NLP文本分类TorchText实战-AG_NEWS 新闻主题分类任务(PyTorch版)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP文本分类TorchText实战-AG_NEWS 新闻主题分类任务(PyTorch版)相关的知识,希望对你有一定的参考价值。
AG_NEWS 新闻主题分类任务(PyTorch版)
前言
这是TorchText官方的一个教程,更多内容.请参考官方文档:PyTorch / TorchText .
本教程说明如何使用torchtext中的文本分类数据集,包括:
- AG_NEWS,
- SogouNews,
- DBpedia,
- YelpReviewPolarity,
- YelpReviewFull,
- YahooAnswers,
- AmazonReviewPolarity,
- AmazonReviewFull
此示例显示了如何使用这些TextClassification数据集之一训练用于分类的监督学习算法。
1. 使用 N 元组加载数据
一袋 N 元组特征用于捕获有关本地单词顺序的一些部分信息。 在实践中,应用二元语法或三元语法作为单词组比仅一个单词提供更多的好处。 一个例子:
"load data with ngrams"
Bi-grams results: "load data", "data with", "with ngrams"
Tri-grams results: "load data with", "data with ngrams"
TextClassification数据集支持ngrams方法。 通过将ngrams设置为 2,数据集中的示例文本将是一个单字加二元组字符串的列表。
import torch
import torchtext
from torchtext.datasets import text_classification
NGRAMS = 2
import os
if not os.path.isdir('./.data'):
os.mkdir('./.data')
train_dataset, test_dataset = text_classification.DATASETS['AG_NEWS'](
root='./.data', ngrams=NGRAMS, vocab=None)
BATCH_SIZE = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. 安装 Torch-GPU&TorchText
1.安装 Torch-GPU版本,请参考: PyTorch 最新安装教程(2021-07-27)
2.输入以下代码进行安装 TorchText:
pip install torchtext
注意:在Pycharm中以这种方式安装Torchtext,会默认安装最新版0.10.0,其中旧版本的一些方法被弃用;另外,默认会附加安装Pytorch最新版CPU版,这可能会覆盖掉您之前安装的GPU版本的Pytorch,请参考:【PyTorch】Key already registered with the same priority: GroupSpatialSoftmax 解决方法.
原文的这个from torchtext.datasets import text_classification代码已被弃用,而且text_classification.DATASETS['AG_NEWS']的参数都变了,详见英文手册。
3. 访问原始数据集迭代器
Torchtext 库提供了一些原始数据集迭代器,这些迭代器产生原始文本字符串。
例如,AG_NEWS数据集迭代器产生的原始数据是标签和文本的元组。
使用此函数时train_data, test_dataset = AG_NEWS(root=path, split=('train', 'test'))会报错:
TimeoutError: [WinError 10060] A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond
这里直接打开url进行下载:
URL = {
'train': "https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/train.csv",
'test': "https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/test.csv",
}
注意:该url内网无法打开,使用IDM下载器可能下载。
推荐:数据集可以在百度云下载,链接:https://pan.baidu.com/s/1FBkweGDEAFgnakZnPpOfLQ 提取码:5oxn
查看数据:
from torchtext.datasets import AG_NEWS
path = '... your path\\\\AG_NEWS.data'
train_data, test_dataset = AG_NEWS(root=path, split=('train', 'test'))
print(next(train_data))
print(next(train_data))
(3, "Wall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\\\band of ultra-cynics, are seeing green again.")
(3, 'Carlyle Looks Toward Commercial Aerospace (Reuters) Reuters - Private investment firm Carlyle Group,\\\\which has a reputation for making well-timed and occasionally\\\\controversial plays in the defense industry, has quietly placed\\\\its bets on another part of the market.')
