/sogou_uid_cnt2
/usr/local/sqoop/bin/sqoop import --connect jdbc:mysql://master:3306/test --username root --password 123456 --table uid_cnt --target-dir /user/hive/warehouse/sogou.db/sogou_uid_cnt2 --fields-terminated-by '\\t' -m 1

3)进入Hive进行验证
select * from sogou.sogou_uid_cnt2 limit 10;

以上是关于HiveQL数据查询进阶的主要内容,如果未能解决你的问题,请参考以下文章