系统学习金融数据挖掘 之爬虫技术基础(附源代码)(网页结构基础)
Posted yk 坤帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统学习金融数据挖掘 之爬虫技术基础(附源代码)(网页结构基础)相关的知识,希望对你有一定的参考价值。
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
1. 爬虫基础1 - 网页结构基础
1.1 浏览器F12的运用,以及如何看网页源代码
首先安装谷歌浏览器:从官网https://www.google.cn/chrome/下载
当然用别的浏览器,比如火狐浏览器等都是可以。
按F12(有的电脑要同时按住左下角的Fn键)能弹出如下图的内容即可。
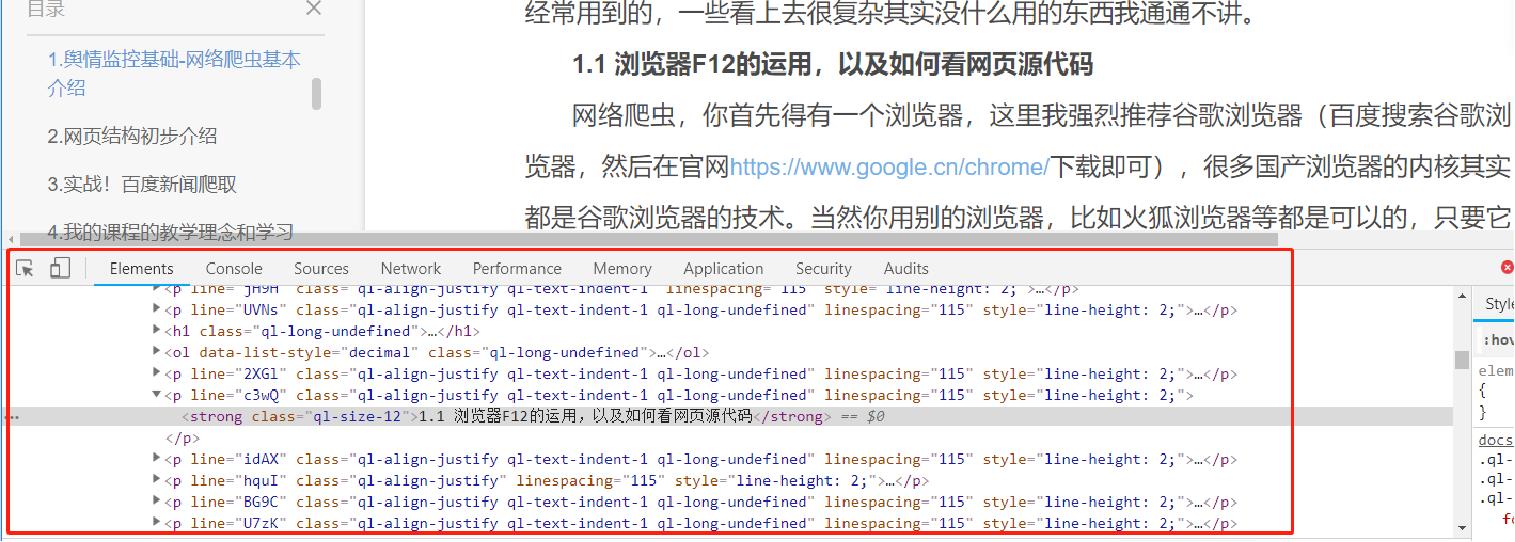
百度搜索“阿里巴巴”,然后按一下F12,弹出如下页面:
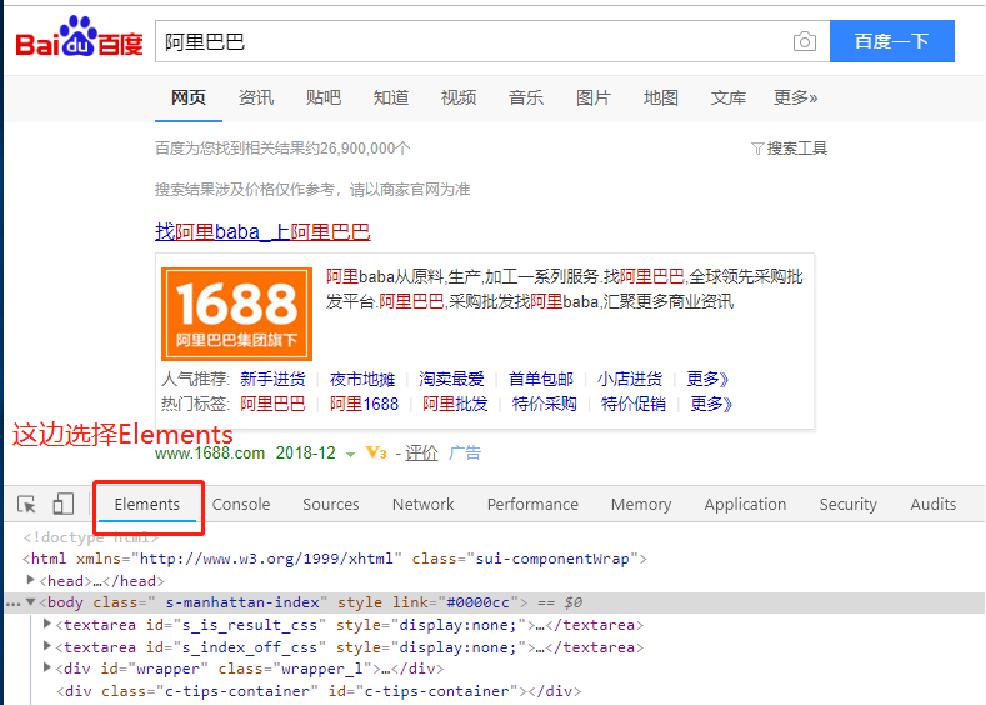
这个按住F12弹出来的东西叫做开发者工具,是进行数据挖掘的利器,对于爬虫来说,只需要会用下图的这两个按钮即可。