4. 准备数据处理管道
我们已经重新审视了torchtext库中最基本的组件,包括vocab、单词向量、tokenizer。
这些都是原始文本字符串的基本数据处理构件。
这里是一个典型的NLP数据处理的例子,使用tokenizer和词汇。
第一步是用原始训练数据集建立一个词汇表,用户可以通过在Vocab类的构造函数中设置参数来拥有一个自定义的词汇表。用户可以通过在Vocab类的构造函数中设置参数来拥有一个自定义的词汇表。例如,要包含的令牌的最小频率min_freq
对于函数lambda,此表达式是一种匿名函数,对应python中的自定义函数def.
词汇块将一个tokens列表转换成整数:
[vocab[token] for token in ['here', 'is', 'an', 'example']]
>>> [476, 22, 31, 5298]
用标记器和词汇准备文本处理管道。文本和标签流水线将用于处理来自数据集迭代器的原始数据字符串:
文本流水线根据词汇表中定义的查找表将文本字符串转换为整数列表。标签流水线将标签转换为整数。
例如:
text_pipeline('here is the an example')
>>> [475, 21, 2, 30, 5286]
label_pipeline('10')
>>> 9
5. 生成数据批次和迭代器
torch.utils.data.DataLoader 推荐给 PyTorch 用户使用(教程在这里)。它适用于实现 getitem()和 len()协议的地图式数据集,并表示从索引/键到数据样本的映射。它也适用于shuffle argumnent为False的可迭代数据集。
在发送至模型之前, collate_fn 函数对 DataLoader 中生成的一批样本进行处理。collate_fn的输入是DataLoader中批量大小的数据, collate_fn根据之前声明的数据处理管道对它们进行处理。这里要注意,一定要将 collate_fn 声明为顶层 def,这样才能保证该函数在每个 worker 中都能使用。
在这个例子中,原始数据批输入中的文本条目被打包成一个列表,并作为一个单一的张量来连接nn.EmbeddingBag的输入。偏移量是一个定界符的张量,用于表示文本张量中各个序列的起始索引。Label是一个张量,保存了indidividual文本条目的标签。
关于torch.cumsum()函数的用法:
x = torch.arange(0, 6).view(2, 3)
print(x)
print(x.cumsum(dim=0)) # 按照列求和
print(x.cumsum(dim=1)) # 按照行依次求和
tensor([[0, 1, 2],
[3, 4, 5]])
tensor([[0, 1, 2],
[3, 5, 7]])
tensor([[ 0, 1, 3],
[ 3, 7, 12]])
个人理解collate_fn是从样本列表中过来了一个batch的数据,经过映射函数,形成一个tensor。
由于文本条目的长度不同,因此使用自定义函数generate_batch()生成数据批(一个batch大小的数据)和偏移量。 该函数被传递到torch.utils.data.DataLoader中的collate_fn。 collate_fn的输入是张量列表,其大小为batch_size,collate_fn函数将它们打包成一个小批量。 请注意此处,并确保将collate_fn声明为顶级def。 这样可以确保该函数在每个工作程序中均可用。
原始数据批量输入中的文本条目打包到一个列表中,并作为单个张量级联,作为nn.EmbeddingBag的输入。 偏移量是定界符的张量,表示文本张量中各个序列的起始索引。 Label是一个张量,用于保存单个文本条目的标签。
def generate_batch(batch):
label = torch.tensor([entry[0] for entry in batch])
text = [entry[1] for entry in batch]
offsets = [0] + [len(entry) for entry in text]
# torch.Tensor.cumsum returns the cumulative sum
# of elements in the dimension dim.
# torch.Tensor([1.0, 2.0, 3.0]).cumsum(dim=0)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)
text = torch.cat(text)
return text, offsets, label
6. 定义模型
该模型由nn.EmbeddingBag层加上一个线性层组成,以达到分类的目的。nn.EmbeddingBag默认模式为 “mean”,计算一个 "袋 "的嵌入物的平均值。虽然这里的文本条目有不同的长度,但由于文本长度是以偏移量保存的,所以nn.EmbeddingBag模块在这里不需要填充。
另外,由于nn.EmbeddingBag会动态累积嵌入中的平均值,因此nn.EmbeddingBag可以提高性能和存储效率,以处理张量序列。
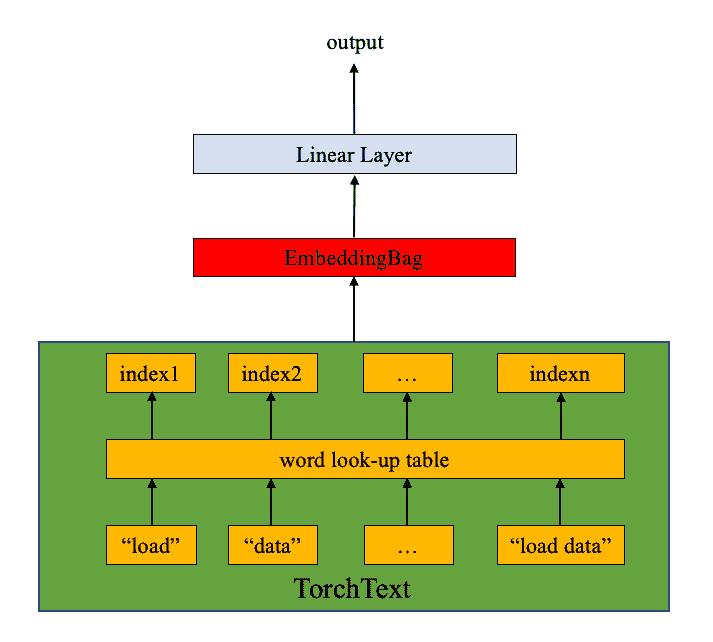
# 导入必备的torch模型构建工具
import torch.nn as nn
import torch.nn.functional as F
class TextSentiment(nn.Module):
"""文本分类模型"""
def __init__(self, vocab_size, embed_dim, num_class):
"""
description: 类的初始化函数
:param vocab_size: 整个语料包含的不同词汇总数
:param embed_dim: 指定词嵌入的维度
:param num_class: 文本分类的类别总数
"""
super().__init__()
# 实例化embedding层, sparse=True代表每次对该层求解梯度时, 只更新部分权重.
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
# 实例化线性层, 参数分别是embed_dim和num_class.
self.fc = nn.Linear(embed_dim, num_class)
# 为各层初始化权重
self.init_weights()
def init_weights(self):
"""初始化权重函数"""
# 指定初始权重的取值范围数
initrange = 0.5
# 各层的权重参数都是初始化为均匀分布
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
# 偏置初始化为0
self.fc.bias.data.zero_()
def forward(self, text, offsets):
"""
:param text: 文本数值映射后的结果
:return: 与类别数尺寸相同的张量, 用以判断文本类别
"""
# 获得embedding的结果embedded
# >>> embedded.shape
# (m, 32) 其中m是BATCH_SIZE大小的数据中词汇总数
embedded = self.embedding(text, offsets)
return self.fc(embedded)
关于EmbeddingBag()函数,官方文档,参数只多了一个:mode,来看这个参数的取值有三种,对应三种操作:"sum"表示普通embedding后接torch.sum(dim=0),"mean"相当于后接torch.mean(dim=0),"max"相当于后接torch.max(dim=0)
此网络输入输出的例子:
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum')
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([1,2,4,5,4,3,2,9])
>>> offsets = torch.LongTensor([0,4])
>>> embedding_sum(input, offsets)
tensor([[-0.8861, -5.4350, -0.0523],
[ 1.1306, -2.5798, -1.0044]])
7. 初始化一个实例
AG_NEWS数据集有四个标签,因此类的数量是四个:
1 : World
2 : Sports
3 : Business
4 : Sci/Tec
我们建立一个嵌入维度为64的模型,vocab大小等于词汇实例的长度,类的数量等于标签的数量4。
# VOCAB_SIZE = len(train_dataset.get_vocab()) 新版本已淘汰
VOCAB_SIZE = len(vocab) # 思路:去重后统计词的总数(参考下面的完整代码)
EMBED_DIM = 32
NUN_CLASS = 4
model = TextSentiment(VOCAB_SIZE, EMBED_DIM, NUN_CLASS).to(device)
8. 定义训练模型和评估结果的函数
关于调整学习率,官方文档,函数:torch.optim.lr_scheduler提供了几种方法来调整基于epochs的学习率.