(1)选择按钮 :

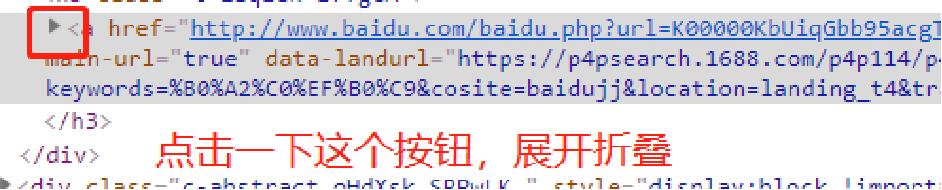
点击一下它,发现它会变成蓝色,然后把鼠标在页面上移动移动,会发现页面上的颜色机会发生改变。如下一页图所示,当移动鼠标的时候,会发现界面上的颜色会发生变化,并且Elements里的内容就会随之发生变化。

如果没看到中文,点击下下图那个箭头把内容展开即可。
(2) Elements元素按钮:
Elements元素按钮里面的内容可以理解为就是网站的源码,最后爬虫爬到的内容大致就是长这个样子的。在下图阿里那个地方鼠标双击俩下,这两个字变成可编辑的格式。
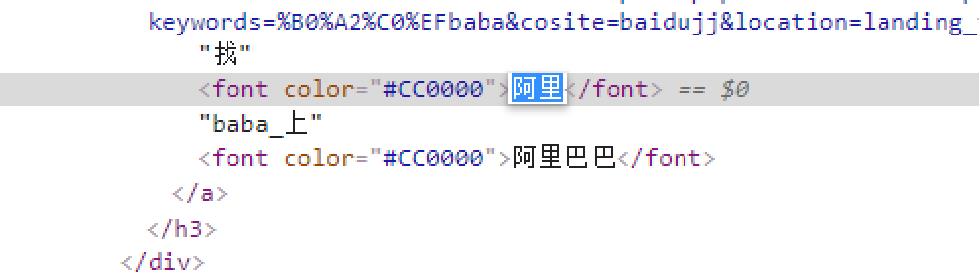
可以把它改成“工作”,然后同样双击下面一行的“baba_上”使它变成可编辑的格式,把“baba_上”中的“baba”删掉,可以看到第一个的标题变成下图了:

还可以用同样的操作,先选
择选择按钮,点击下面的
阿里股价:
用同样的方法可以在
Elements里将这个数字
改成所想改的数据,
如下图所示:
1.2 查看网页源码的另外一个方式
另外一个获取网页源码的方式是在网页上右击选择“查看网页源代码”

1.3 网址构成及http与https协议
如果在Python里输入
www.baidu.com
它是不认识的,应为他会以为是http://,我们得把“https://”加上才行,如下面所示。

其实最简单的办法,就是直接浏览器访问该网址,然后把链接复制下来就行。
1.4 网页结构初步了解
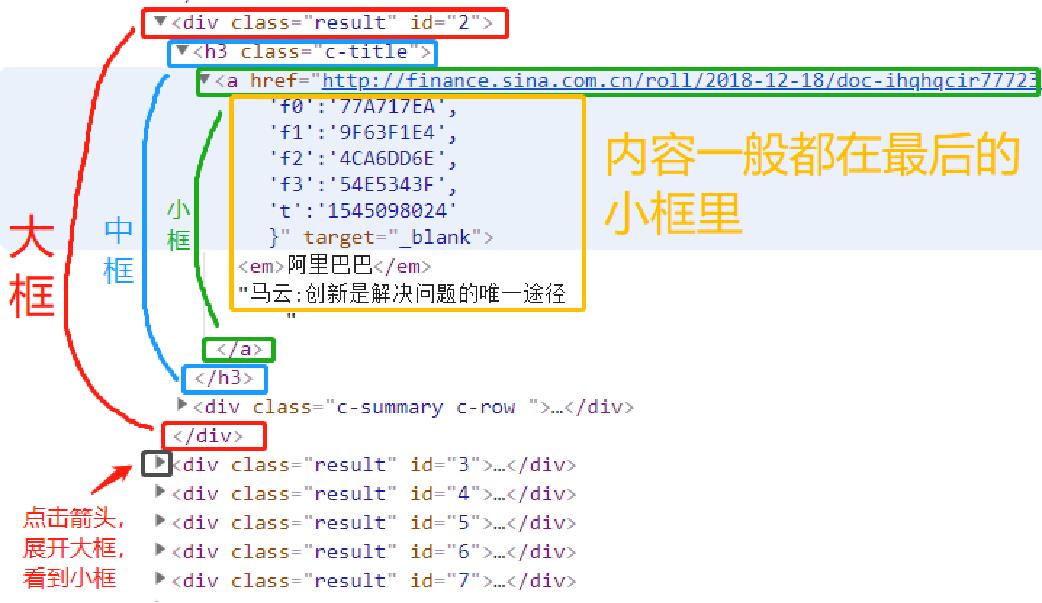
结构其实很简单,就是一个大框套着一个小框,一个小框再套着一个小小框,一般文本内容都是在最后的小框里。
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
以上是关于系统学习金融数据挖掘 之爬虫技术基础(附源代码)(网页结构基础)的主要内容,如果未能解决你的问题,请参考以下文章