torch.optim.lr_scheduler.StepLR每隔一个step_size epochs,将每个参数组的学习率按gamma衰减。请注意,这种衰减可以与其他来自这个调度器外部的学习率变化同时发生。当last_epoch=-1时,设置初始lr为lr
关于torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1)函数,作用是剪切参数迭代的梯度法线,官方文档,法线是在所有梯度上一起计算的,就像它们被连成一个向量一样。梯度是就地修改的,即:梯度剪切,规定了最大不能超过的max_norm
对于每一个batch预测的predited_label,是一个64*4的tensor,对于每一个label,是一个64的一维的tensor.
tensor([[ 0.4427, 0.0830, 0.0109, 0.1273],
[ 0.1601, 0.0869, -0.0540, 0.0422],
...
tensor([0, 0, 0, 3, 1, 1, 1, 3, 3, 3, 3, 3, 1, 1, 3, 1, 1, 3, 3, 3, 1, 1, 3, 3,
3, 1, 1, 2, 1, 2, 1, 1, 3, 3, 1, 1, 1, 3, 1, 3, 0, 1, 0, 0, 1, 3, 3, 3,
2, 3, 1, 3, 3, 3, 1, 3, 3, 1, 1, 2, 0, 2, 1, 3])
之前我们用的是.topk()函数,这里了解一下.argmax(1)函数:
print(predited_label.argmax(1) == label)
tensor([False, True, True, True, False, True, True, True, True, True,
True, False, True, True, True, False, True, True, True, True,
True, True, True, True, True, True, True, True, True, True,
True, False, True, False, True, True, True, True, False, True,
True, True, False, True, False, True, True, False, True, True,
True, False, False, True, True, False, True, False, False, True,
False, True, True, True])
执行以下代码输出就是一个常数:
(predited_label.argmax(1) == label).sum().item()
9. 分割数据集并运行模型
由于原AG_NEWS没有有效数据集,我们将训练数据集拆分为训练/有效集,拆分比例为0.95(训练)和0.05(有效)。这里我们使用PyTorch核心库中的torch.utils.data.dataset.random_split函数
CrossEntropyLoss准则将nn.LogSoftmax()和nn.NLLLoss()结合在一个类中。它在训练分类问题时非常有用。SGD实现了随机梯度下降法作为优化器。初始学习率设置为5.0。这里使用StepLR通过epochs来调整学习率
打印训练过程:
| epoch 1 | 500/ 1782 batches, accuracy 0.685
| epoch 1 | 1000/ 1782 batches, accuracy 0.852
| epoch 1 | 1500/ 1782 batches, accuracy 0.876
-----------------------------------------------------------
| end of epoch 1 | time: 15.24s | valid accuracy 0.886
-----------------------------------------------------------
| epoch 2 | 500/ 1782 batches, accuracy 0.896
| epoch 2 | 1000/ 1782 batches, accuracy 0.902
| epoch 2 | 1500/ 1782 batches, accuracy 0.902
-----------------------------------------------------------
| end of epoch 2 | time: 15.20s | valid accuracy 0.899
-----------------------------------------------------------
| epoch 3 | 500/ 1782 batches, accuracy 0.915
| epoch 3 | 1000/ 1782 batches, accuracy 0.914
| epoch 3 | 1500/ 1782 batches, accuracy 0.915
-----------------------------------------------------------
| end of epoch 3 | time: 15.22s | valid accuracy 0.904
-----以上是关于NLP文本分类TorchText实战-AG_NEWS 新闻主题分类任务(PyTorch版)的主要内容,如果未能解决你的问题,请参考以下文章